Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
CKE で始める!はじめての Kubernetes クラスタ インプレースアップグレード
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
Cybozu
PRO
February 27, 2020
Technology
3.2k
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
CKE で始める!はじめての Kubernetes クラスタ インプレースアップグレード
Cybozu
PRO
February 27, 2020
More Decks by Cybozu
See All by Cybozu
新卒1年目QAが リリース基準の"なぜ"をたどってみた
cybozuinsideout
PRO
1
390
サイボウズ 開発本部採用ピッチ / Cybozu Engineer Recruit
cybozuinsideout
PRO
10
83k
kintone リサーチ副部/UXリサーチャー 業務紹介
cybozuinsideout
PRO
0
110
私たちが『JaSST協賛』から『外部コネクト』チームになった理由
cybozuinsideout
PRO
0
390
LLMでもいつものテスト技術〜意外と半分はこれまでのテストでした〜
cybozuinsideout
PRO
1
970
kintone開発のプラットフォームエンジニアの紹介
cybozuinsideout
PRO
0
1.4k
LLMアプリの品質保証
cybozuinsideout
PRO
1
700
技術広報チームに丸投げしない!「一緒につくる」スポンサー活動
cybozuinsideout
PRO
0
260
テクニカルライター (グループウェア) について
cybozuinsideout
PRO
0
230
Other Decks in Technology
See All in Technology
Oracle Exadata Database Service on Cloud@Customer X11M (ExaDB-C@C) サービス概要
oracle4engineer
PRO
2
8.4k
「最後に責任を取るのはチーム」— 人間のPRレビューを最小化してアップデートしたメンタルモデル
jnishime_dresscode
0
420
「ちゃんとやっている」は独りよがりだった ― 不安に寄り添うインシデント対応へ / Towards incident response that addresses anxieties
chmikata
1
4.8k
SRE依存からの脱却 運用を開 発チームへ移す、 フルサイ クル開 発体制の実践
joooee0000
0
2.6k
