Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
KDD2021の多変量時系列関連のタイトルいくつか
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
CookieBox26
August 28, 2021
320
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
KDD2021の多変量時系列関連のタイトルいくつか
CookieBox26
August 28, 2021
More Decks by CookieBox26
See All by CookieBox26
ずんだもんと雪さんとDeepSeek-R1-Zero
cookiebox26
0
1.4k
svm as a constrainted optimization
cookiebox26
0
120
最近のTransformer関連の論文から
cookiebox26
0
320
固有表現抽出をドメイン外の弱いラベリングたちから学習する
cookiebox26
0
120
Speech and Language Processing 9章 RNNによる系列の処理
cookiebox26
0
2.3k
LSTM to GRU
cookiebox26
0
300
Speech and Language Processing 5章 ロジスティック回帰
cookiebox26
0
370
「統計的因果推論」勉強会 「1. 古典的問題意識」
cookiebox26
0
950
レヴィ過程の経験尤度推定の紹介
cookiebox26
0
670
Featured
See All Featured
The untapped power of vector embeddings
frankvandijk
2
1.8k
A Guide to Academic Writing Using Generative AI - A Workshop
ks91
PRO
1
340
Taking LLMs out of the black box: A practical guide to human-in-the-loop distillation
inesmontani
PRO
3
2.3k
Jamie Indigo - Trashchat’s Guide to Black Boxes: Technical SEO Tactics for LLMs
techseoconnect
PRO
0
250
How to Create Impact in a Changing Tech Landscape [PerfNow 2023]
tammyeverts
55
3.4k
コードの90%をAIが書く世界で何が待っているのか / What awaits us in a world where 90% of the code is written by AI
rkaga
62
44k
Test your architecture with Archunit
thirion
1
2.3k
Context Engineering - Making Every Token Count
addyosmani
9
1k
The B2B funnel & how to create a winning content strategy
katarinadahlin
PRO
1
410
Become a Pro
