Programação dinâmica em tempo real para Processos de Decisão Markovianos com Probabilidades Imprecisas
Apresentação realizada em 28/11/2014 para a defesa de mestrado do aluno Daniel Baptista Dias, realizada no Instituto de Matemática e Estatística da Universidade de São Paulo
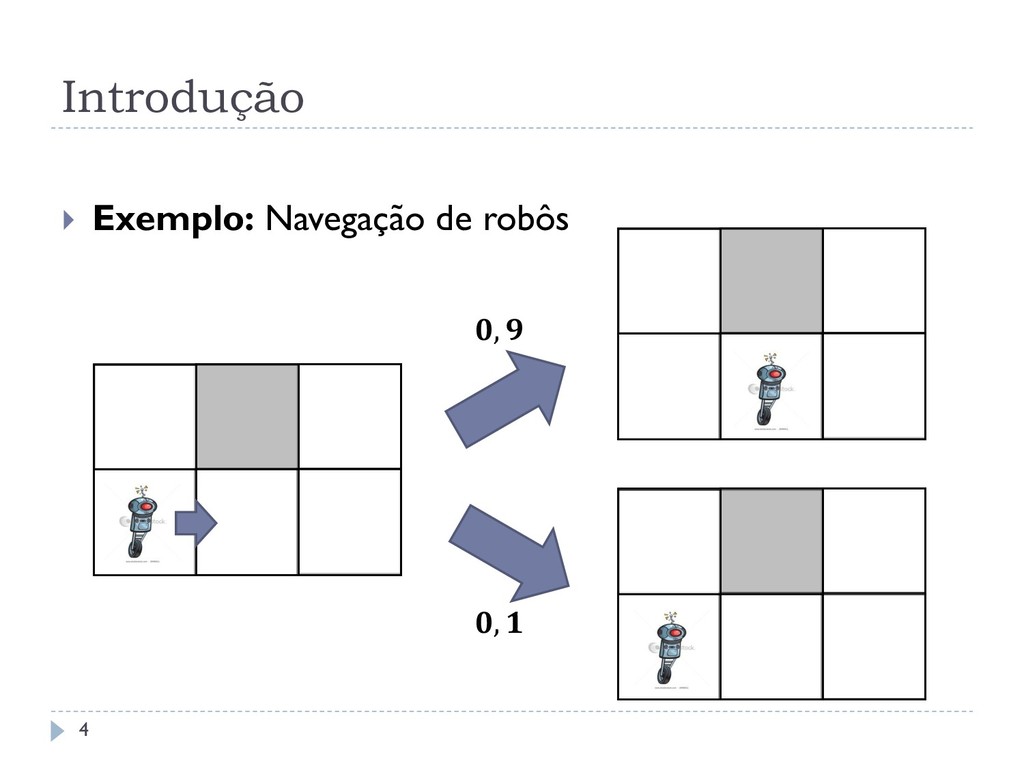
usados como um arcabouço padrão para problemas de planejamento probabilístico. Eles modelam a interação de um agente em um ambiente, que executam ações com efeitos probabilísticos que podem levar o agente a diferentes estados. 3
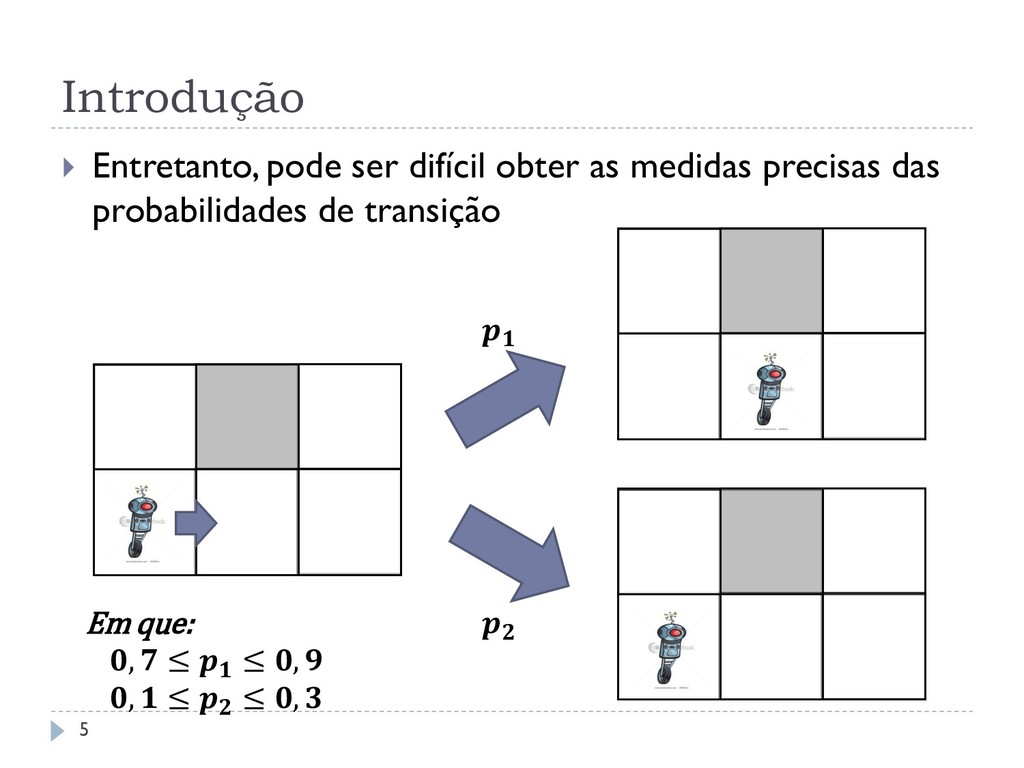
As probabilidades imprecisas são dadas através de parâmetros nas transições de estados restritas por um conjunto de inequações Geralmente modelados de duas maneiras: MDP-IP enumerativo: estados com informações autocontidas MDP-IP fatorado: estados representados por variáveis de estado Solução para MDP-IPs fatorados: SPUDD-IP Algoritmo de programação dinâmica síncrona fatorada Supera o algoritmo clássico enumerativo Iteração de Valor em duas ordens de magnitude 6
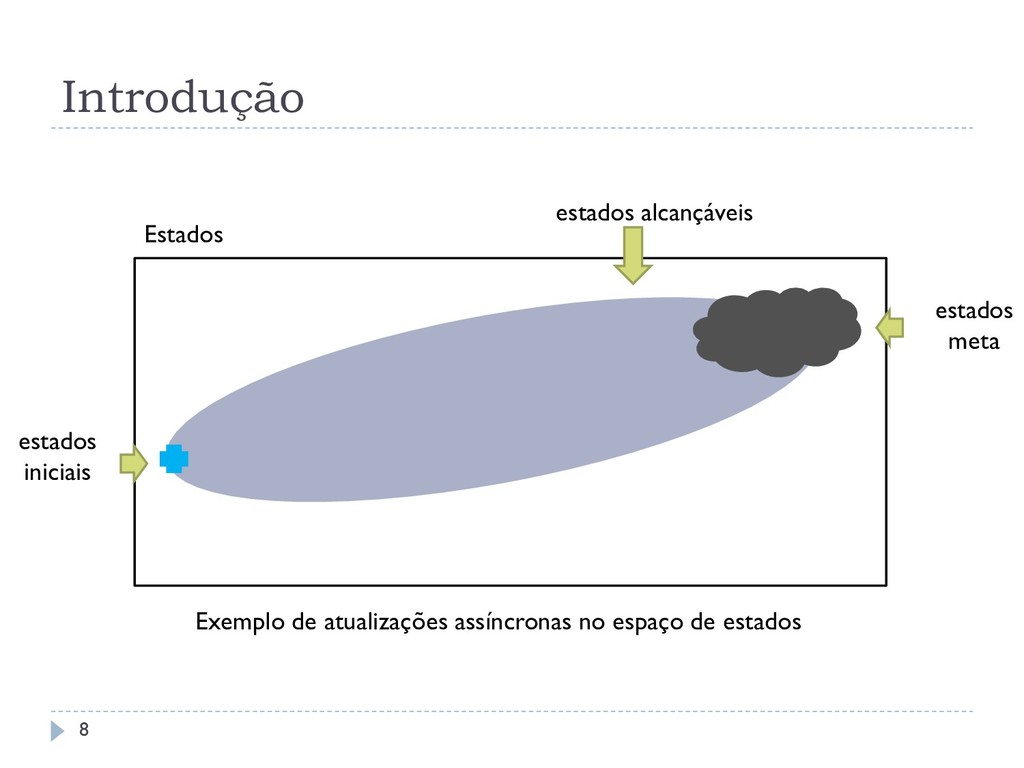
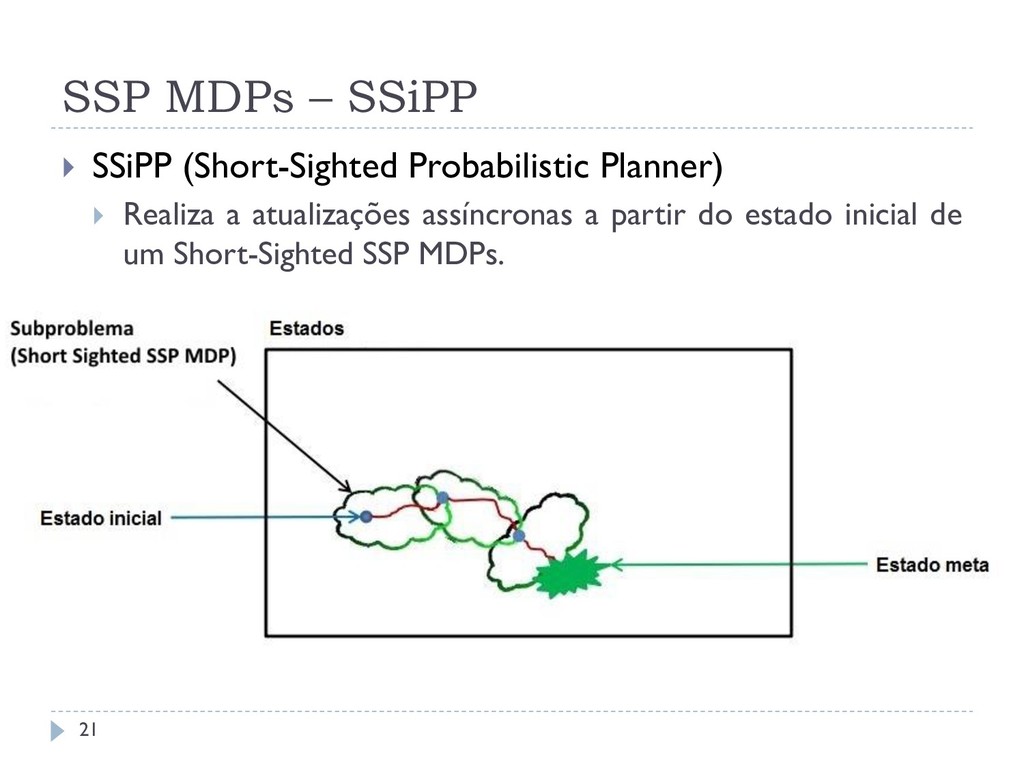
por Bertsekas e Tsitsiklis (1991) Considera um estado inicial e um conjunto de estados meta Soluções comuns para SSP MDPs Algoritmos de programação dinâmica assíncrona Exploram a informação de um estado inicial do problema Obtêm uma política ótima parcial Algoritmos conhecidos: RTDP e SSiPP Short Sighted SSP MDPs (Trevizan, 2013) São problemas menores criados a partir de SSP MDP 7
