Pycon Colombia 2018
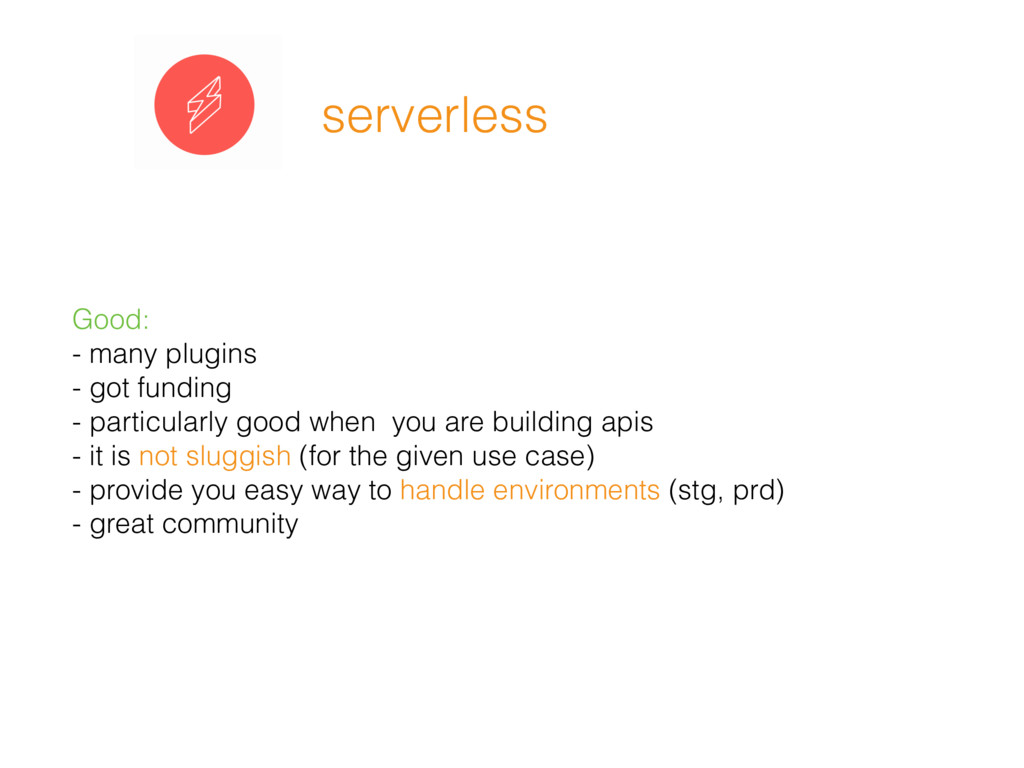
One year ago I joined a team that favours Serverless, since then I’ve been building and maintaining lots of services using Serverless. With a pinch of Skepticism, I sailed through some of the challenges and tooling, I want to share with the community the pains and glory of it.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
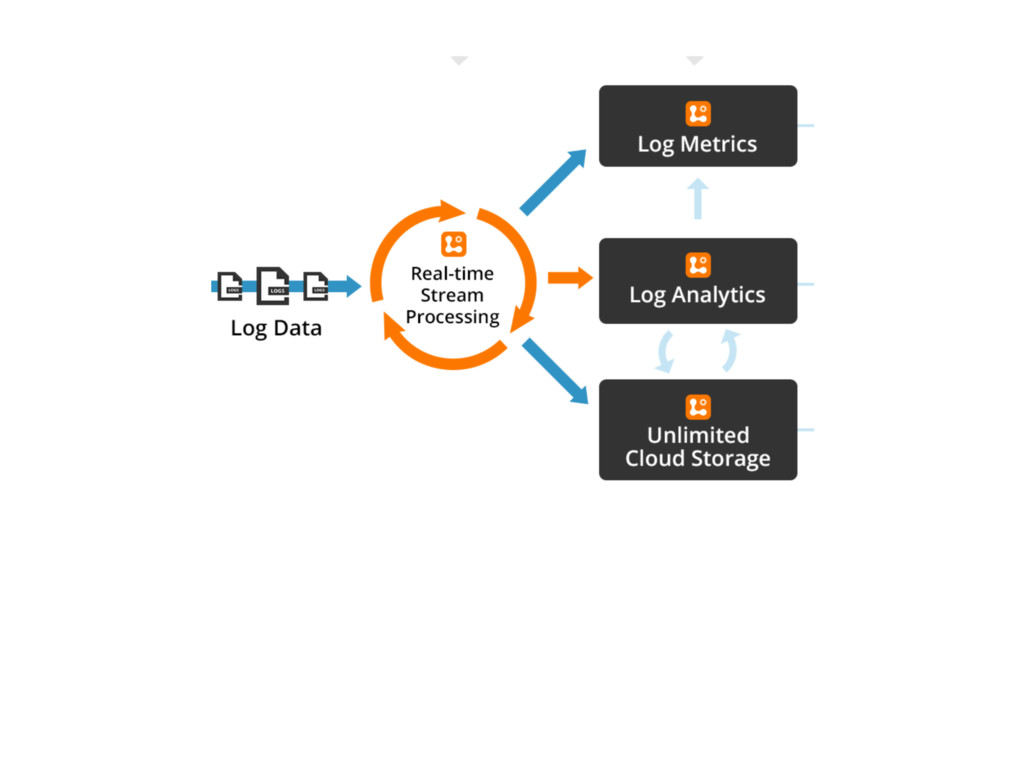{kind=link}
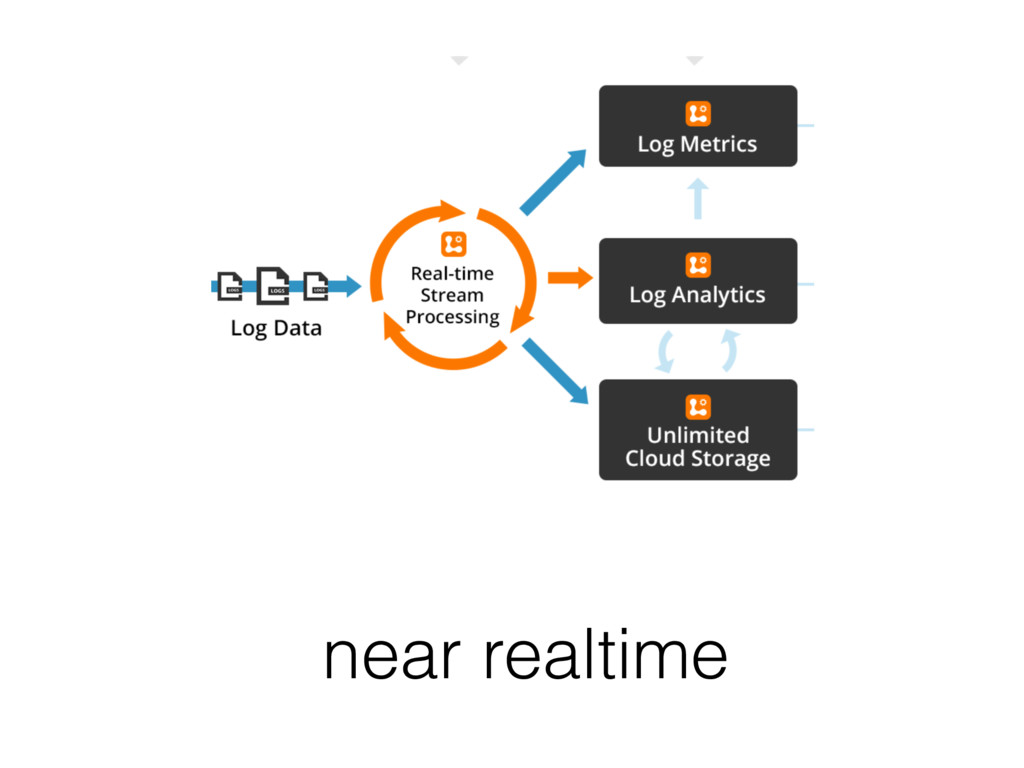{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![def handler(event, context): # do