speakerdeck
PRO
31
6k
Why Our Code Smells
bkeepers
PRO
340
58k
The Straight Up "How To Draw Better" Workshop
denniskardys
239
140k
Transcript
KDD2021の多変量時系列関連の タイトルいくつか Chihiro Mihara 私の誤りは私に帰属します。
2 トランスフォーマーを用いた多変量 時系列の表現学習 Representation Learning of Multivariate Time Series using
a Transformer Framework George Zerveas, Srideepika Jayaraman, Dhaval Patel, Anuradha Bhamidipaty, Carsten Eickhoff 原題 新しいと思った点・個人的感想 トランスフォーマーによる多変量時系列の事前学習の枠組みを初めて提 案している。特に、時系列データ向けにカスタマイズすべき点(正規化、 事前学習のマスク)をカスタマイズしその有効性の裏付けもとっている。 提案手法で学習したモデルは様々な多変量時系列の回帰・分類タスクで 既存モデルの性能を上回った。 マスクの仕方にもっと工夫の余地はないだろうか。 時空間データだったら空間方向のパターンも正規化したい。→ 2本目へ
先行研究 3 LogSparse Transformer [Li et al. 2019] トランスフォーマーを時系列データに応用する上で、アテンション Softmax(QK⊤/√d)
の計算量が系列長の2乗のオーダーになることがボ トルネックになる。→ アテンションを完全に計算することを避け、 「近くは綿密に、遠くにいくほど大雑把に」といった感じで間引く。 その他トランスフォーマーを時系列に適用した研究はあるが、ドメイン スペシフィックなものや、タスクスペシフィックなものが多い。 この研究ではトランスフォーマーを汎用的な時系列に適用できる手法を 目指す。
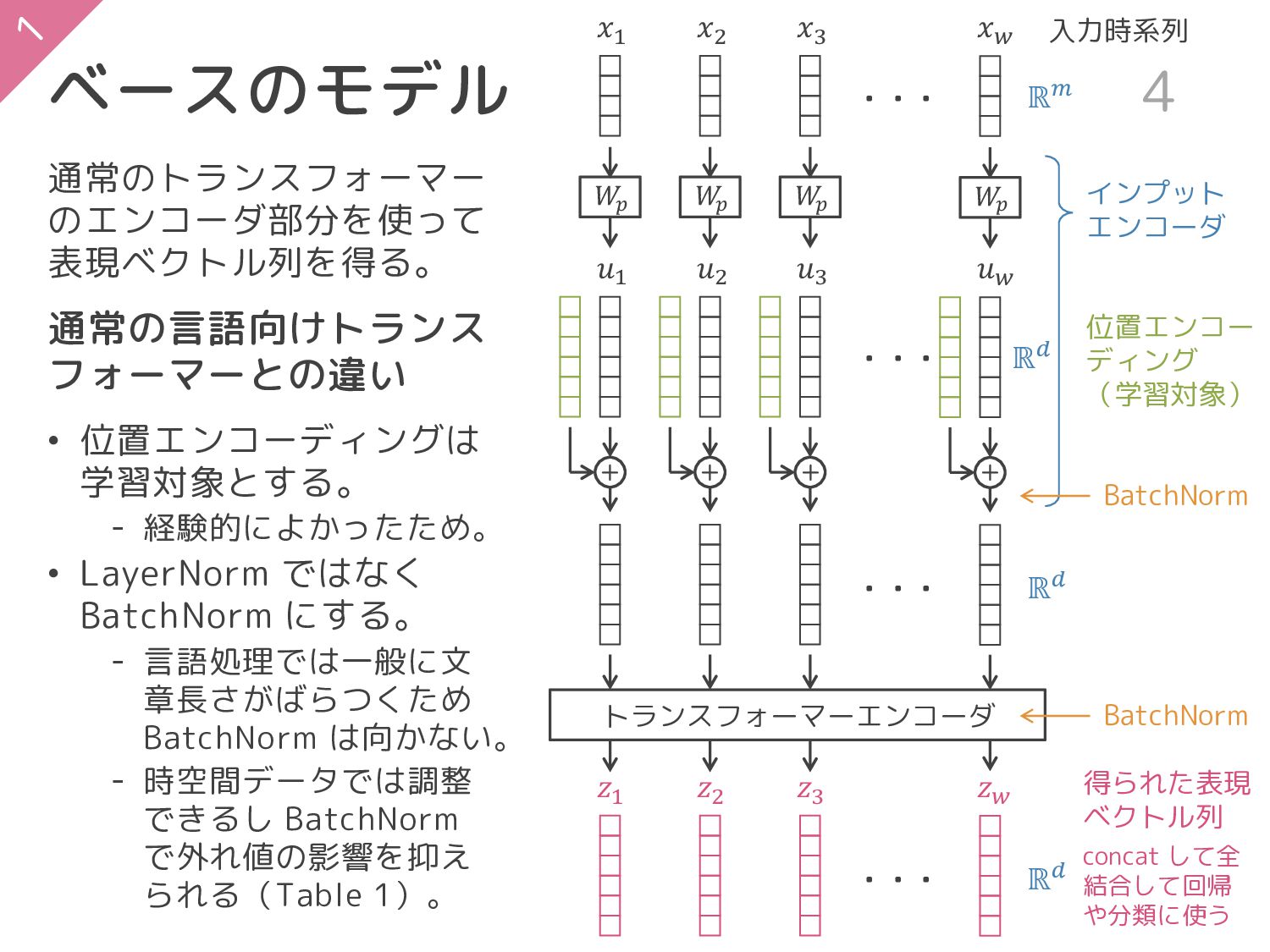
ベースのモデル 4 + + 𝑥1 𝑥2 𝑢1 𝑢2 トランスフォーマーエンコーダ 𝑧1
𝑧2 𝑊 𝑝 𝑊 𝑝 + 𝑥3 𝑢3 𝑧3 𝑊 𝑝 + 𝑥𝑤 𝑢𝑤 𝑧𝑤 𝑊 𝑝 ・・・ ・・・ ・・・ ・・・ 通常のトランスフォーマー のエンコーダ部分を使って 表現ベクトル列を得る。 通常の言語向けトランス フォーマーとの違い • 位置エンコーディングは 学習対象とする。 ‐ 経験的によかったため。 • LayerNorm ではなく BatchNorm にする。 ‐ 言語処理では一般に文 章長さがばらつくため BatchNorm は向かない。 ‐ 時空間データでは調整 できるし BatchNorm で外れ値の影響を抑え られる(Table 1)。 位置エンコー ディング (学習対象) インプット エンコーダ ℝ𝑚 ℝ𝑑 ℝ𝑑 ℝ𝑑 得られた表現 ベクトル列 concat して全 結合して回帰 や分類に使う BatchNorm BatchNorm 入力時系列
補足:LayerNorm と BatchNorm 5 LayerNorm 系列長 特徴次元数 BatchNorm 系列長 特徴次元数
言語処理ならば(位置や 前後の文脈を反映した) 単語ベクトルの正規化. 単語空間で方向のみが意 味をもつときの処理. 特徴によるスケールの差 の吸収、外れ値の抑制.