para SSP MDP-IPs com restrições gerais Deve-se adaptar algumas características do (L)RTDP e (L)SSiPP para se criar estes algoritmos para SSP MDP-IPs As principais são: Como garantir a convergência de soluções de programação dinâmica assíncrona para SSP MDP-IPs? Como amostrar o próximo estado no trial dadas as probabilidades imprecisas? Como criar os Short-Sighted SSP MDP-IPs a partir de SSP MDP-IPs? 9
novos algoritmos assíncronos para resolver SSP MDP-IPs enumerativos e fatorados, estendendo os algoritmos (L)RTDP e (L)SSiPP para lidar com um conjunto de probabilidades no lugar de probabilidades precisas. 10
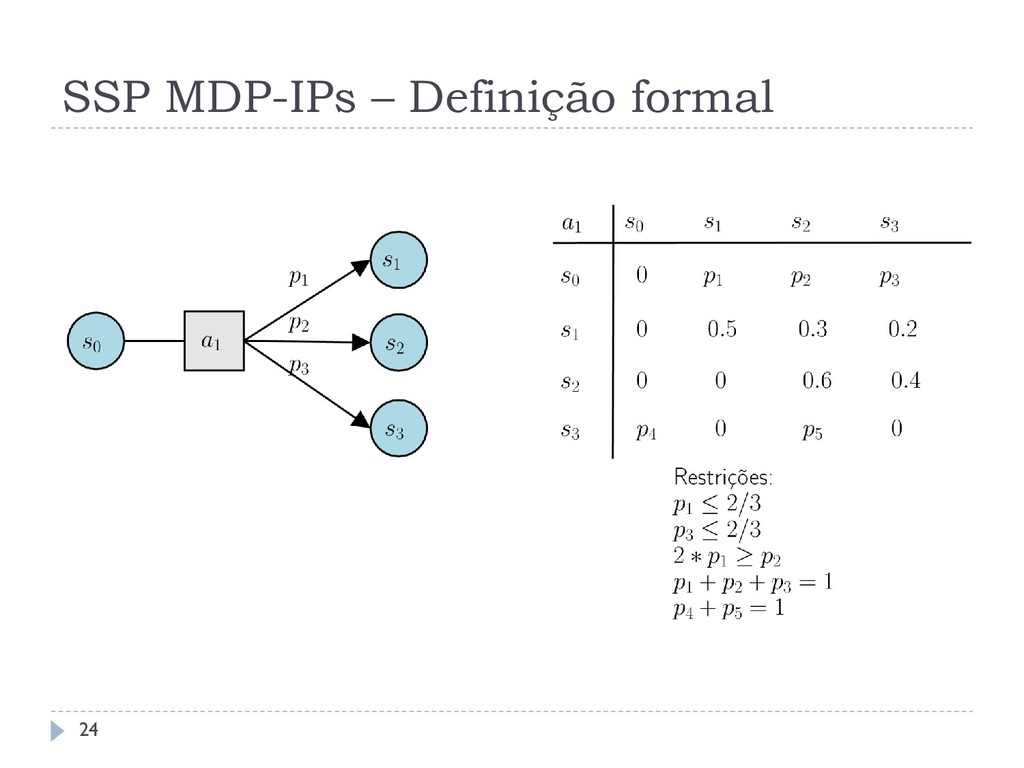
e Tsitsiklis, 1991), é uma tupla S, , , , , 0 em que: é um conjunto finito de estados é um conjunto finito de ações ∶ × → ℛ+ é uma função de custo (′|, ) define a probabilidade de transição de se alcançar um estado ′ ∈ a partir de um estado ∈ , executando a ação ∈ ⊆ é um conjunto de estados meta, definidos como estados de absorção. Para cada ∈ , (|, ) = 1 e (, ) = 0 para todo ∈ 0 ∈ é o estado inicial 12
pressupostos (Bertsekas e Tsitsiklis, 1991): Política apropriada: Cada ∈ deve ter ao menos uma política apropriada, i.e., uma política que garante que um estado meta é alcançado com probabilidade 1. Política imprópria: Cada política imprópria deve ter custo ∞ em todos os estados que não podem alcançar a meta com probabilidade 1. 13
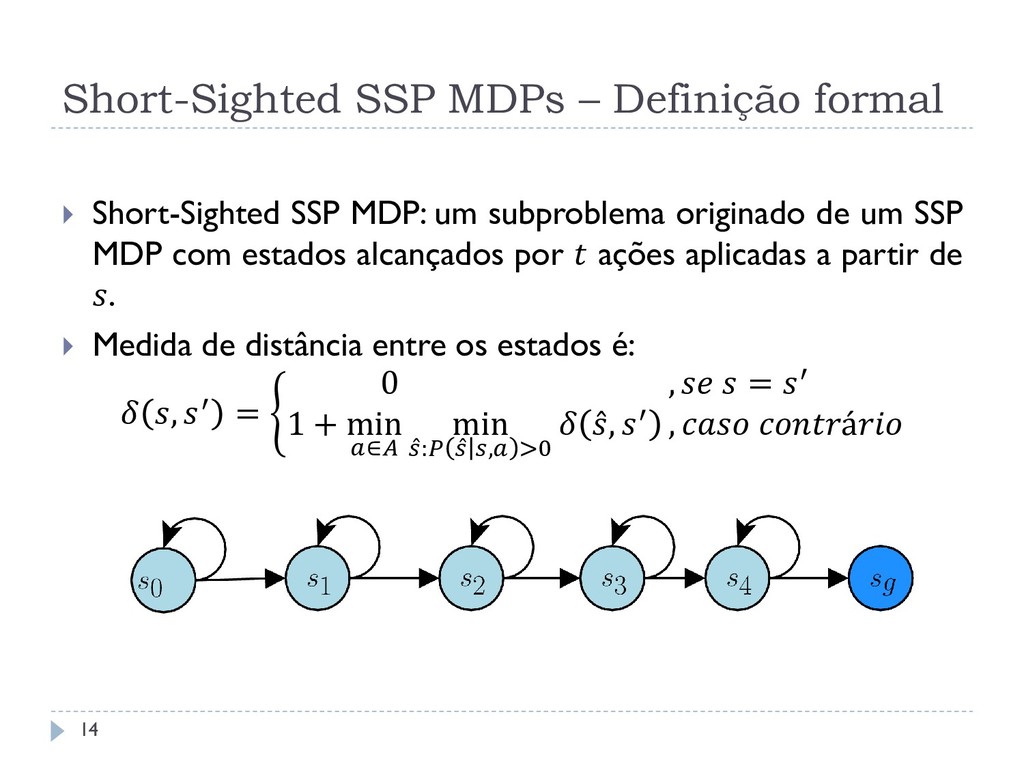
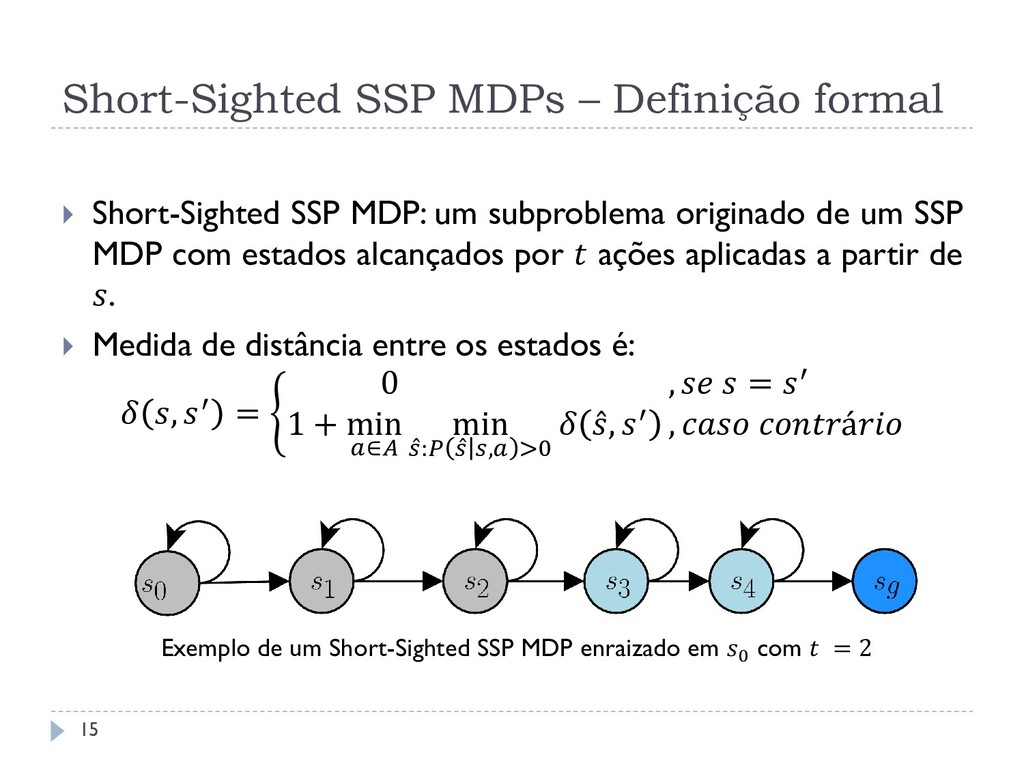
um subproblema originado de um SSP MDP com estados alcançados por ações aplicadas a partir de . Medida de distância entre os estados é: , ′ = 0 , = ′ 1 + min ∈ min : , >0 , ′ , á 14