something url = event[‘url’] scrape(url)](https://files.speakerdeck.com/presentations/0fff5356df8748a489be2f5fe4e52a1d/slide_56.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
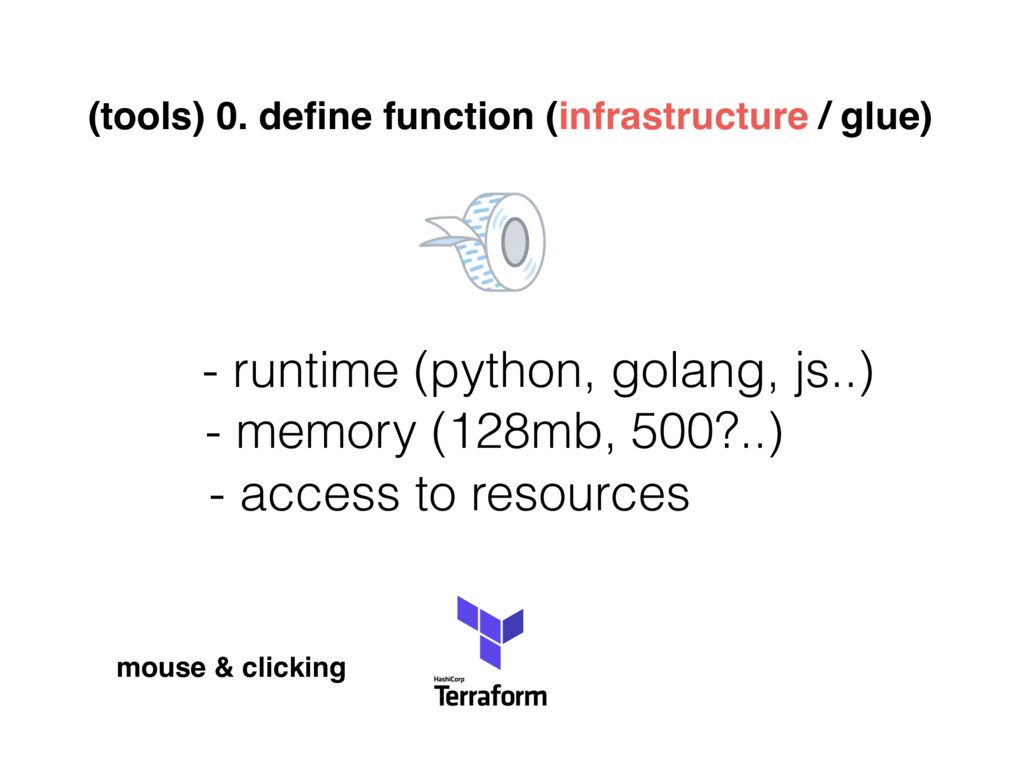{kind=link}
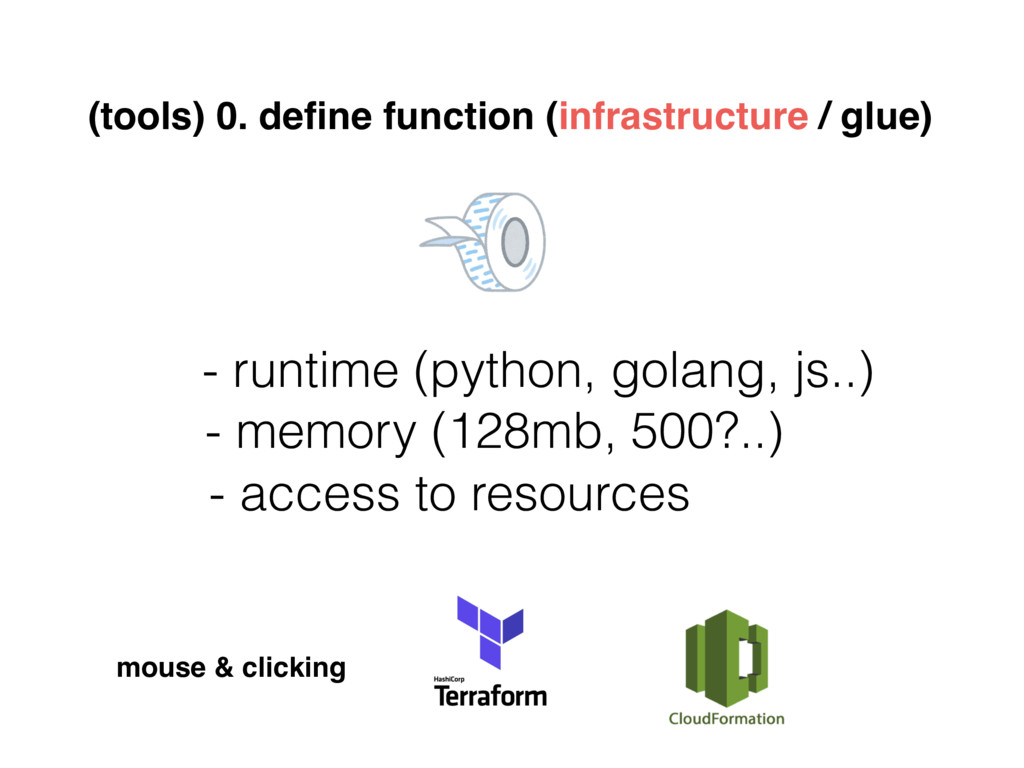{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
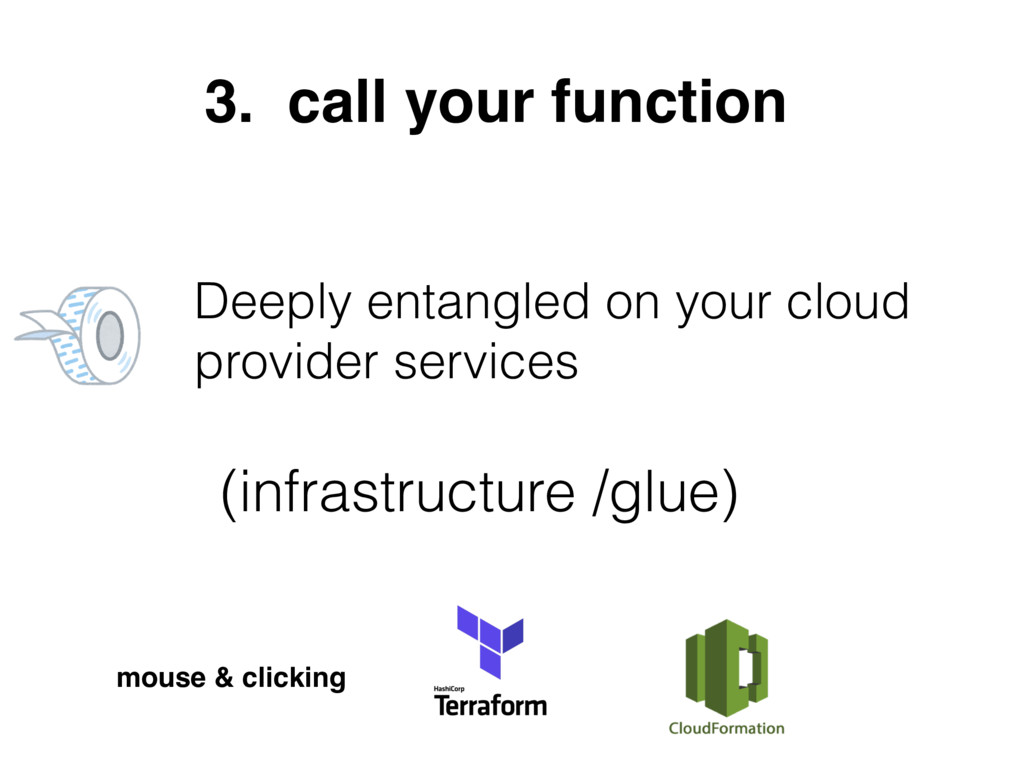{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
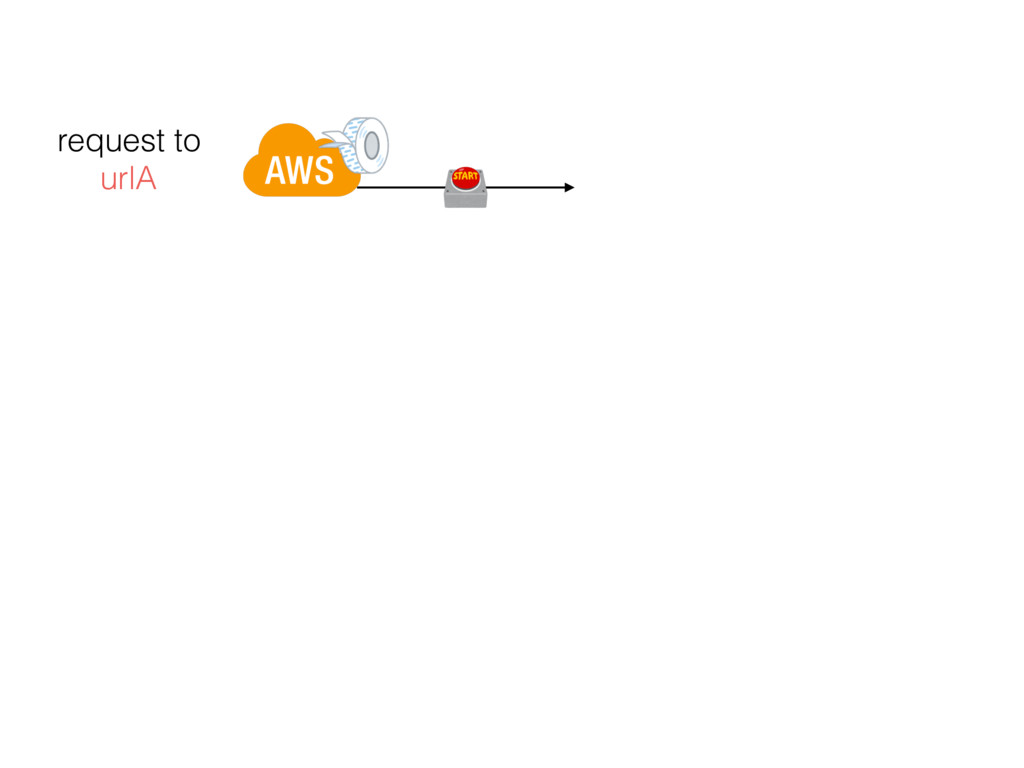{kind=link}
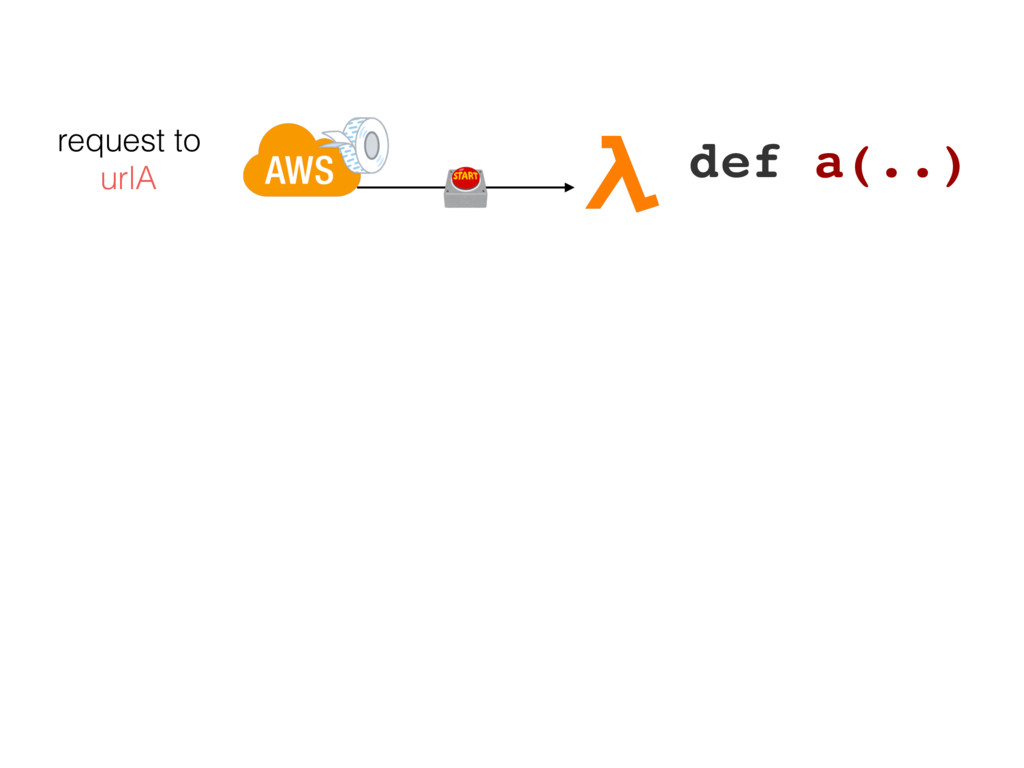{kind=link}
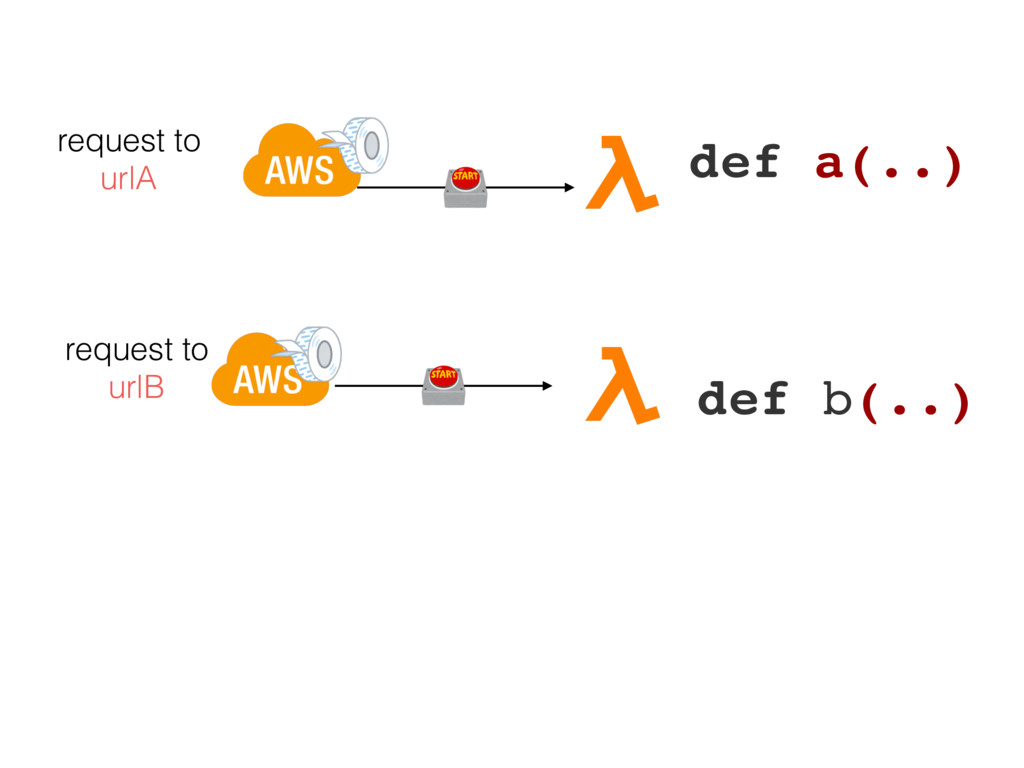{kind=link}
