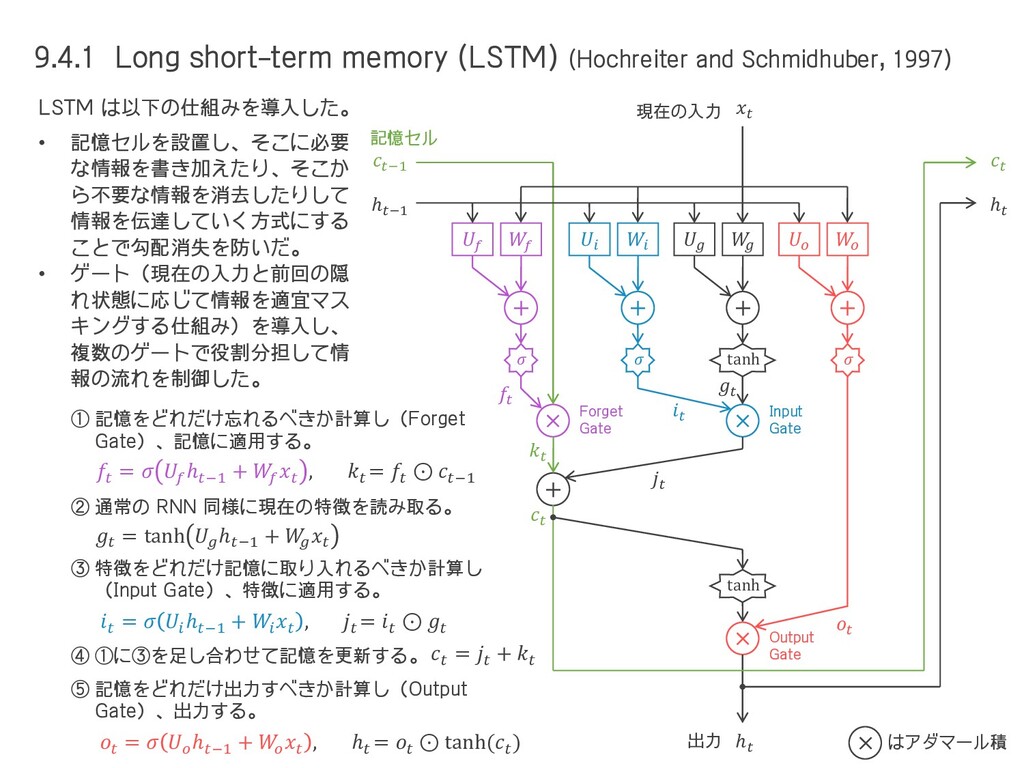
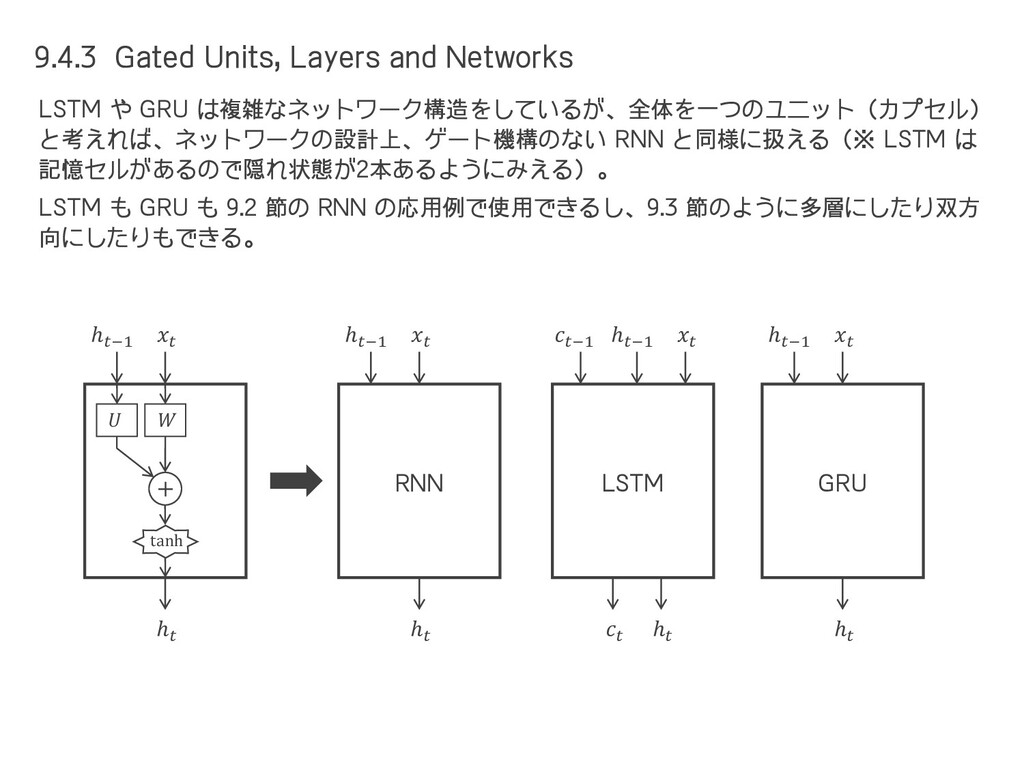
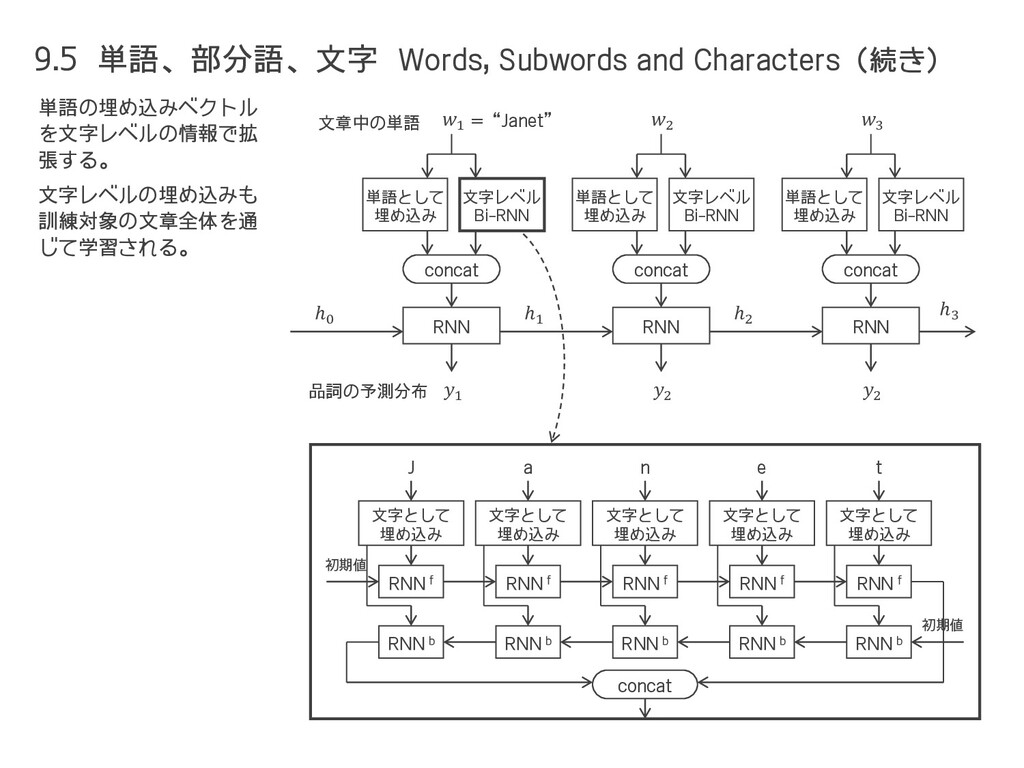
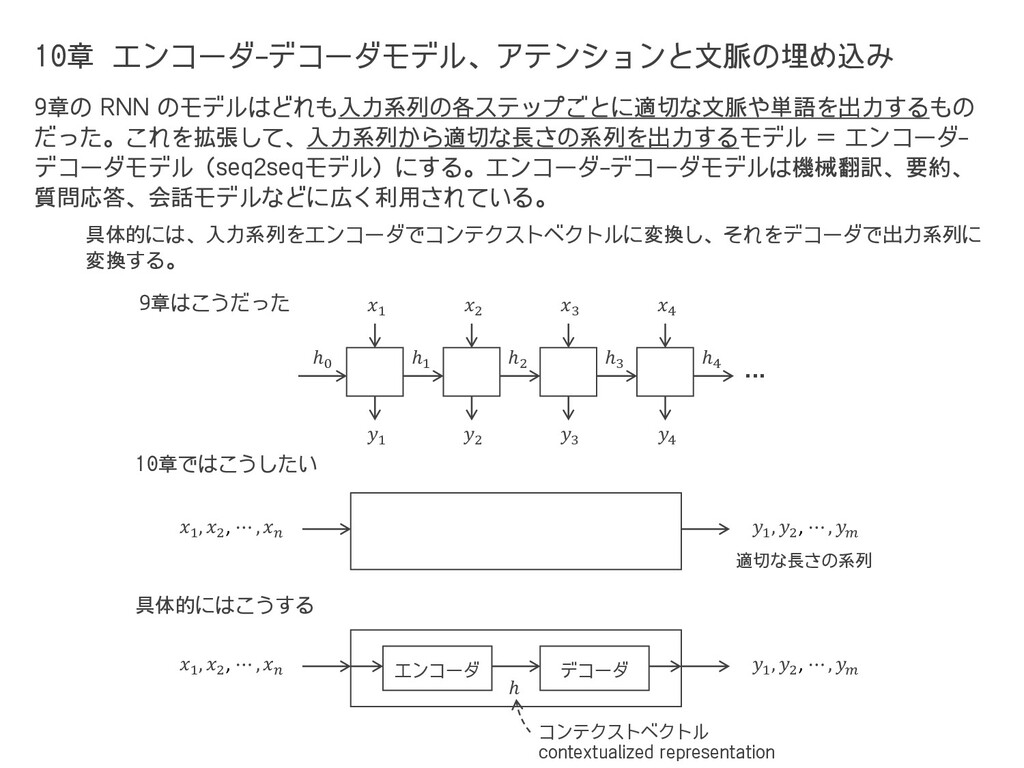
