Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
A Natural Language Pipeline
Search
ddqz
July 06, 2019
Technology
540
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
A Natural Language Pipeline
Presentation from the spaCy IRL 2019 conference.
ddqz
July 06, 2019
Other Decks in Technology
See All in Technology
5分でわかる Amazon Connect_20260608
hwangbyeonghun
0
160
MySQL & MySQL HeatWave Report - June 2026
freshdaz
0
260
AIをフル活用してオンコール機能のプロトタイプを2日で作った話 / Building an AI-Powered On-Call Prototype in Just Two Days
nari_ex
0
160
時期が悪い!それでもRaspberry Piを買って遊んで活用するには / 20260627-osc26do-rpi-jikigawarui
akkiesoft
1
960
秘密度ラベル初心者が第1歩でつまづかないための「設計・運用」ポイント
seafay
PRO
1
550
感情と身体を置き去りにしない、エンジニアの生きのこり方 ──いまから、ここから「自分の状態」を扱うという選択
saorimurooka
0
440
GitHub Copilot運用のリアル ~AI Credit時代にどう向き合うか~
takafumisu2uk1
0
590
背中から、背中へ /paying forward to community
naitosatoshi
0
200
AIDLC_ヤフーショッピングの取り組み
lycorptech_jp
PRO
0
350
製造現場での生成AIの活用、およびエージェントAIの実装のあり方、AVEVAの取り組み
iotcomjpadmin
0
210
Zenoh on Zephyr on LiteX
takasehideki
2
160
40代で“やっとエンジニアになれた”――閉じた学びを開き、空の青さを知る / 20260628 Naoki Takahashi
shift_evolve
PRO
4
1.5k
Featured
See All Featured
Fireside Chat
paigeccino
42
4k
The Curious Case for Waylosing
cassininazir
1
420
Save Time (by Creating Custom Rails Generators)
garrettdimon
PRO
32
3.6k
ラッコキーワード サービス紹介資料
rakko
1
3.8M
Designing Powerful Visuals for Engaging Learning
tmiket
1
430
[RailsConf 2023 Opening Keynote] The Magic of Rails
eileencodes
31
10k
Ruling the World: When Life Gets Gamed
codingconduct
0
270
The SEO identity crisis: Don't let AI make you average
varn
0
510
Effective software design: The role of men in debugging patriarchy in IT @ Voxxed Days AMS
baasie
0
440
The Psychology of Web Performance [Beyond Tellerrand 2023]
tammyeverts
49
3.5k
Art, The Web, and Tiny UX
lynnandtonic
304
22k
Marketing Yourself as an Engineer | Alaka | Gurzu
gurzu
0
250
Transcript
A Natural Language Pipeline
More Input
Knowledge” “A compendium of human...
Library
Physical archives became digital records, encoded with metadata
The internet promised rich dynamic experiences
The internet promised rich dynamic experiences but served us banner
ads
Advertising has and continues to fuel a substantial portion of
the innovation on the internet
What would The Economist look like if it were founded
in 2012?