クラウド上のデータ復旧で見落としがちな制約: 医療系 SaaS の BCP 設計から得た教訓
kakehashi
PRO
0
3.3k
KiCAD講習会②
tutcreators
0
110
ボーイスカウトルールでメモリやスキルを改善しよう
azukiazusa1
1
340
AIDLC_ヤフーショッピングの取り組み
lycorptech_jp
PRO
0
610
プライバシー保護の理論と実践
lycorptech_jp
PRO
1
250
Claude Codeとハーネスについて考えてみる
oikon48
18
9.3k
ゴールデンパスは敷いただけでは道にならない ─ 企画部門のエンジニアが技術標準を事業価値に変えるまで
mhrtech
0
120
“全部コピーしない”ファイルデータの活用 : — FSx for ONTAP × S3 Tables × Icebergで作るメタデータカタログ
yoshiki0705
0
710
Featured
See All Featured
HU Berlin: Industrial-Strength Natural Language Processing with spaCy and Prodigy
inesmontani
PRO
0
460
Efficient Content Optimization with Google Search Console & Apps Script
katarinadahlin
PRO
1
680
Faster Mobile Websites
deanohume
310
32k
DevOps and Value Stream Thinking: Enabling flow, efficiency and business value
helenjbeal
1
260
Amusing Abliteration
ianozsvald
1
220
Breaking role norms: Why Content Design is so much more than writing copy - Taylor Woolridge
uxyall
0
340
Lightning talk: Run Django tests with GitHub Actions
sabderemane
0
220
The Success of Rails: Ensuring Growth for the Next 100 Years
eileencodes
47
8.2k
How to Create Impact in a Changing Tech Landscape [PerfNow 2023]
tammyeverts
55
3.4k
Groundhog Day: Seeking Process in Gaming for Health
codingconduct
0
240
Building Adaptive Systems
