Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
最近のTransformer関連の論文から
Search
CookieBox26
February 04, 2022
320
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
最近のTransformer関連の論文から
CookieBox26
February 04, 2022
More Decks by CookieBox26
See All by CookieBox26
ずんだもんと雪さんとDeepSeek-R1-Zero
cookiebox26
0
1.4k
svm as a constrainted optimization
cookiebox26
0
120
KDD2021の多変量時系列関連のタイトルいくつか
cookiebox26
0
320
固有表現抽出をドメイン外の弱いラベリングたちから学習する
cookiebox26
0
120
Speech and Language Processing 9章 RNNによる系列の処理
cookiebox26
0
2.3k
LSTM to GRU
cookiebox26
0
300
Speech and Language Processing 5章 ロジスティック回帰
cookiebox26
0
370
「統計的因果推論」勉強会 「1. 古典的問題意識」
cookiebox26
0
950
レヴィ過程の経験尤度推定の紹介
cookiebox26
0
670
Featured
See All Featured
Chasing Engaging Ingredients in Design
codingconduct
0
230
The Illustrated Children's Guide to Kubernetes
chrisshort
51
52k
Evolving SEO for Evolving Search Engines
ryanjones
0
230
A brief & incomplete history of UX Design for the World Wide Web: 1989–2019
jct
2
410
Visual Storytelling: How to be a Superhuman Communicator
reverentgeek
2
580
Max Prin - Stacking Signals: How International SEO Comes Together (And Falls Apart)
techseoconnect
PRO
0
200
WENDY [Excerpt]
tessaabrams
11
38k
The Curious Case for Waylosing
cassininazir
1
420
A better future with KSS
kneath
240
18k
Speed Design
sergeychernyshev
33
1.9k
Product Roadmaps are Hard
iamctodd
55
12k
A designer walks into a library…
pauljervisheath