um subproblema originado de um SSP MDP com estados alcançados por ações aplicadas a partir de . Medida de distância entre os estados é: , ′ = 0 , = ′ 1 + min ∈ min : , >0 , ′ , á Exemplo de um Short-Sighted SSP MDP enraizado em 0 com = 2 15
MDP enraizado em ∈ e com profundidade ∈ +é uma tupla , , , , , , , , , onde: e são definidos como em SSP MDPs; , = {′ ∈ | , ′ ≤ } , = ′ ∈ , ′ = ∪ ∩ , , ′, , ′′ = ′, , ′′ + (′′) ′, , ′′ ′′∈,\G á Onde () é uma heurística definida para o estado Neste trabalho o custo será considerado dependente apenas de e , i.e., (′, ) e ′′ = 0 16
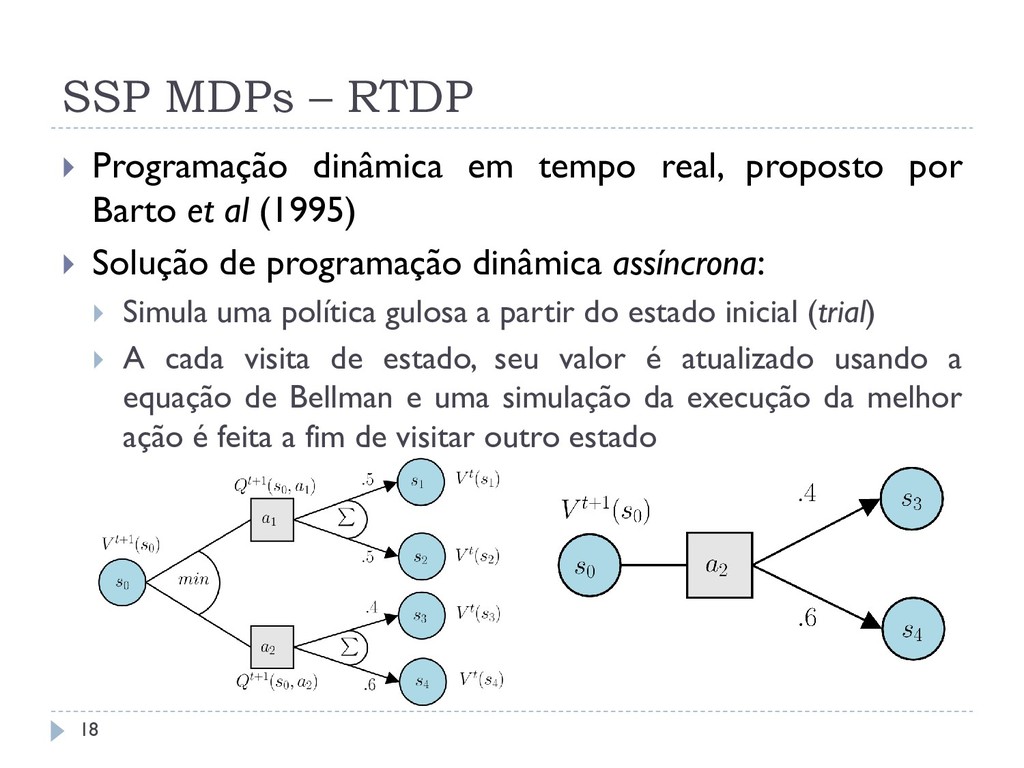
proposto por Barto et al (1995) Solução de programação dinâmica assíncrona: Simula uma política gulosa a partir do estado inicial (trial) A cada visita de estado, seu valor é atualizado usando a equação de Bellman e uma simulação da execução da melhor ação é feita a fim de visitar outro estado 18
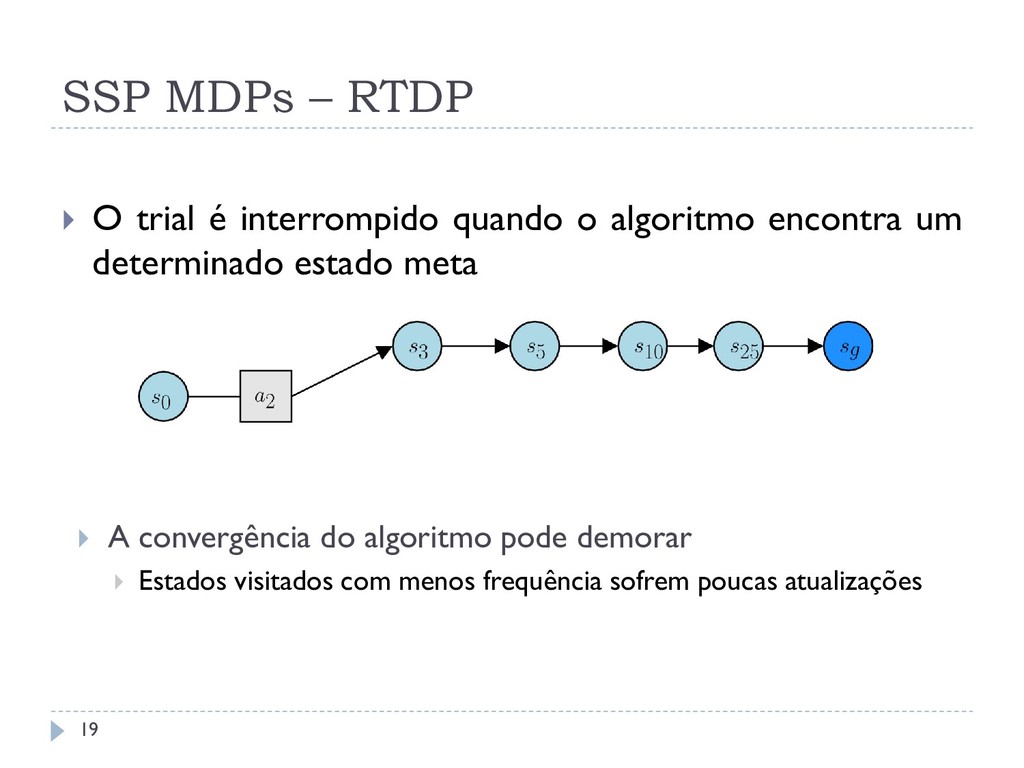
o algoritmo encontra um determinado estado meta A convergência do algoritmo pode demorar Estados visitados com menos frequência sofrem poucas atualizações 19
Bonet e Geffner (2003) Melhora a convergência através da rotulação dos estados que convergiram Características: Os trials são interrompidos quando um estado rotulado é encontrado Ao final de um trial, os estados visitados são atualizados se necessário e a convergência dos mesmos é verificada (através do procedimento CheckSolved) 20
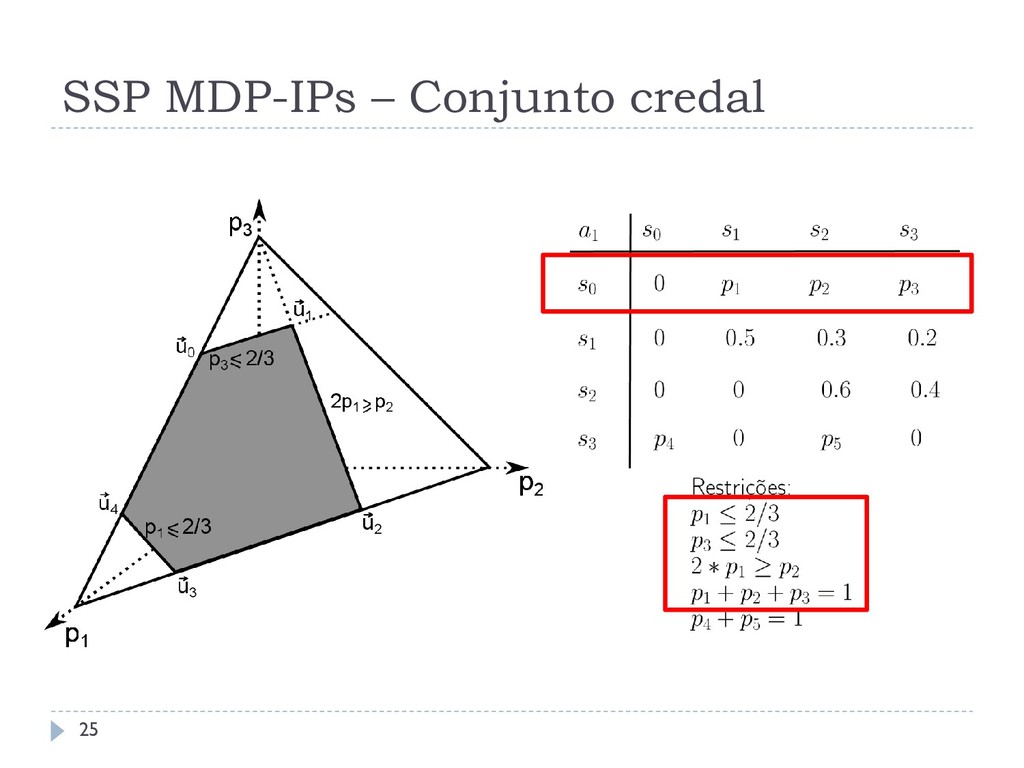
, , , , , 0 onde: , , , e 0 são definidos como qualquer SSP MDP; e é um conjunto de conjuntos credais de transição, onde um conjunto credal de transição é definido para cada par de estado-ação, i.e., ≤ = S × A . São assumidos os pressupostos de políticas apropriadas e impróprias. 23