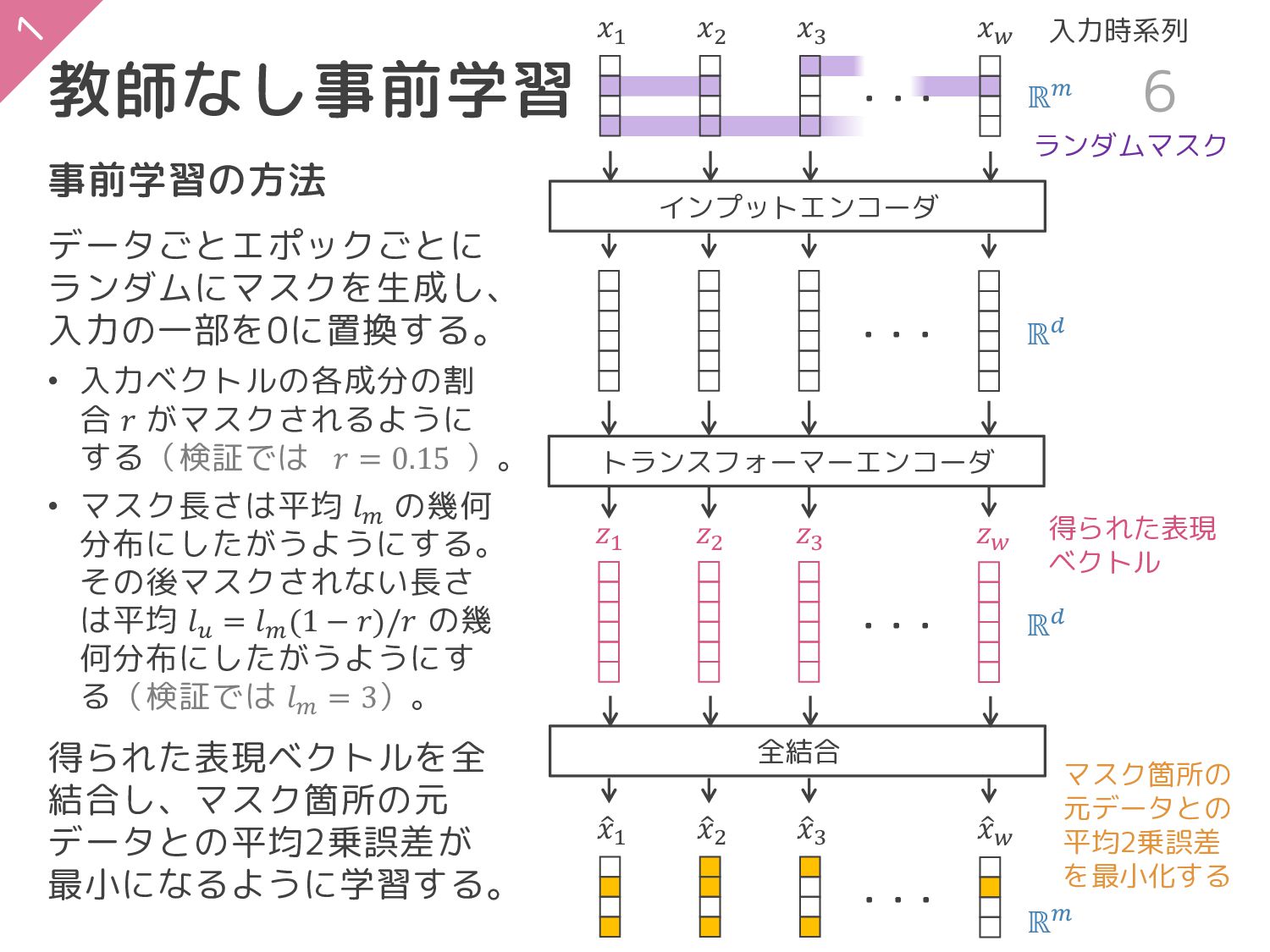
教師なし事前学習 6 𝑥1 𝑥2 トランスフォーマーエンコーダ 𝑧1 𝑧2 𝑥3 𝑧3 𝑥𝑤
𝑧𝑤 ・・・ ・・・ ・・・ 事前学習の方法 データごとエポックごとに ランダムにマスクを生成し、 入力の一部を0に置換する。 • 入力ベクトルの各成分の割 合 𝑟 がマスクされるように する(検証では 𝑟 = 0.15 )。 • マスク長さは平均 𝑙𝑚 の幾何 分布にしたがうようにする。 その後マスクされない長さ は平均 𝑙𝑢 = 𝑙𝑚 (1 − 𝑟)/𝑟 の幾 何分布にしたがうようにす る(検証では 𝑙𝑚 = 3)。 得られた表現ベクトルを全 結合し、マスク箇所の元 データとの平均2乗誤差が 最小になるように学習する。 ℝ𝑚 ℝ𝑑 ℝ𝑑 得られた表現 ベクトル インプットエンコーダ 全結合 ො 𝑥1 ො 𝑥2 ො 𝑥3 ො 𝑥𝑤 ・・・ ℝ𝑚 ランダムマスク マスク箇所の 元データとの 平均2乗誤差 を最小化する 入力時系列
言語処理でのマスクとの違い 7 BERTのような言語処理での「穴埋め」マスクとは以下が異なる。 1. ある特徴ベクトル全体をマスクするのではなく一部の成分をマスクする。 → 同時刻の成分間の依存関係も学習されることが期待される。 2. 一定の長さの区間をマスクする。→ 時系列では一定区間を連続してマスク
しないと復元がトリビアルになりがち(単に両隣の線形補間になるなど)。 実際、以下4パターンで4つ目のパターンが一番よかった(Table 3)。 𝑥1 𝑥2 𝑥3 𝑥𝑤 𝑥1 𝑥2 𝑥3 𝑥𝑤 𝑥1 𝑥2 𝑥3 𝑥𝑤 𝑥1 𝑥2 𝑥3 𝑥𝑤 Sync., Bern. Sep., Bern. Sync., Stateful Sep., Stateful … … … … ファインチューニング ファインチューニング時には出力層以外をフリーズするのではなく、全 てのパラメータを学習可能にするとよかった(Table 2)。 教師あり学習のみでの学習より収束も早く性能も上回った(Table 4, 5)。