keathley
44
3.1k
How To Speak Unicorn (iThemes Webinar)
marktimemedia
1
500
Transcript
Maneki & Neco Meetup CKE で始める︕ はじめての Kubernetes クラスタ インプレースアップグレード
2020-02-18 サイボウズ株式会社 ⽯井 正將 (masa213f)
発表タイトルについてのお詫び ▌チュートリアル的なタイトルですが チュートリアルではありません ▌Neco で実現している Kubernetes クラスタの アップグレード⽅法の説明になります 1
⾃⼰紹介 ▌サイボウズ ⼤阪オフィス勤務 • OSや仮想化に興味があったエンジニア ▌経歴 • 前職では、電機メーカーでOS・仮想化の開発 • 2018/09
サイボウズ キャリア⼊社 • 2019/03 運⽤本部 インフラ刷新プロジェクト Neco へ異動 2
質問 ▌Kubernetes v1.17 がリリースされました。 あなたの環境では Kubernetes v1.16 を使っています。 どうやって、Kubernetes クラスタを更新しますか︖
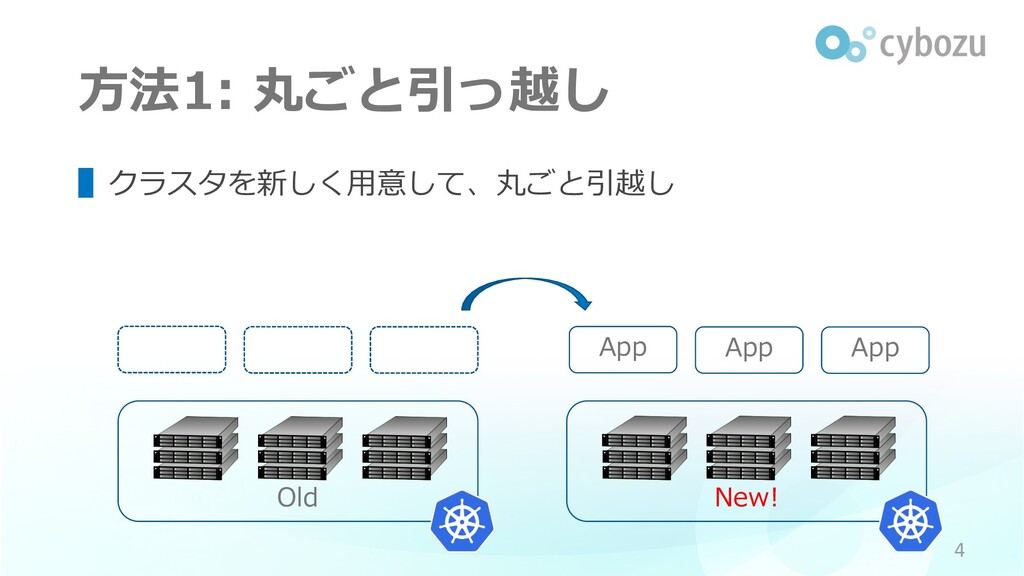
3 ▌よく聞く⽅法 1. クラスタを新しく⽤意して、丸ごと引っ越し 2. ノードを順番に更新して、ローリングアップグレード
⽅法1: 丸ごと引っ越し ▌クラスタを新しく⽤意して、丸ごと引越し Old 4 New! App App App
⽅法2: ローリングアップグレード ▌ノードを順番に更新し、ローリングアップグレード 5 App App App App App App
App App Old Old Old Old
⽅法2: ローリングアップグレード 1. 更新したいノードを kubectl drain ØPod が退去 (evict) &
そのノードへの Pod の配置が停⽌ 6 App App App App App App Old Old Old Old App App 更新したい kubectl drain
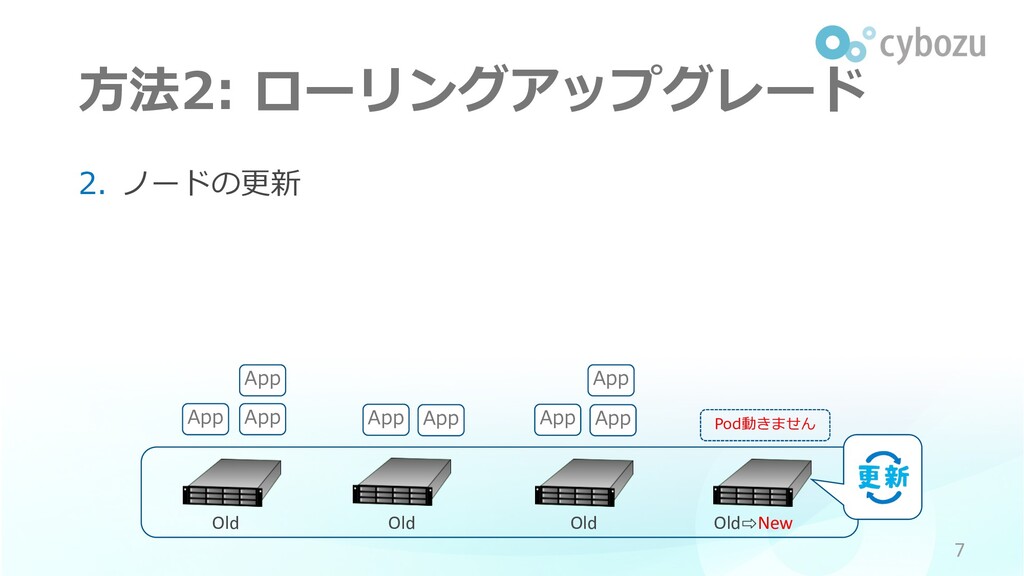
⽅法2: ローリングアップグレード 2. ノードの更新 7 App App App App App
App Old Old Old Old⇨New App App Pod動きません
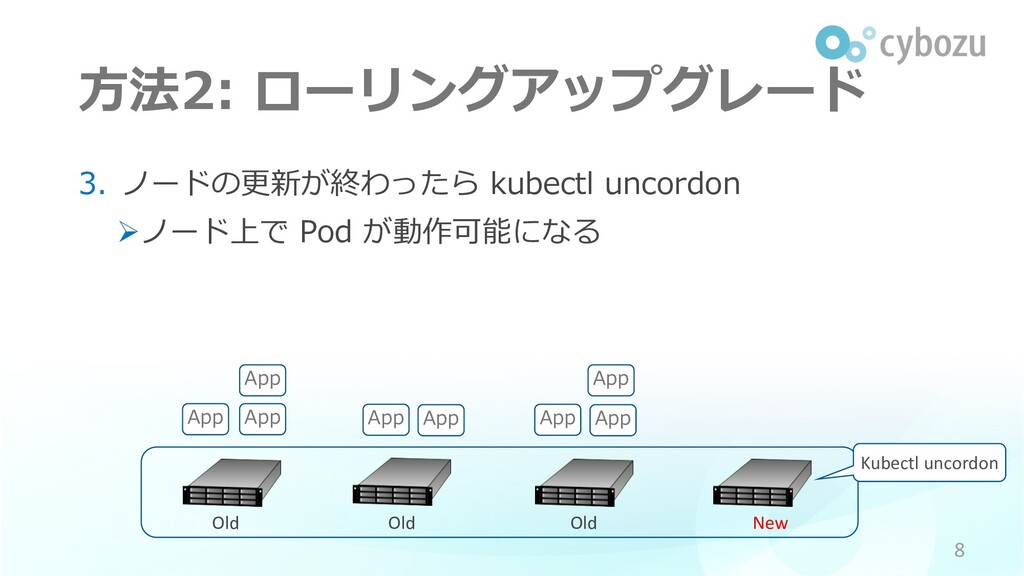
⽅法2: ローリングアップグレード 3. ノードの更新が終わったら kubectl uncordon Øノード上で Pod が動作可能になる 8
App App App App App App Old Old Old New App App Kubectl uncordon
