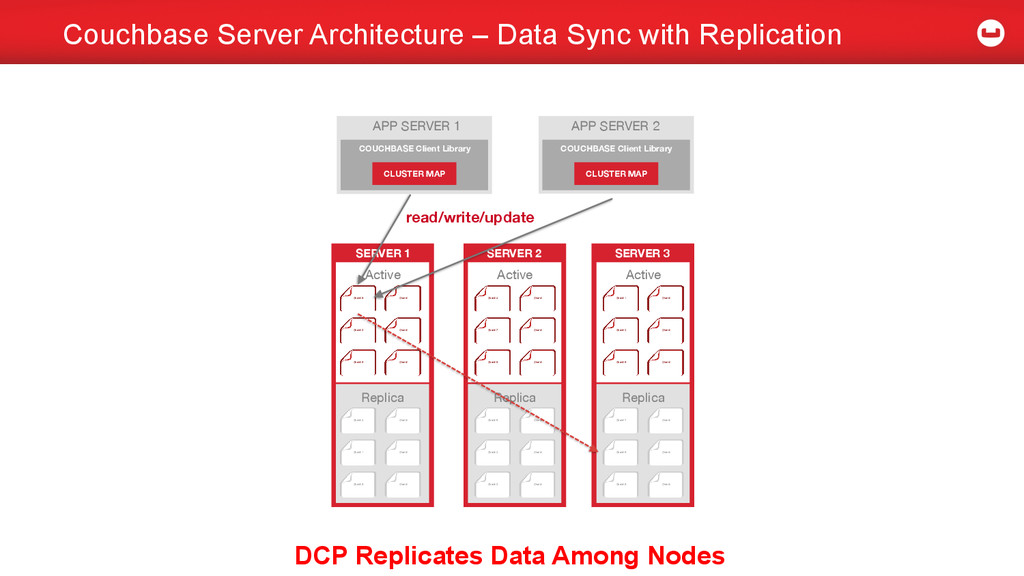
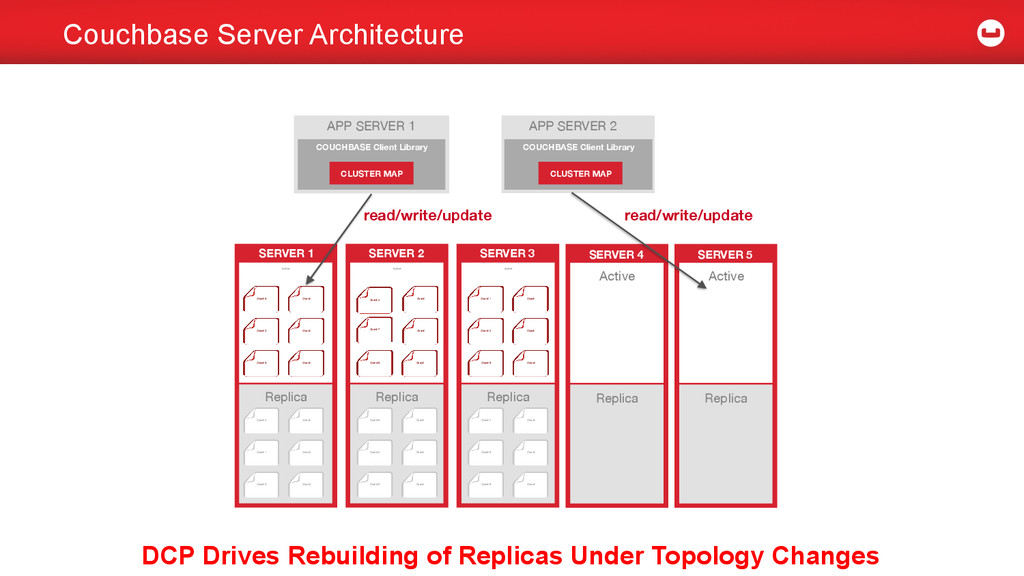
Fundamental piece of the architecture - Data Sync maintains Data Redundancy for High Availability (HA) & Disaster Recovery (DR) - Protect against failures – node, rack, region etc. - Data Sync maintains Indexes - Indexing is key to building faster access paths to query data - Spatial, Full-text DCP and Couchbase Server Architecture
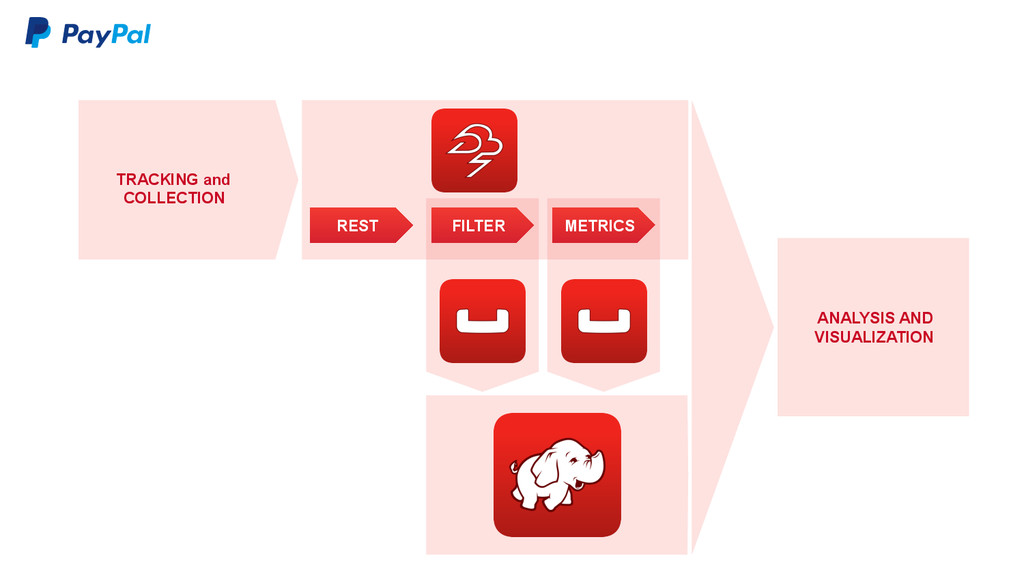
data sync for Couchbase Server • Increase data sync efficiency with massive data footprints • Remove slower Disk-IO from the data sync path • Improve