jogos Utilizada para definir o valor de uma política Assume-se que existe outro agente no sistema, a Natureza Ela escolherá uma distribuição de probabilidades em um conjunto credal assumindo algum critério Critério minimax O agente seleciona as ações que minimizam o custo futuro A Natureza escolhe a probabilidade que maximiza o custo esperado do agente (i.e., a Natureza é adversária) 26
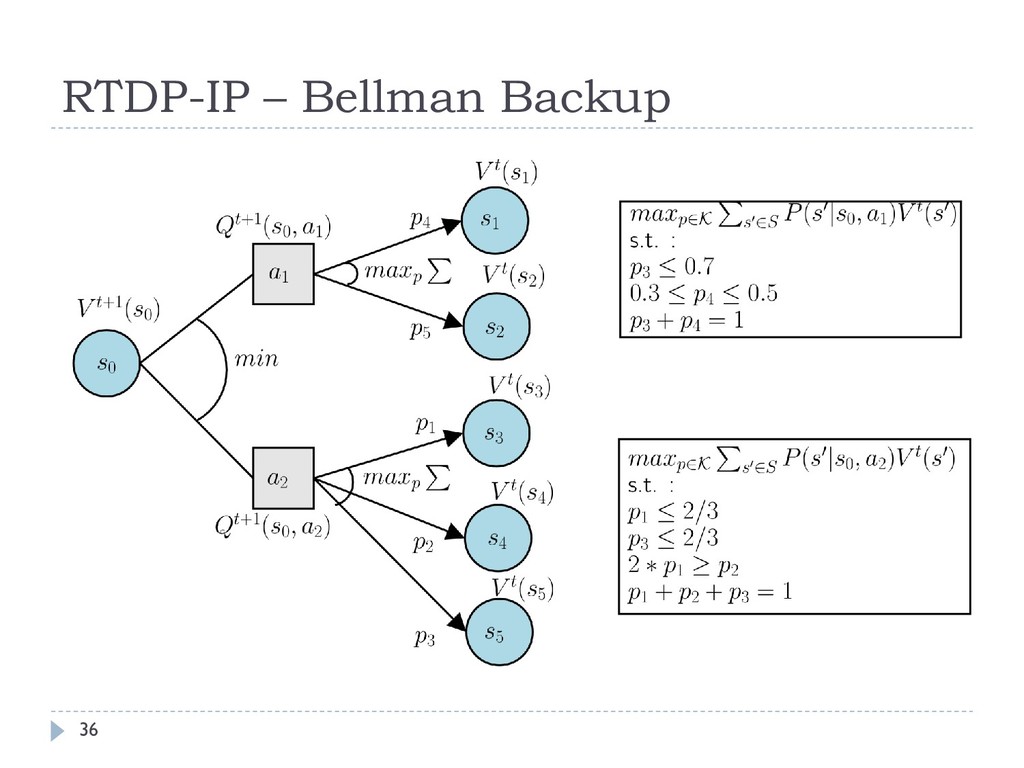
de Bellman para SSP MDP-IPs é: ∗ = min ∈ max ∈ (, ) + ′ , ∗(′) ′∈ Existe de valor de equilíbrio para um SSP game alternado (Patek e Bertsekas, 1999) Este valor pode ser calculado para SSP MDP-IPs com a equação de Bellman 27
mesmas definições que os Short-Sighted SSP MDP, com uma tupla , , , , , , , , . Porém , e , ao invés de ser definido por , ′ , será definido pela função , ′ : , ′ = 0 , = ′ 1 + min ∈ min : , >0∀∈(⋅|,) , ′ , á 29
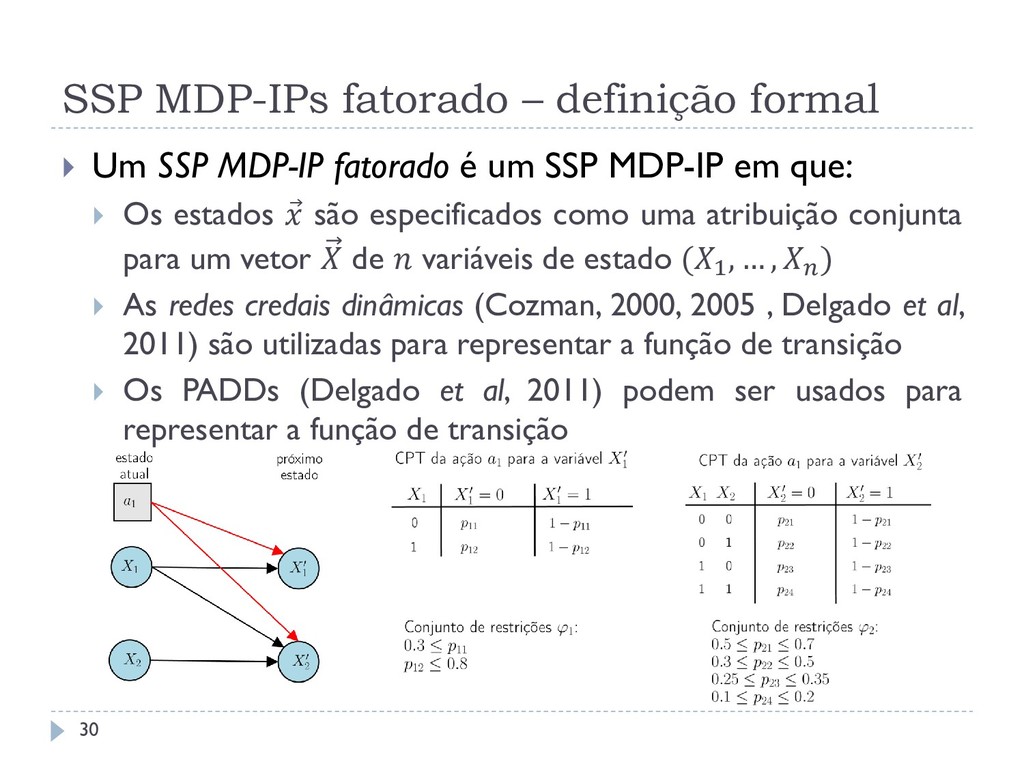
fatorado é um SSP MDP-IP em que: Os estados são especificados como uma atribuição conjunta para um vetor de variáveis de estado (1 , … , ) As redes credais dinâmicas (Cozman, 2000, 2005 , Delgado et al, 2011) são utilizadas para representar a função de transição Os PADDs (Delgado et al, 2011) podem ser usados para representar a função de transição 30
pode ser criado através de um fatorado pelo cálculo da probabilidades de transição conjunta: ′ , = ( ′| ′ , ) =1 As probabilidades de transição deste novo SSP MDP-IP enumerativo não serão mais lineares, pois podem envolver multiplicação de parâmetros 32
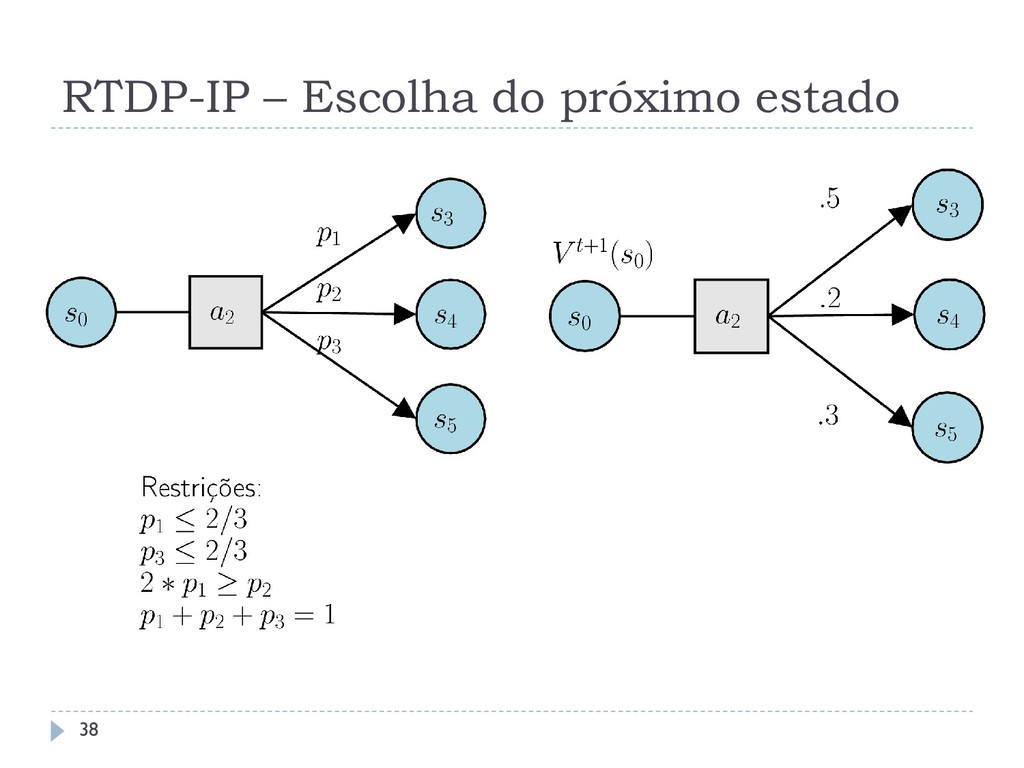