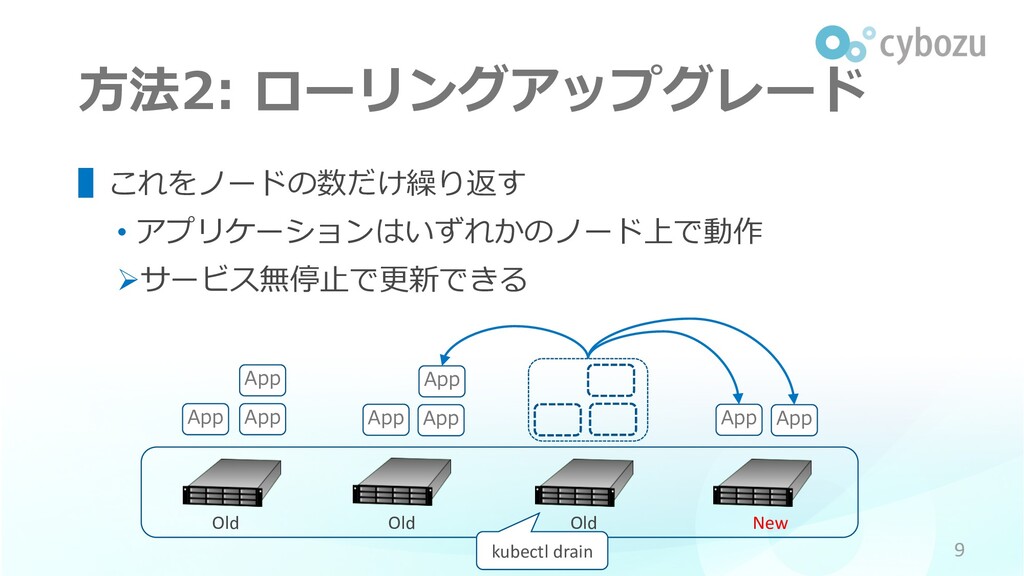
⽅法2: ローリングアップグレード 9 App App App App Old Old Old
New App App App App kubectl drain ▌これをノードの数だけ繰り返す • アプリケーションはいずれかのノード上で動作 Øサービス無停⽌で更新できる
これらの⽅法 ▌⽅法1、2は ノードのローカルストレージに データが保存されていない場合はうまくいく ▌Neco の Kubernetes クラスタは 少し事情が異なる Ø⾃社製
Kubernetes 管理ツール CKE で In-place Upgrade 10
CKE とは (Cybozu Kubernetes Engine) ▌サイボウズで開発している OSS ▌Kubernetes クラスタの構築と運⽤を⾃動化するソフトウェア ▌Kubernetes
Conformance Software に認定 詳しく知りたい⽅は、以下を参照ください。 n GitHub Ø https://github.com/cybozu-go/cke n CKEがKubernetes Conformance Softwareに認定されました – Cybozu Inside Out Ø https://blog.cybozu.io/entry/cke 11
Neco の Kubernetes ▌Storage on Kubernetes Øローカルストレージを多⽤する 2種類のサーバで構成 (CS、SS合わせて、1クラスタ数千台 ×
3 クラスタ) 1. CS (Compute Server) • ⾼速な CPU、SSD • AP サーバ、DBサーバ (更新頻度の⾼いデータを保存) として利⽤ 2. SS (Storage Server) • ⼤量の HDD • S3 互換のオブジェクトストレージ (更新頻度の低いデータを保存) として利⽤ 12
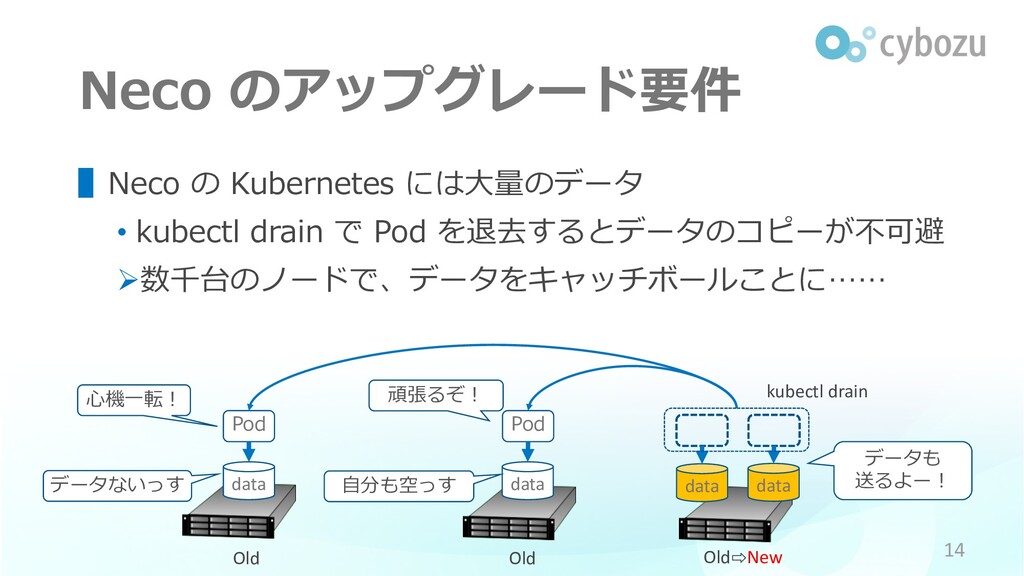
Neco のアップグレード要件 ▌Neco の Kubernetes には⼤量のデータ • アップグレードの度に サーバ間 and/or
クラスタ間で データのコピーはしたくない (ネットワークの負荷も上がるし、ディスクの寿命も縮まる) 13
Neco のアップグレード要件 ▌Neco の Kubernetes には⼤量のデータ • kubectl drain で
Pod を退去するとデータのコピーが不可避 Ø数千台のノードで、データをキャッチボールことに…… 14 data data Pod Pod ⼼機⼀転︕ 頑張るぞ︕ データも 送るよー︕ kubectl drain data data データないっす ⾃分も空っす Old Old Old⇨New
Neco のアップグレード要件 ▌クラスタのアップグレードでアプリケーションを⽌めたくない • 好きなタイミングで、⾃由に更新したい (夜は寝ていたい) 15
