election process. Understand the dynamics of failover! It’s not magic; there are rules & gotchas. Vulnerable to false positives in the real world network flaps, high load failover
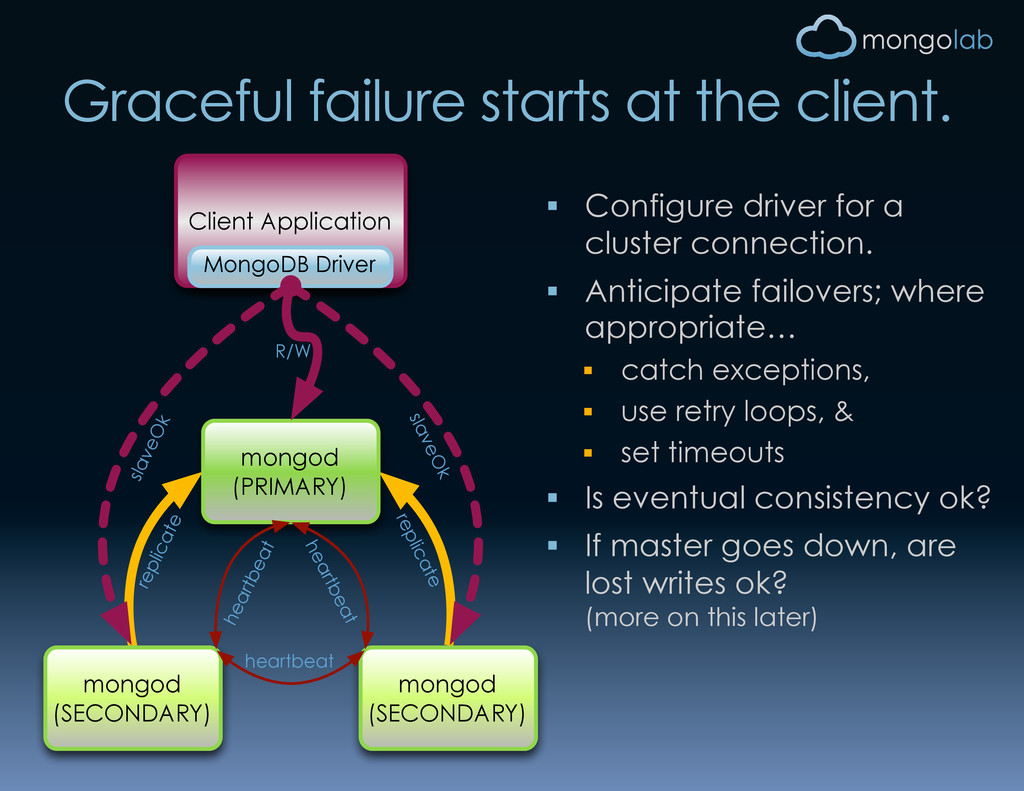
mongod (SECONDARY) mongod (PRIMARY) heartbeat heartbeat heartbeat Client Application MongoDB Driver slaveOk slaveOk R/W Configure driver for a cluster connection. Anticipate failovers; where appropriate… catch exceptions, use retry loops, & set timeouts Is eventual consistency ok? If master goes down, are lost writes ok? (more on this later)
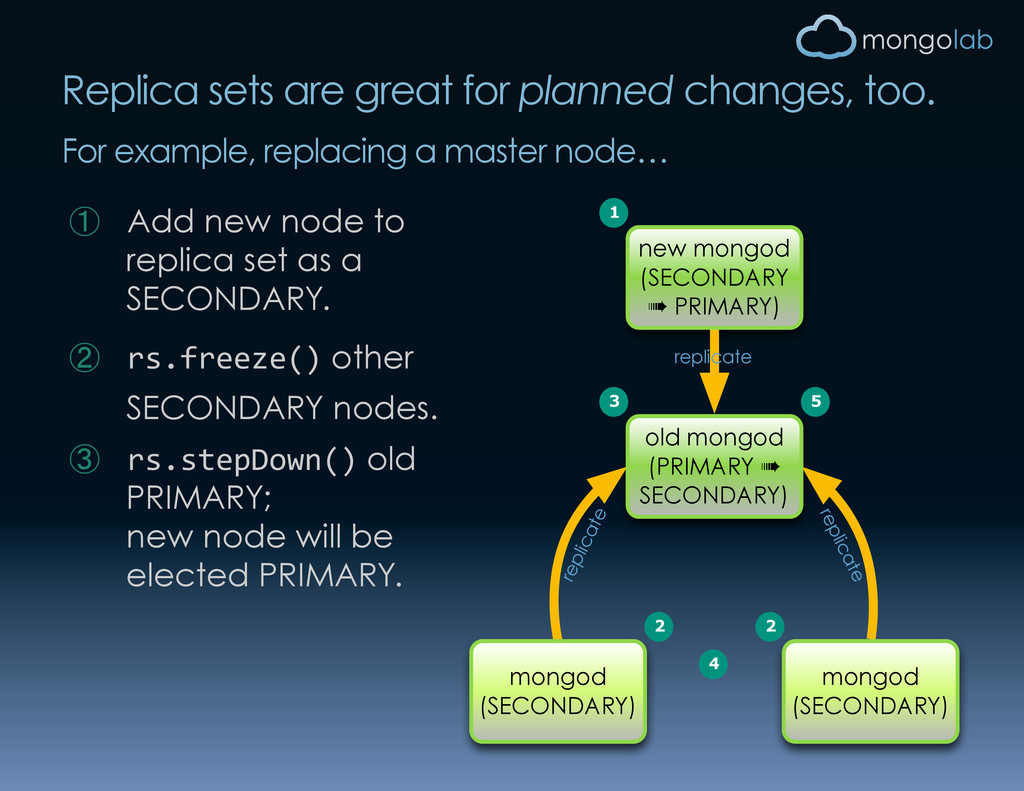
replacing a master node… ① Add new node to replica set as a SECONDARY. ② rs.freeze() other SECONDARY nodes. ③ rs.stepDown() old PRIMARY; new node will be elected PRIMARY. replicate replicate mongod (SECONDARY) mongod (SECONDARY) old mongod (PRIMARY ➠ SECONDARY) new mongod (SECONDARY ➠ PRIMARY) replicate 1 2 3 4 5 2
gone) new mongod (PRIMARY) 4 5 4 …then take the old master offline. Properly configured clients will hardly notice the switch. ④ [optional] Unfreeze the nodes from (2). ⑤ rs.remove() old node from the replica set. (Needlessly complex if we can live for a bit without 1/N of the throughput. Just take node offline & upgrade in place!)