as seguintes alterações: O Bellman backup para o estado atual visitado é executado considerando o critério minimax A escolha do próximo estado é feita considerando as probabilidades imprecisas, isto é, dado uma ação gulosa, primeiro os valores para cada são escolhidos, sujeitos ao conjunto de restrições , para depois realizar a escolha real 35
MDPs, com as seguintes alterações: O Bellman backup para o estado atual visitado é executado considerando o critério minimax A escolha do próximo estado é feita considerando as probabilidades imprecisas, isto é, dado uma ação gulosa, primeiro os valores para cada são escolhidos, sujeitos ao conjunto de restrições , para depois realizar a escolha real 37
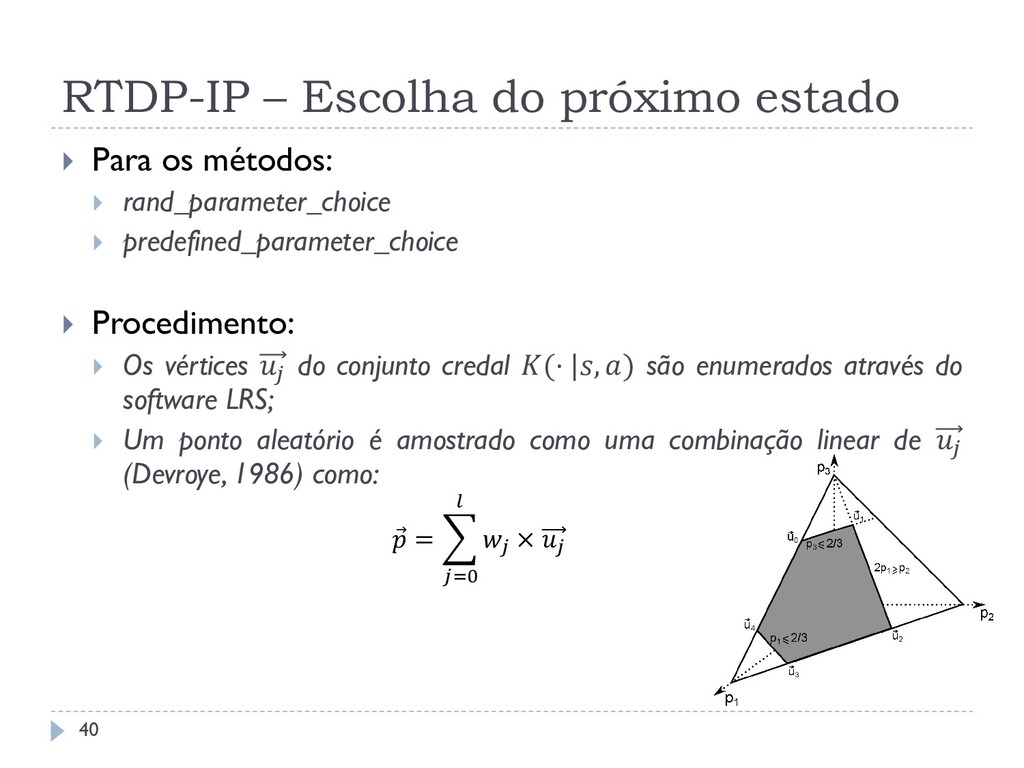
valor das probabilidades imprecisas pode ser feita de três formas: Utilizando o mesmo valor computado pelo Bellman update (método minimax_parameter_choice) Calculando um valor aleatório válido a cada visita de um estado durante o trial (método rand_parameter_choice) Calculando um valor válido pré determinado apenas uma vez no início do algoritmo (método predefined_parameter_choice) 39
rand_parameter_choice predefined_parameter_choice Procedimento: Os vértices do conjunto credal (⋅ |, ) são enumerados através do software LRS; Um ponto aleatório é amostrado como uma combinação linear de (Devroye, 1986) como: = × =0 40
Buffet e Aberdeen (2005) Que por sua vez estende a prova de Barto et al. (1999) Os seguintes pontos são provados para garantir a convergência do RTDP-IP: O operador (Bellman Backup) é uma contração (Patek e Bertsekas, 1999) A admissibilidade da função valor é mantida durante a execução do algoritmo Ao realizar repetidos trials nos estados relevantes utilizando qualquer método de amostragem do próximo estado, o RTDP-IP converge. 41