Neco のアップグレード要件 ▌Kubernetes は 3ヶ⽉に1度 マイナーアップデート • 陳腐化を防ぐために、追従していきたい Ø数千台のノードを、 3ヶ⽉毎に更新……
16
Neco のアップグレード要件 ▌まとめると 1. Eviction-free な In-place Upgrade • クラスタの作り直しなし
• ノードの⼊替なし • Pod の退去 (evict) なし 2. 加えて、(できるだけ) クラスタ無停⽌ 3. さらに加えて、(頻度が⾼いので) ⾃動化したい 17
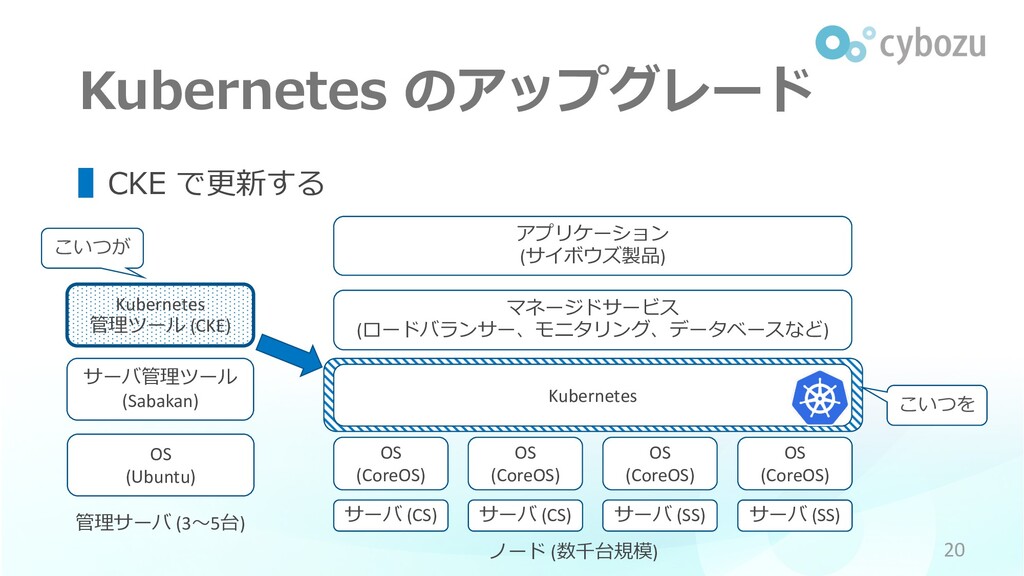
Neco の構成 OS (Ubuntu) 管理サーバ (3〜5台) サーバ管理ツール (Sabakan) Kubernetes 管理ツール
(CKE) Kubernetes ノード (数千台規模) マネージドサービス (ロードバランサー、モニタリング、データベースなど) ▌ざっくりとこんな構成 Neco Maneki + 製品開発 チーム 18 OS (CoreOS) アプリケーション (サイボウズ製品) サーバ (CS) サーバ (CS) サーバ (SS) サーバ (SS) OS (CoreOS) OS (CoreOS) OS (CoreOS)
どこをアップグレードしたい︖ ▌⼤まかに分類すると4種類 1. Pod (Kubernetes ワークロード) • マネージドサービス 2. Kubernetes
• Kubernetes コンポーネント 3. OS 4. (サーバの) ファームウェア 19 今⽇はココの説明
こいつを Kubernetes のアップグレード OS (Ubuntu) 管理サーバ (3〜5台) サーバ管理ツール (Sabakan) Kubernetes
管理ツール (CKE) Kubernetes ノード (数千台規模) マネージドサービス (ロードバランサー、モニタリング、データベースなど) ▌CKE で更新する 20 OS (CoreOS) アプリケーション (サイボウズ製品) サーバ (CS) サーバ (CS) サーバ (SS) サーバ (SS) OS (CoreOS) OS (CoreOS) OS (CoreOS) こいつが
Kubernetes の構成 ▌⼤きく分けると2種類のノード 1. Masterノード (3〜7台) • クラスタ全体を管理 (etcd /
kube-apiserver / kube-scheduler / kube-controller-manager ) 2. Workerノード (たくさん) • アプリケーション (Pod) の実⾏環境 ( kubelet / kube-proxy ) 21
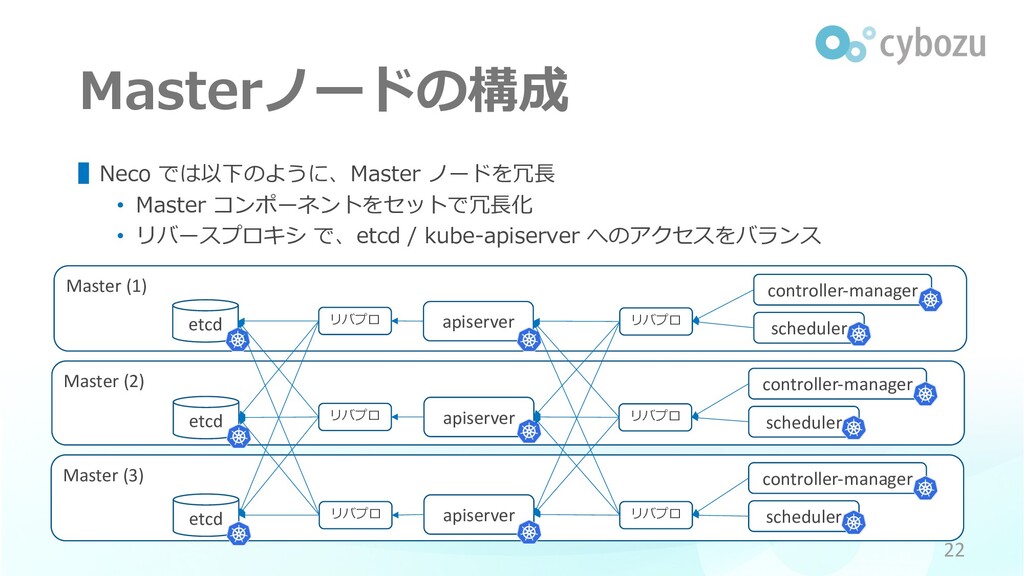