indexes mean the difference between fast, slow, and toast. Many page faults per query can kill the server. Even with entire working set in RAM, scanning a collection ⇒ O(n) more cycles per query. But don’t overcompensate. Each index increases insert latency and memory footprint. Nonselective indexes are worse than useless. e.g., indexing on a field with values ∊ { 0, 1 }
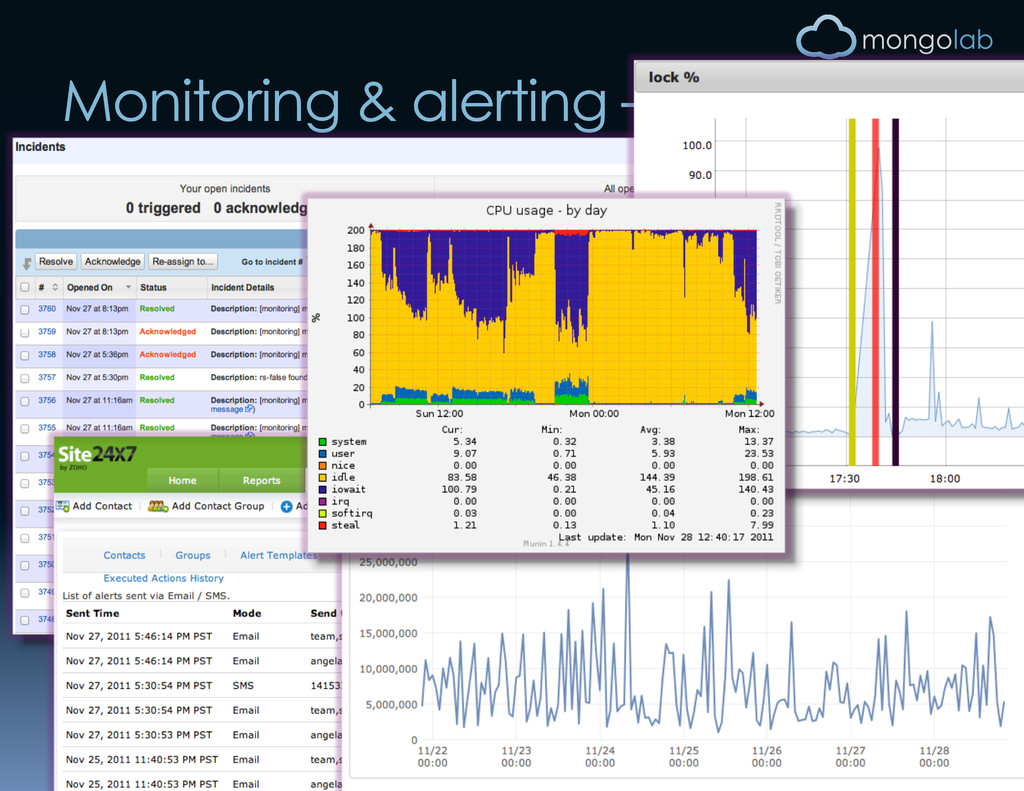
TOGWL™ lots of write cycles this can ruin your day. build indexes in the background! B-tree rebalancing: the silent killer. Holding lock + no indexes very bad e.g., findAndModify with poor/no index Troubleshooting : mongostat 5 large #s in “faults” col see “index” slides large #s in “wq|rq” col who’s got the lock?
crash will leave databases intact. Allows one to snapshot files without locking server. On by default in 2.0; use -‐-‐journal in 1.8 Tip ☞ Keep 3 pre-allocated 1GB journal files on the spindle for a quicker restart. Tip ☞ In non-production setting, restart without journaling for any big, disposable data load. e.g., mongoimport, full resync, etc. to do this in 2.0, use -‐-‐nojournal
PRIMARY has enough load already. Approaches[1]: 1. fsync, lock, cp 2. mongodump when in doubt, -‐-‐forceTableScan -‐-‐oplog point-in-time for whole server 3. point-in-time fs snapshot (EBS or LVM) Store in a safe place (e.g., S3) Consider frequency & retention e.g., keep 5 dailies and 3 weeklies
boost performance means “slave if at all possible” – master won’t contribute to read throughput if any slaves are available. “Eventual consistency” data from previous writes may not be there yet.