検証 8 Monash University, UEA, UCR Time Series Regression and
Classification Archives から次元数、系列長、データ数、分類クラス 数、予測難度が多様になるように選定(回帰6タスク、分類11タスク)。 が、同名のアーカイブがあるのかわからない。似た名前のサーベイ論文はあり (Regression のみ)。個々のデータセットは探せばおそらくみつかる。クラス分類の InsectWingbeat(昆虫の鳴き声の音声からどの昆虫か分類するタスク)はここ。
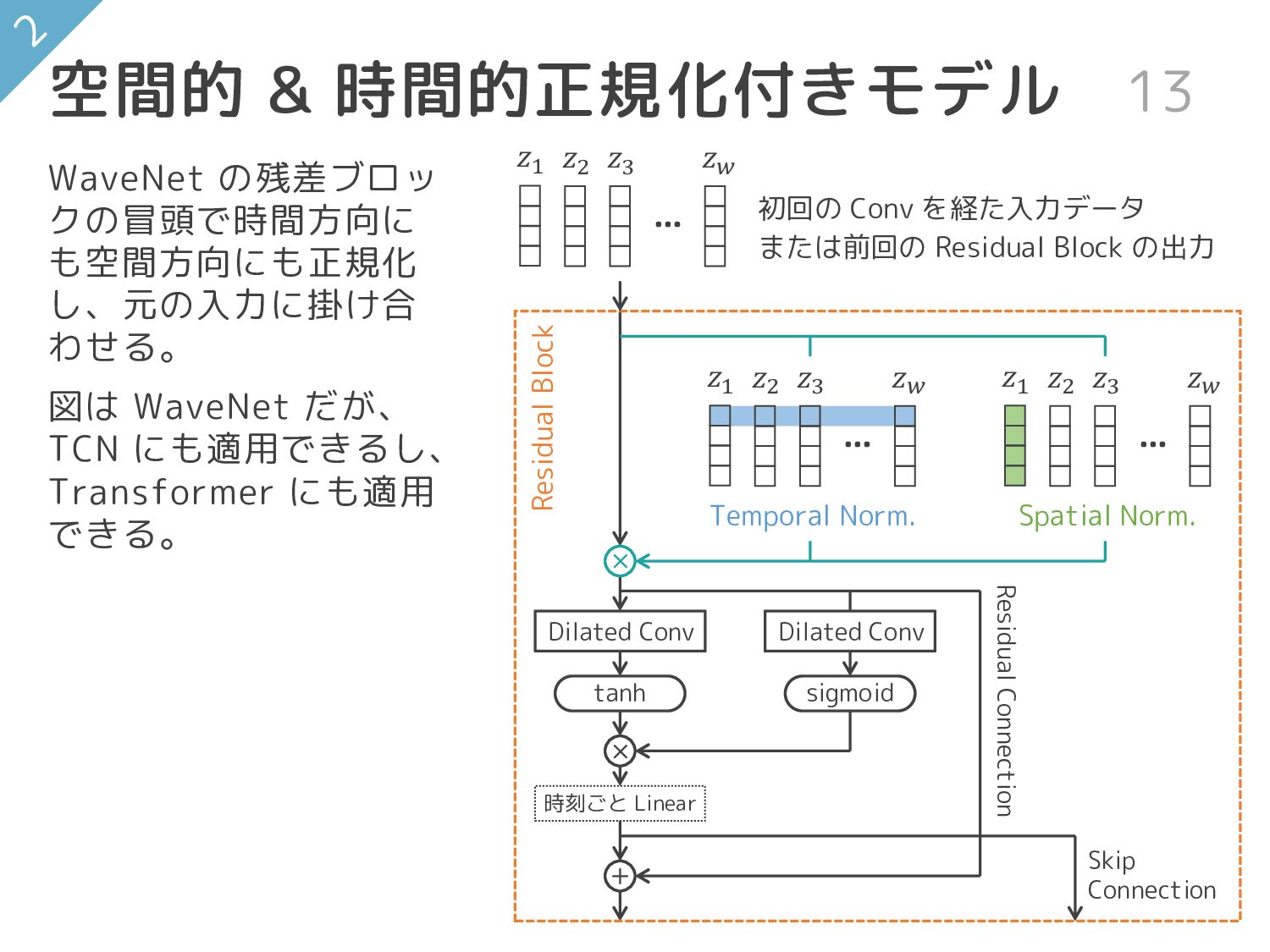
9 多変量時系列予測のための 空間的 & 時間的正規化 ST-Norm: Spatial and Temporal Normalization
for Multi-variate Time Series Forecasting Jinliang Deng, Xiusi Chen, Renhe Jiang, Xuan Song, Ivor W. Tsang 原題 新しいと思った点・個人的感想 何が時空間データ (空間方向にも時間方向にも広がりがあるデータ)の予 測のボトルネックになっているのかを考え、時間的周波数・空間的周波 数に目を付け、「時空間データであれば時間方向にも空間方向にも正規 化すべき」というアイデアを実装している(ST-Norm)。実際それで WaveNet などの系列モデルの学習性能を向上させている。 時間と空間でなくとも、データが2次元以上の配列(インデックスごと に何らかの意味をもつような)であったら適用できると思われる。 正規化のスパンを複数にすれば色々な周波数成分を拾えるのではないか。
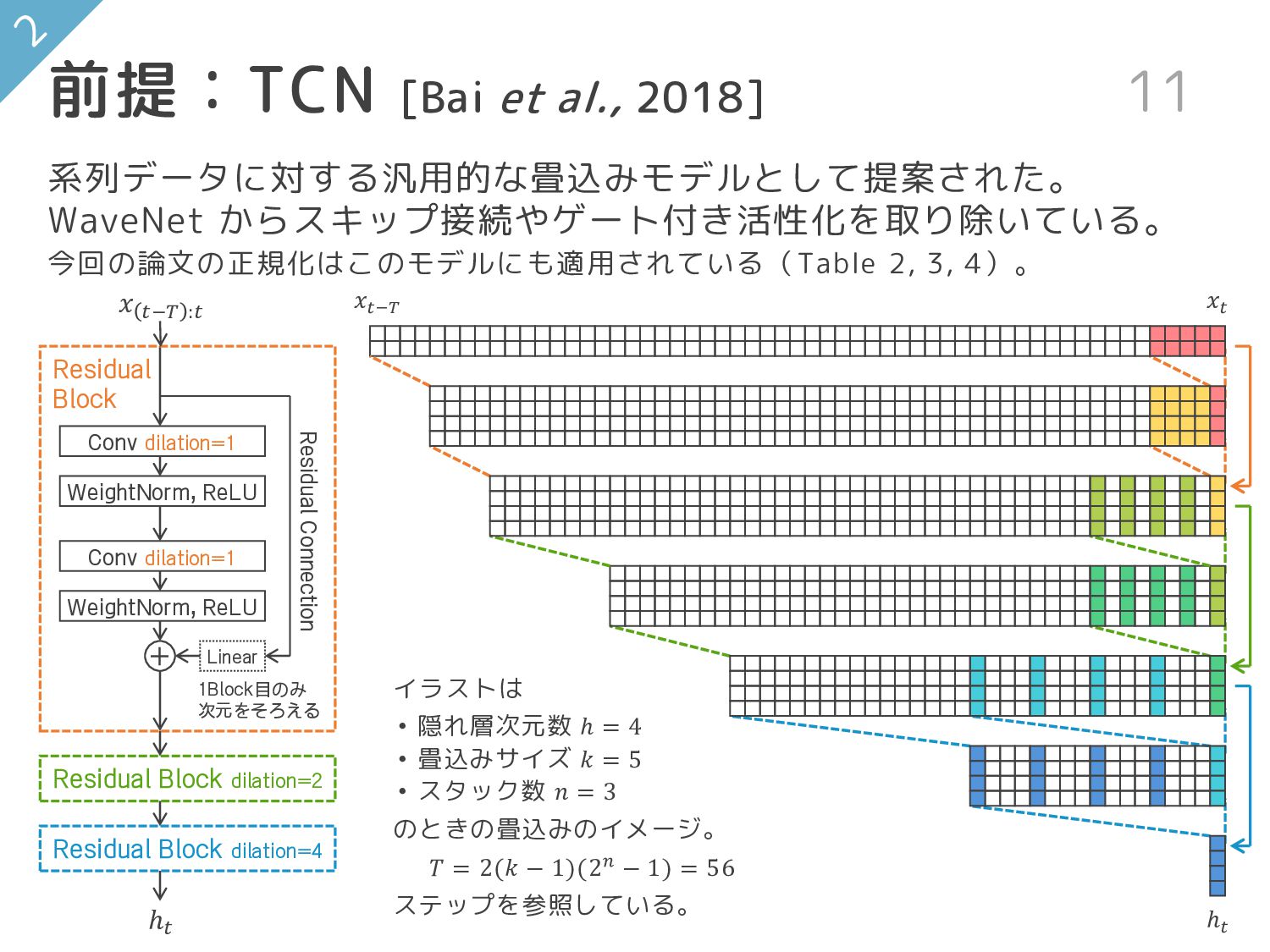
前提:WaveNet [van den Oord et al., 2016]10 + Conv dilation=1