O critério de parada do algoritmo e parada do trial são idênticos ao LRTDP No fim de cada trial é verificado se o estado pode ser rotulado como resolvido através do método CheckSolved-IP Ao se buscar os estados sucessores no CheckSolved-IP, considera-se todas as transições parametrizadas diferentes de 0 (zero) 42
que atualiza um estado por vez Implementa o Bellman Update e a seleção do próximo estado de forma fatorada +1 = ∈ +1( , ) +1 , = ( , , ) ⊕ max ∈ ⊗=1 (( ( ′| 1 ′ , ), ) ⊗ (′) 1 ′ ,⋅, ′ O factLRTDP-IP também realiza as operações de forma fatorada, porém com chamadas ao método factCheckSolved-IP 43
Ao segmentar um SSP MDP-IP ele gera um Short-Sighted SSP MDP-IP e chama um solver para SSP MDP-IPs para resolvê-lo Ao simular a política devolvida pelo solver, ele leva em consideração os métodos de amostragem de próximo estado apresentados no RTDP-IP O LSSiPP-IP considera os mesmos pontos e também utiliza o método CheckSolved-IP para rotular os estados resolvidos, considerando as probabilidades imprecisas. 44
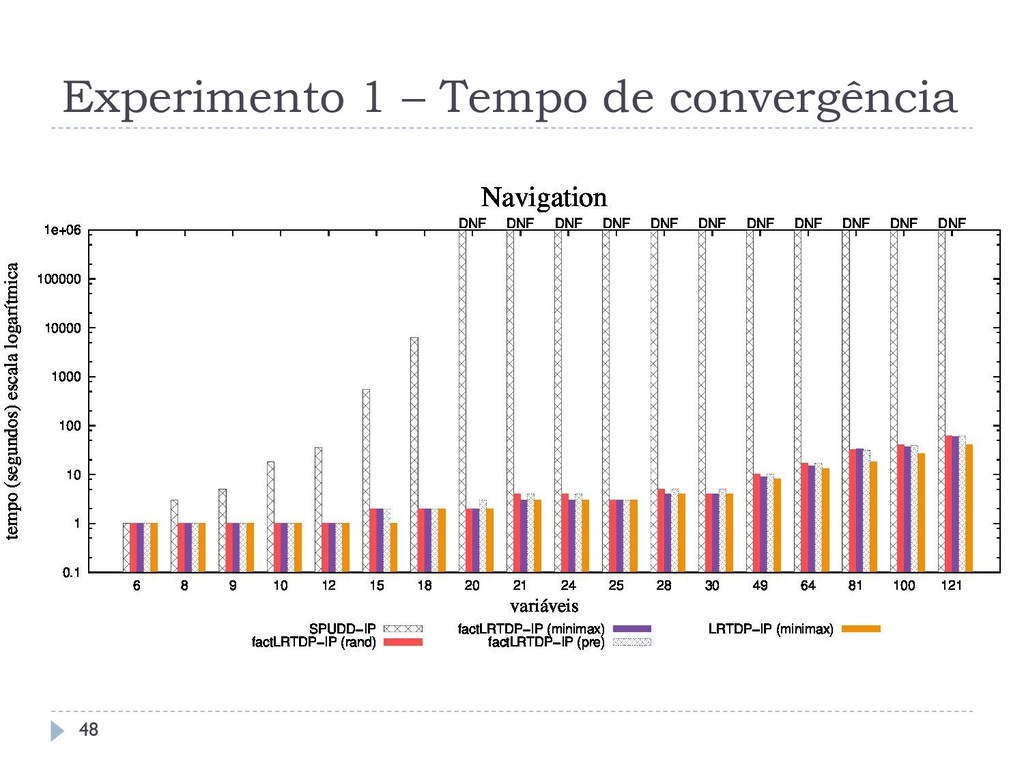
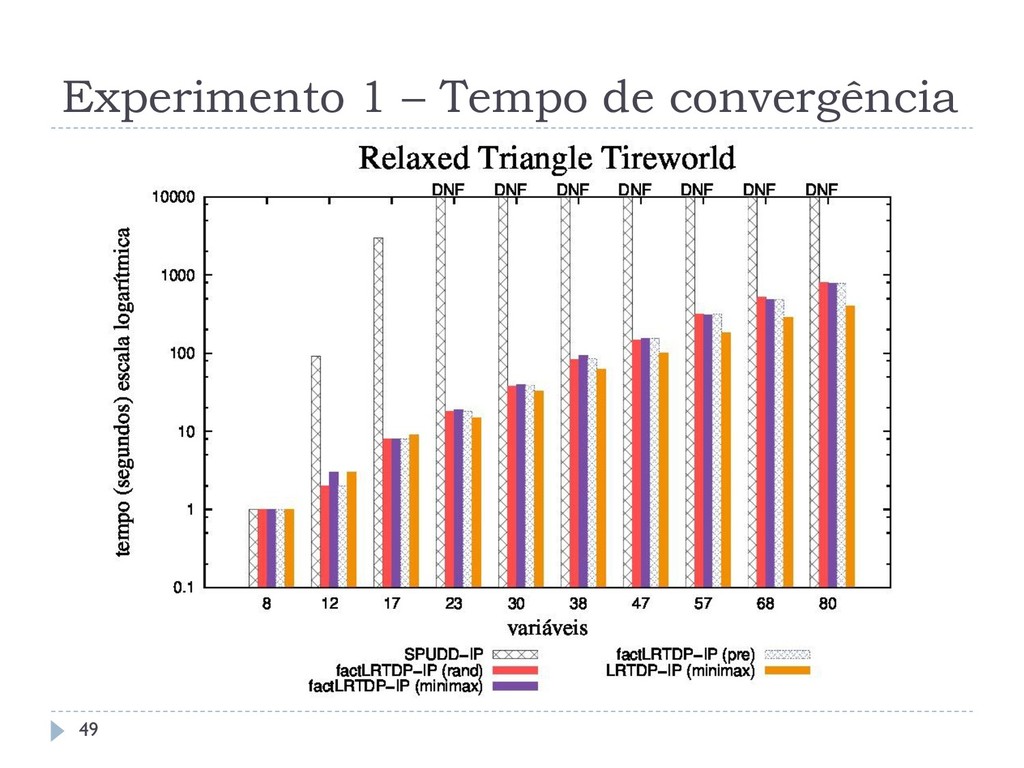
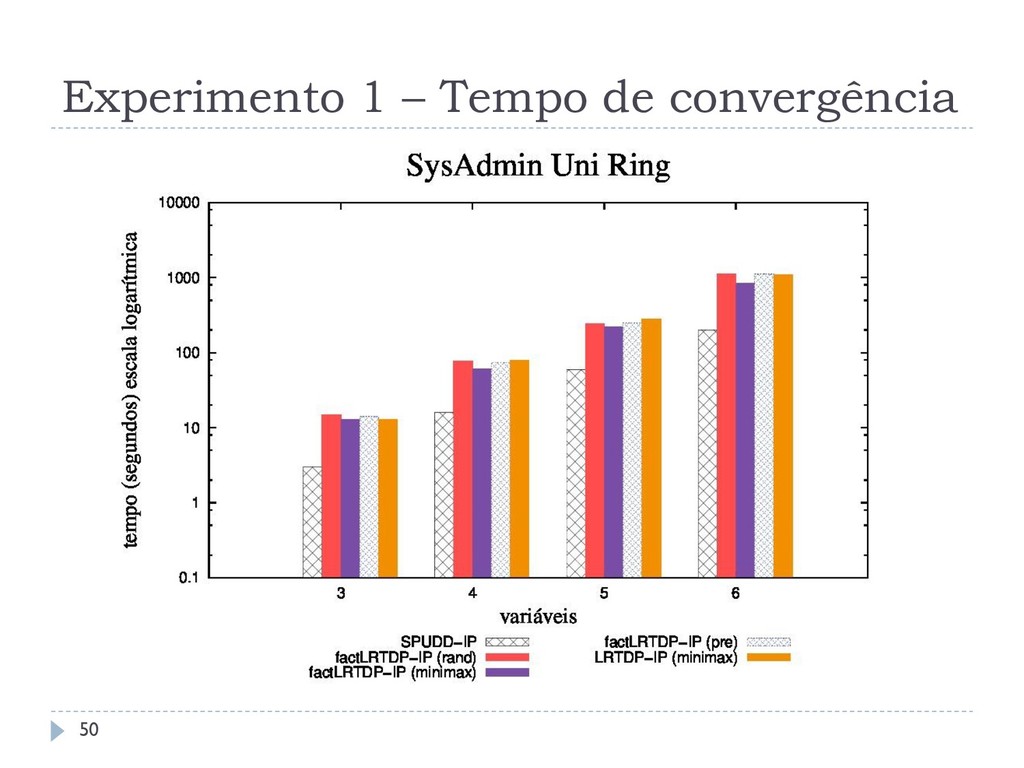
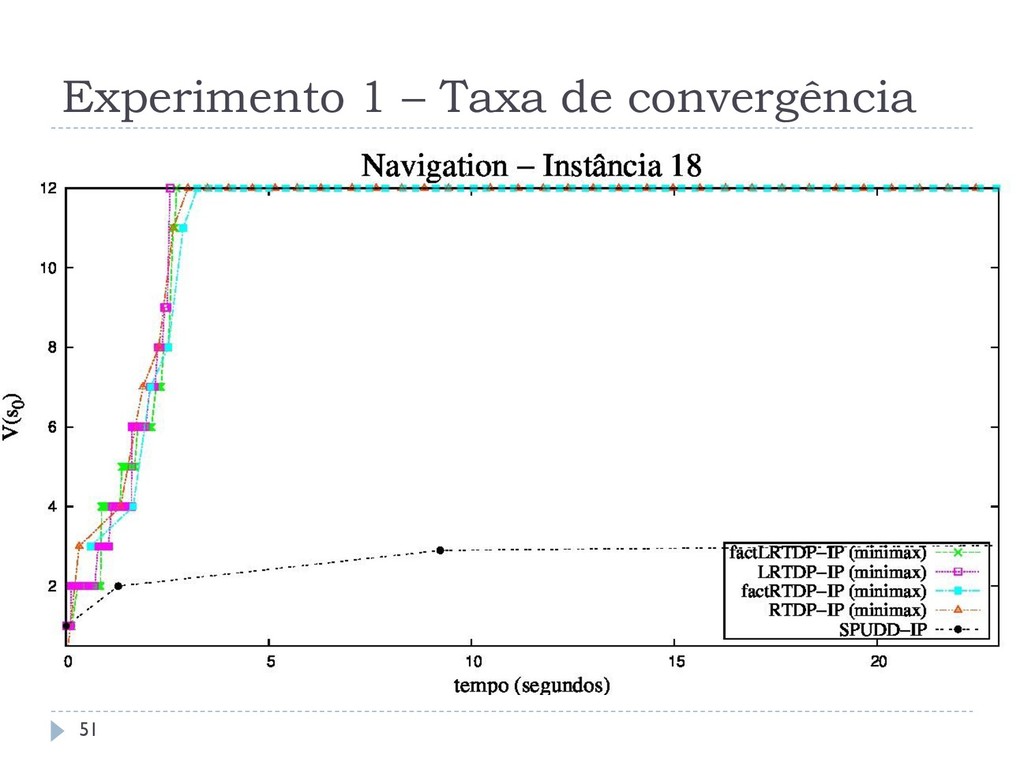
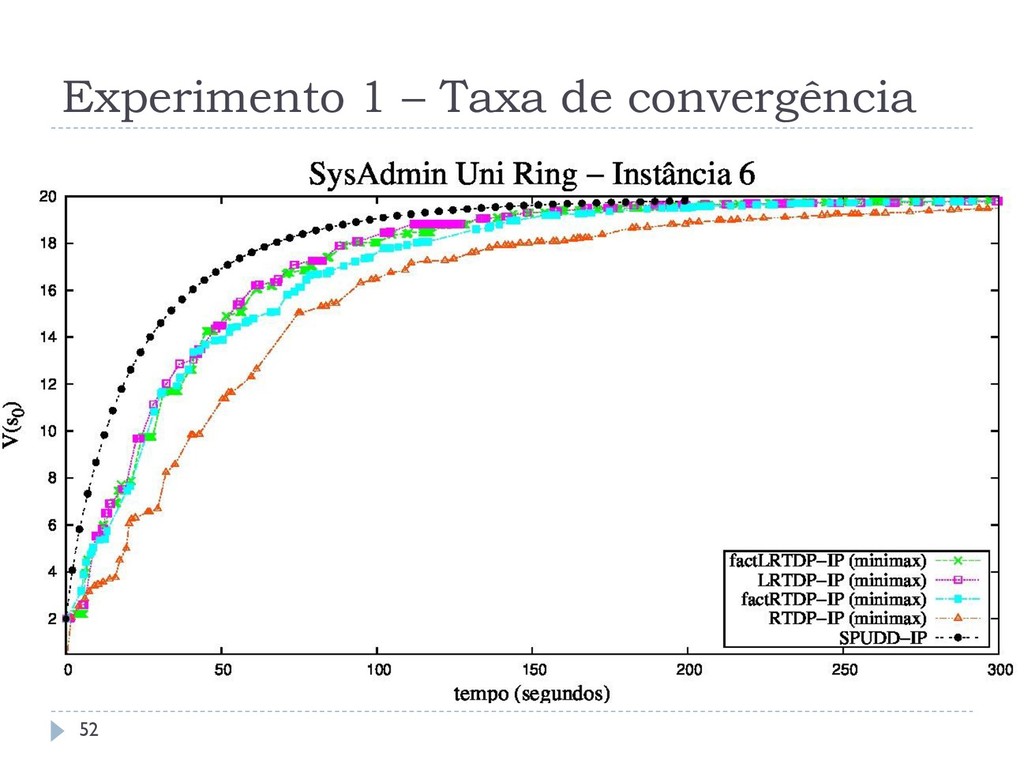
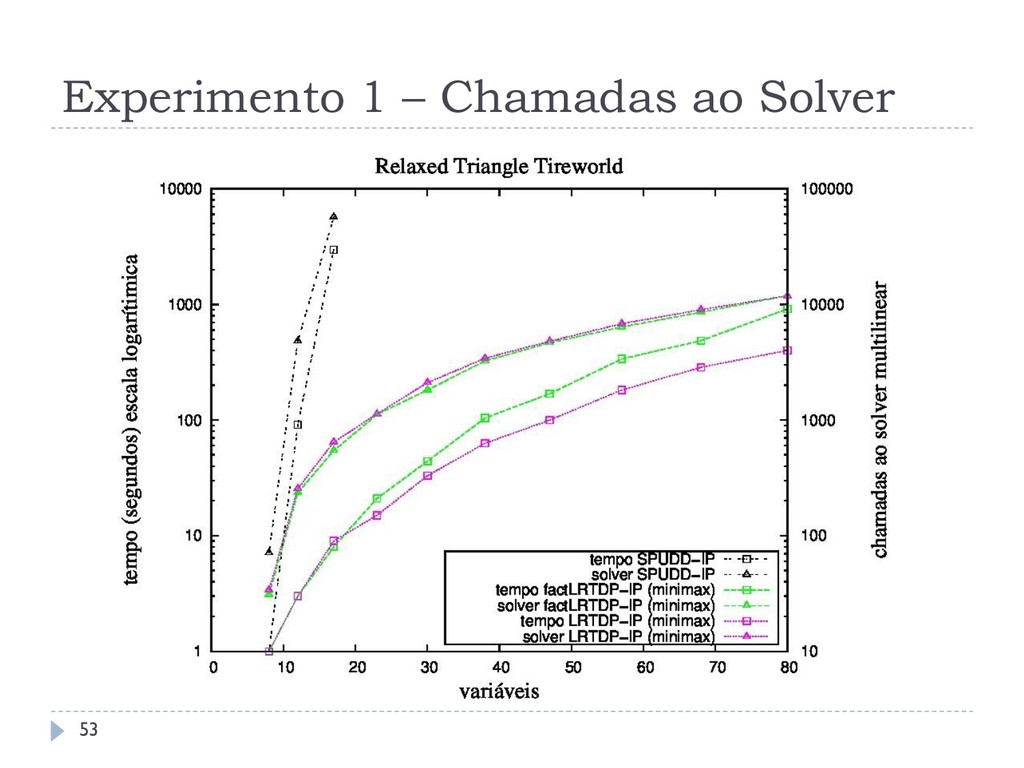
os algoritmos assíncronos RTDP-IP, LRTDP-IP, factRTDP-IP e factLRTDP-IP com o algoritmo síncrono estado- da-arte SPUDD-IP Outro comparando os algoritmos assíncronos LRTDP-IP e LSSiPP-IP Todos os algoritmos foram comparados em relação a: Tempo de Convergência Taxa de Convergência Chamadas ao Solver 46