211
24k
Transcript
最近のTransformer関連の論文から 三原 千尋 ▪ Reservoir(溜池) Transformers Reservoir Transformers. ACL 2021.
→ エンコーダ層の一部 (かなり一部) を乱数初期化のまま固定しても性能が出た。 ▪ 相対位置エンコーディング付きでも Kernelized Attention Stable, Fast and Accurate: Kernelized Attention with Relative Positional Encoding. NeurIPS 2021. → 相対位置エンコーディング付きセルフアテンションを 𝑂(𝑛 log 𝑛) で近似した。 ▪ KeyとQueryの分布をそろえてセルフアテンションさせやすく Alignment Attention by Matching Key and Query Disributions. NeurIPS 2021. → Key と Query の分布をそろえると文章理解系タスクの性能等が向上した。
前置き • リザバーコンピューティングについて調べようとしていたところ、ACL 2021 に Reservoir Transformers というタイトルをみつけたので紹介しようと考えた。 • が、最先端
NLP 勉強会で紹介されていた。一応、概要と所感を記す。 • 本日は代わりに NeurIPS 2021 の Transformer 関連の論文を系列データの観点 で調査していた中から自然言語処理らしいものを紹介したい。 2
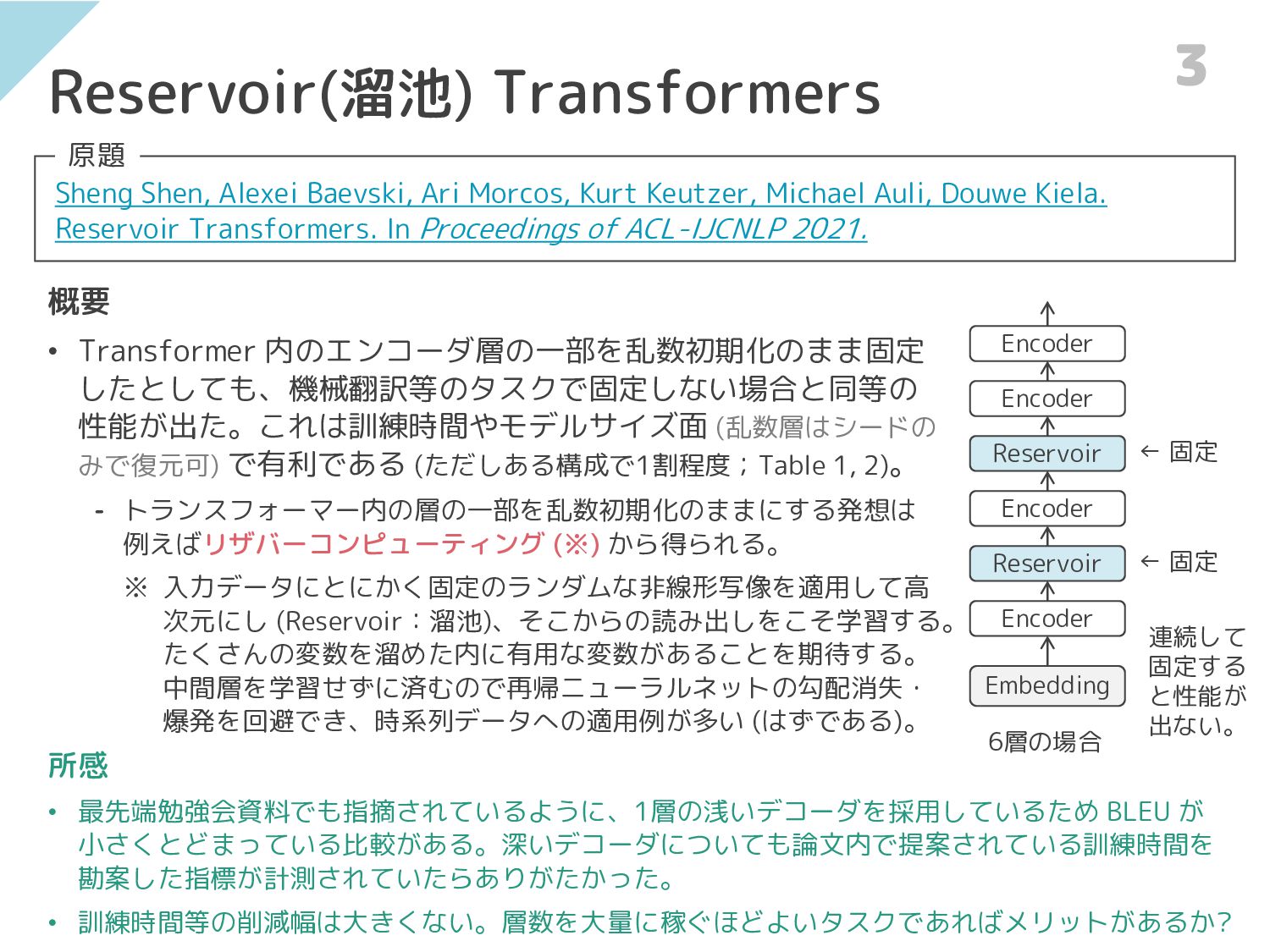
Reservoir(溜池) Transformers Sheng Shen, Alexei Baevski, Ari Morcos, Kurt Keutzer,
Michael Auli, Douwe Kiela. Reservoir Transformers. In Proceedings of ACL-IJCNLP 2021. 原題 概要 • Transformer 内のエンコーダ層の一部を乱数初期化のまま固定 したとしても、機械翻訳等のタスクで固定しない場合と同等の 性能が出た。これは訓練時間やモデルサイズ面 (乱数層はシードの みで復元可) で有利である (ただしある構成で1割程度;Table 1, 2)。 ⁃ トランスフォーマー内の層の一部を乱数初期化のままにする発想は 例えばリザバーコンピューティング (※) から得られる。 ※ 入力データにとにかく固定のランダムな非線形写像を適用して高 次元にし (Reservoir:溜池)、そこからの読み出しをこそ学習する。 たくさんの変数を溜めた内に有用な変数があることを期待する。 中間層を学習せずに済むので再帰ニューラルネットの勾配消失・ 爆発を回避でき、時系列データへの適用例が多い (はずである)。 Embedding Encoder Reservoir Encoder Reservoir Encoder Encoder 所感 • 最先端勉強会資料でも指摘されているように、1層の浅いデコーダを採用しているため BLEU が 小さくとどまっている比較がある。深いデコーダについても論文内で提案されている訓練時間を 勘案した指標が計測されていたらありがたかった。 • 訓練時間等の削減幅は大きくない。層数を大量に稼ぐほどよいタスクであればメリットがあるか? 6層の場合 3 ← 固定 ← 固定 連続して 固定する と性能が 出ない。