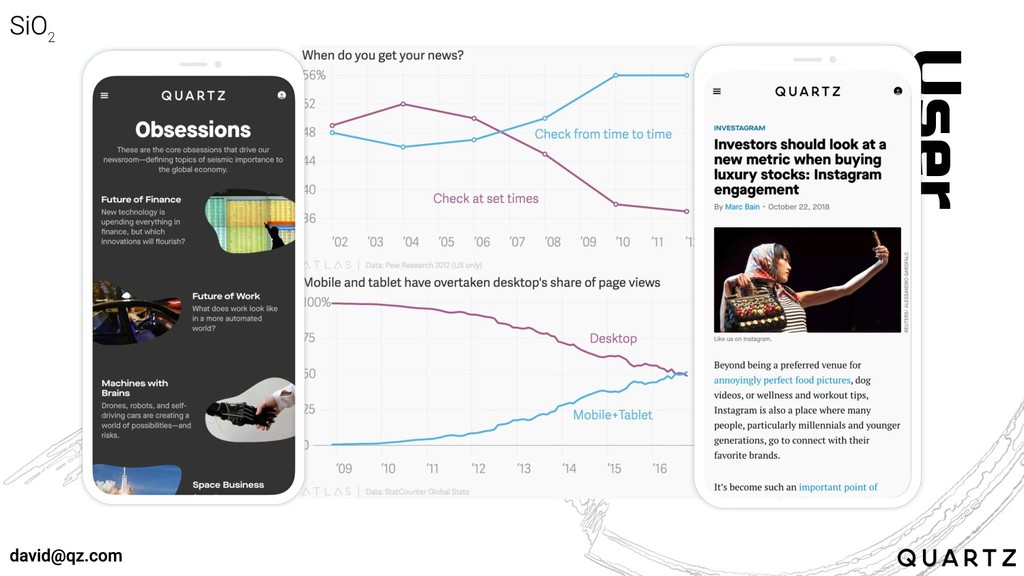
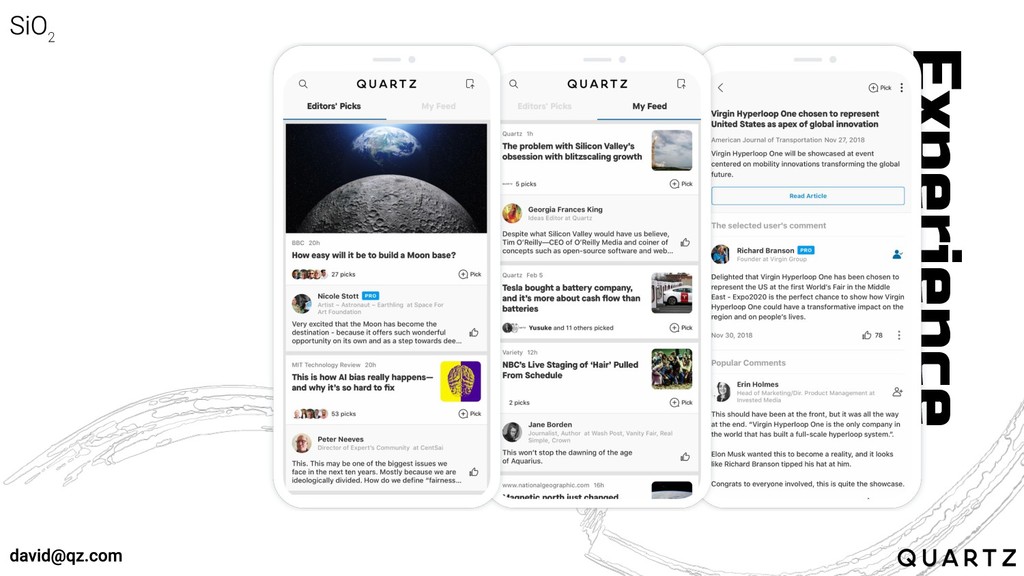
User
First
Experience
“There’s a reason that tech companies are topping the lists
of most valuable companies and brands. Every company is a tech company.” Maggie Chan Jones
Every story, at its core, is a business story
Language
None
None
Stage -> Stenographer -> Editors -> spaCy -> Data Store
<-> Backend <- Slack <- Users Proto-Pipeline
Over eight hours we created data from the content of
the event, building the model in real-time