domínios: Navigation (IPPC-2011) Relaxed Triangle Tireworld (IPPC-2005) SysAdmin, topologia Uniring (Guestrin et al, 2003) Todos os domínios foram adaptados para SSP MDP-IPs, a partir do RDDL e do PPDDL. Em domínios com deadends, todos os algoritmos tem tratamento para detectá-los. 47
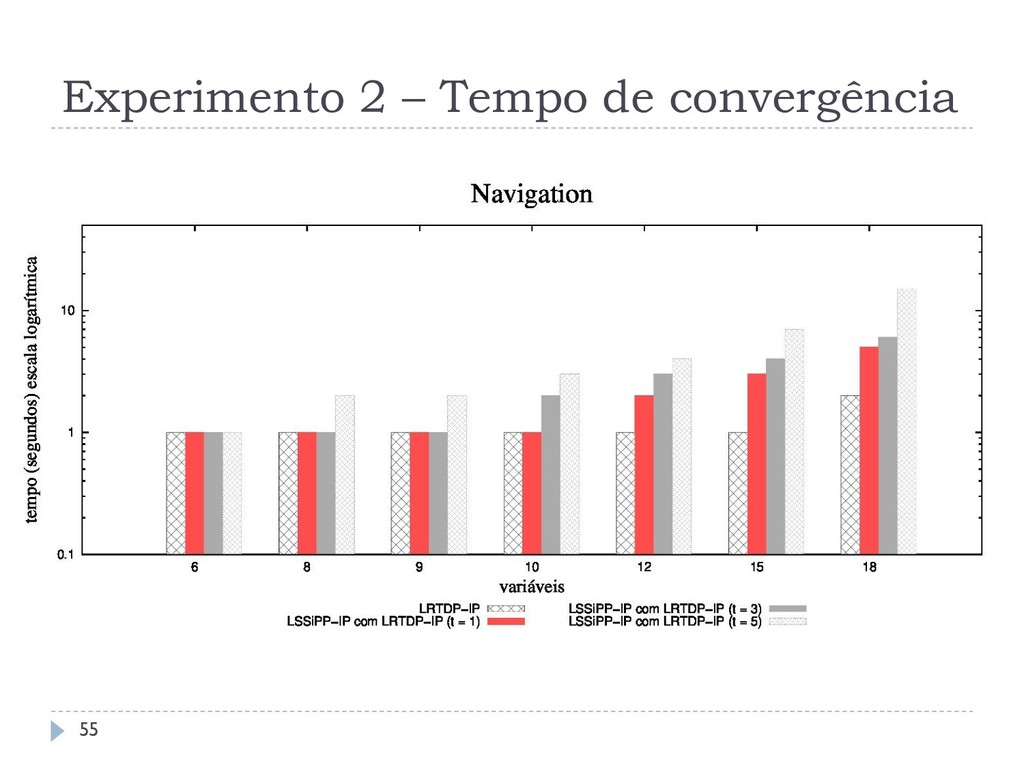
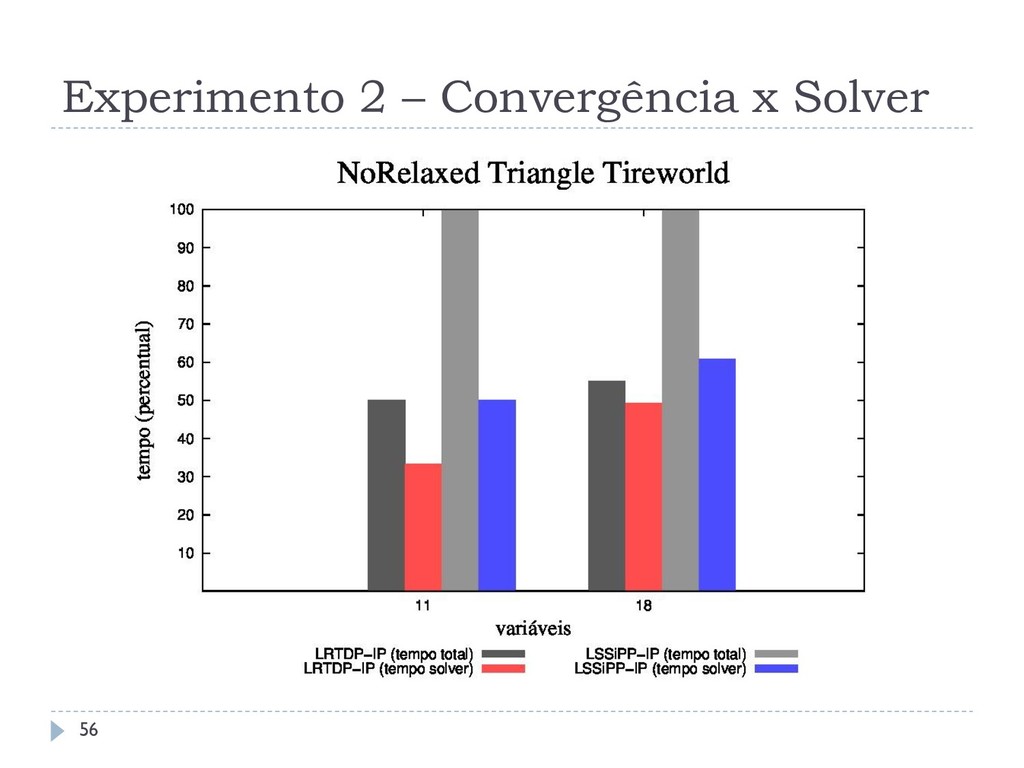
domínios: Navigation (IPPC-2011) Relaxed Triangle Tireworld (IPPC-2005) NoRelaxed Triangle Tireworld (IPPC-2005) A execução do LSSiPP-IP é feita com = 1, 3, 5 . Os algoritmos utilizam o minimax_parameter_choice. A detecção de deadends é realizada da mesma forma que no experimento anterior. 54
para SSP MDP-IPs Criação de métodos de amostragem para o próximo estado Algoritmos de programação dinâmica assíncrona para Short-Sighted SSP MDP-IP 58
que o SPUDD-IP em até três ordens, resolvendo problemas com até 120 variáveis Esta melhoria não se aplica em domínios densos Os diferentes métodos de amostragem não interferem no tempo de execução dos algoritmos O LSSiPP-IP não consegue ser melhor que o LRTDP-IP, não reproduzindo o comportamento observado em SSP MDPs 59
(Kolobov et al, 2010) Propor novas funções valor admissíveis para Short- Sighted SSP MDP-IPs Adaptar outros algoritmos assíncronos de SSP MDPs para os SSP MDP-IPs Investigar abordagens Bayesianas para SSP MDP-IPs 60