NeurIPS 2021 の Transformer 関連の論文(1 / 2) 4 • タイトルを元に
Transformer 関連 の論文を抜き出した もので網羅的ではな い。また、系列デー タ一般の処理に興味 があるためタイトル から自然言語処理以 外に適用できないと 思われた論文は拾っ ていない。 • cite はこちらのPDF を参照。これらの論 文のうち公開コード が確認できるものも 記してある。 • 区分は恣意的なもの、 1行要約は表面的な 理解によるものであ る。 多い。 Google Research, Brain Team
NeurIPS 2021 の Transformer 関連の論文(2 / 2) 5 次スライド以降で以下を紹介する。 •
アテンションの計算に高速フーリエ変換を応用する [25] 。 • Q と K の分布が近くなるように正則化する [15]。 Google Research Google Research, Brain Team このアプローチで3件提案されている。
相対位置エンコーディング付きでも Kernelized Attention Shengjie Luo, Shanda Li, Tianle Cai, Di
He, Dinglan Peng, Shuxin Zheng, Guolin Ke, Liwei Wang, Tie-Yan Liu. Stable, Fast and Accurate: Kernelized Attention with Relative Positional Encoding. In Proceedings of NeurIPS 2021. 原題 • [KrzysztofMarcin+2021] などにみられる Kernelized Attention はセルフアテ ンションの計算量を系列長の 𝑂(𝑛2) から 𝑂(𝑛) に抑え、系列長約 500 のテキスト データ等で Transformer に対して訓練速度・推論速度で優位性を得ている。 • 他方、相対位置エンコーディング (RPE) を採用したい場合は既存の Kernelized Attention の枠組みでは取り扱うことができない。 • そこで、RPE がある場合の Kernelized Attention を提案する。このセルフアテ ンションは愚直に計算すると結局 𝑂(𝑛2) になるが、この場合は FFT を適用して 𝑂(𝑛 log 𝑛) にできる。さらに Kernelize 前に正規化することで安定化を図る。 • 提案モデルは GLUE データセットタスクの一部等で 𝑂(𝑛2) 未満のアーキテクチャ としてはベストな性能を発揮した。 • 長い文章 × RPE の現実における需要感はわからない。 • テキスト以外で効果が出ないか? 6
𝑧𝑖 = σ𝑗=1 𝑛 exp 1 𝑑 𝑞𝑖 𝑘𝑗 T