latencies – replication for data durability • In future, will provide a programmable data sync protocol for external stores outside Couchbase Server DCP powers many critical components What is DCP? 11
have a concept of when operations happened. Couchbase operation ordering at the node level: § Each mutation is assigned a sequence number § Sequence numbers increase monotonically § Sequence numbers are assigned on a per VBucket basis Restart-ability Need to handle failures with grace, in particular being efficient about the amount of data being moved around. Consistency points Points in time for incremental backup, query consistency. Performance Recognize that durability on a distributed system may have different definitions. Design Goals 15
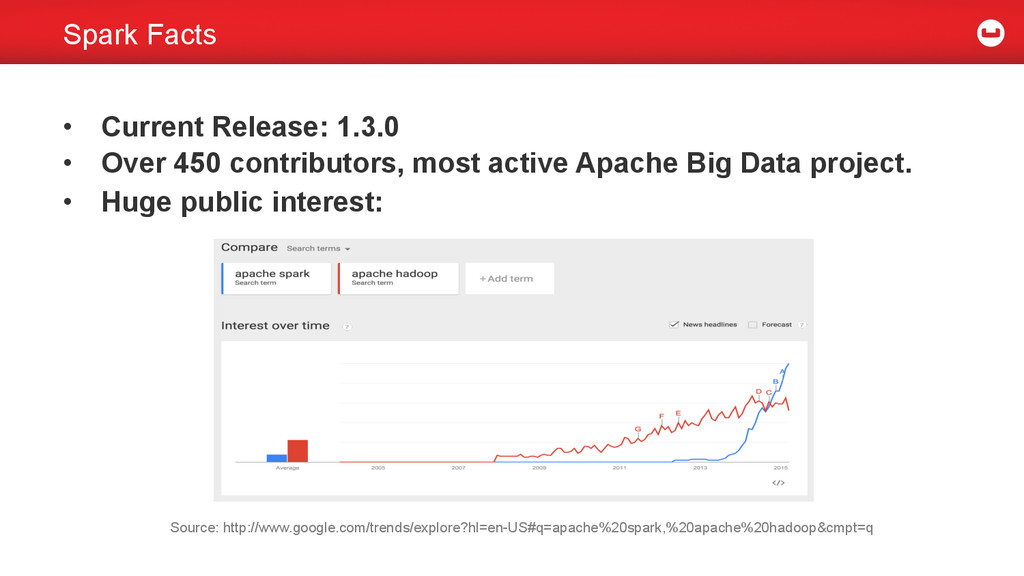
most active Apache Big Data project. • Huge public interest: Source: http://www.google.com/trends/explore?hl=en-US#q=apache%20spark,%20apache%20hadoop&cmpt=q
HDFS (disk) bound • API easier to reason about & to develop against • Fully compatible with Hadoop Input/Output formats • Hadoop more mature, Spark ecosystem growing fast