TOGWL™. Durability: mutations not guaranteed to persist until they reside on the disks of a majority of nodes. In the event of a failover, is there anything to be concerned about? Let’s look at an example …
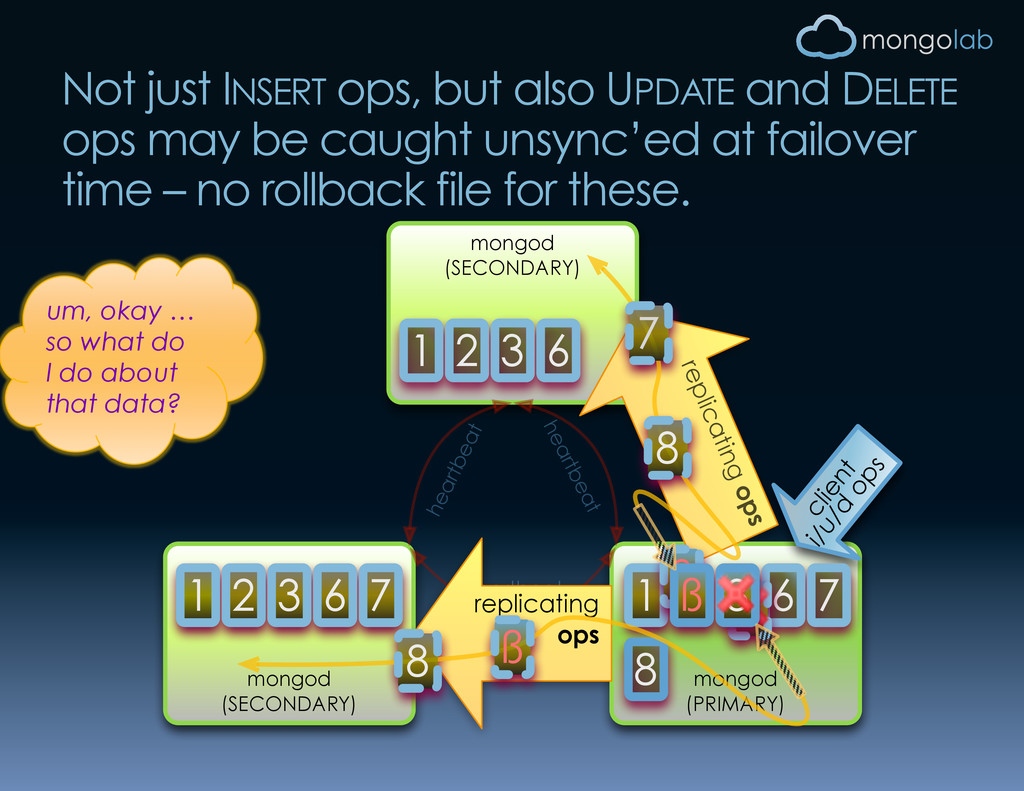
heartbeat 10278 dbclient error communicating with server 10278 dbclient error communicating with server client inserts 3 2 1 2 1 1 2 3 4 5 election time! Master can become unreachable before slave replicates all data…
heartbeat replicating ops 1 2 1 1 2 3 6 3 6 7 6 7 client i/u/d ops 3 ß 8 ß 3 8 ß 7 8 Not just INSERT ops, but also UPDATE and DELETE ops may be caught unsync’ed at failover time – no rollback file for these. um, okay … so what do I do about that data?
must cope. For reads: slaveOk not okay For writes: Set w > ( N / 2.0 ) w: “majority” does this automagically in 2.0 But cluster will be less available & slower. CAP theorem (q.v.) does apply to you as well. For thus have the wise men blogged.
1, w : 2 } ⇒ deliver to 2 nodes before returning For all but the 1st node, “delivered” is in the TCP/IP sense of the word; the written op isn’t on a node’s disk until the next journal “group commit”. Durable from there. replicate replicate mongod (SECONDARY) mongod (SECONDARY) mongod (PRIMARY) heartbeat heartbeat heartbeat Client Application MongoDB Driver slaveOk slaveOk R/W
mongomunich-2011/learning-by-doing- running-a-mongodb-the-hard-way Operations Understanding MongoDB & Keeping it Happy Brendan McAdams 10gen, Inc. [email protected] @rit Monday, October 10, 11 Learning by doing - running a mongoDB, the hard way 10.10.2011 – 10gen Mongo Munich, Sandro Grundmann
{kind=link}
![Who am I? Todd O. Dampier [email protected] @t0dampier CTO](https://files.speakerdeck.com/presentations/4edc4e308a72e3004d00d3d1/slide_1.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}