The model evolved over time
This was the experiment that would evolve into SiO 2
Silicon, a key element in everything from glass to microchips,
is at the core of global business
Oxygen, the journalistic voice Quartz breathes into the global business
news cycle
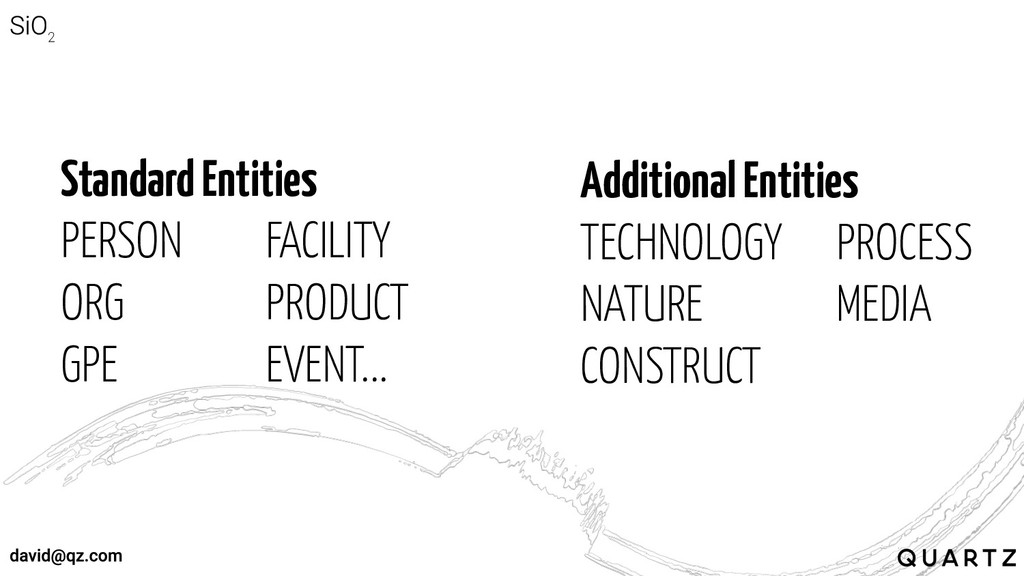
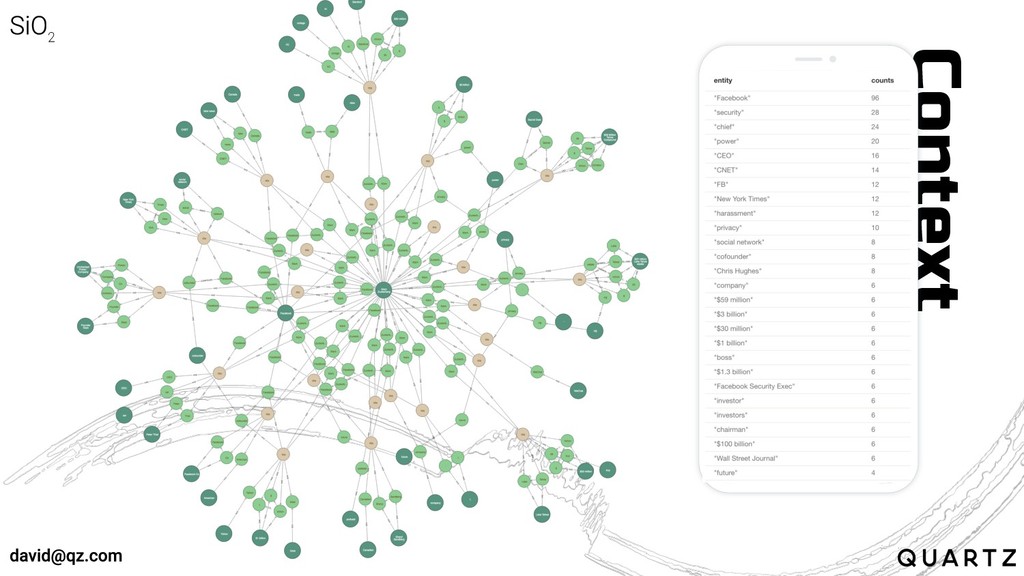
Entities are linguistic anchors, defined by context and around which
context can be inferred
Standard Entities PERSON FACILITY ORG PRODUCT GPE EVENT... Additional Entities
