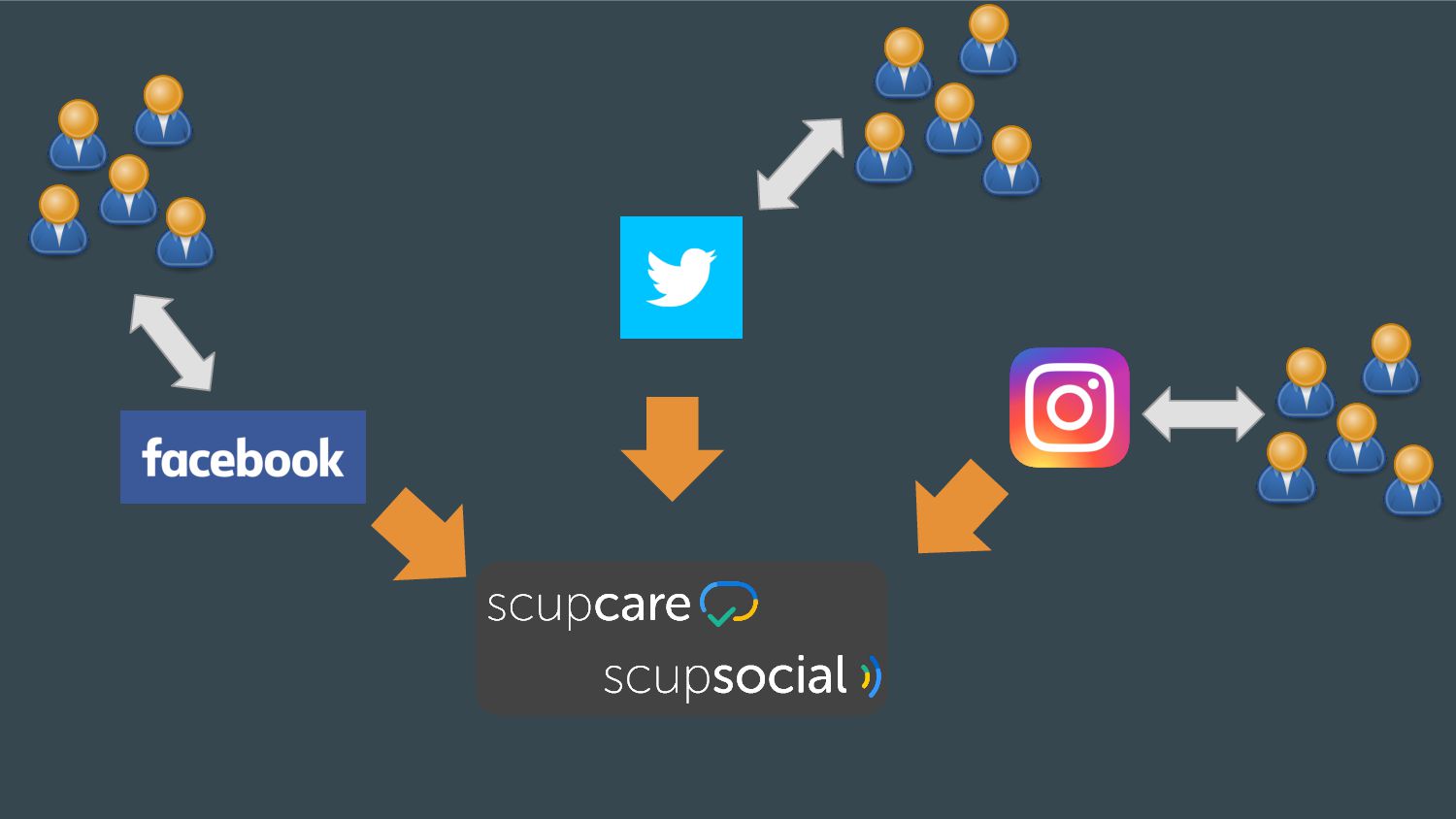
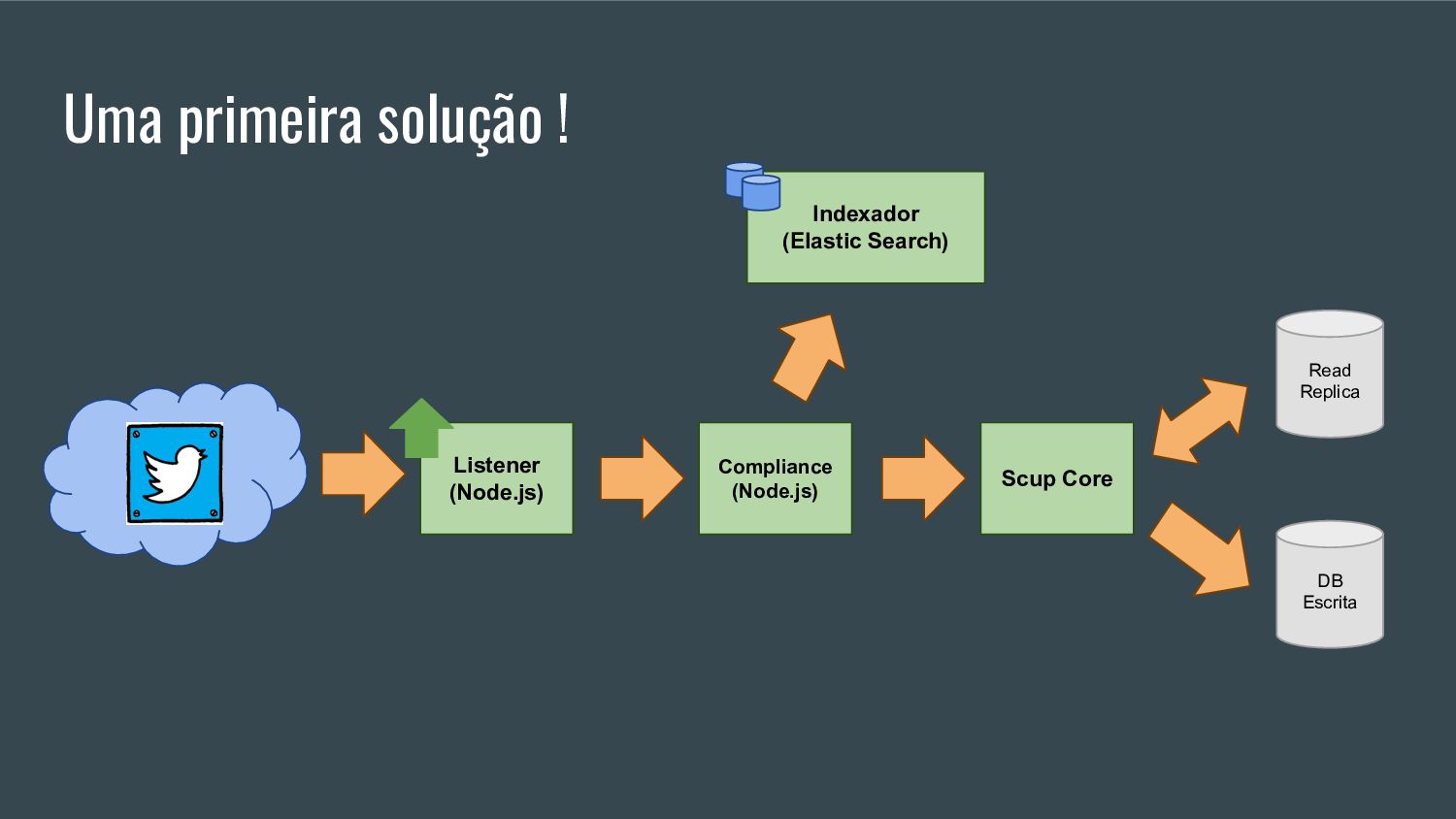
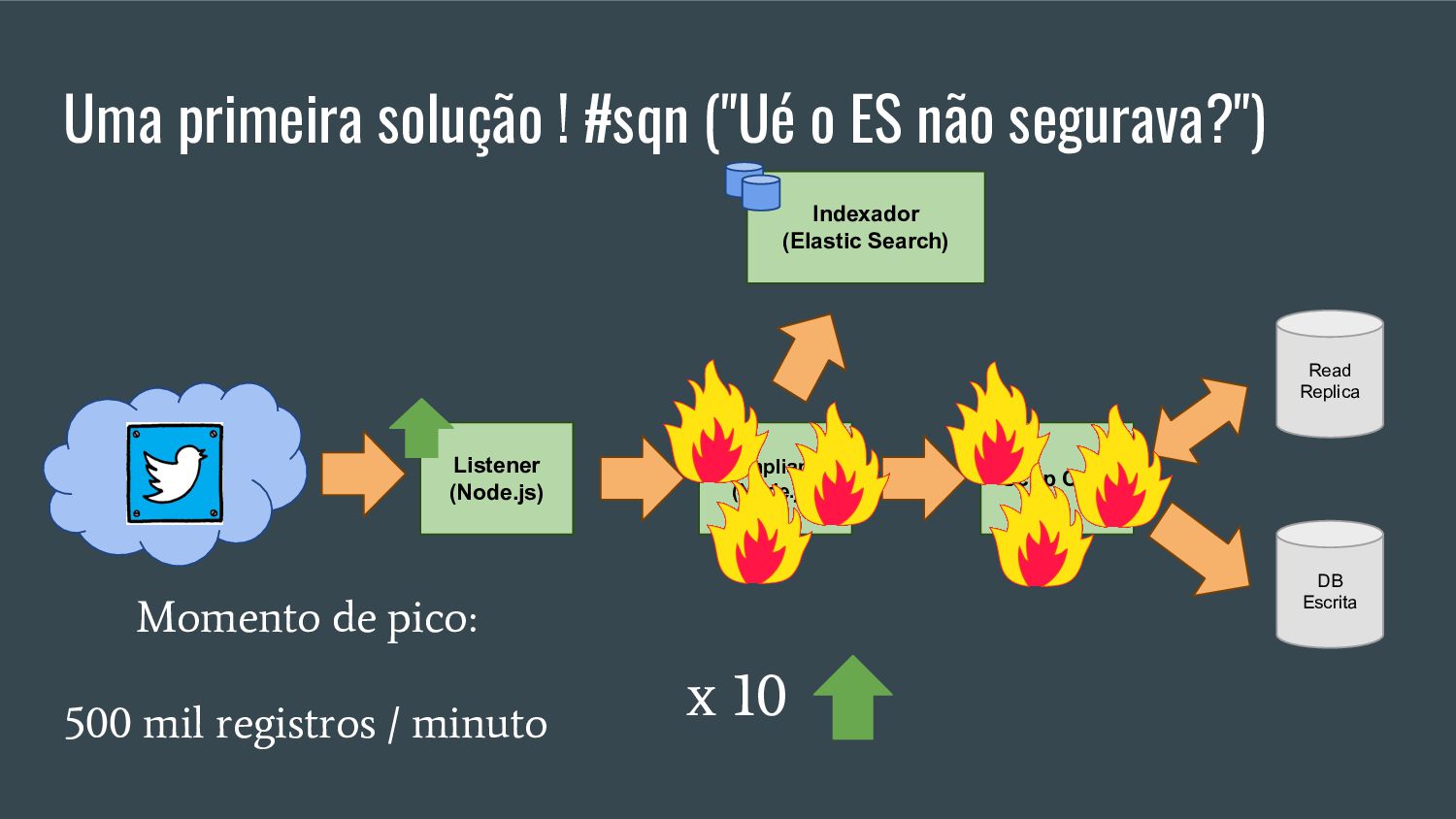
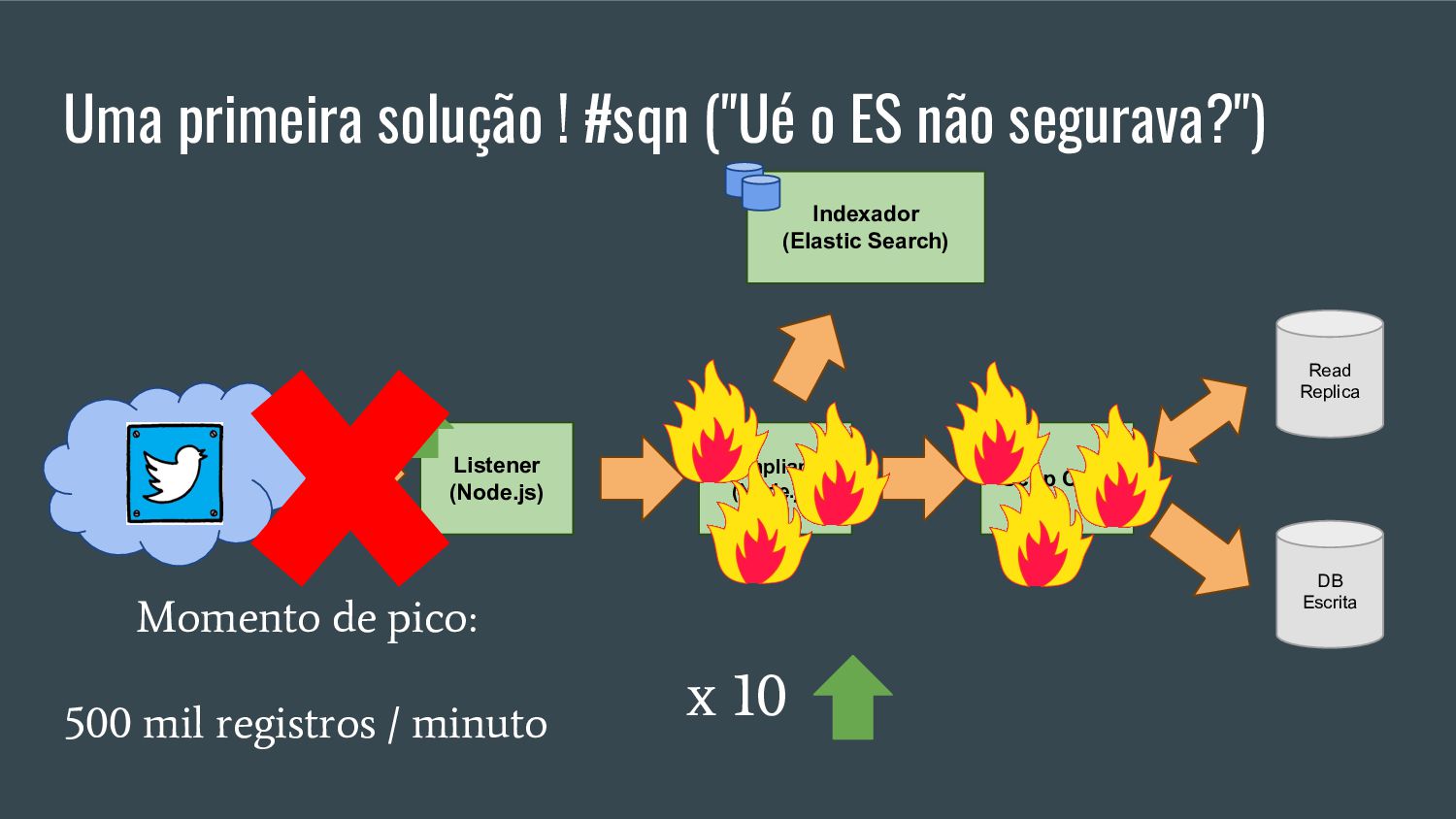
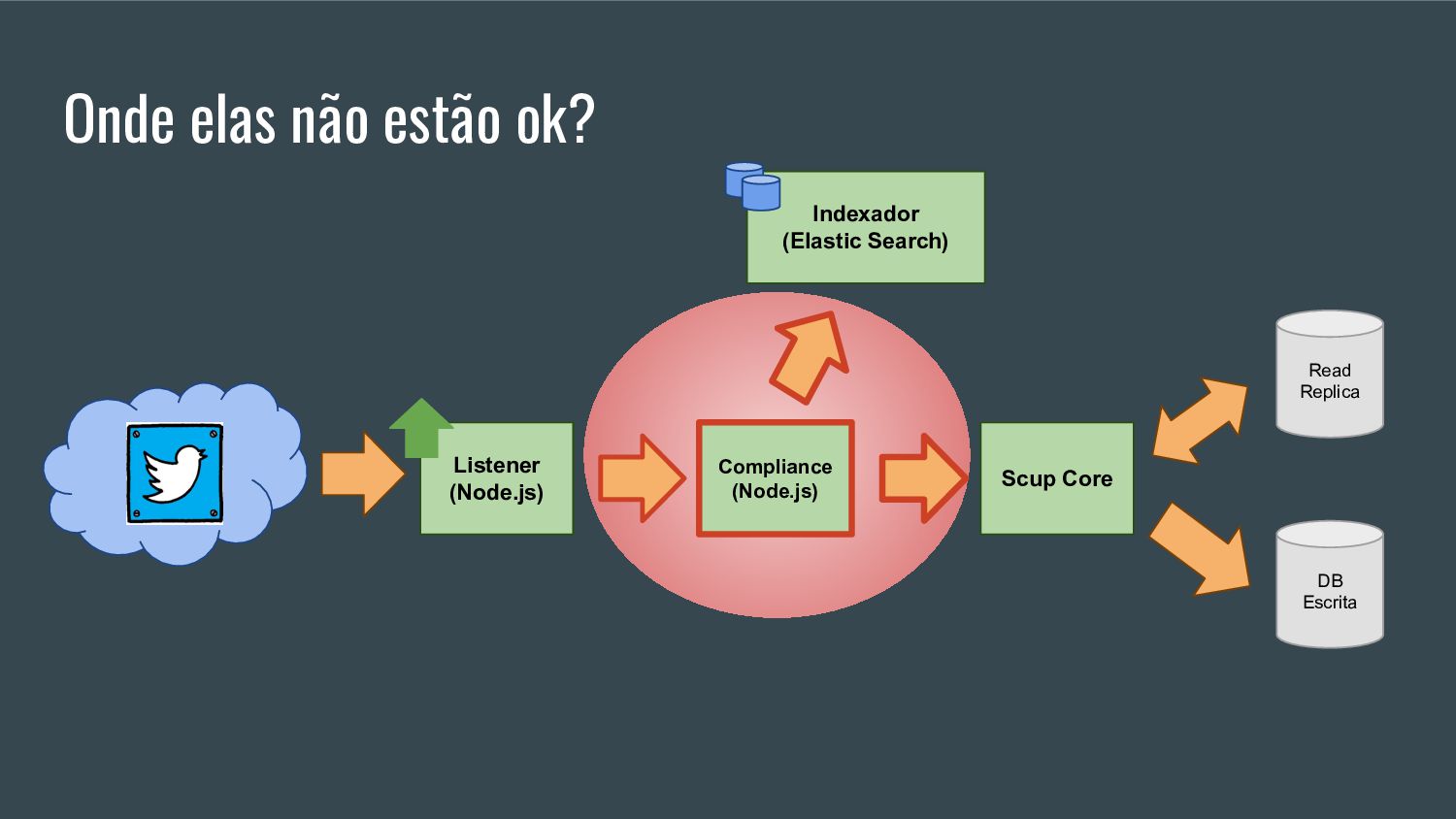