Bradtke e Satinder P. Singh. Learning to act using real-time dynamic programming. Artificial Intelligence, 72:81 - 138. ISSN 0004-3702. Bertsekas e Tsitsiklis(1991) Dimitri P. Bertsekas e John N. Tsitsiklis. An analysis of stochastic shortest path problems. Math. Oper. Res., 16(3):580 - 595. ISSN 0364-765X. Bonet e Geffner(2003) B. Bonet e H. Geffner. Labeled RTDP: Improving the convergence of real-time dynamic programming. Proceedings of 2003 International Conference on Automated Planning and Scheduling, páginas 12-21. Buffet e Aberdeen(2005) Olivier Buffet e Douglas Aberdeen. Robust planning with LRTDP. Em Proceedings of 2005 International Joint Conference on Artificial Intelligence, páginas 1214-1219. 61
120:199-233. Cozman(2005) F. G. Cozman. Graphical models for imprecise probabilities. International Journal of Approximate Reasoning, 39(2-3):167-184. Delgado et al.(2011) Karina Valdivia Delgado, Scott Sanner e Leliane Nunes de Barros. Efficient solutions to factored MDPs with imprecise transition probabilities. Artificial Intelligence, 175:1498 - 1527. ISSN 0004-3702 Devroye(1986) Luc Devroye. Non-Uniform Random Variate Generation. Springer-Verlag. 62
Parr e Shobha Venkataraman. Efficient solution algorithms for factored MDPs. Journal of Artificial Intelligence Research, 19:399-468. Holguin(2013) Mijail Gamarra Holguin. Planejamento probabilístico usando programação dinâmica assíncrona e fatorada. Dissertação de Mestrado, IME-USP. Patek e Bertsekas(1999) Stephen D Patek e Dimitri P Bertsekas. Stochastic shortest path games. SIAM Journal on Control and Optimization, 37(3):804-824. Trevizan(2013) Felipe W Trevizan. Short-sighted Probabilistic Planning. Tese de Doutorado, Carnegie Melon. 63
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}