Master (3) Master (2) etcd Master (1) Masterノードの構成 apiserver ▌Neco
では以下のように、Master ノードを冗⻑ • Master コンポーネントをセットで冗⻑化 • リバースプロキシ で、etcd / kube-apiserver へのアクセスをバランス 22 scheduler controller-manager リバプロ etcd apiserver etcd apiserver リバプロ リバプロ リバプロ リバプロ リバプロ scheduler controller-manager scheduler controller-manager
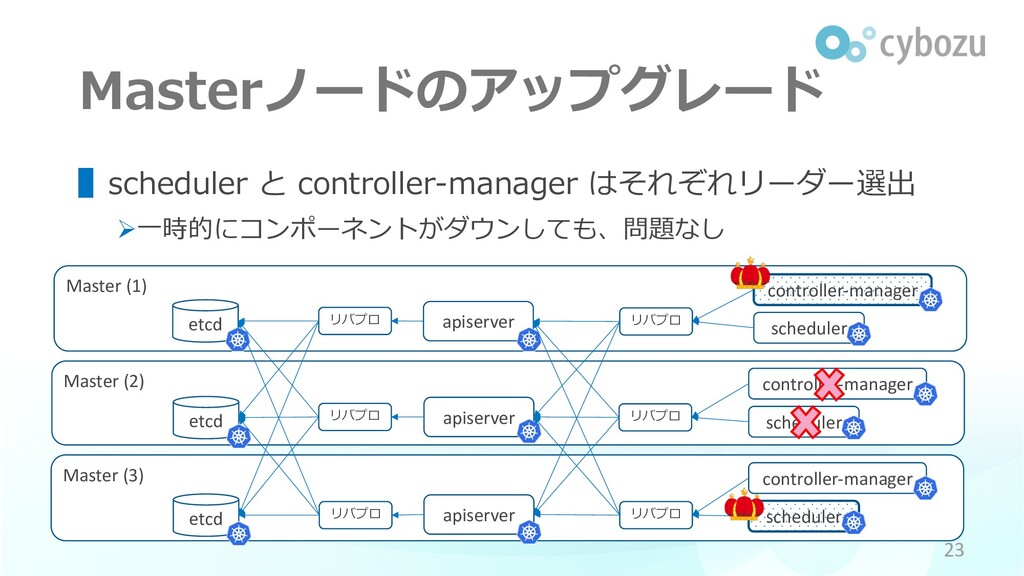
Master (3) Master (2) etcd Master (1) Masterノードのアップグレード apiserver ▌scheduler
と controller-manager はそれぞれリーダー選出 Ø⼀時的にコンポーネントがダウンしても、問題なし 23 scheduler controller-manager リバプロ etcd apiserver etcd apiserver リバプロ リバプロ リバプロ リバプロ リバプロ scheduler controller-manager scheduler controller-manager
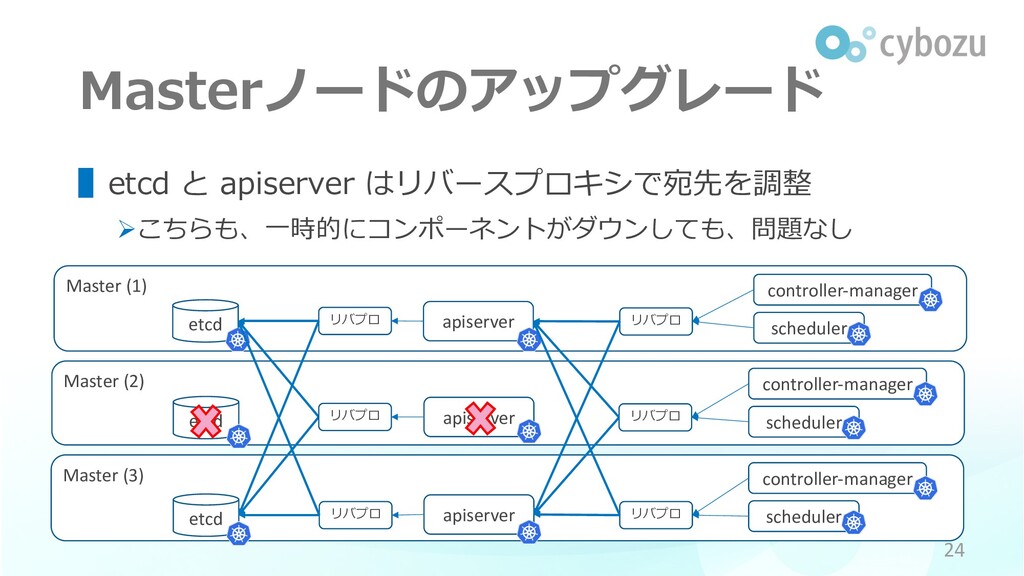
Master (3) Master (2) etcd Master (1) Masterノードのアップグレード apiserver ▌etcd
と apiserver はリバースプロキシで宛先を調整 Øこちらも、⼀時的にコンポーネントがダウンしても、問題なし 24 scheduler controller-manager リバプロ etcd apiserver etcd apiserver リバプロ リバプロ リバプロ リバプロ リバプロ scheduler controller-manager scheduler controller-manager
Masterノードのアップグレード ▌Master ノードの冗⻑化 & リバースプロキシでの経路制御 • Master コンポーネントが⼀時的にダウンしても Kubernetes クラスタの管理に影響はない
ØMaster ノードを順番に更新していけばよい 25
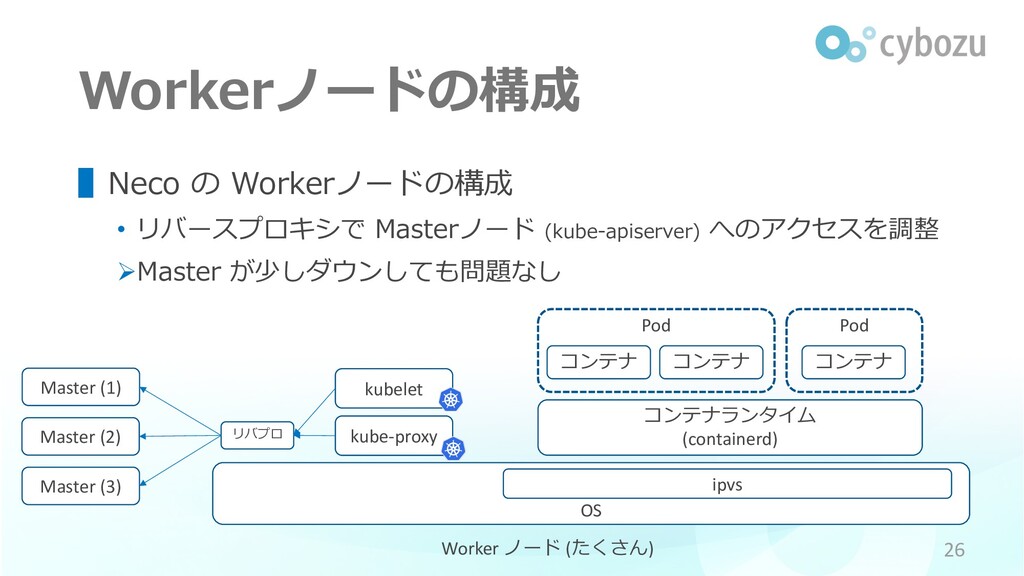
Pod Workerノードの構成 ▌Neco の Workerノードの構成 • リバースプロキシで Masterノード (kube-apiserver) へのアクセスを調整