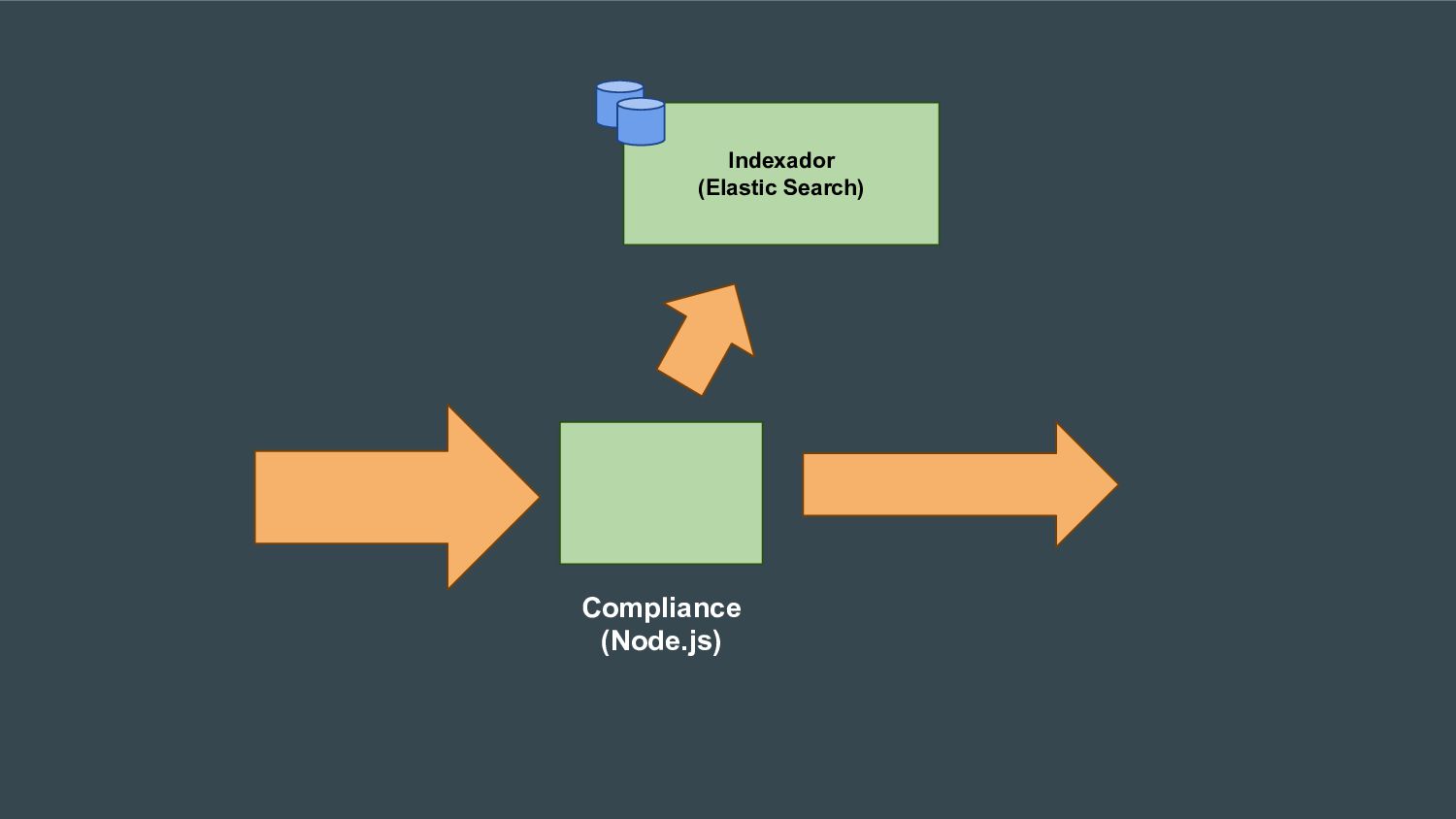
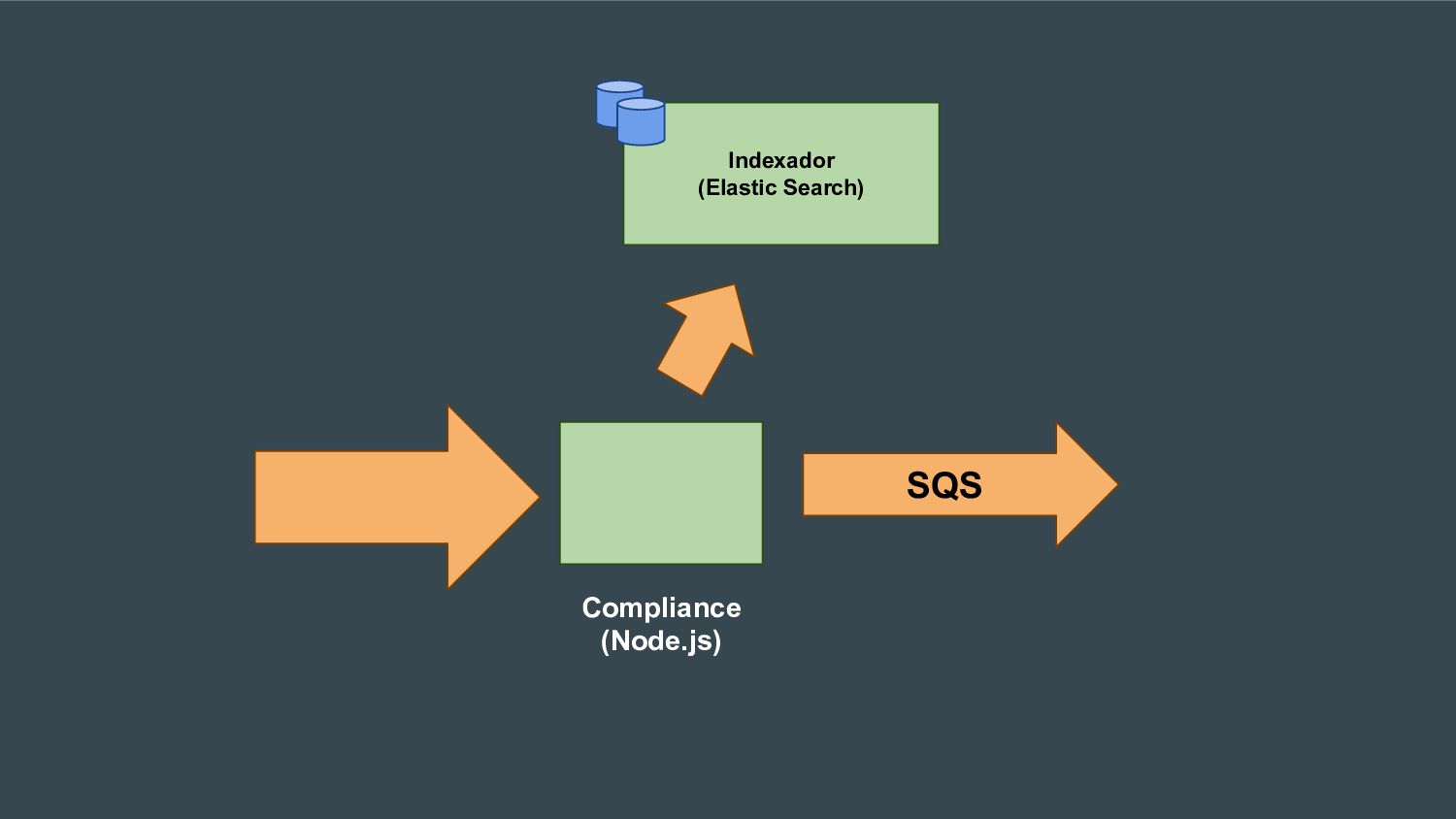
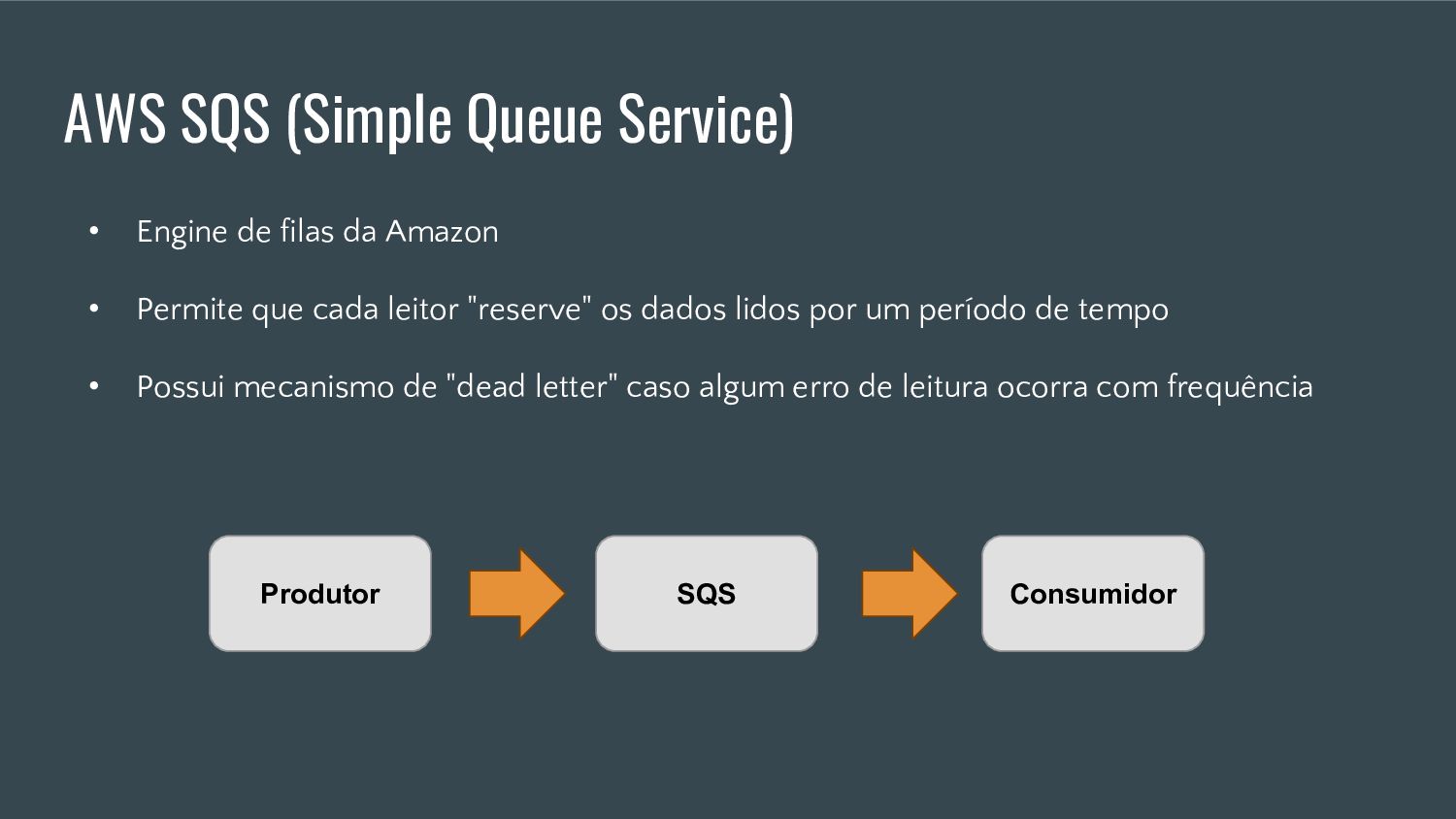
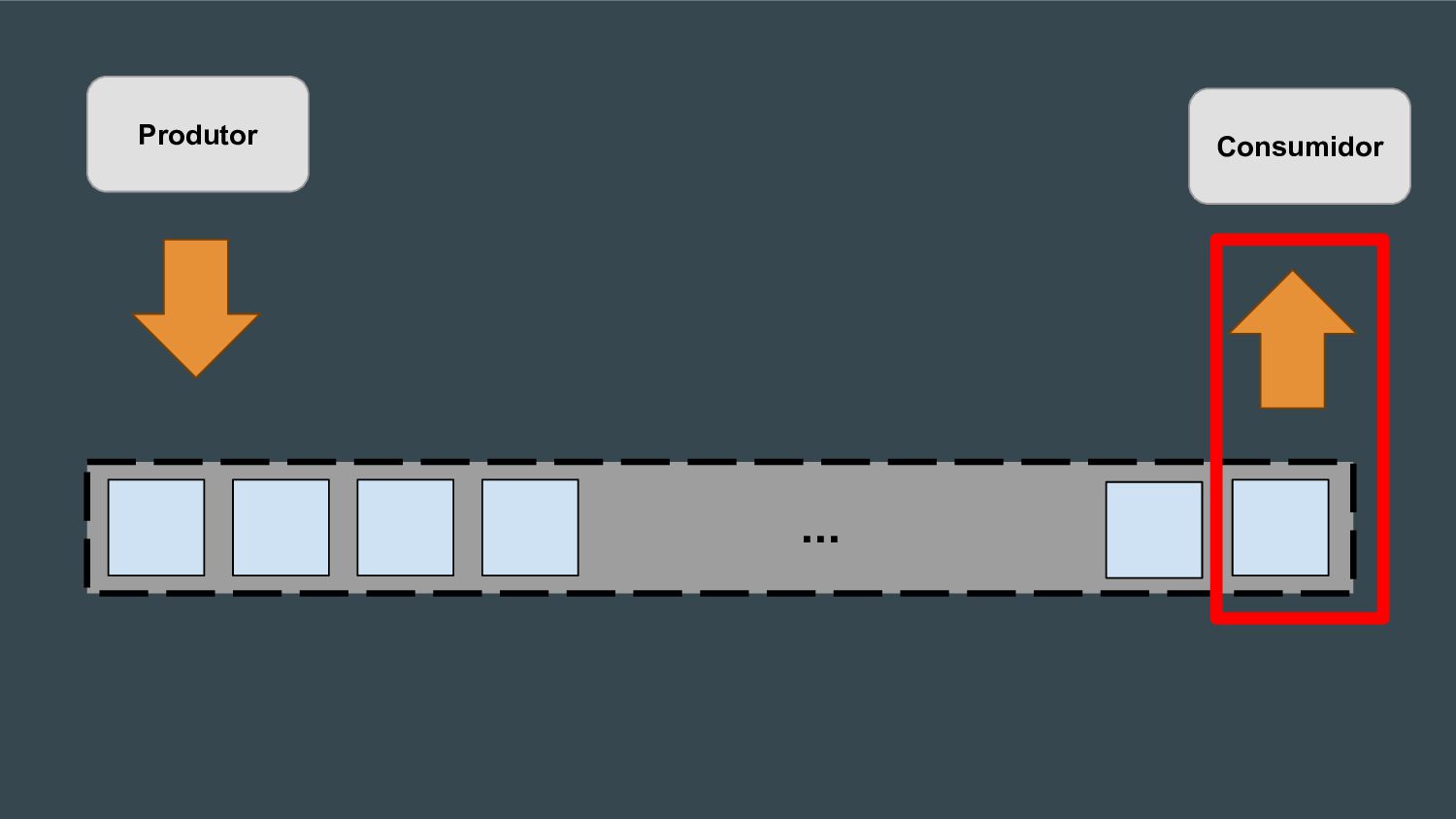
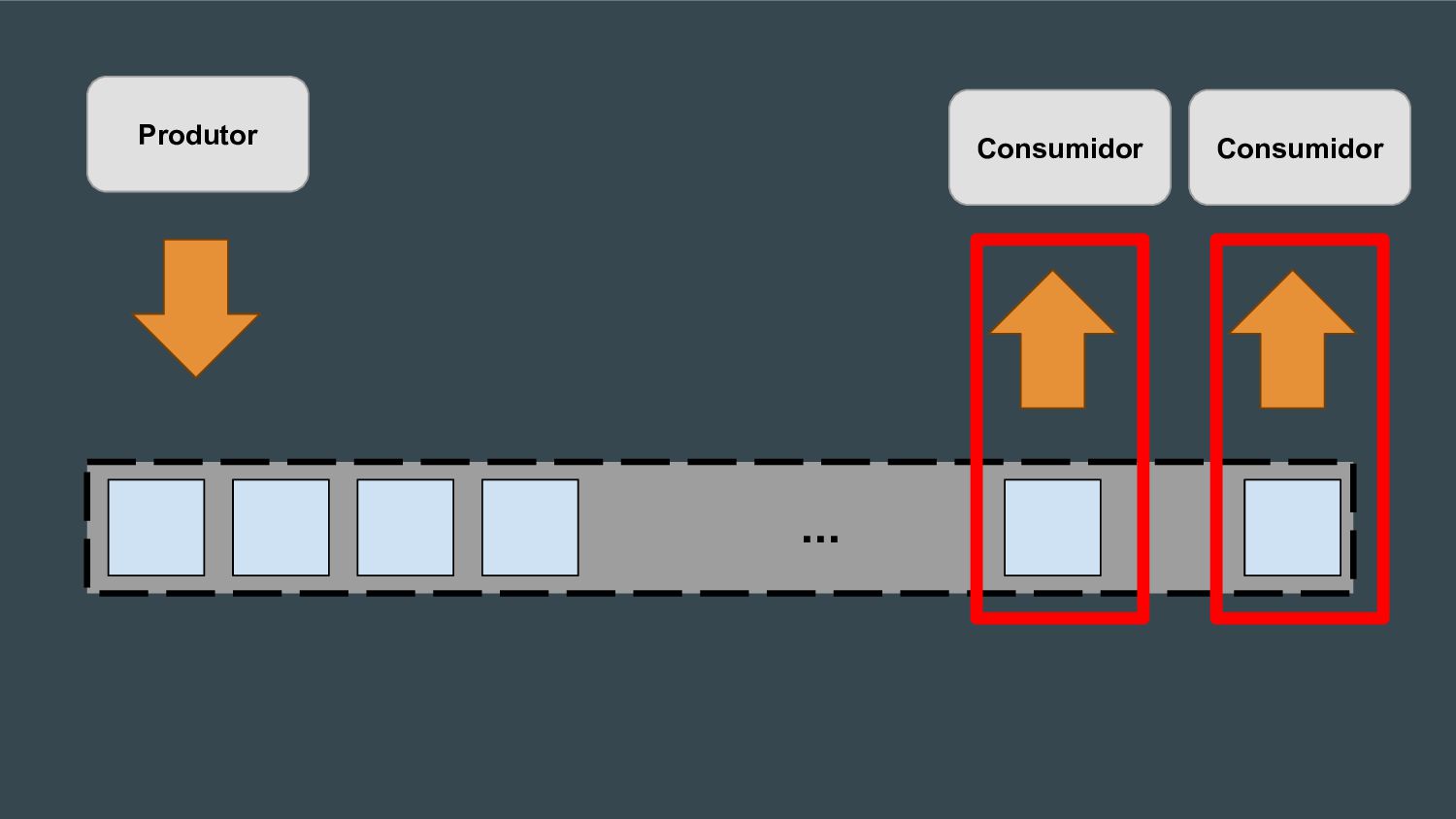
