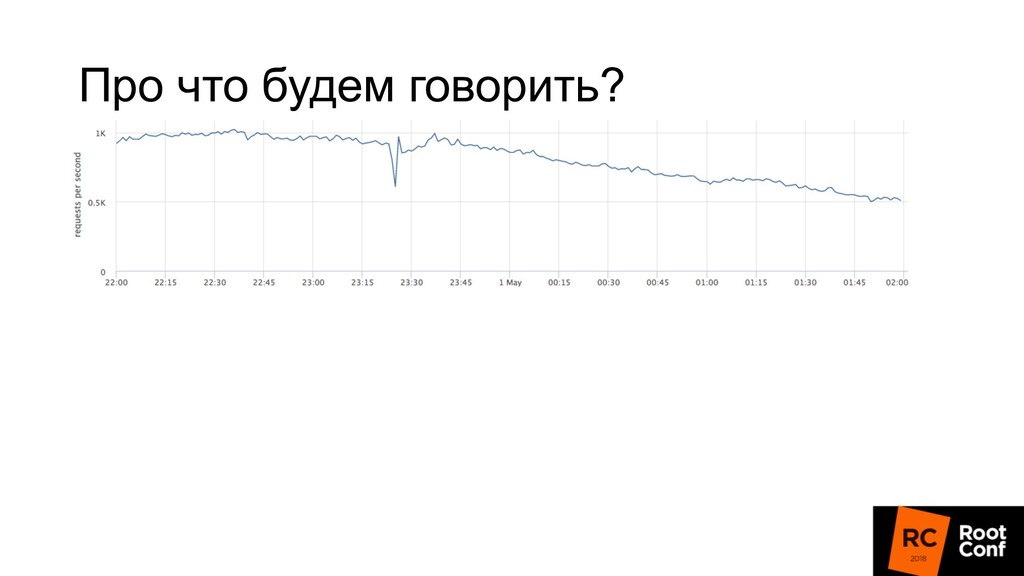
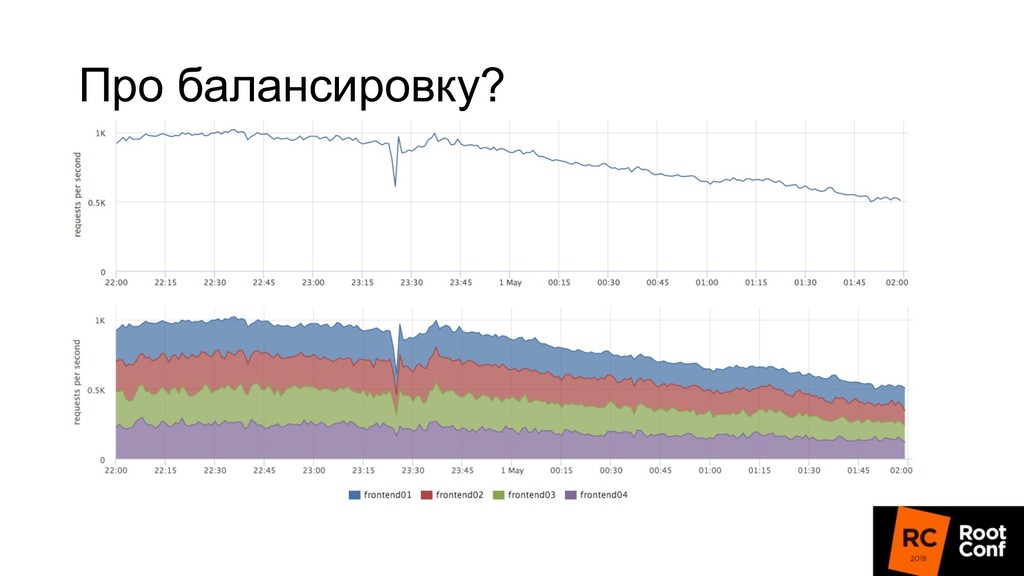
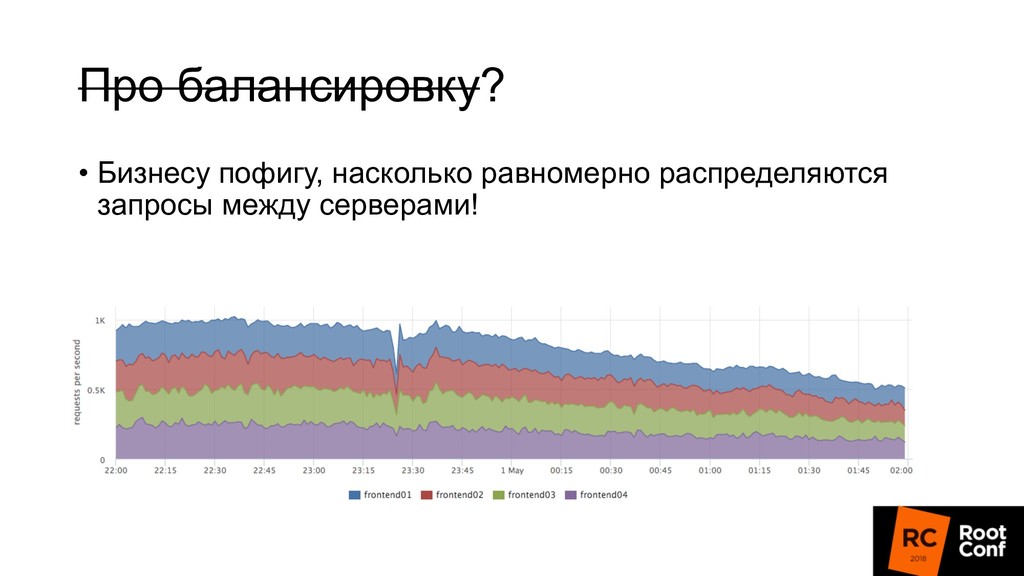
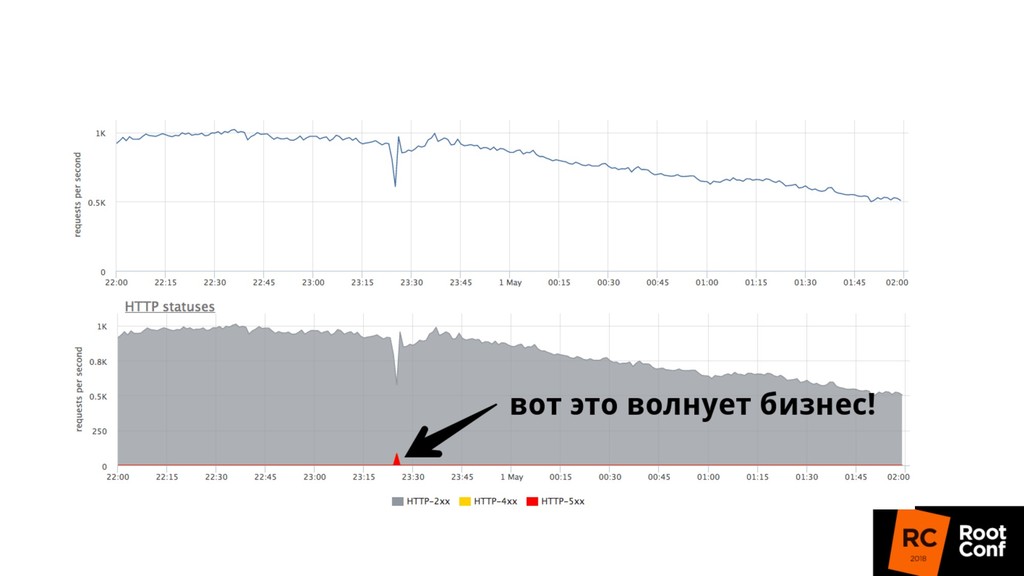
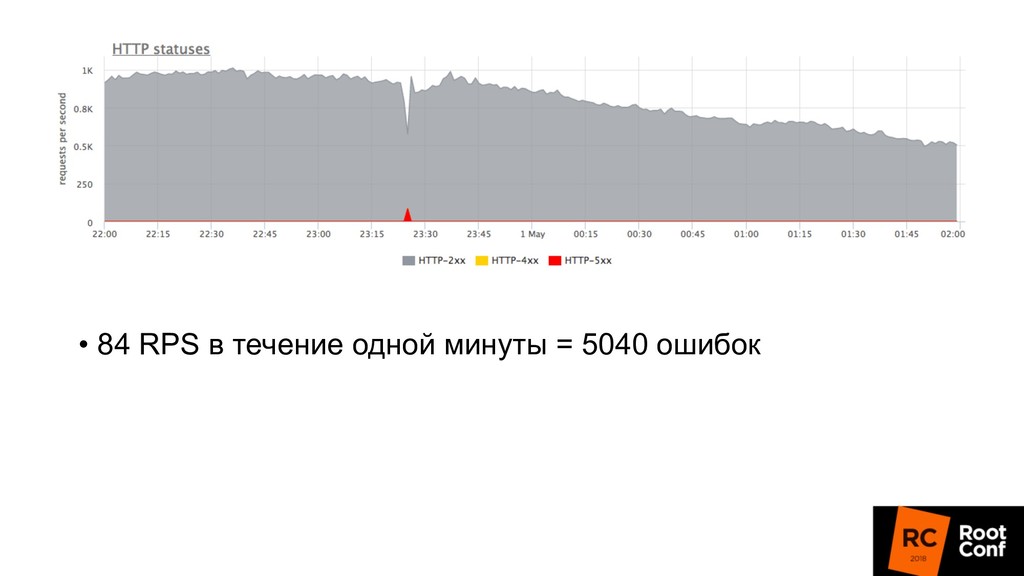
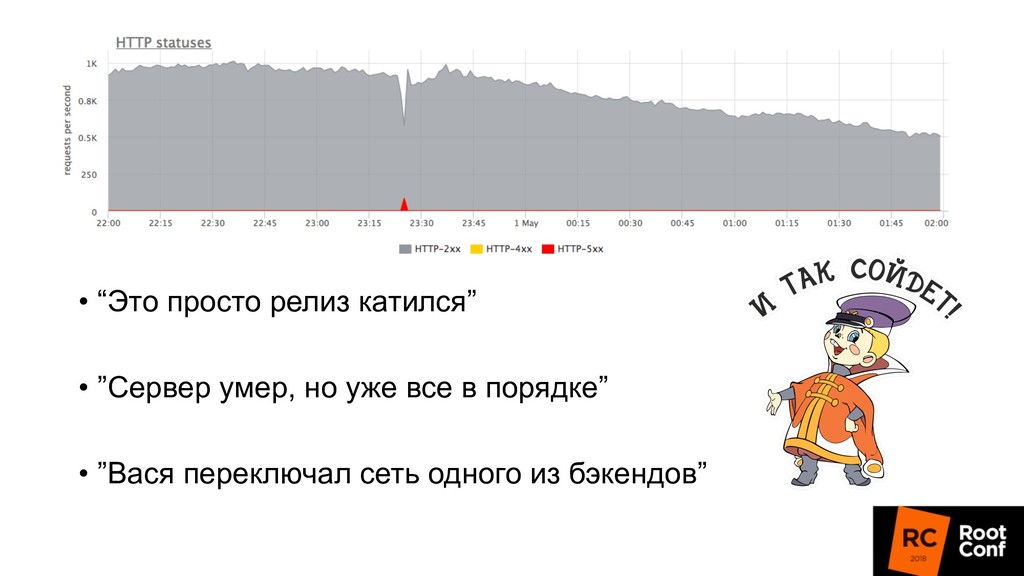
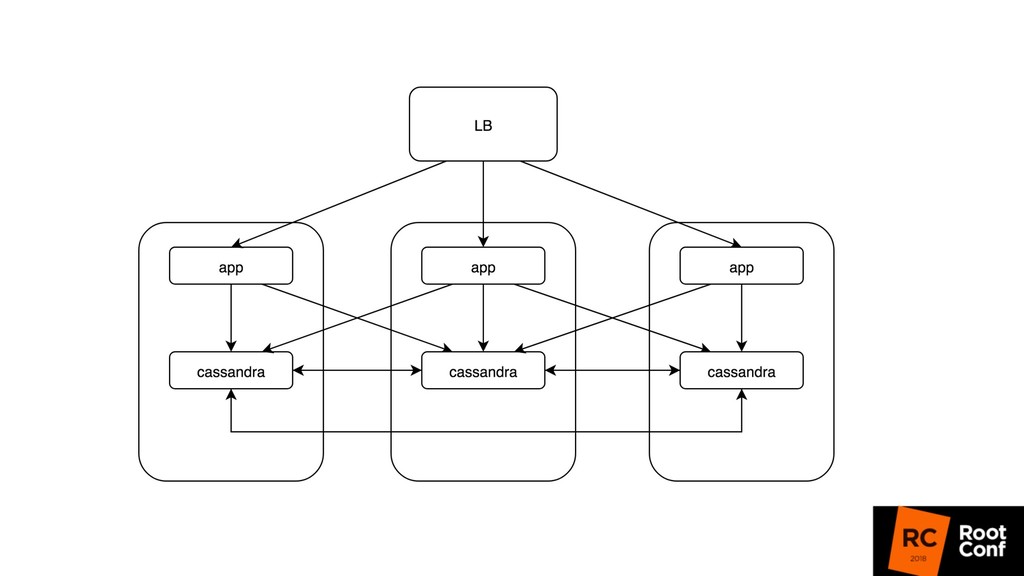
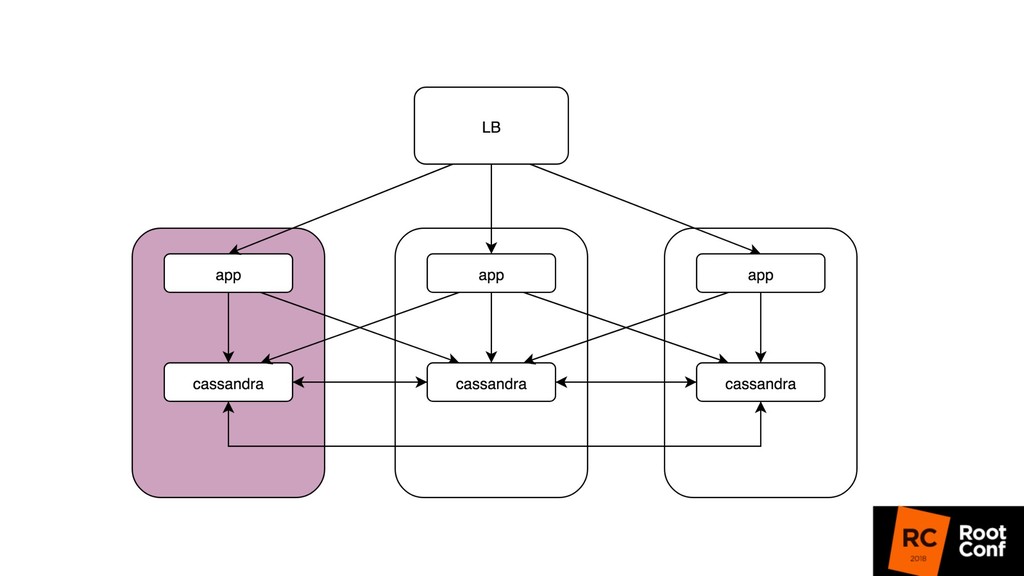
релизиться 100 раз в день • Kubernetes rollout с точки зрения балансировщика — это как в новую школу перевестись (все апстримы новые) • Микросервисы: теперь все общаются по сети, нужно делать это надежно
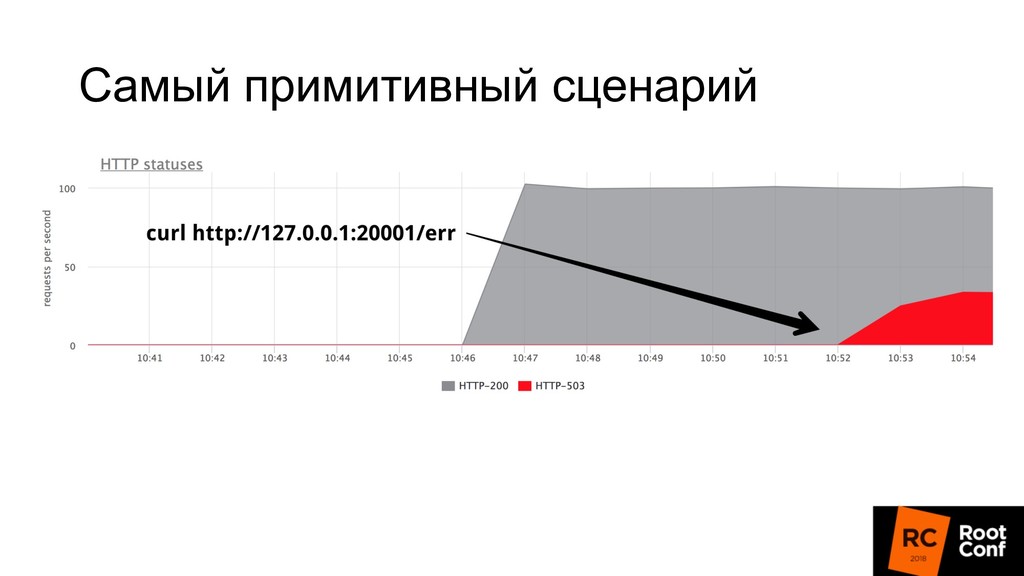
• GET /err – переключатель в режим http-503 • GET /ok – опять http-200 • Запускаем 3 инстанса: • 127.0.0.1:20001 • 127.0.0.1:20002 • 127.0.0.1:20003 • Подаем 100rps через yandex.tank через nginx