ØMaster が少しダウンしても問題なし 26 OS Worker ノード (たくさん) kube-proxy kubelet ipvs コンテナ コンテナ コンテナランタイム (containerd) コンテナ Pod リバプロ Master (1) Master (2) Master (3)
Pod Workerノードのアップグレード ▌Kubernetes 上でアプリケーションが動く、と⾔うけれど どちらかというと、横からから⼩突いている 27 OS Worker ノード (たくさん)
kube-proxy kubelet ipvs コンテナ コンテナ コンテナランタイム (containerd) コンテナ Pod リバプロ Master (1) Master (2) Master (3) 起動/終了/監視 ルーティング設定
Workerノードのアップグレード ▌Kubernetes コンポーネントと Pod は別プロセス • Kubernetes コンポーネントが⼀時的にダウンしても Pod の動作に直ちに影響はない
Øダウンタイムを最⼩限にして、Pod に影響がでる前に 新しい kubelet / kube-proxy に⼊れ替えればいい 28
Workerノードのアップグレード ▌CKE では Kubernetes コンポーネントを Docker で起動 • 新しいコンテナイメージを事前に Pull
• 折を⾒て再起動 Øコンポーネントの再起動は⼗数秒、すぐにアップグレード完了 アプリケーションへの影響もなく、ノードの⼊替も不要 29
In-place Upgrade の注意点 ▌ただし • アップグレード前後で、⾮互換の変更があった場合 単純な再起動では済まないケースがある • その場合は、⾃⼒で頑張るしかない ▌Neco
の場合は 1. CKE が⾃社製ツールのため、改修が容易 2. 仮想クラスタ & Stage環境 でアップグレード試験を実施 Øだから、In-place Upgrade にチャレンジできている 30
まとめ • Neco は Storage on Kubernetes • ⾃社製ツール CKE
で Kubernetes クラスタの In-place Upgrade を実現 Øアプリケーションへの影響を最⼩限に Kubernetes クラスタをアップグレードできる 31
補⾜スライド
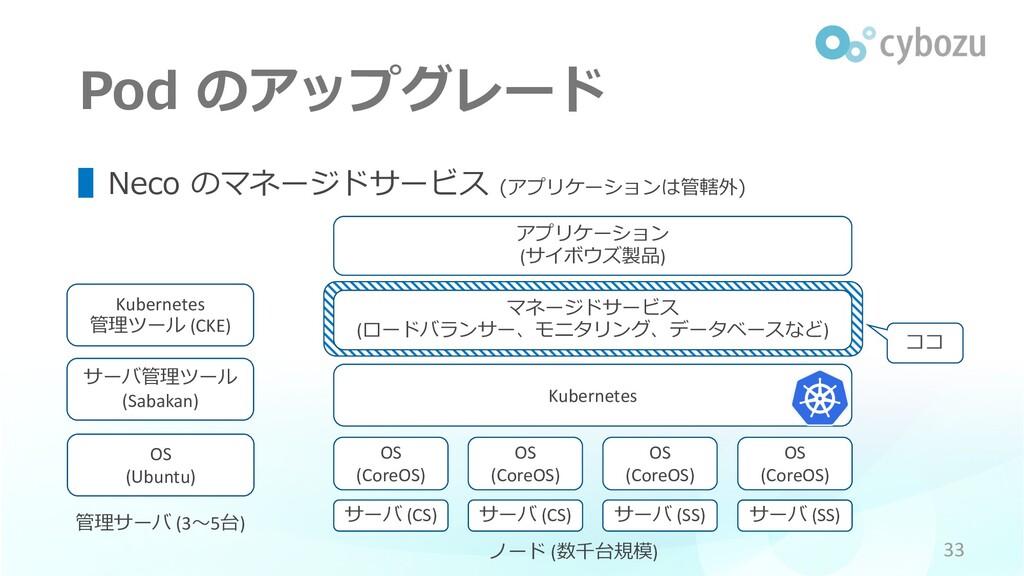
ココ Pod のアップグレード OS (Ubuntu) 管理サーバ (3〜5台) サーバ管理ツール (Sabakan) Kubernetes
管理ツール (CKE) Kubernetes ノード (数千台規模) マネージドサービス (ロードバランサー、モニタリング、データベースなど) ▌Neco のマネージドサービス (アプリケーションは管轄外) 33 OS (CoreOS) アプリケーション (サイボウズ製品) サーバ (CS) サーバ (CS) サーバ (SS) サーバ (SS) OS (CoreOS) OS (CoreOS) OS (CoreOS)