= ሚ ℎ,, ℎ−1, = ሚ ℎ,, , = out,, ℎ, + ℎ−1 損失 ℎ () () () () ① ② ③ ④ ⑤ ⑥ out, ሚ ℎ, 但し、④ の箇所(中間層)における値は だけでなく +1 , +2 , ⋯ の値に影響するので、それも考慮すると ሚ ℎ, を修正する必要がある。 ℎ−1, = , () , () ℎ−1, = , () σ′ ′ ℎ−1,′ ℎ−1, = ሚ ℎ,, ⑦ −1, + −1, = ℎ−1, ℎ−1, −1, + −1, = ሚ ℎ,, ′ −1, + −1, ⑧ ሚ ℎ,, ( + 1) = 1 ሚ ℎ,+1,1 1 ′ , + , ሚ ℎ,, ≡ , () ′ , + , ሚ ℎ,, ( + 1) を導出するため、前頁の続きで、さらに ⑦, ⑧ までたどる。 ሚ ℎ,, ( + 2) = 1 ሚ ℎ,+1,1 + 2 1 ′ , + , ℎ,, = ሚ ℎ,, + ሚ ℎ,, + 1 + ሚ ℎ,, + 2 + ⋯ = 1 2 ሚ ℎ,+2,2 21 ′ +1,1 + +1,1 1 ′ , + , への 影響 +1 への 影響 +2 への 影響 これが ሚ ℎ,−1, なので、 