𝑣𝑗 σ 𝑗′=1 𝑛 exp 1 𝑑 𝑞𝑖 𝑘 𝑗′ T 𝑧𝑖 = σ𝑗=1 𝑛 𝜙 𝑞𝑖 𝜙 𝑘𝑗 T 𝑣𝑗 σ 𝑗′=1 𝑛 𝜙 𝑞𝑖 𝜙 𝑘 𝑗′ T = 𝜙 𝑞𝑖 σ𝑗=1 𝑛 𝜙 𝑘𝑗 T 𝑣𝑗 𝜙 𝑞𝑖 σ 𝑗′=1 𝑛 𝜙 𝑘 𝑗′ T 通常のセルフアテンションはこう。 この「単語 𝑖 から単語 𝑗 への注意の強さ」exp 1 𝑑 𝑞𝑖 ⋅ 𝑘𝑗 を何らかの特徴 softmax 𝑖 単語目にセルフアテンションを適用した 𝑧𝑖 を得る のに、𝑗 = 1, ⋯ , 𝑛 に対し 𝑞𝑖 𝑘𝑗 T を計算する必要。 ⇒ 𝑖 = 1, ⋯ , 𝑛 単語目すべてのセルフアテンション を得るには2重ループになり計算量が 𝑂(𝑛2) になる。 和と内積が交換するため、 点線で囲んだ箇所を 𝑖 = 1, ⋯ , 𝑛 で使い回せるので、 計算量が 𝑂(𝑛) になる。 Kernelized Attention のモチベーション(1 / 2) 単語 𝑖 から単語 𝑗 への注意の強さ (仮称) 空間における内積で近似したい (= Kernelized Attention )。 特徴写像 注意の強さ (仮称) カーネル法 ―― 線形モデルを適用するべくデータの方を特徴空間に埋め込もうとする方法論。 特徴写像は不要で特徴の内積があればよい。今回は線形モデルなら計算量が落ちる点にモチ ベーションがある。なお exp(・,・/√d ) は内積の要請を満たさないので近似することになる。 なので上式の特徴写像 𝜙 をどうすべきか知りたい。 7
𝜙RPF (𝑥) = exp − 𝑥 2/2 𝑚 exp(𝑤1 𝑥T)
, ⋯ , exp(𝑤𝑚 𝑥T) 特徴写像 𝜙 をどうすべきか知りたい。 → 内積を与える関数から特徴写像を近似する手法に Random Feature [AliRahimi+2007] がある。 → [KrzysztofMarcin+2021] ではそれをセルフアテンションに応用し、 以下の特徴写像 (PRF: Positive Random Feature) を採用、テキストや 画像やタンパク質データに適用し、 Transformer や Reformer に比べ、 長い系列に対する推論速度・訓練速度で優位性を得ている。 カーネル法における計算量削減 ―― 一般にカーネル法では線形モデルに帰着させた結果、 訓練データ間の内積を並べた行列 (グラム行列) に対する演算 (逆行列、固有値、…) をする ことになるため、データが巨大な場合はこれを避けたい。具体的なアプローチには「グラム 行列の低ランク近似」や「与えた内積に対応する特徴写像の近似」などがある。 Random Feature ―― カーネル法の計算量削減手法として知られ、特徴写像の近似に該当す る。内積のフーリエ逆変換表示の周波数サンプル近似版に基づき特徴写像を近似する。 Kernelized Attention のモチベーション(2 / 2) 𝑑 次元の入力を 𝑚 次元の特徴にする。 𝑤1 , ⋯ , 𝑤𝑚 は 𝑑 次元の標準正規分布から独立にサンプリングしたランダムベクトル。 8
Kernelized Attention は長い系列に Transformer を適用したいとき有力 だが、より工夫が凝らされたセルフアテンションも近似できるかは不明。 今回のモチベーション 𝑧𝑖 = σ𝑗=1