(handler) • Nginx: нет таймаута на весь запрос • proxy_send_timeout: время между 2 успешными вызовами write() • proxy_read_timeout: время между 2 успешными вызовами read() • c допущением, что в сети нет slow loris, proxy_read_timeout прокатит за request_timeout • Envoy: timeout || per_try_timeout
• чтобы обработать тупняк одного сервера: • request_timeout < max • гарантированные 2 попытки: per_try_timeout = 0.5 * max • оптимистичные 2 попытки: per_try_timeout = k * max (где k > 0.5)
известном мне прокси • Как сделано в cassandra (rapid read protection): • speculative_retry = N ms | Mth percentile • при достижении условия отправляем второй запрос • первый не прерываем • берем ответ того, кто быстрее ответил • Надежность VS лишние запросы
клиенту, никакие ошибки исправить уже нельзя • Уменьшаем вероятность: graceful shutdown при выкладке • Если у нас “умный клиент”: повторная попытка из клиента
а ответ уже начал отдаваться клиенту, ответ прерывался • Мы сделали патч, который уже в master и будет в 1.7 https://github.com/envoyproxy/envoy/pull/3221 by Pavel Trukhanov • Теперь, если ответ начали передавать, сработает только global timeout
укладывается в per_try_timeout + • Отсутствие request cancellation в 99.9% сервисов: • первая попытка начала грузить базу; балансер бросил запрос • вторая попытка начала грузить базу, которую грузит первая попытка, так как не умеет понимать, что ответ уже никому не нужен • …
и нижележащие подсистемы • Если балансер не особо интеллектуальный, можно понаписать разной логики: • последние N запросов закончились ошибкой, забаню сам себя на M секунд • Должен быть легким, так как дергаться будет часто