ሚ ℎ,, ( + 1) や ሚ ℎ,, ( + 2) は以下のようになる。 (9.4) ※ 独自の notation である。 1 が繰り返し掛け算 されるので勾配爆発 or 消失しやすい。 中間層 の誤差 出力層 の誤差
{kind=link}
{kind=link}
{kind=link}
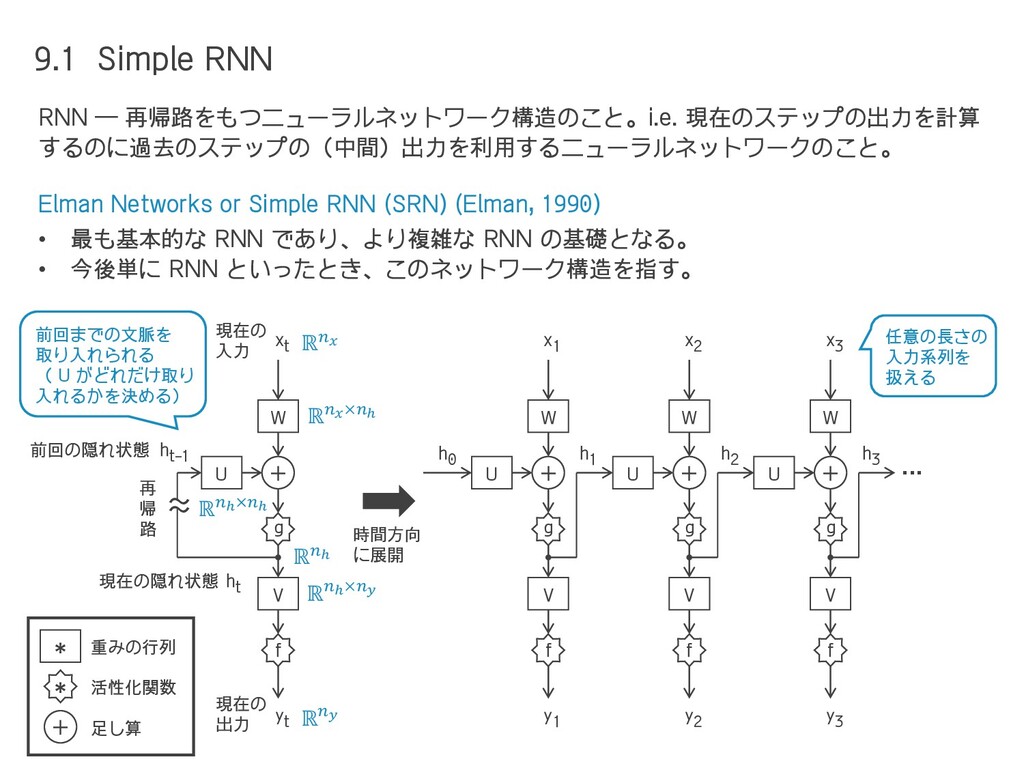{kind=link}
{kind=link}
{kind=link}
{kind=link}
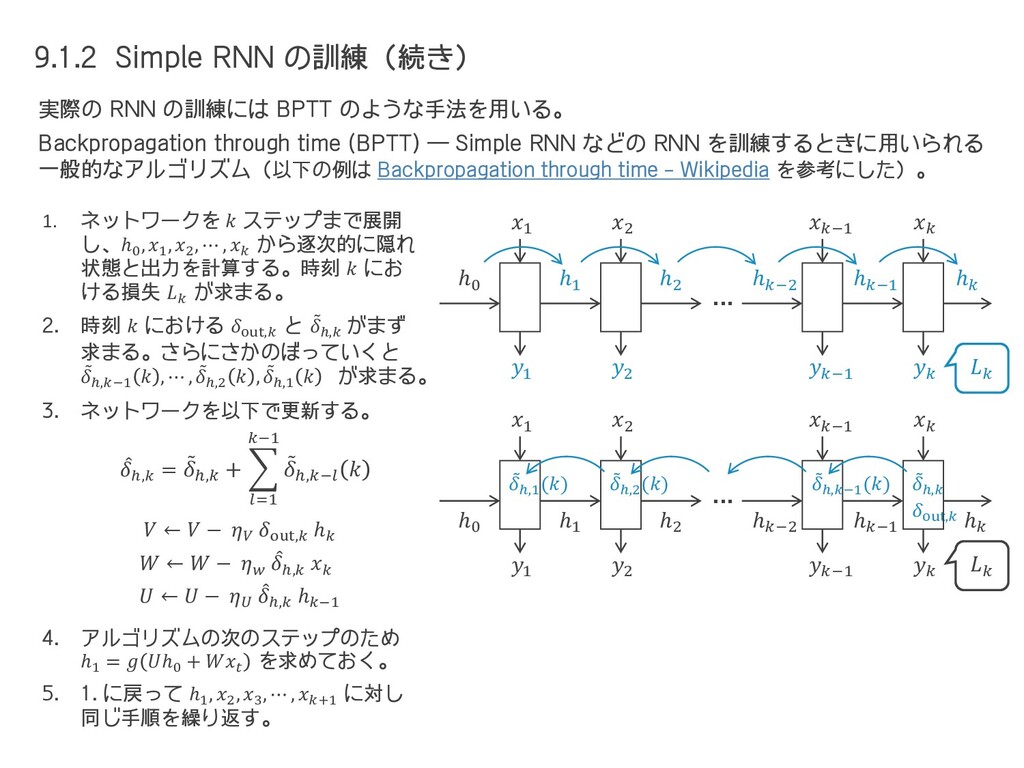{kind=link}
{kind=link}
{kind=link}