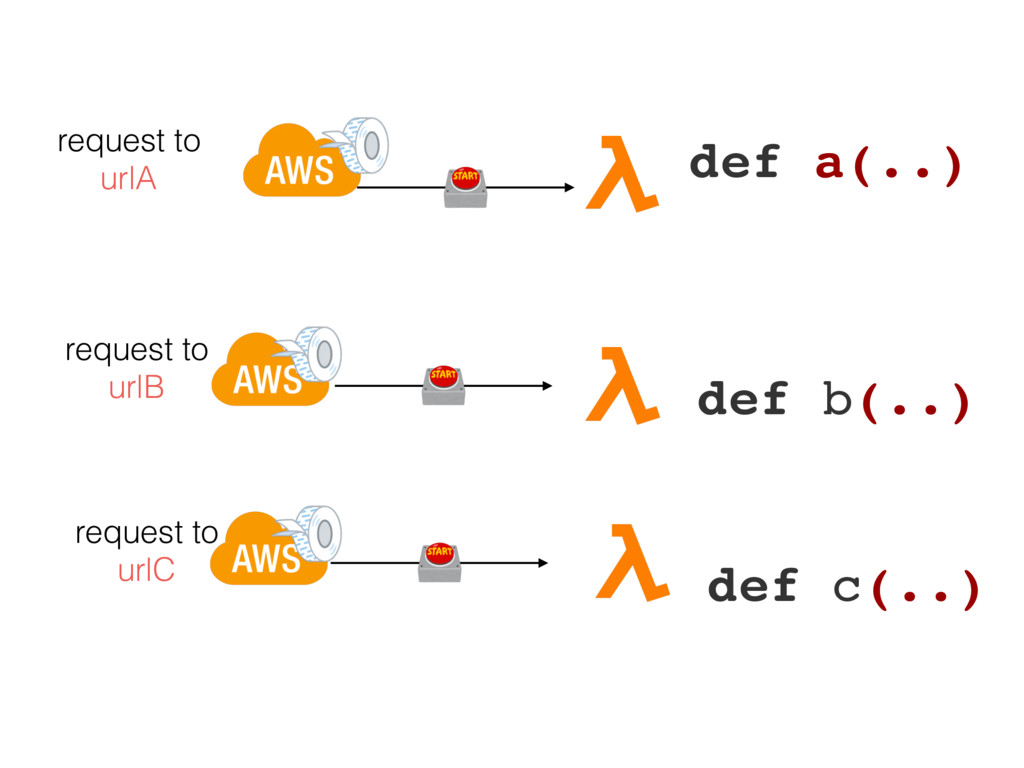{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
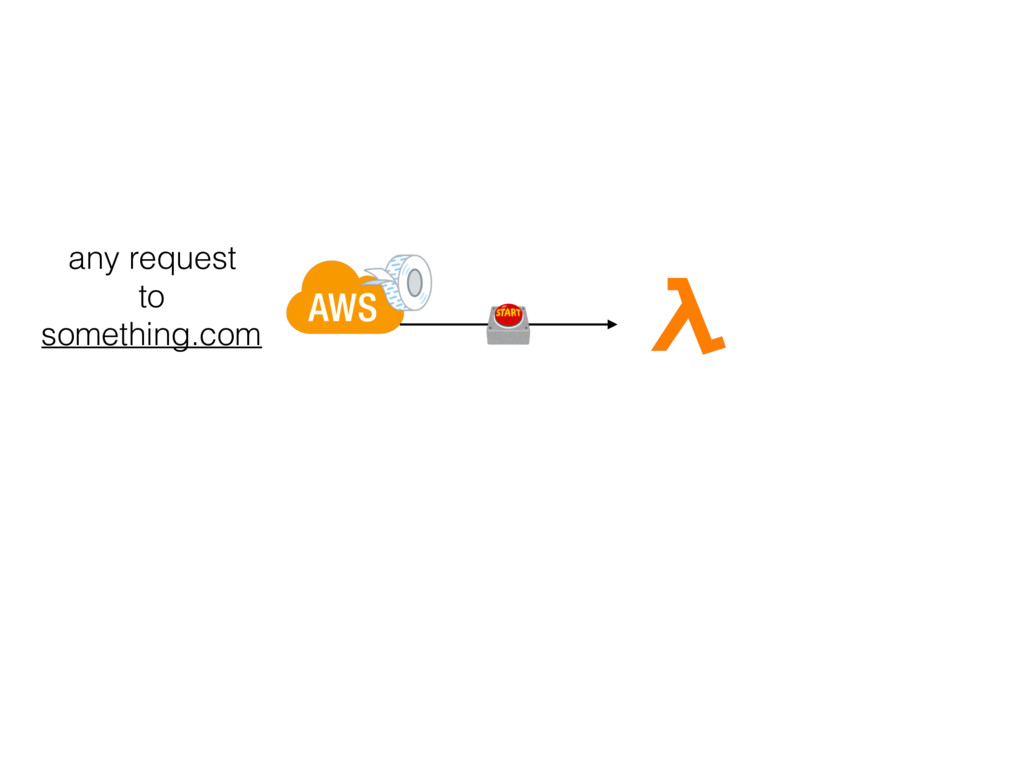{kind=link}
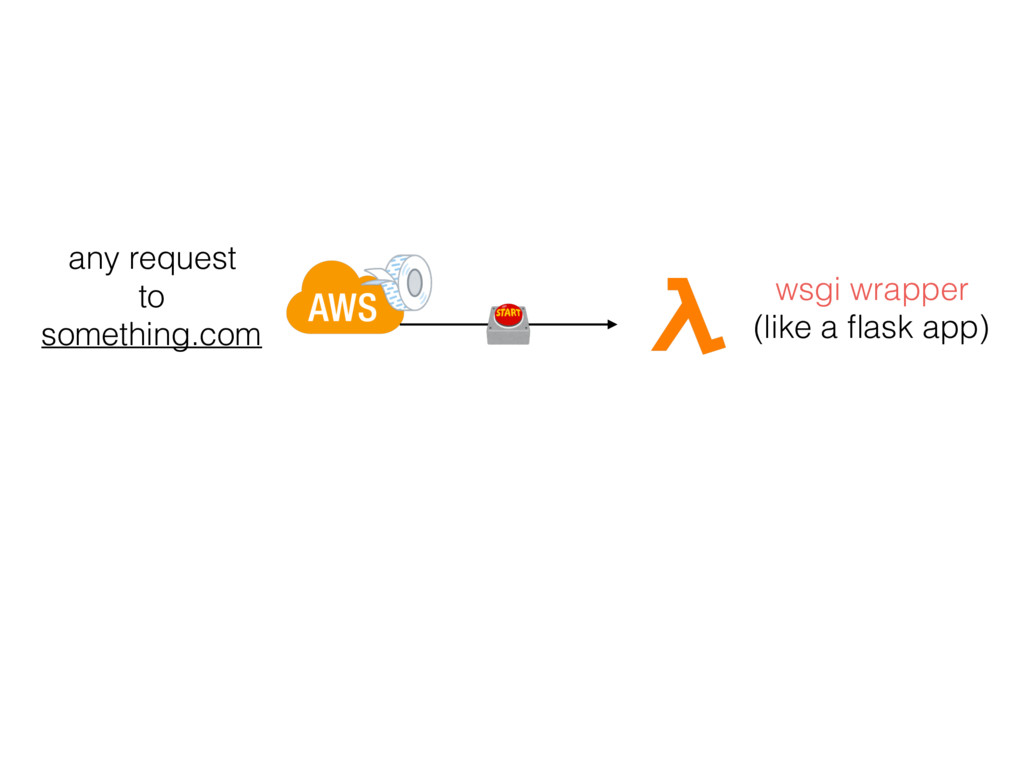{kind=link}
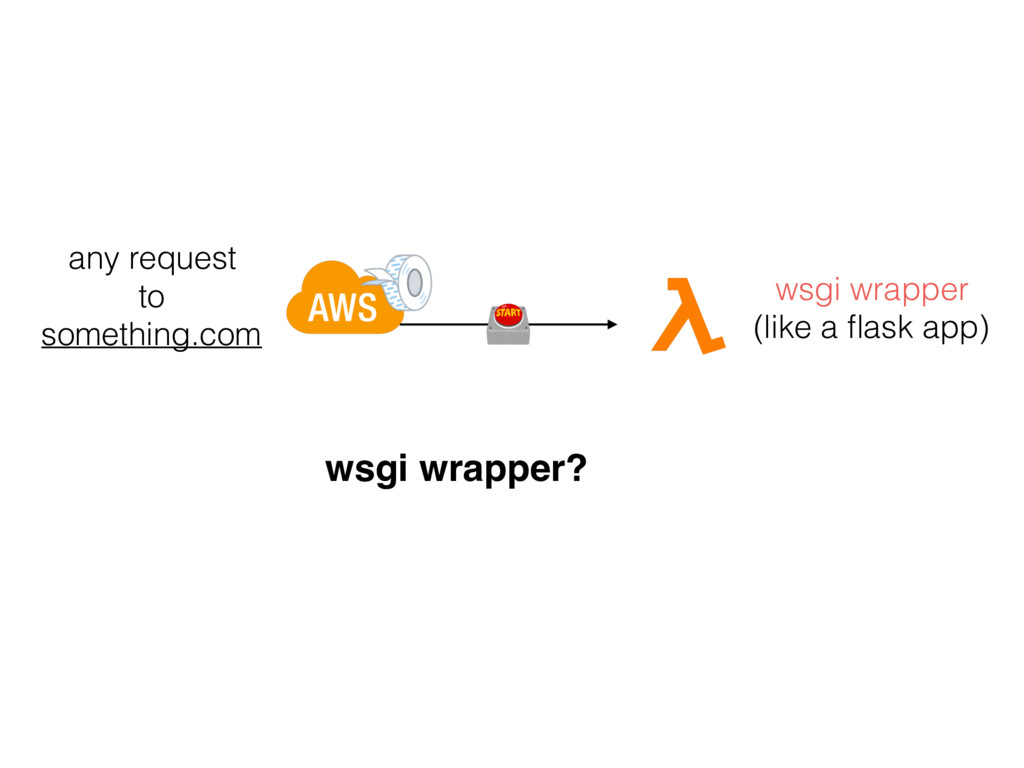{kind=link}
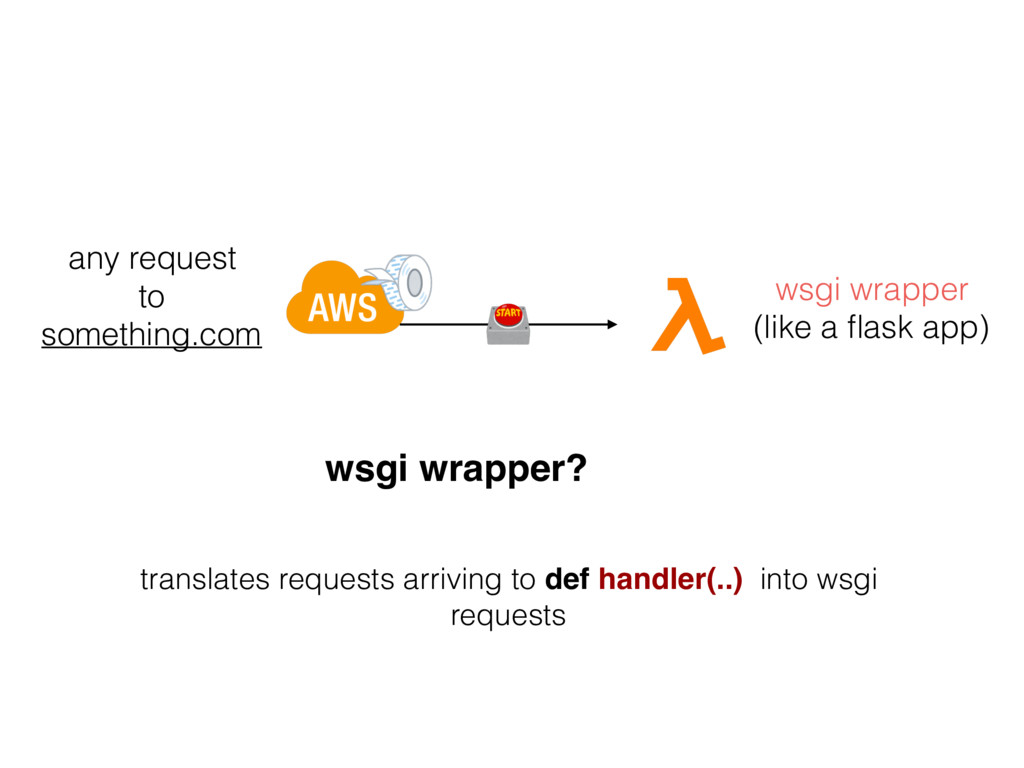{kind=link}
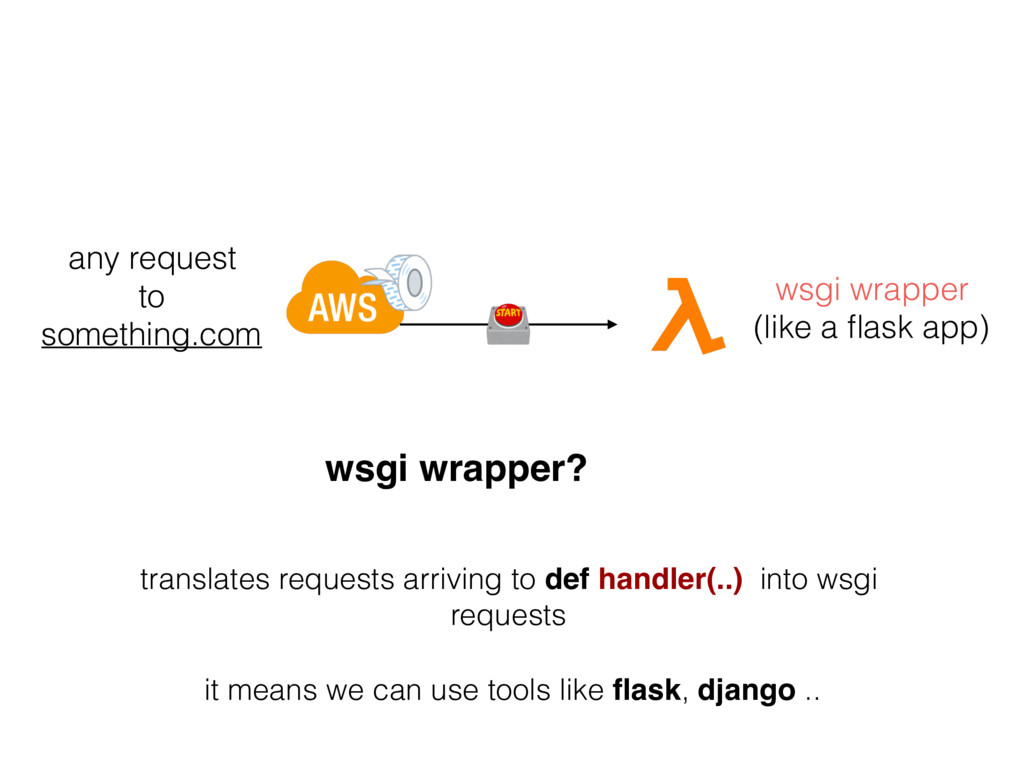{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
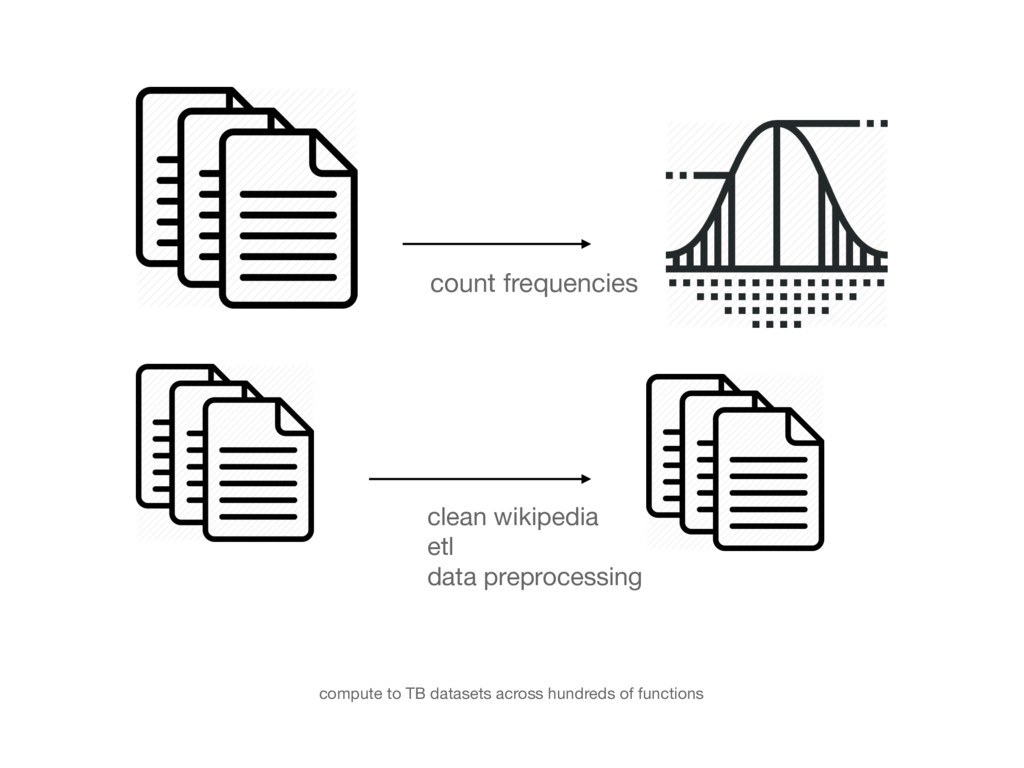{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
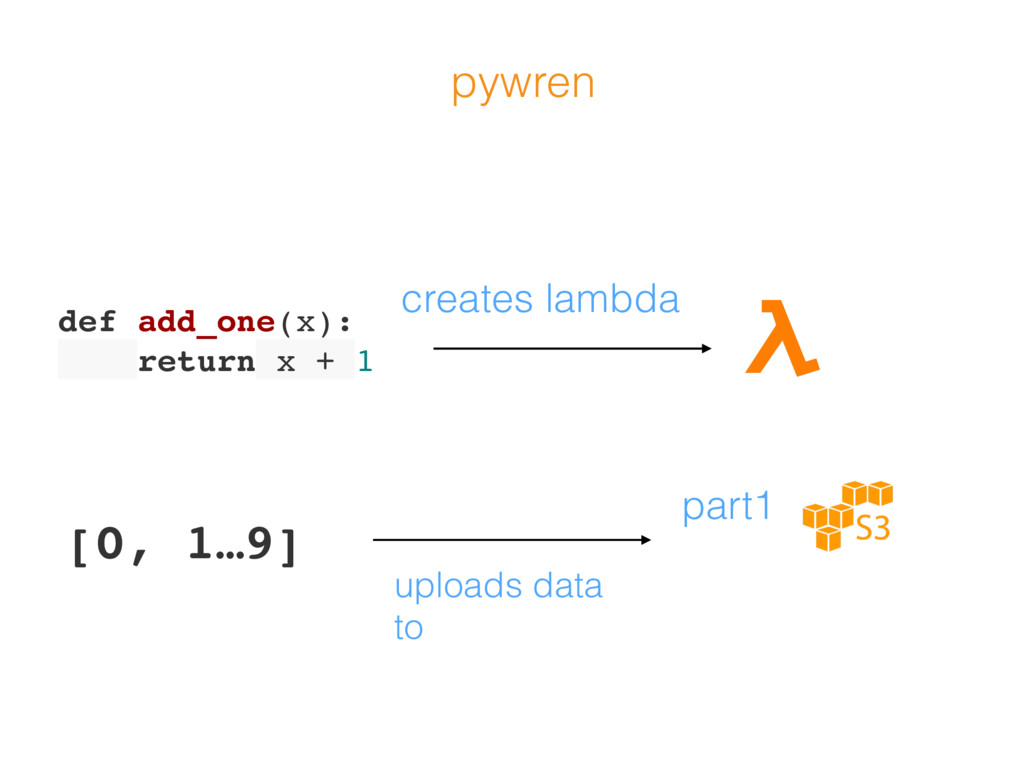