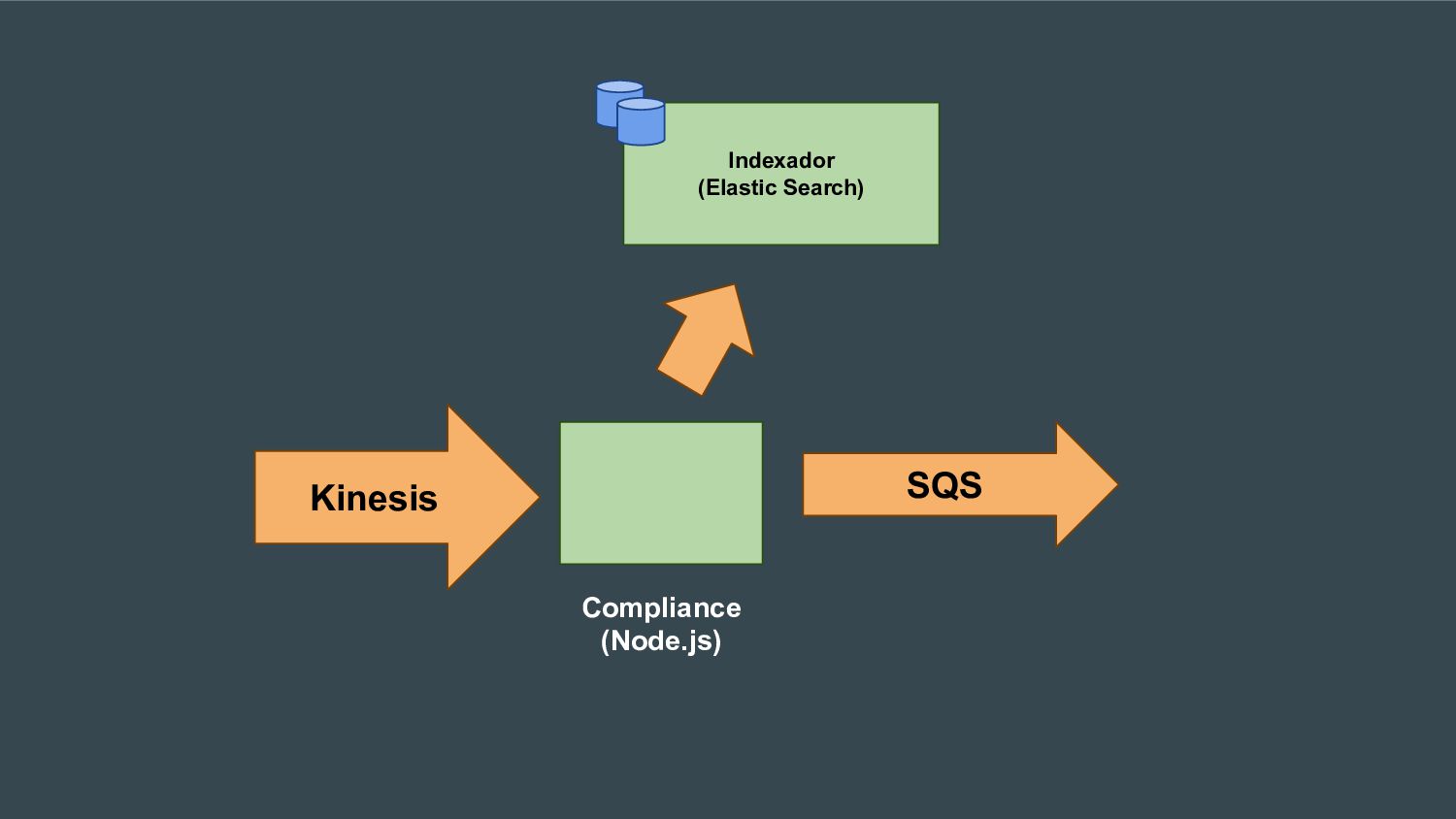
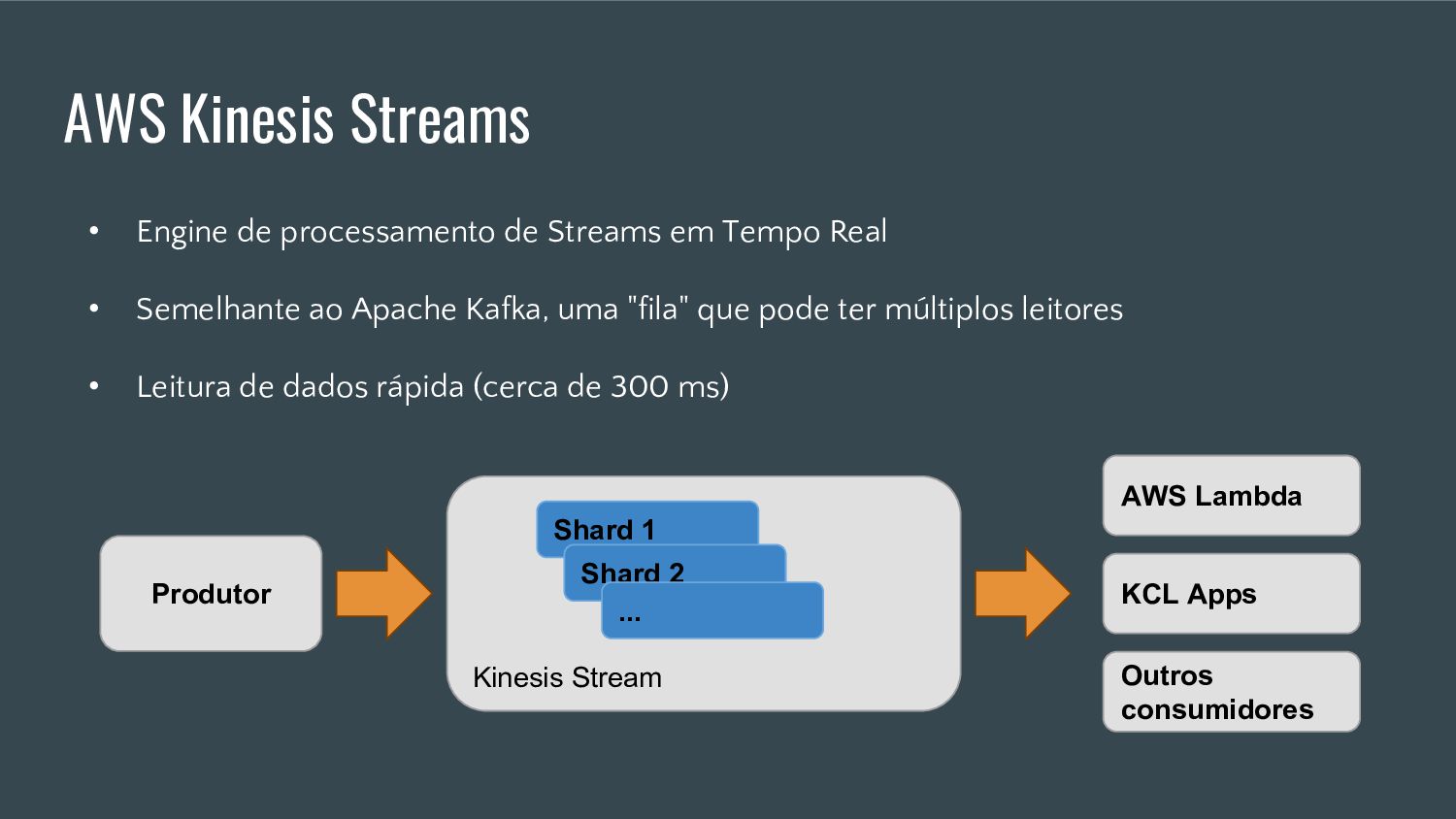
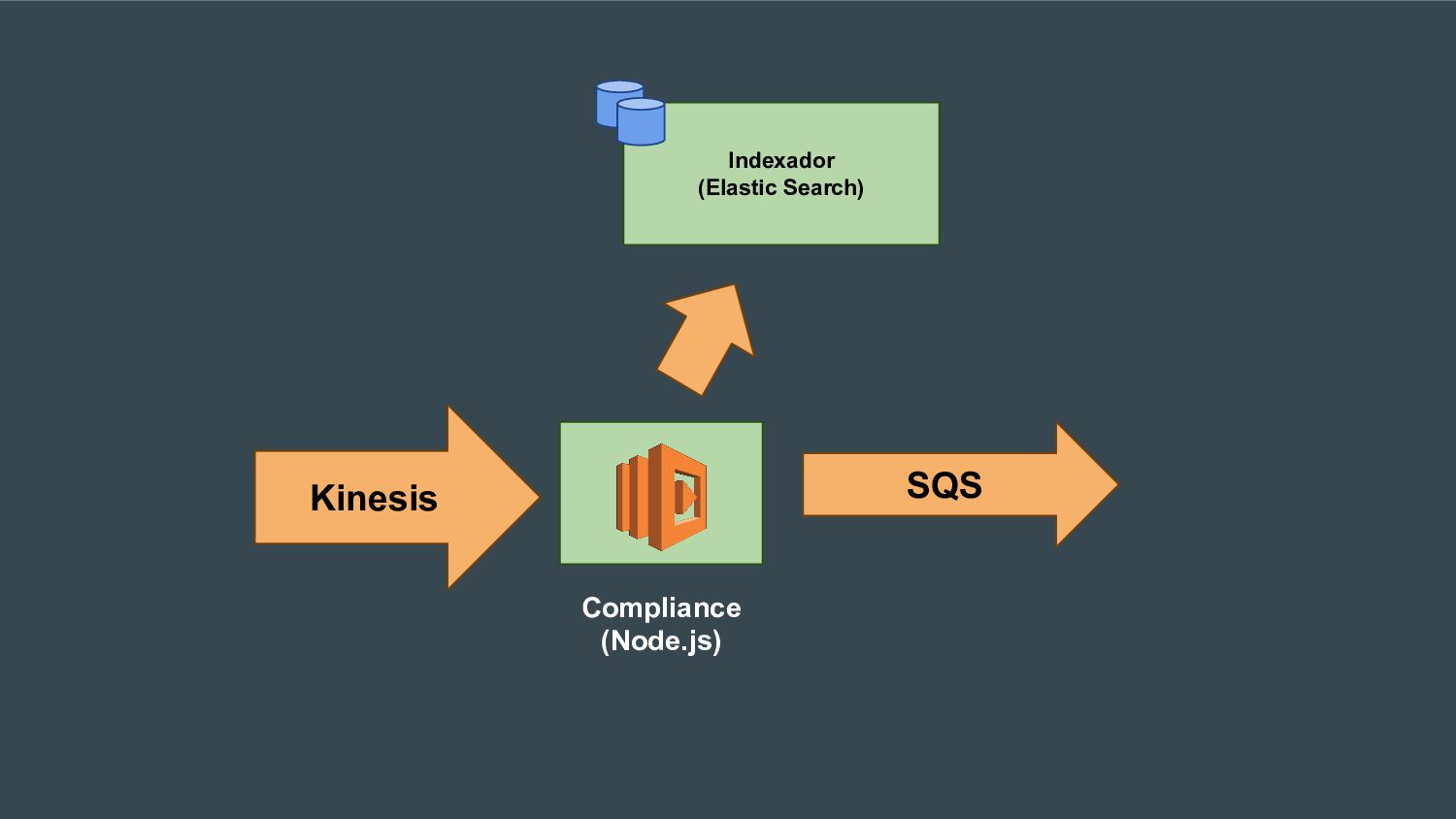
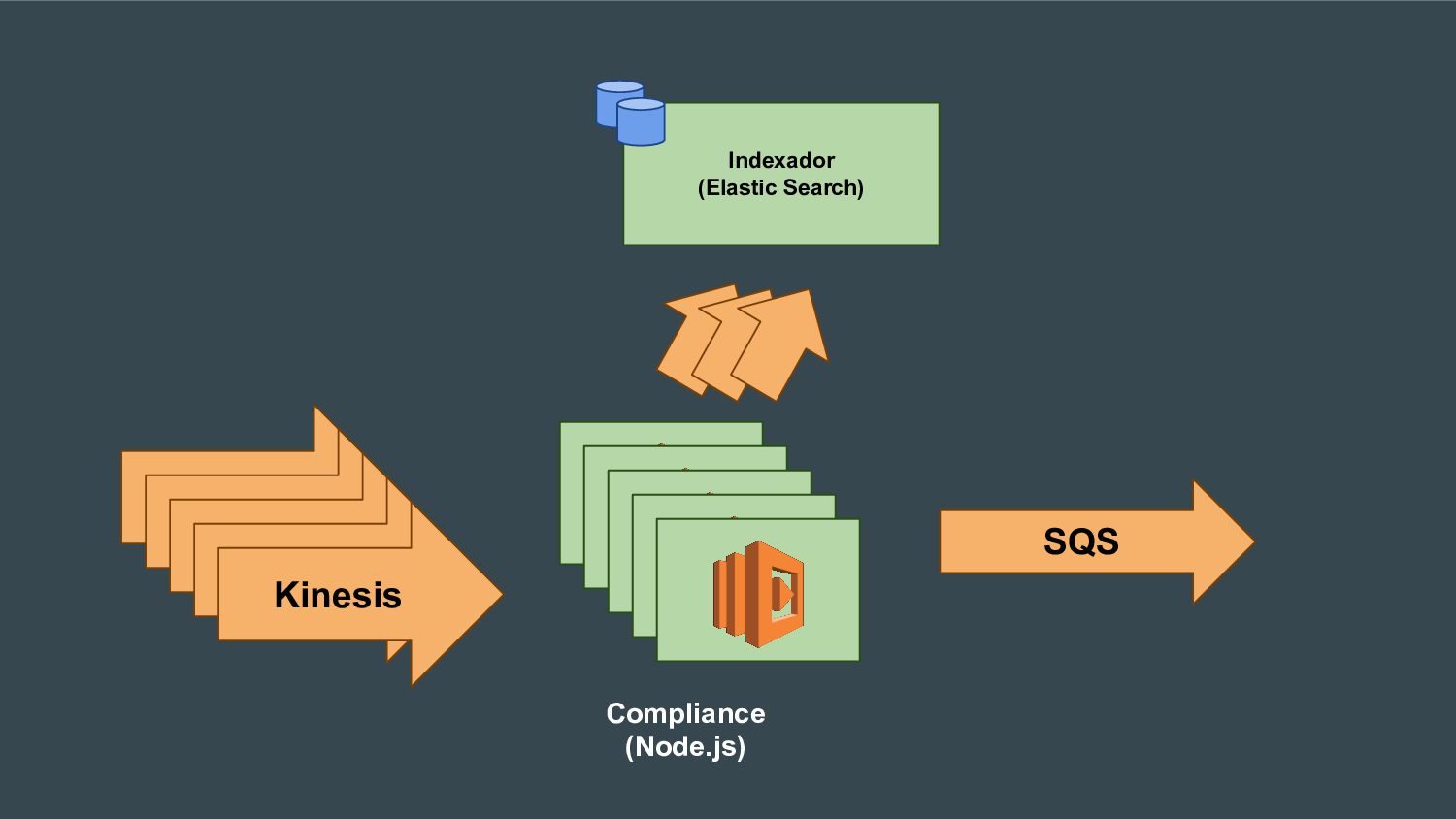
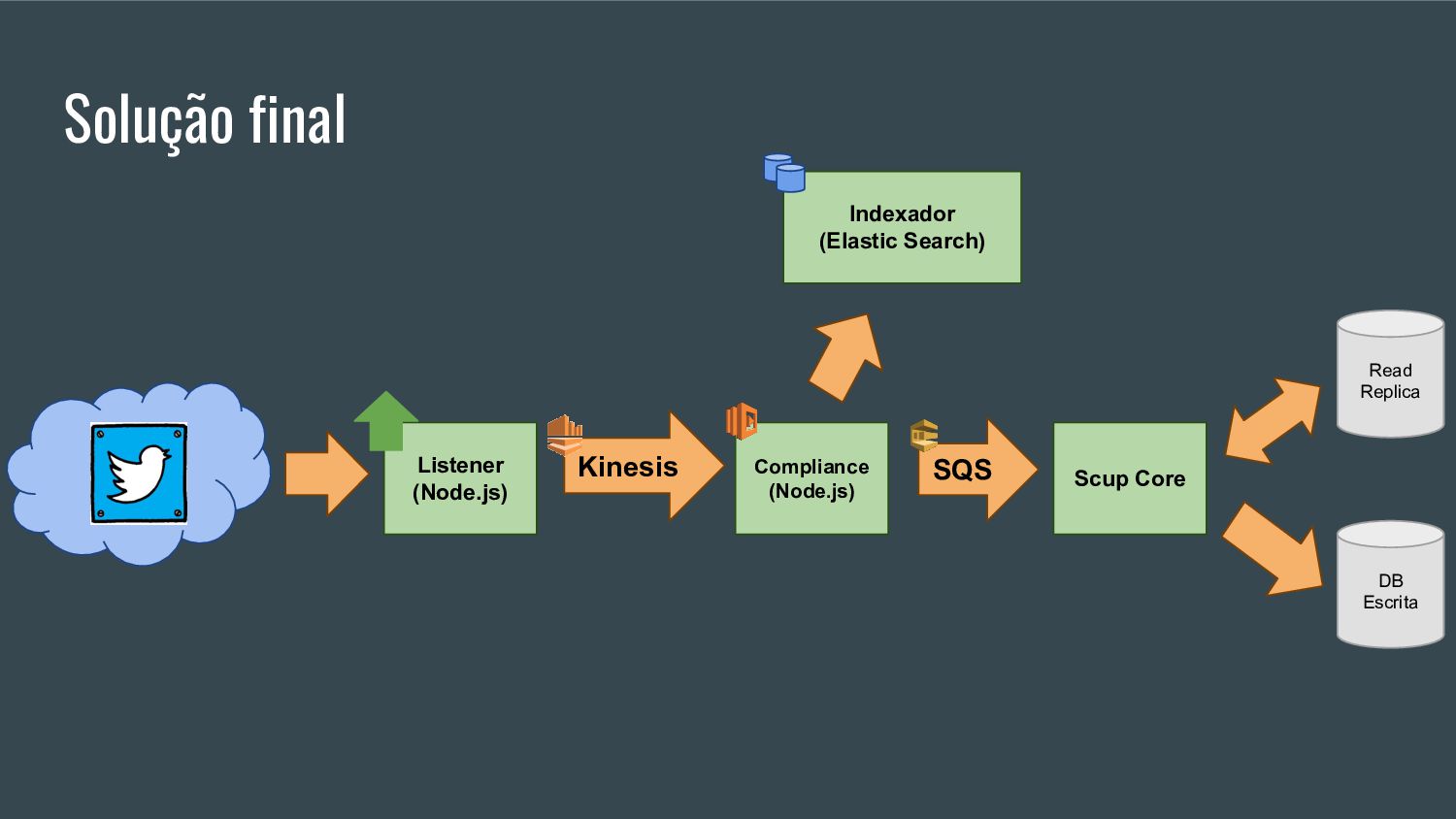