𝑛 exp 1 𝑑 𝑞𝑖 𝑘𝑗 T− 𝑏𝑗−𝑖 𝑣𝑗 σ 𝑗′=1 𝑛 exp 1 𝑑 𝑞𝑖 𝑘 𝑗′ T− 𝑏 𝑗′−𝑖 [ColinRaffel+2020] 方式の RPE を採用したセルフアテンションはこう。 相対位置に依存するバイアス (学習対象) これは RPE がない場合のセルフアテンションより表現力が高い (命題 1.) ため (というよりそもそも学習対象パラメータを含んでいる) 、以下の形に近似 して計算量削減することができない。 9 今回はそのようなセルフアテンションの例として知られる相対位置エン コーディング (RPE) を考える。 𝑧𝑖 = σ𝑗=1 𝑛 𝜙 𝑞𝑖 𝜙 𝑘𝑗 T 𝑣𝑗 σ 𝑗′=1 𝑛 𝜙 𝑞𝑖 𝜙 𝑘 𝑗′ T = 𝜙 𝑞𝑖 σ𝑗=1 𝑛 𝜙 𝑘𝑗 T 𝑣𝑗 𝜙 𝑞𝑖 σ 𝑗′=1 𝑛 𝜙 𝑘 𝑗′ T
相対位置に依存するバイアスは内積から分離する。 今回の手法 𝑧𝑖 = σ𝑗=1 𝑛 e𝑏𝑗−𝑖 𝜙 𝑞𝑖 𝜙
𝑘𝑗 T 𝑣𝑗 σ 𝑗′=1 𝑛 e 𝑏 𝑗′−𝑖 𝜙 𝑞𝑖 𝜙 𝑘 𝑗′ T = 𝜙 𝑞𝑖 σ𝑗=1 𝑛 e𝑏𝑗−𝑖 𝜙 𝑘𝑗 T 𝑣𝑗 𝜙 𝑞𝑖 σ 𝑗′=1 𝑛 e 𝑏 𝑗′−𝑖 𝜙 𝑘 𝑗′ T 10 しかしこの点線で囲んだ箇所は 𝑖 に依存している (使い回せない)。 点線で囲んだ箇所のすべての 𝑖 に対する値を並べたベクトルが (11) だが、 これは (12) (13) のように行列とベクトルの積にできる。が、この積を愚 直に計算すると計算量が 𝑂(𝑛2) になり意味がない。 だがここでは (12) (13) に出てくる行列がテプリッツ行列 (対角一定行列) であることから FFT を利用してこの積の演算を 𝑂(𝑛 log 𝑛) にできる。 しかし Kernelized Attention は訓練が不安定なことが経験的に知られて いる。 理論的に Kernelized Attention の近似誤差は 𝑞𝑖 , 𝑘1:𝑛 の L2ノルム に依存する (Theorem 3.)。そのため、𝑞𝑖 , 𝑘1:𝑛 をL2ノルムで正規化する。 FFT を利用 ―― toeplitz matrix vector multiplication fft 等で検索すると出る。行列を変形するのがミソ。
Key と Query の分布をそろえて セルフアテンションさせやすく Shujian Zhang, Xinjie Fan, Huangjie
Zheng, Korawat Tanwisuth, Mingyuan Zhou. Alignment Attention by Matching Key and Query Distributions. In Proceedings of NeurIPS 2021. 原題 • セルフアテンション自体をより効果的にしたい。 ⁃ 既存研究ではヘッド間で異なるアテンションをするように正則化するなど。 • 今回は「Query と Key が上手く巡り合うか」(語弊) という点に着目する。 ⁃ 通常のセルフアテンションの訓練には明示的に「Query が捉えやすいような Key にしよう」という働きはない。なので訓練時にヘッド内での Query と Key の分布の距離をペナルティする機構を導入する。 ⚬ AA-GAN: Query かどうか見分けるディスクリミネータを導入 (GAN)。 ⚬ AA-CT: Wasserstein 距離に基づくペナルティをより低コストに近似。 • 提案機構を ALBERT に適用すると、GLUE データセットタスクや SQuAD タスク の正解率が向上した。ドメイン間汎化や敵対的攻撃へのロバスト性の効果も。 ⚬ GLUE MRPC 同義判定タスクの正解率が 86.5% → 88.6% など。 • 単純な系列予測のようなタスクに対してはどうなるのか気になった。 11