TECHNOLOGY PROCESS NATURE MEDIA CONSTRUCT
70K articles 1.4M blocks of text 85K labeled sentences
Entities
This spaCy model made rich analysis for any given text
easy to do on the fly
Stored analysis of a large corpus is a vital resource
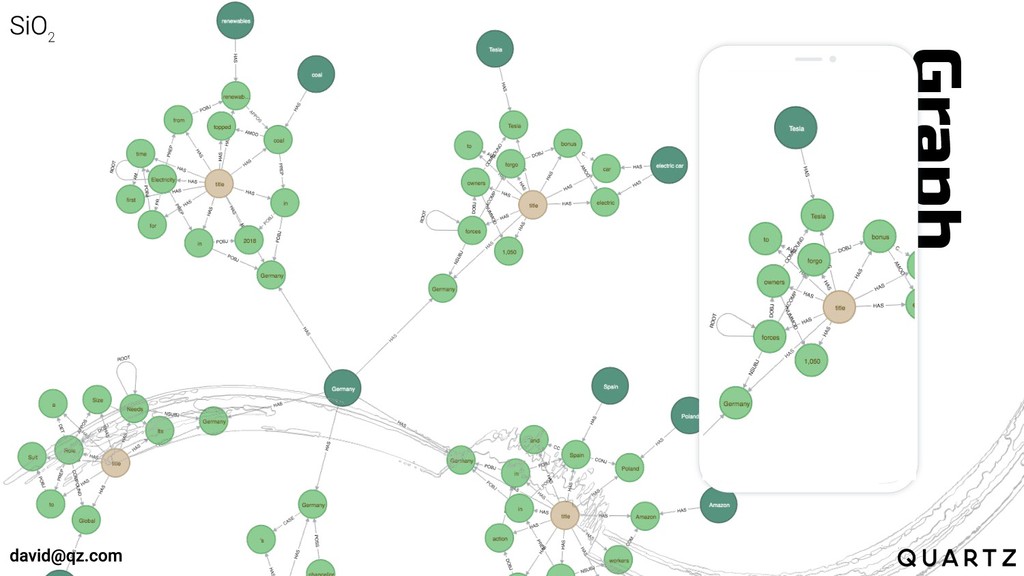
The language graph...
Graph
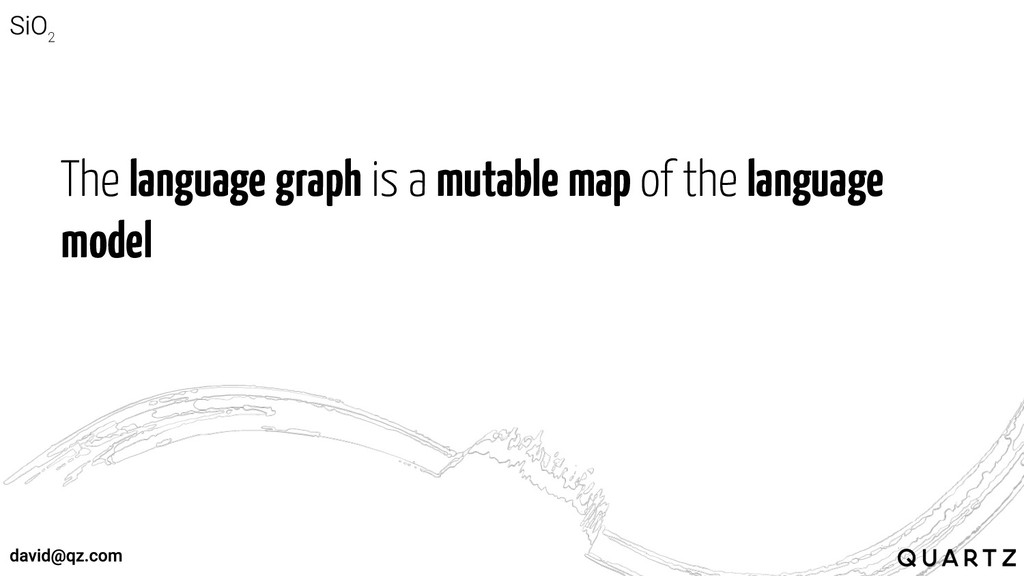
The language graph is a mutable map of the language
model
Any new content is analyzed and then mapped onto the
language graph