RDDs in, and apply a few transformations… sc.couchbaseGet[JsonDocument(Seq( "21st_amendment_brewery_cafe-‐21a_ipa", "aass_brewery-‐genuine_pilsner")) .map(doc => doc.content().getString("name")) .collect() .foreach(println)
subfilter, and then map over them… // Read the first 10 rows and load their full documents val beers = sc.couchbaseView(ViewQuery.from("beer", "brewery_beers")) .map(_.id) .couchbaseGet[JsonDocument]() .filter(doc => doc.content().getString("type") == "beer") .cache() // Calculate the mean for all beers println(beers .map(doc => doc.content().getDouble("abv").asInstanceOf[Double]) .mean())
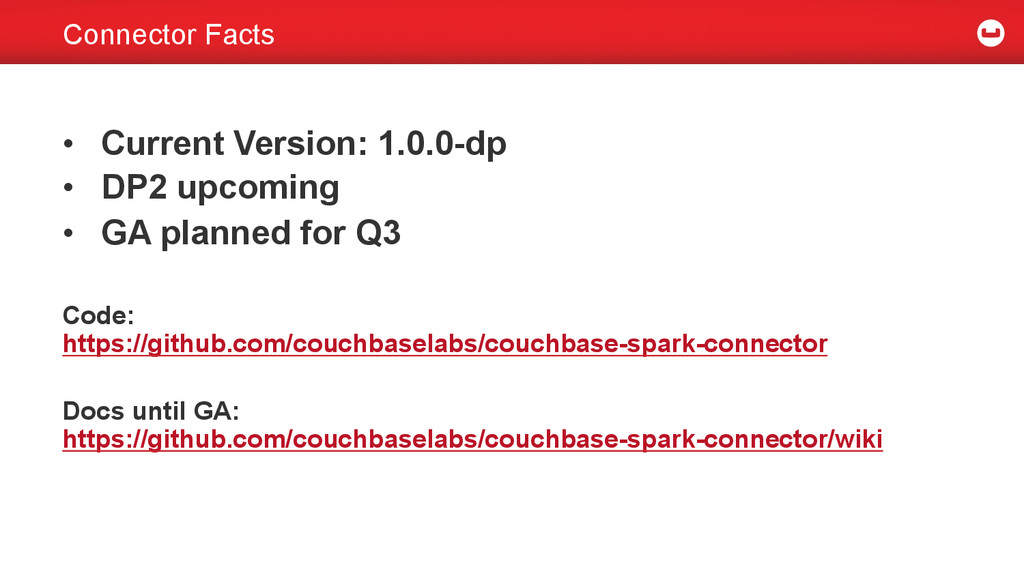