Pod のアップグレード ▌Neco のマネージドサービス • Kubernetes 的なやり⽅で頑張る 34
こいつを OS のアップグレード OS (Ubuntu) 管理サーバ (3〜5台) サーバ管理ツール (Sabakan) Kubernetes
管理ツール (CKE) Kubernetes ノード (数千台規模) マネージドサービス (ロードバランサー、モニタリング、データベースなど) ▌Sabakan によるプロビジョニング 35 OS (CoreOS) アプリケーション (サイボウズ製品) サーバ (CS) サーバ (CS) サーバ (SS) サーバ (SS) OS (CoreOS) OS (CoreOS) OS (CoreOS) こいつが
OS のアップグレード ▌Sabakan によるプロビジョニング • Core OS をネットワークブート • Ignition
でノード別に設定をカスタマイズ Øノードを再起動するだけで、OS が新しくなる︕ ▌ただし、再起動の間は そのノード上で動くアプリケーションのタウンタイムが発⽣ Øデータの冗⻑化 & Pod の分散配置で対応 36
データの冗⻑化 & Pod の分散配置 ▌DB でクラスタを組み、データを冗⻑化 • Rook/Ceph、Elasticsearh、MySQL のクラスタ ▌ただ、それだけでは不⼗分
ØPod の配置に偏りがでるかもしれない ノード1 カン︕ 37 Pod data Pod data Pod data Pod data ノード2 ノード3 ノード4
データの冗⻑化 & Pod の分散配置 ▌Topology Spread Constraints (Kubernetes v1.16〜) •
複数の Failure domain に Pod を分散配置 Øノードを再起動しても問題なし、耐障害性も向上 ラック1 ラック2 ラック3 ラック4 ラック1がやられたようだな やつは最弱 38 data data data data
ココ ファームウェアのアップグレード OS (Ubuntu) 管理サーバ (3〜5台) サーバ管理ツール (Sabakan) Kubernetes 管理ツール
(CKE) Kubernetes ノード (数千台規模) マネージドサービス (ロードバランサー、モニタリング、データベースなど) ▌ファームウェアアップグレードの⾃動化はこれから…… 39 OS (CoreOS) アプリケーション (サイボウズ製品) サーバ (CS) サーバ (CS) サーバ (SS) サーバ (SS) OS (CoreOS) OS (CoreOS) OS (CoreOS)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}