Residual Connection Residual Block Residual Block dilation=2 Residual Block dilation=4 𝑥 𝑡−𝑇 :𝑡 自然な音声生成(Ex. テキスト読み上げ)を達成すべく「膨張畳込み (Dilated Conv)」「残差接続」「スキップ接続」「ゲート付活性化」 を盛り込んだ。今回の論文はこのモデルをベースに紹介している(Figure 3)。 𝑥𝑡 𝑥𝑡−𝑇 時刻ごと Linear Conv dilation=1 tanh sigmoid × ゲーティング + Skip Connection 𝑖 Block 目の Conv1D の dilation(膨張) を 2𝑖−1 にすることで広範囲を参照。 Dilated Conv Conv 1 2 3 4 5 ℎ 𝑡−𝑇 :𝑡 (1)
イラストは • 隠れ層次元数 ℎ = 4 • 畳込みサイズ 𝑘 =
5 • スタック数 𝑛 = 3 のときの畳込みのイメージ。 𝑇 = 2(𝑘 − 1)(2𝑛 − 1) = 56 ステップを参照している。 前提:TCN [Bai et al., 2018] 11 + Conv dilation=1 WeightNorm, ReLU WeightNorm, ReLU Residual Connection Conv dilation=1 Residual Block Residual Block dilation=2 Residual Block dilation=4 𝑥 𝑡−𝑇 :𝑡 ℎ𝑡 系列データに対する汎用的な畳込みモデルとして提案された。 WaveNet からスキップ接続やゲート付き活性化を取り除いている。 今回の論文の正規化はこのモデルにも適用されている(Table 2, 3, 4)。 ℎ𝑡 𝑥𝑡 𝑥𝑡−𝑇 Linear 1Block目のみ 次元をそろえる
12 問題意識 ある県での色々な地点での時間毎の交通量を予測したいとする。この とき訓練データが以下のようであったとする。 • 県内の地域Aでも地域Bでも午前7時から午前8時にかけては交通量が 増加する。が、その増加幅は地域Aの方が圧倒的に大きい。 • 平日でも土日でも午前7時から午前8時にかけては交通量が増加する。 が、その増加幅は平日の方が圧倒的に大きい。