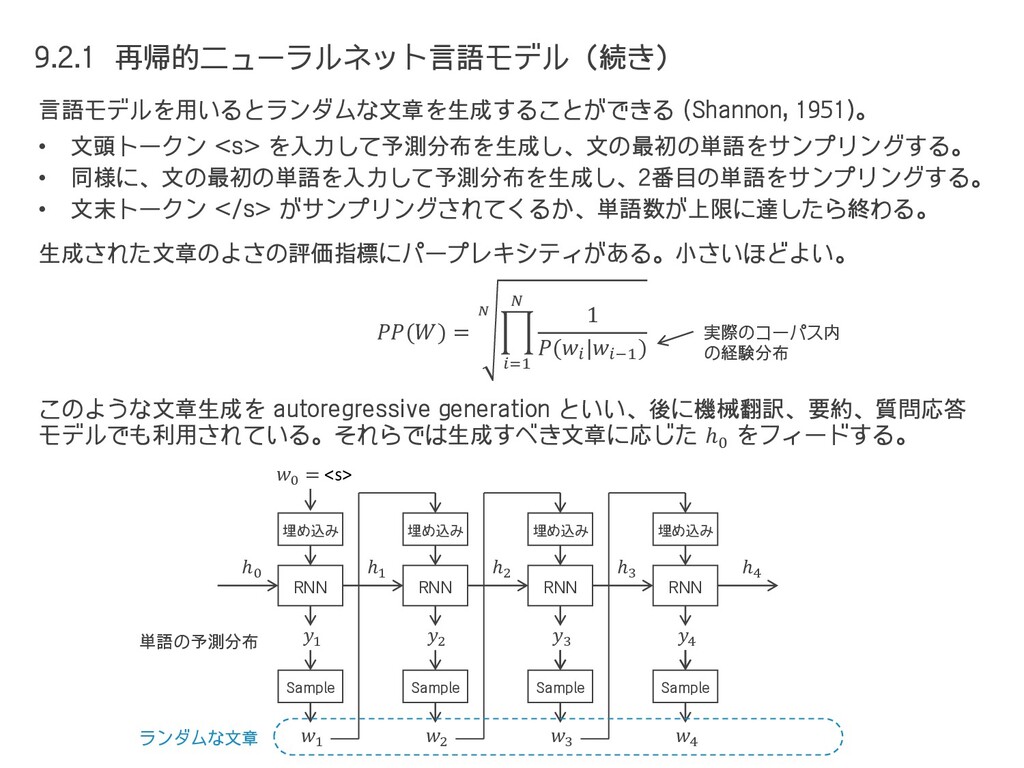{kind=link}
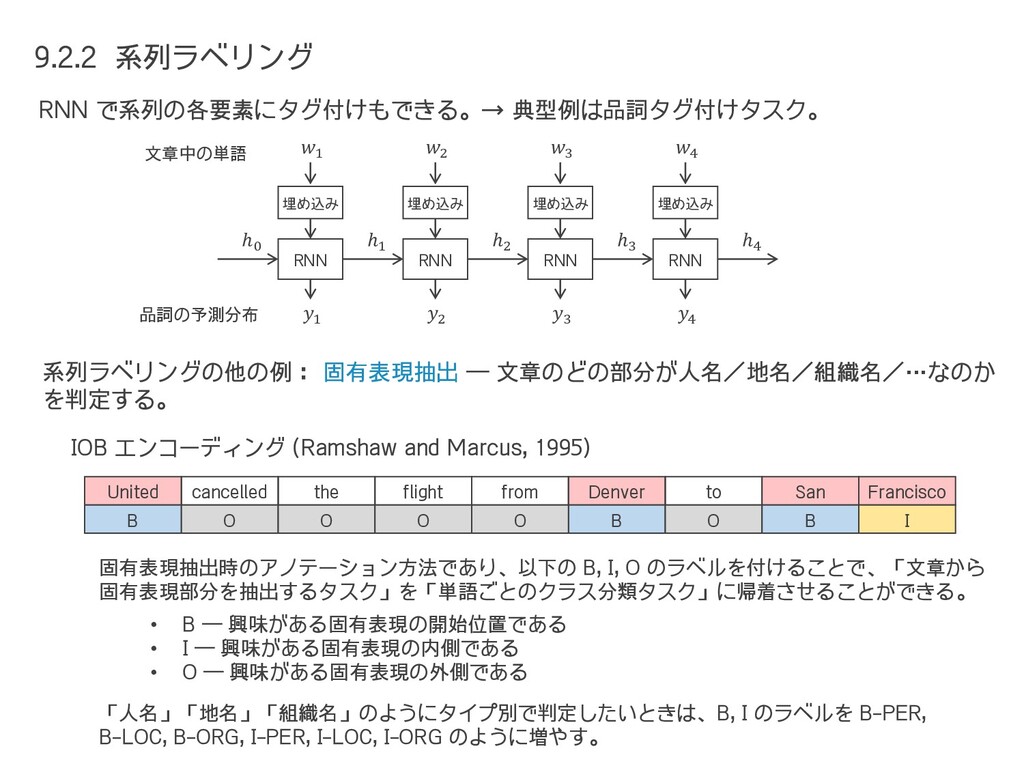{kind=link}
{kind=link}
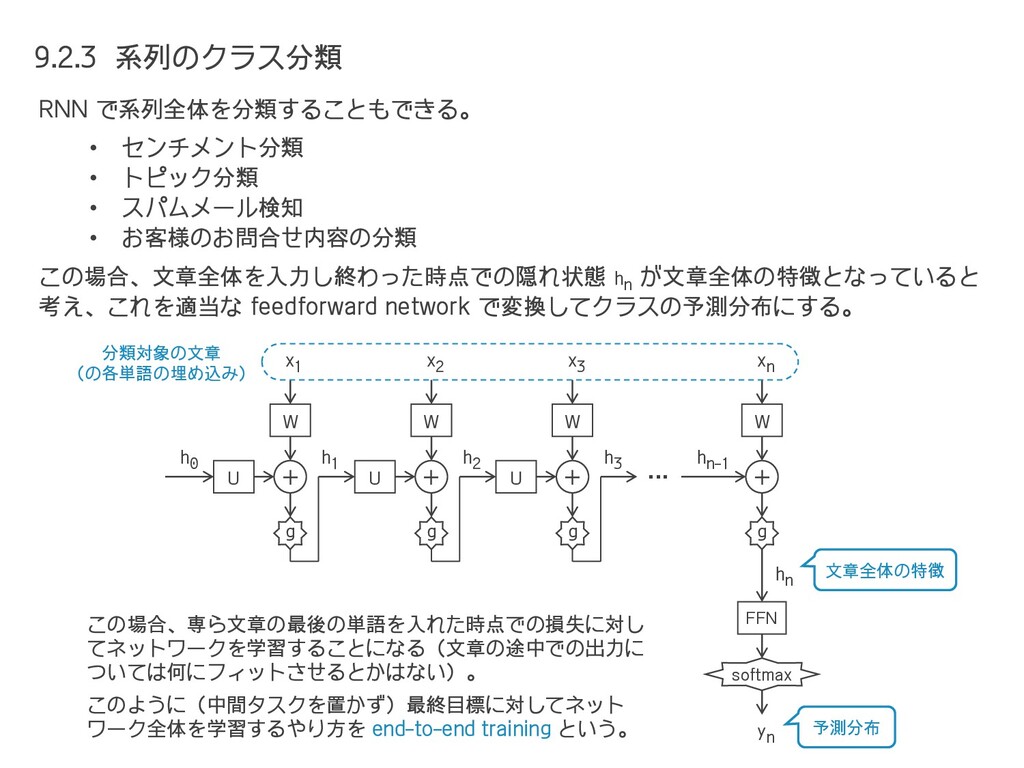{kind=link}
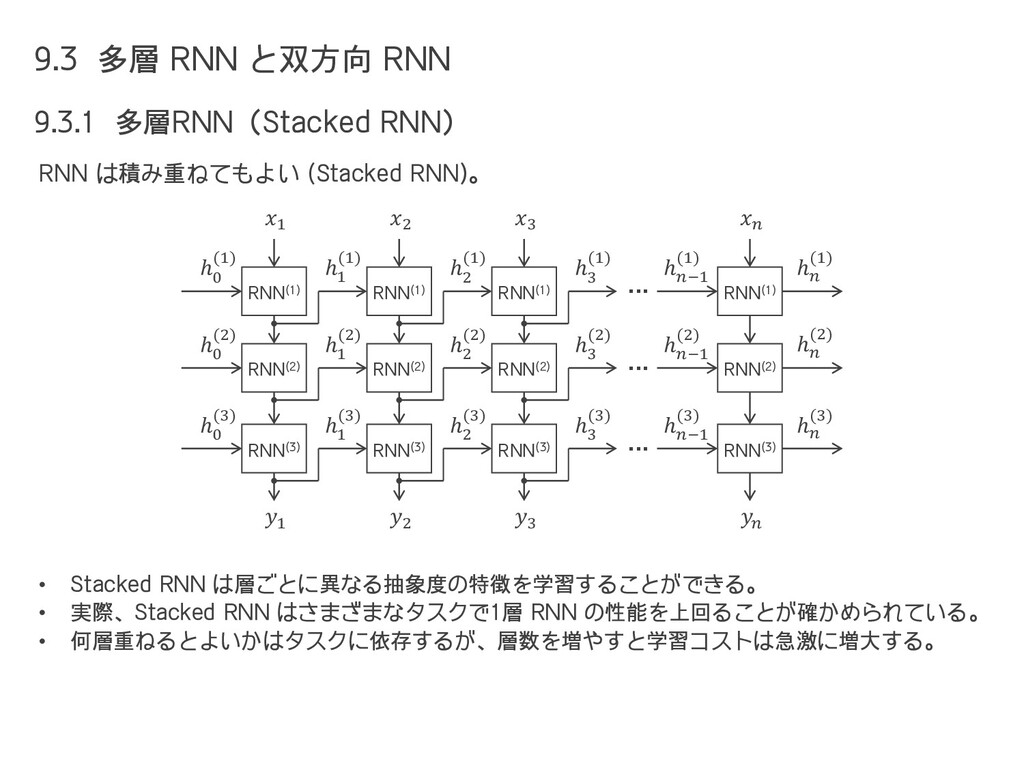{kind=link}