Request • Timeout • Interval + jitter • Healthy threshold • Unhealthy threshold • Check status + body • nginx: только в nginx+ ($) • envoy: есть panic mode, если > N% хостов unhealthy — игнорируем результаты health checks
nginx: • нет халявных health checks • до 1.11.5 не было халявного ограничения на количество соединений с бэкендом • Nginx балансит между несколькими haproxy: • Haproxу не делает retry после успешного соединения • Retry – запрос на другой haproxy • Можем попасть на тот же backend
service proxy, designed for cloud-native applications • Изначально разрабатывался в Lyft (С++) • Обычно service mesh = envoy + примочки (istio, contour, ambassador) • Из коробки умеет кучу плюшек по нашей сегодняшней теме
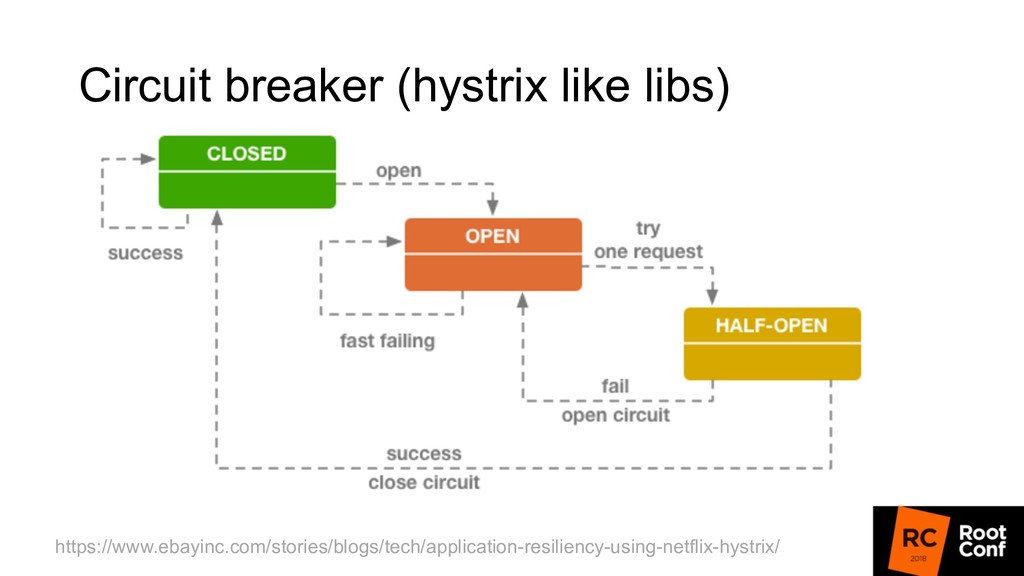
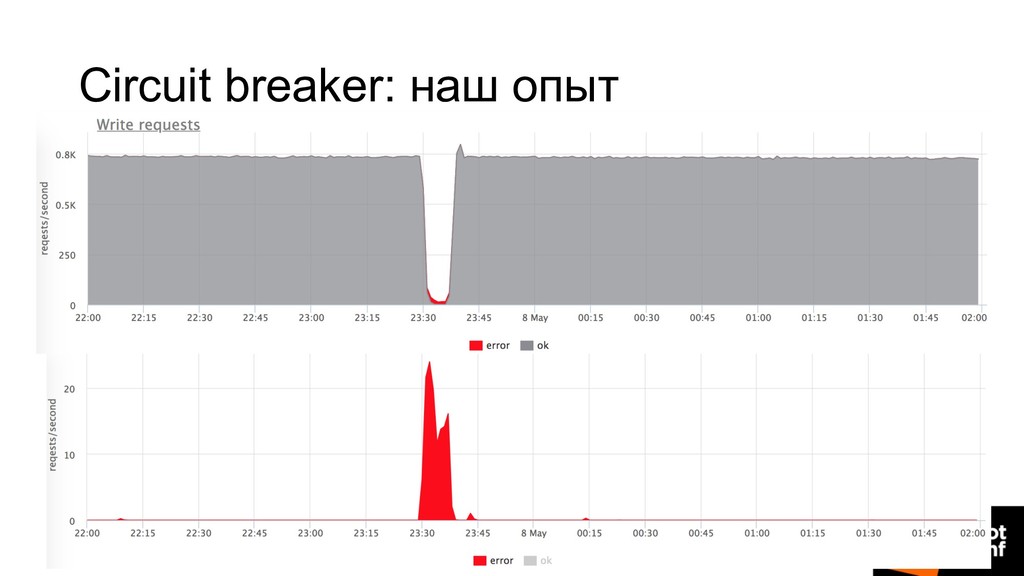