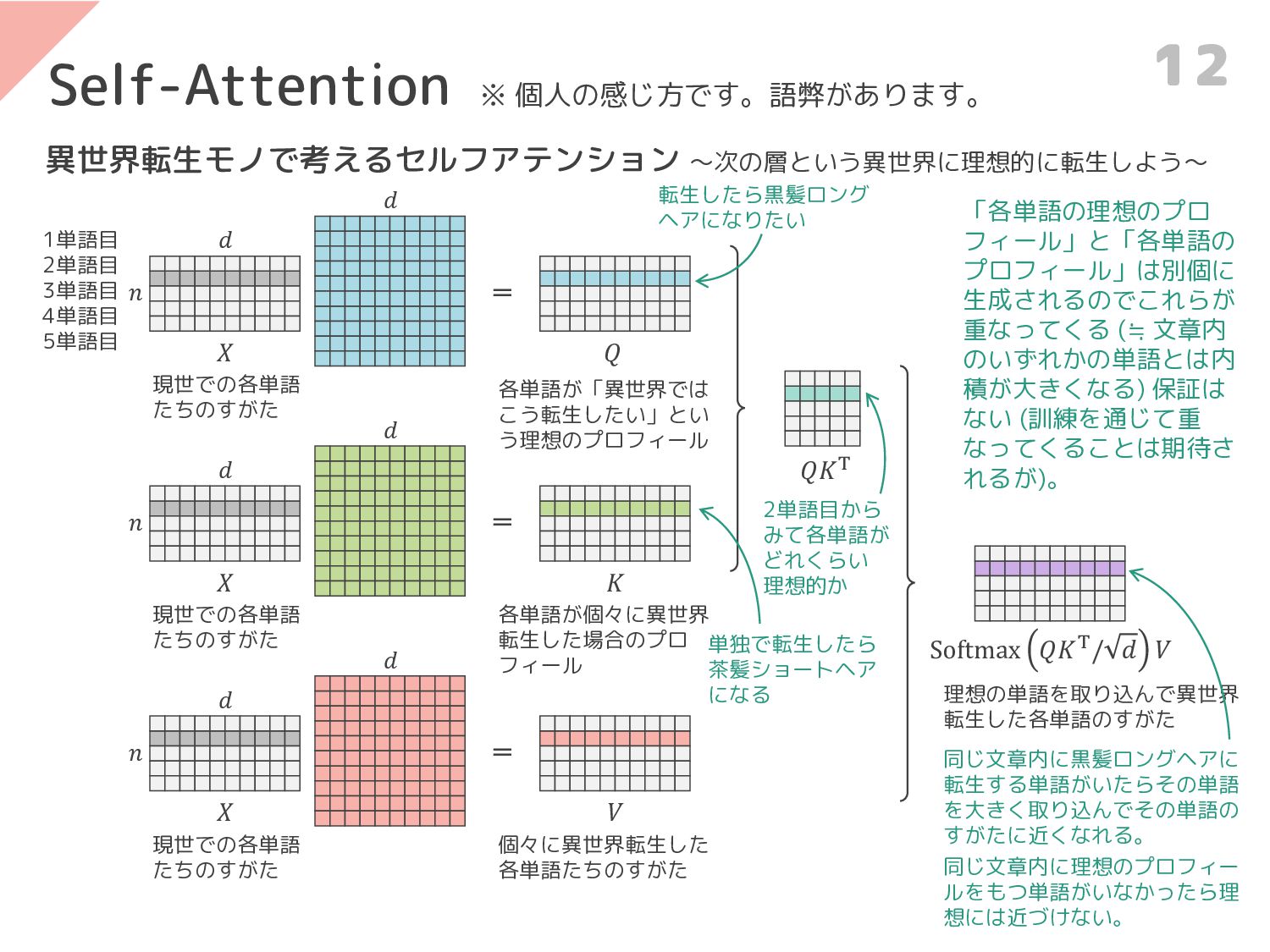
𝑑 = 𝑛 𝑑 𝑄 𝑑 = 𝑛 𝑑 𝐾
𝑄𝐾T 𝑑 = 𝑛 𝑑 𝑉 Softmax 𝑄𝐾T/ 𝑑 𝑉 異世界転生モノで考えるセルフアテンション ~次の層という異世界に理想的に転生しよう~ Self-Attention ※ 個人の感じ方です。語弊があります。 各単語が「異世界では こう転生したい」とい う理想のプロフィール 各単語が個々に異世界 転生した場合のプロ フィール 個々に異世界転生した 各単語たちのすがた 2単語目から みて各単語が どれくらい 理想的か 現世での各単語 たちのすがた 𝑋 現世での各単語 たちのすがた 𝑋 現世での各単語 たちのすがた 𝑋 理想の単語を取り込んで異世界 転生した各単語のすがた 12 1単語目 2単語目 3単語目 4単語目 5単語目 「各単語の理想のプロ フィール」と「各単語の プロフィール」は別個に 生成されるのでこれらが 重なってくる (≒ 文章内 のいずれかの単語とは内 積が大きくなる) 保証は ない (訓練を通じて重 なってくることは期待さ れるが)。 転生したら黒髪ロング ヘアになりたい 単独で転生したら 茶髪ショートヘア になる 同じ文章内に黒髪ロングヘアに 転生する単語がいたらその単語 を大きく取り込んでその単語の すがたに近くなれる。 同じ文章内に理想のプロフィー ルをもつ単語がいなかったら理 想には近づけない。
今回の手法 13 発想〈多分に想像を含む〉 例えば「青い顔をして (ショックを受けて)」といったときの「青い」の意味は 「顔」に依存しているので「青い」は「顔」に注意しその特徴を取り込む必要があ ると思われる。 「青い」に「こんな単語に注意したいです (Query)」というのを出させ、「顔」に 「わたしはこんな単語です
(Key)」というのを出させ、訓練を通じて両者が重なる ことを期待するのが通常のセルフアテンションである (と思われる)。 しかし、もっと積極的にヘッド内でクエリとキーが重なるようにしたほうが効果的 ではないかと思われる。 手法 Transformer の訓練時に Query と Key の分布を近づけるための機構が3つ提案され ている。 • Disctiminator-based modules ―― Query か見分けるディスクリミネータを導入 • Optimal transport-based modules • CT-based modules Figure 1. (a) 通常のアテンションの 𝑞, 𝑘 を T-SNE して可視化。 Figure 1. (b) 今回の手法のアテンションの 𝑞, 𝑘 を T-SNE して可視化。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}