このようなとき、地域Bでも/土日でも交通量が増加するという情報は 埋もれてしまうかもしれない。 増加幅が小さくても、それがいつも同じような状況でみられるか学習 したい。
13 𝑧1 𝑧2 𝑧3 𝑧𝑤 … 𝑧1 𝑧2 𝑧3 𝑧𝑤
… × 空間的 & 時間的正規化付きモデル Dilated Conv 𝑧1 𝑧2 𝑧3 𝑧𝑤 … Temporal Norm. Spatial Norm. × tanh sigmoid + Residual Block Dilated Conv Residual Connection 時刻ごと Linear Skip Connection 初回の Conv を経た入力データ または前回の Residual Block の出力 WaveNet の残差ブロッ クの冒頭で時間方向に も空間方向にも正規化 し、元の入力に掛け合 わせる。 図は WaveNet だが、 TCN にも適用できるし、 Transformer にも適用 できる。
14 ニューラルネットによる時空間 データ予測の不確かさの定量化 Quantifying Uncertainty in Deep Spatiotemporal Forecasting Dongxia
Wu, Liyao Gao, Matteo Chinazzi, Xinyue Xiong, Alessandro Vespignani, Yi-An Ma, Rose Yu 原題 新しいと思った点・個人的感想 不確かさも含めて予測する様々な手法を比較し、傾向を調べている。 なぜ同じ区間予測をしているのに手法間でそんなにばらつきが出てしま うのか。
概要 15 何かを予測するとき予測値だけでなくその予測がどれだけ不確かなのか もほしいことがある。判断を誤ると致命的なドメインでは重要。 ニューラルネットでも予測の不確かさを扱おうという研究は色々なされ てきた [17, 47, 55, 60]。