но при этом получает больше нагрузки: • F5/⌘-R от пользователей • Retries от балансировщика • Circuit breaker позволяет определить, что мы в таком состоянии, быстро отстрелить ошибку и дать бэкендам “отдышаться”
работал по http • В момент проблем агенты получали ошибки и делали повторные попытки (метрики уже были в spool на диске) • Агентов много, они не расстраиваются и не уходят:) • При проблемах мы зажимали входящий поток записи через nginx limit req
записывать гораздо больше, чем кризисный limit req • Из-за других причин мы перешли на свой протокол поверх TCP и потеряли возможность использовать nginx limit req • К тому же больше не хотелось менять limit req руками
времени ответа • Время ответа – взвешенное среднее (свежие замеры более значимые) • Периодически сбрасываем старые замеры https://github.com/bitly/go-hostpool
http-5xx • Consecutive gateway errors (502,503,504) • Success rate • Outlier баним на N ms • С ростом количества банов, N растет • max_ejection_percent
факт • Для 99% проблем хватает стандартных возможностей nginx/haproxy/envoy • Дело не в конкретном proxy (если это не haproxy:), а в том, как вы его настроили
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Retries: точка невозврата [envoy] • Если в envoy срабатывал per_try_timeout,](https://files.speakerdeck.com/presentations/3ec331cd421544e196cc3c4d38ff48ce/slide_27.jpg){kind=link}
{kind=link}
{kind=link}
![Retries: применяем [nginx] upstream backends { server 127.0.0.1:20001; server 127.0.0.1:20002;](https://files.speakerdeck.com/presentations/3ec331cd421544e196cc3c4d38ff48ce/slide_30.jpg){kind=link}
![Retries: применяем [nginx]](https://files.speakerdeck.com/presentations/3ec331cd421544e196cc3c4d38ff48ce/slide_31.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Backoff for retries [envoy] • Между попытками envoy делает паузы](https://files.speakerdeck.com/presentations/3ec331cd421544e196cc3c4d38ff48ce/slide_40.jpg){kind=link}
{kind=link}
{kind=link}
![Circuit breaking [envoy] • Cluster (upstream group) max connections •](https://files.speakerdeck.com/presentations/3ec331cd421544e196cc3c4d38ff48ce/slide_43.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Outlier detection [envoy] • Может найти outlier по: • Consecutive](https://files.speakerdeck.com/presentations/3ec331cd421544e196cc3c4d38ff48ce/slide_57.jpg){kind=link}
{kind=link}
{kind=link}
![Спасибо за внимание! Вопросы? Николай Сивко [email protected]](https://files.speakerdeck.com/presentations/3ec331cd421544e196cc3c4d38ff48ce/slide_60.jpg){kind=link}