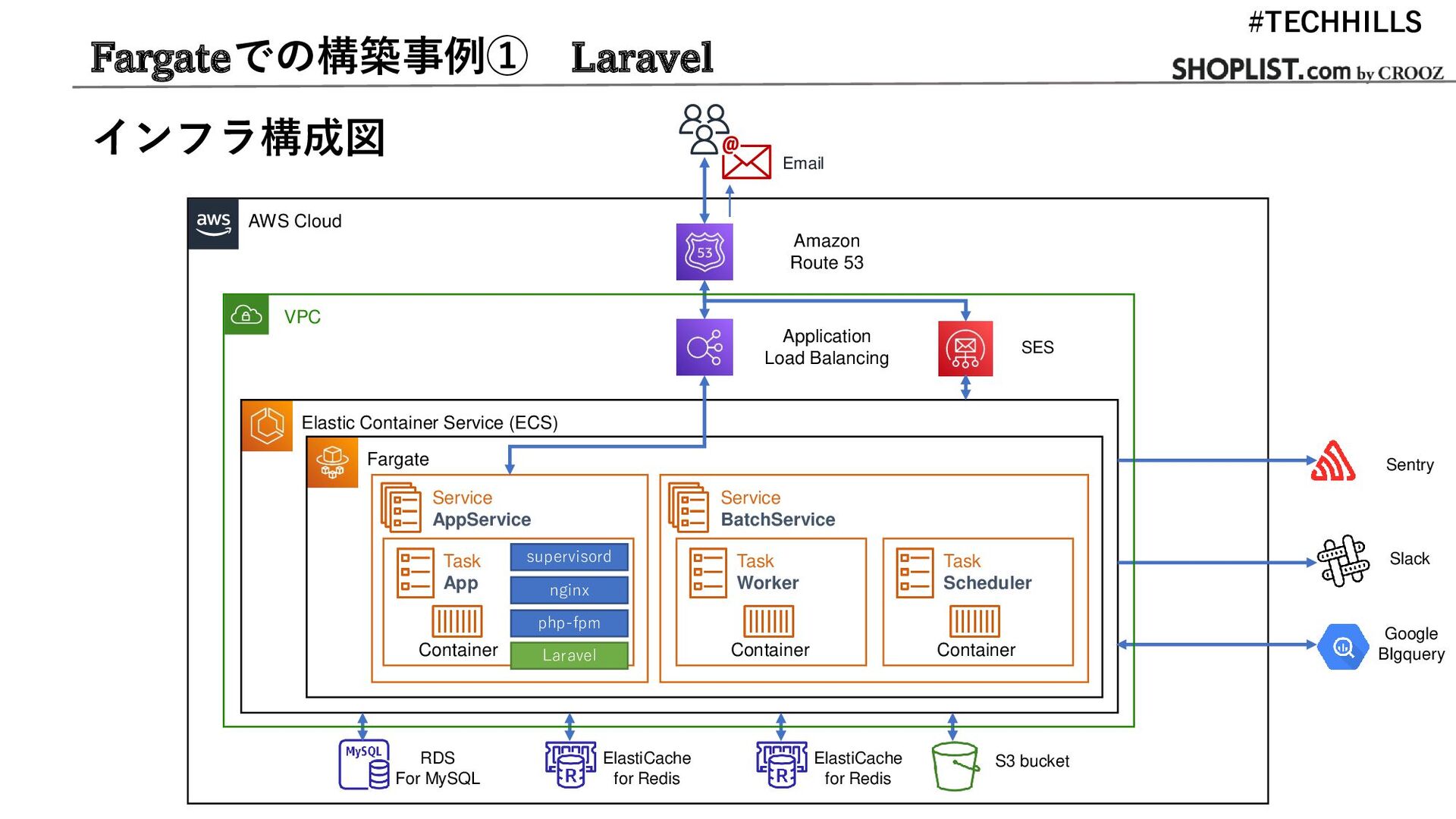
Application Load Balancing Elastic Container Service (ECS) Fargate Service AppService Service BatchService Task App Task Worker Task Scheduler Container Container RDS For MySQL ElastiCache for Redis SES Email Slack S3 bucket Google BIgquery ElastiCache for Redis Sentry VPC supervisord nginx php-fpm Laravel
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}