![def add_one(x): return x + 1 [0, 1…9] pywren](https://files.speakerdeck.com/presentations/0fff5356df8748a489be2f5fe4e52a1d/slide_158.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
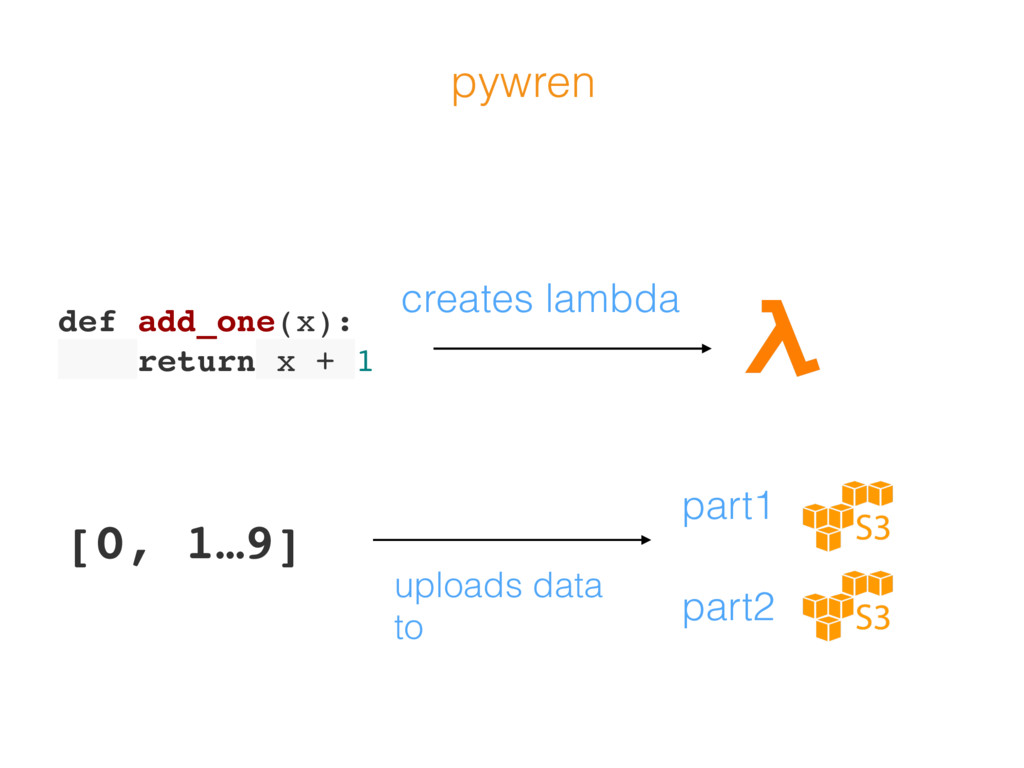
{kind=link}
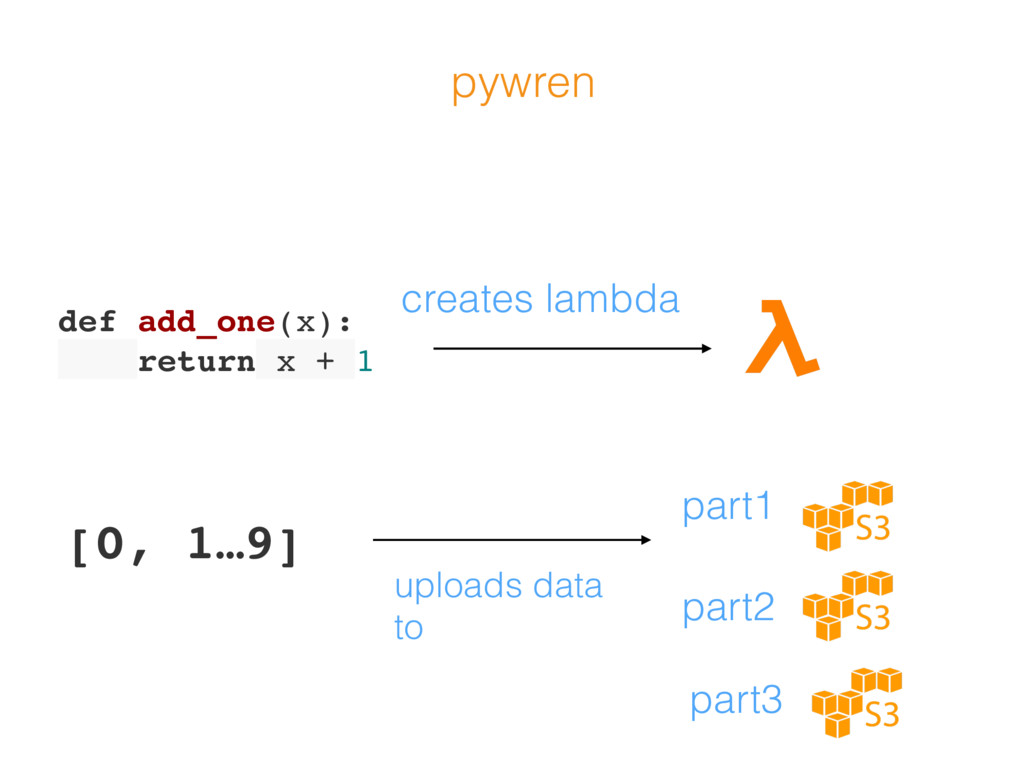
{kind=link}
{kind=link}
![pywren def add_one(x): return x + 1 [0, 1…9]](https://files.speakerdeck.com/presentations/0fff5356df8748a489be2f5fe4e52a1d/slide_167.jpg){kind=link}
![pywren def add_one(x): return x + 1 [0, 1…9] add_one(0)](https://files.speakerdeck.com/presentations/0fff5356df8748a489be2f5fe4e52a1d/slide_168.jpg){kind=link}