Changes made to the graph can then be incorporated into
the next model iteration
The language graph becomes a primary resource for extracting training
data
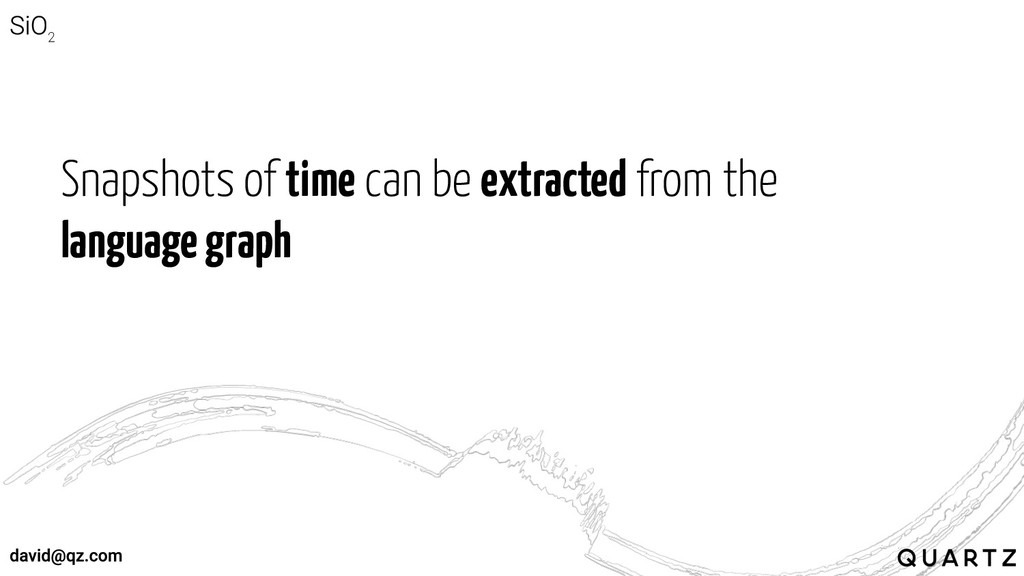
Snapshots of time can be extracted from the language graph
Context can be derived by looking at the relationships in
the language graph
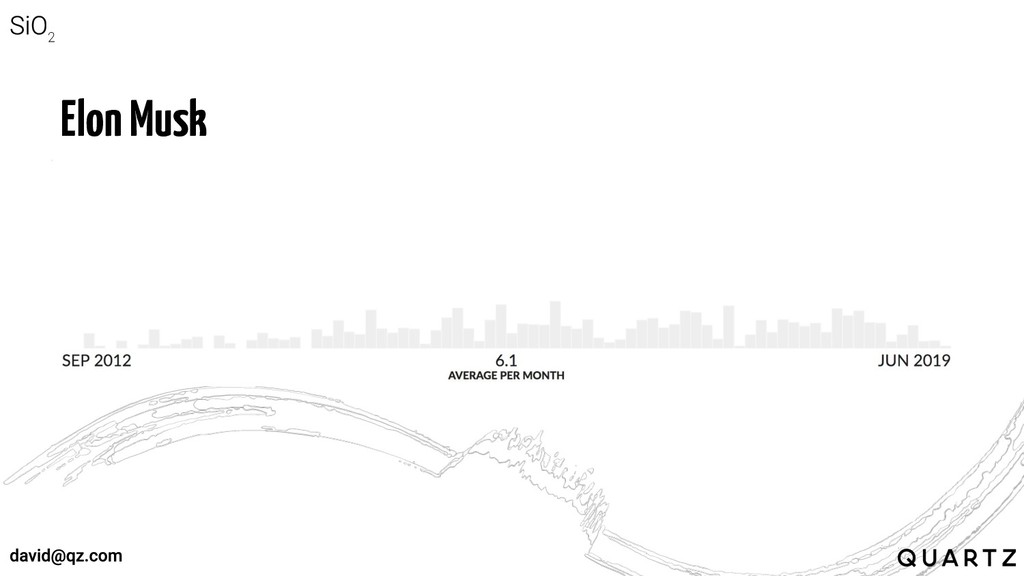
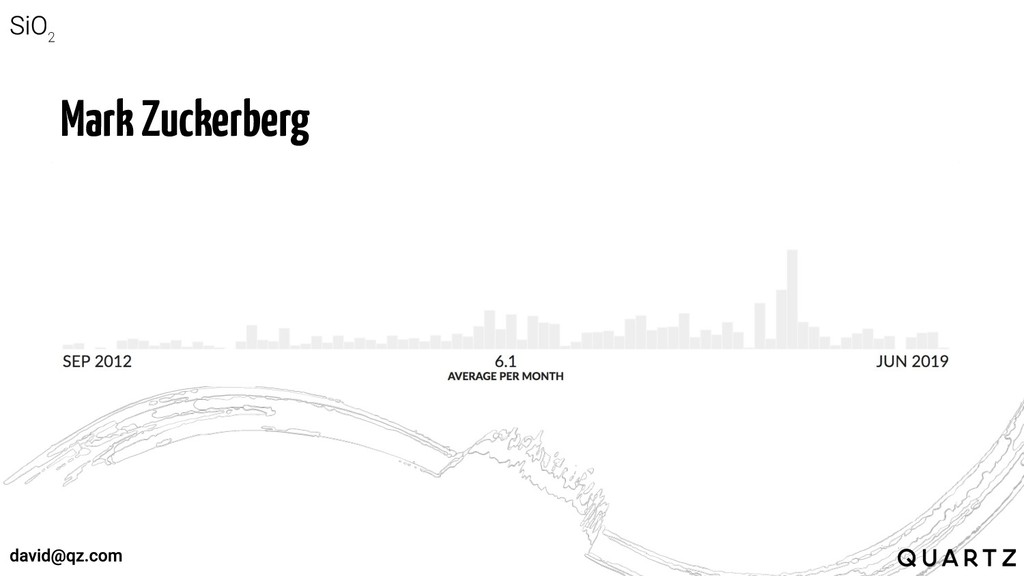
Elon Musk
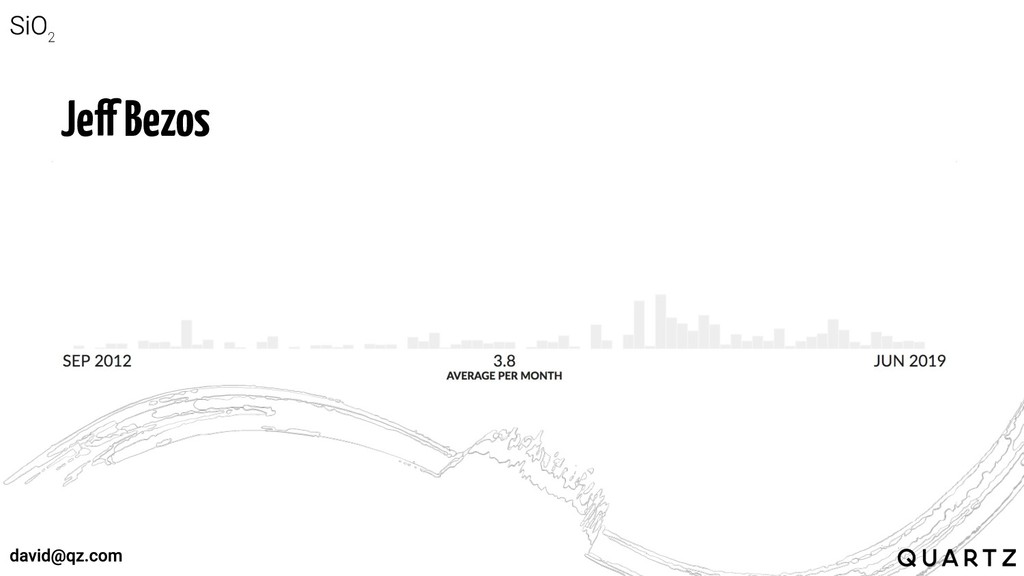
Jeff Bezos
Mark Zuckerberg
Context
SiO 2 is a living Natural Language Pipeline of networked
algorithms trained on the corpus of Quartz to understand the linguistic patterns of global business news
The Pipeline(s) Quartz Corpus -> Training Sentences -> spaCy Content
-> spaCy -> Language Graph Language Graph -> Training Data -> Statistical Models / Classifiers Language Graph -> Training Sentences -> spaCy Unseen Content -> spaCy -> Pre-Processed Text / Vectors -> Statistical Models / Classifiers
Thank you
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}