しかし、時空間データの予測の不確かさをどう扱うべきかという研究は あまりなされてこなかった。 そこで、色々なドメインの時空間データ (PM2.5, Traffic, COVID-19) を用いて、どのような手法が適するか検証した。 • PM2.5: グリッド状データ • Traffic, COVID-19: グラフ状データ 結果、以下のことがわかった。 • 平均値の予測の観点では確率的勾配MCMCが安定した性能を示す(点 予測の手法よりも)。 • 95%信頼区間(MIS: 平均インターバルスコア)の観点ではMIS回帰や 分位点回帰が有利だった。
{kind=link}
{kind=link}
![先行研究 3 LogSparse Transformer [Li et al. 2019] トランスフォーマーを時系列データに応用する上で、アテンション Softmax(QK⊤/√d)](https://files.speakerdeck.com/presentations/4cbe9918d92d44549277bb009468bd31/slide_2.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![前提:WaveNet [van den Oord et al., 2016]10 + Conv dilation=1](https://files.speakerdeck.com/presentations/4cbe9918d92d44549277bb009468bd31/slide_9.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![概要 15 何かを予測するとき予測値だけでなくその予測がどれだけ不確かなのか もほしいことがある。判断を誤ると致命的なドメインでは重要。 ニューラルネットでも予測の不確かさを扱おうという研究は色々なされ てきた [17, 47, 55, 60]。](https://files.speakerdeck.com/presentations/4cbe9918d92d44549277bb009468bd31/slide_14.jpg){kind=link}