GA planned for Q3 Code: https://github.com/couchbaselabs/couchbase-spark-connector Docs until GA: https://github.com/couchbaselabs/couchbase-spark-connector/wiki
Couchbase is hiring a Solution Engineer in Paris • http://www.couchbase.com/careers • Join Paris Couchbase Meetup • http://www.meetup.com/Couchbase-France/
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
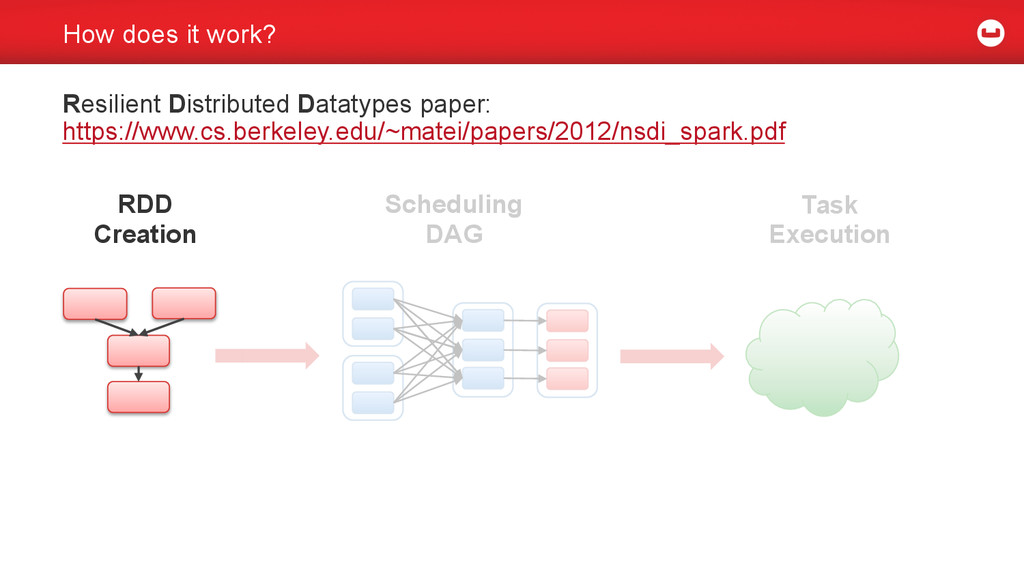{kind=link}
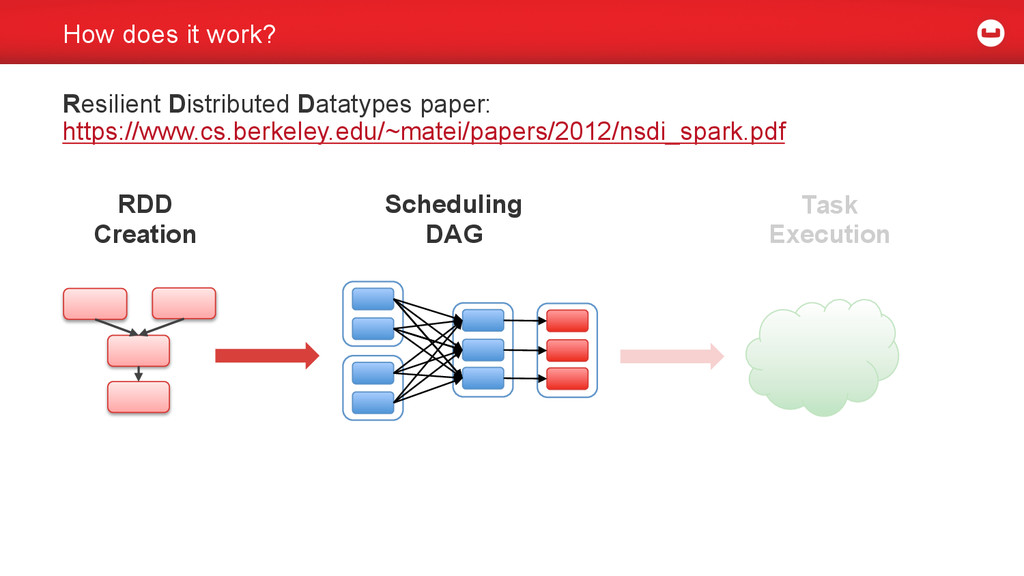{kind=link}
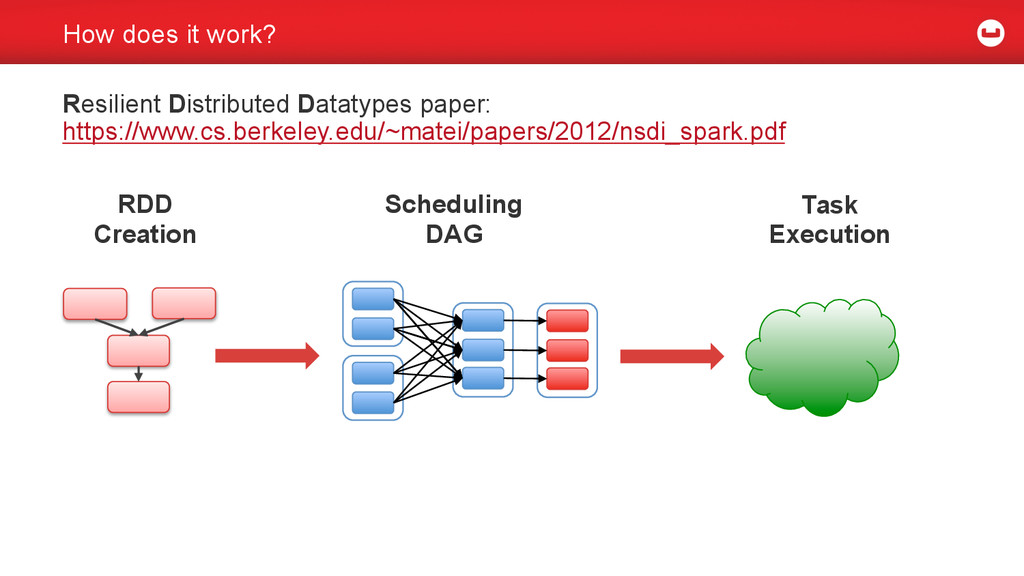{kind=link}
{kind=link}
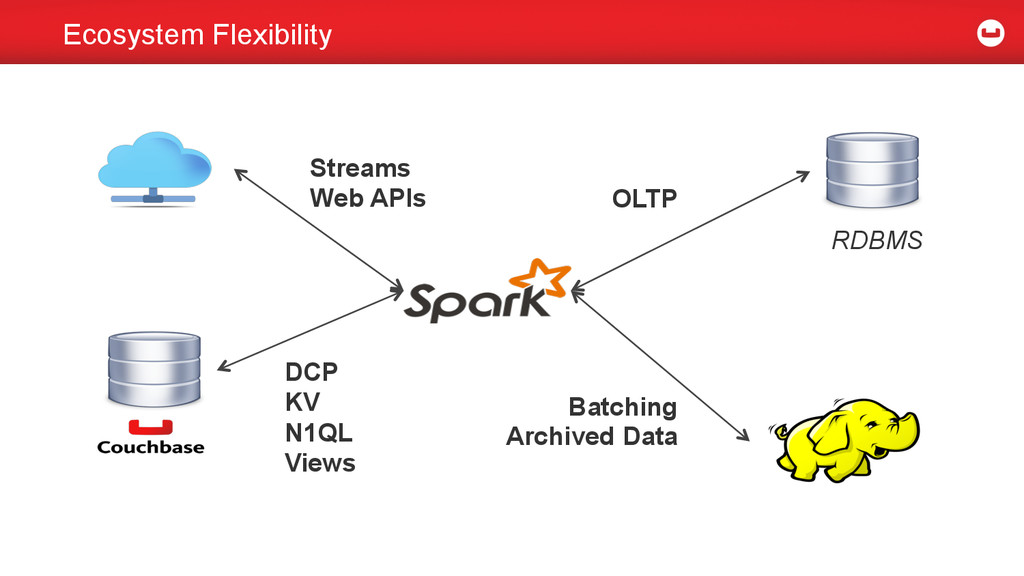{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}