![pywren def add_one(x): return x + 1 [0, 1…9] add_one(0)](https://files.speakerdeck.com/presentations/0fff5356df8748a489be2f5fe4e52a1d/slide_169.jpg){kind=link}
![pywren def add_one(x): return x + 1 [0, 1…9] add_one(0)](https://files.speakerdeck.com/presentations/0fff5356df8748a489be2f5fe4e52a1d/slide_170.jpg){kind=link}
![pywren def add_one(x): return x + 1 [0, 1…9] add_one(0)](https://files.speakerdeck.com/presentations/0fff5356df8748a489be2f5fe4e52a1d/slide_171.jpg){kind=link}
![pywren def add_one(x): return x + 1 [0, 1…9] add_one(0)](https://files.speakerdeck.com/presentations/0fff5356df8748a489be2f5fe4e52a1d/slide_172.jpg){kind=link}
![pywren def add_one(x): return x + 1 [0, 1…9] add_one(0)](https://files.speakerdeck.com/presentations/0fff5356df8748a489be2f5fe4e52a1d/slide_173.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![list_of_users = [‘admin’] def handler(a,b): list_of_users = list_of_users + a[‘user’]](https://files.speakerdeck.com/presentations/0fff5356df8748a489be2f5fe4e52a1d/slide_200.jpg){kind=link}
![list_of_users = [‘admin’] def handler(a,b): list_of_users = list_of_users + a[‘user’]](https://files.speakerdeck.com/presentations/0fff5356df8748a489be2f5fe4e52a1d/slide_201.jpg){kind=link}