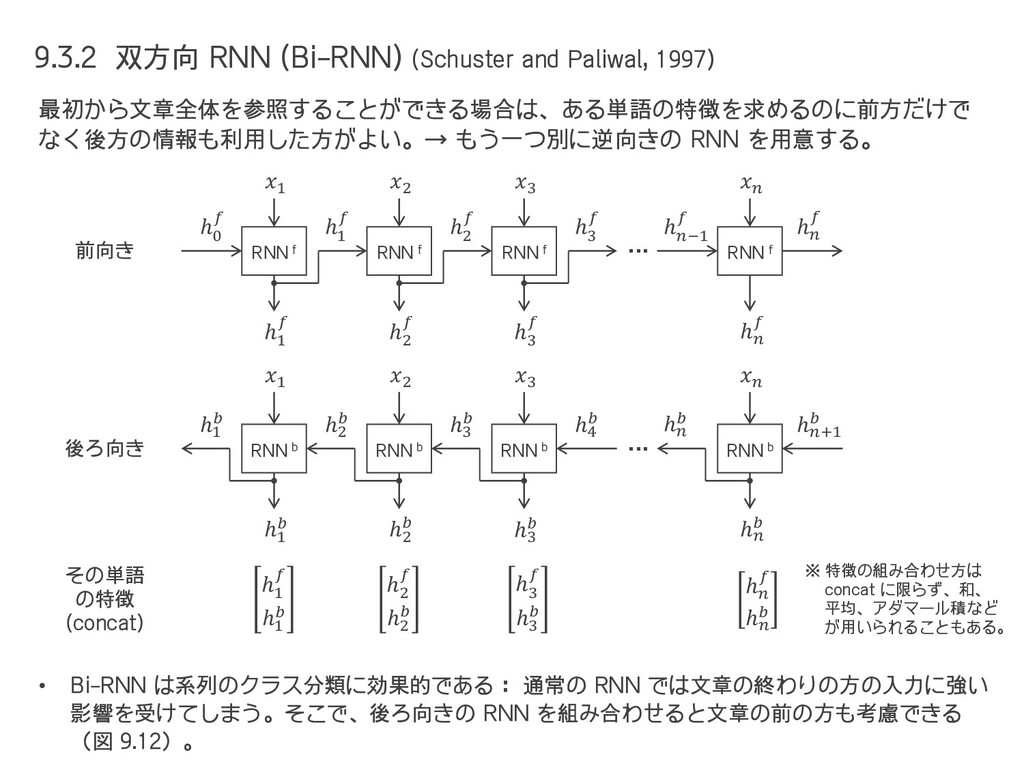{kind=link}
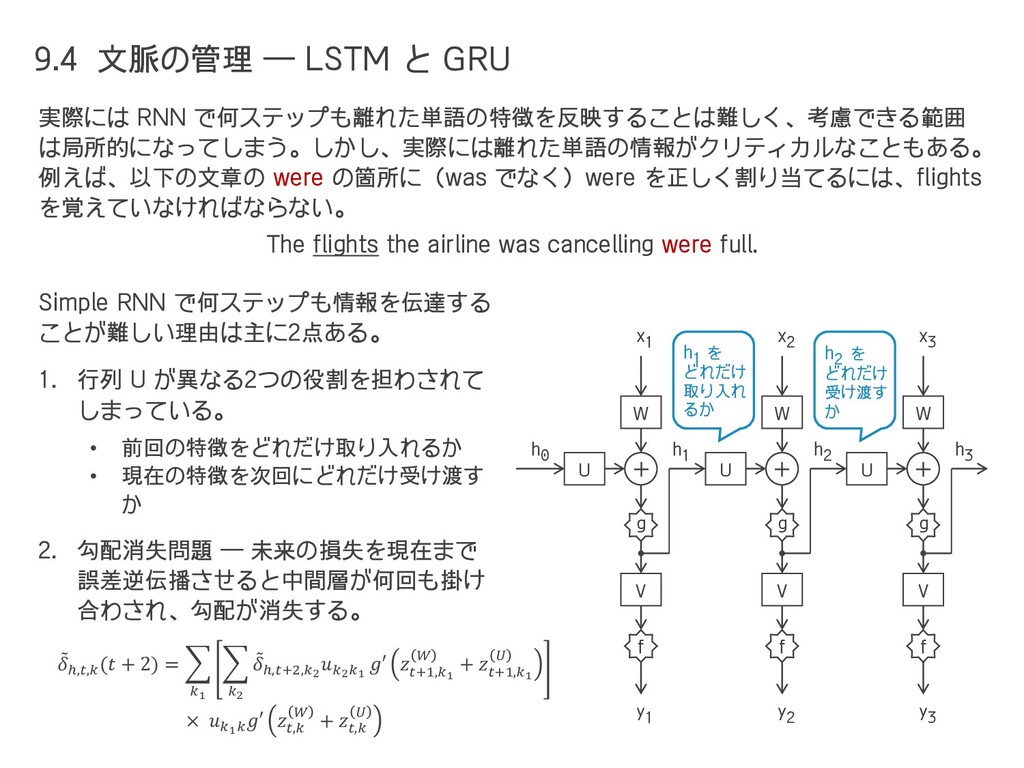{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}