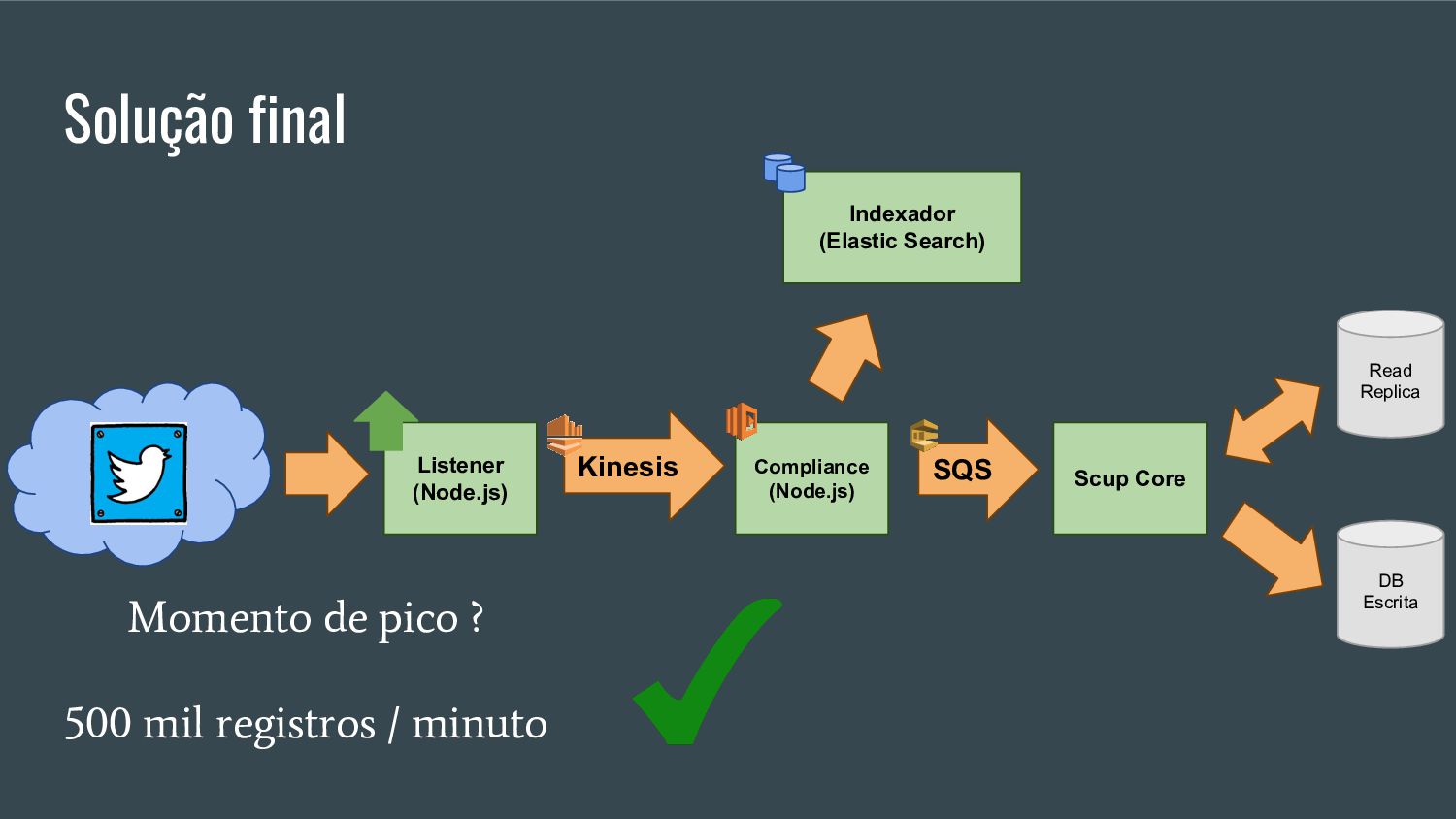
Esta apresentação discute como processar grandes volumes de dados do Twitter em tempo real usando AWS Lambda e Kinesis. A solução proposta usa Lambda para ler dados do Kinesis e indexá-los no ElasticSearch para permitir checagens em tempo real, resolvendo problemas de escalabilidade do ElasticSearch. Isso fornece elasticidade, tolerância a erros e capacidade de lidar com picos de tráfego.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Muito obrigado ! [email protected] @danielbdias https://www.slideshare.net/DanielDias10 https://github.com/danielbdias/nodebr-meetup-lambda-kinesis-demo](https://files.speakerdeck.com/presentations/13e6b18ba40c43ac8edde7285976a00f/slide_48.jpg){kind=link}
{kind=link}
![Dúvidas ? [email protected] @danielbdias https://www.slideshare.net/DanielDias10 https://github.com/danielbdias/nodebr-meetup-lambda-kinesis-demo](https://files.speakerdeck.com/presentations/13e6b18ba40c43ac8edde7285976a00f/slide_50.jpg){kind=link}