![list_of_users = [‘admin’] def handler(a,b): list_of_users = list_of_users + a[‘user’]](https://files.speakerdeck.com/presentations/0fff5356df8748a489be2f5fe4e52a1d/slide_202.jpg){kind=link}
![list_of_users = [‘admin’] def handler(a,b): list_of_users = list_of_users + a[‘user’]](https://files.speakerdeck.com/presentations/0fff5356df8748a489be2f5fe4e52a1d/slide_203.jpg){kind=link}
![list_of_users = [‘admin’] def handler(a,b): list_of_users = list_of_users + a[‘user’]](https://files.speakerdeck.com/presentations/0fff5356df8748a489be2f5fe4e52a1d/slide_204.jpg){kind=link}
![list_of_users = [‘admin’] def handler(a,b): list_of_users = list_of_users + a[‘user’]](https://files.speakerdeck.com/presentations/0fff5356df8748a489be2f5fe4e52a1d/slide_205.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![serverless is [in my opinion] cheaper not simpler](https://files.speakerdeck.com/presentations/0fff5356df8748a489be2f5fe4e52a1d/slide_220.jpg){kind=link}
{kind=link}
{kind=link}
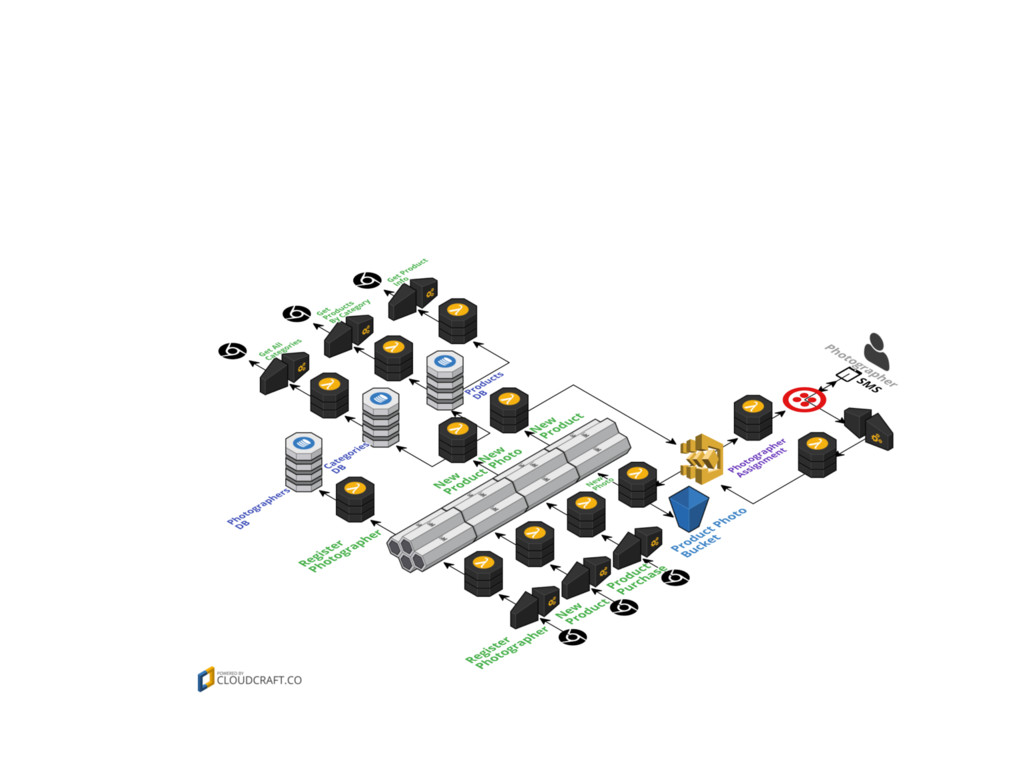{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}