каждом из них 20-50 контейнеров • Базы работают на отдельных железках и как правило общие • Resource-intensive сервисы на отдельных железках • Latency-sensitive сервисы на отдельных железках
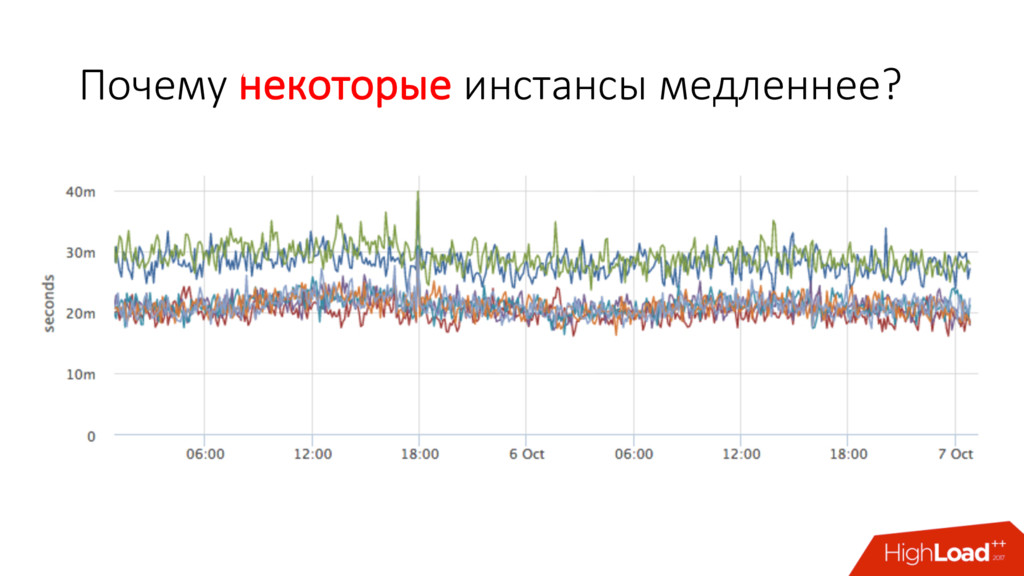
Может кто-то ресурсы съел? • Нужно найти, на каких серверах работают инстансы • dc1d9748-30b6-4acb-9a5f-d5054cfb29bd • 7a1c47cb-6388-4016-bef0-4876c240ccd6 и посмотреть там на соседние контейнеры и потребление ресурсов
Это всего лишь dedicated k8s поверх купленных вами VM • Никаких готовых рецептов они не предлагают Google App Engine: • Вы выбираете класс инстанса • Класс = CPU (Mhz) + Memory • Mhz = CPU Shares • Платим за instance/hour
• Первый merge в ядро 2.6.24 (2008) • Cобираем процессы в группу, на неё навешиваем ограничения ресурсов • Все потомки автоматически включаются в группу родителя • Запущенный docker* контейнер = всегда отдельная cgroup, даже если ресурсы не ограничивали
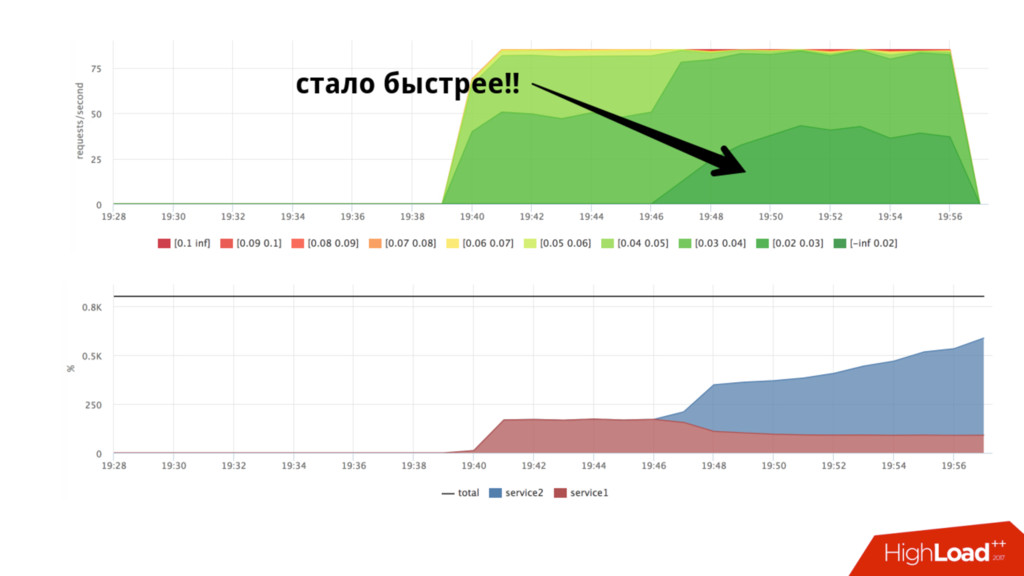
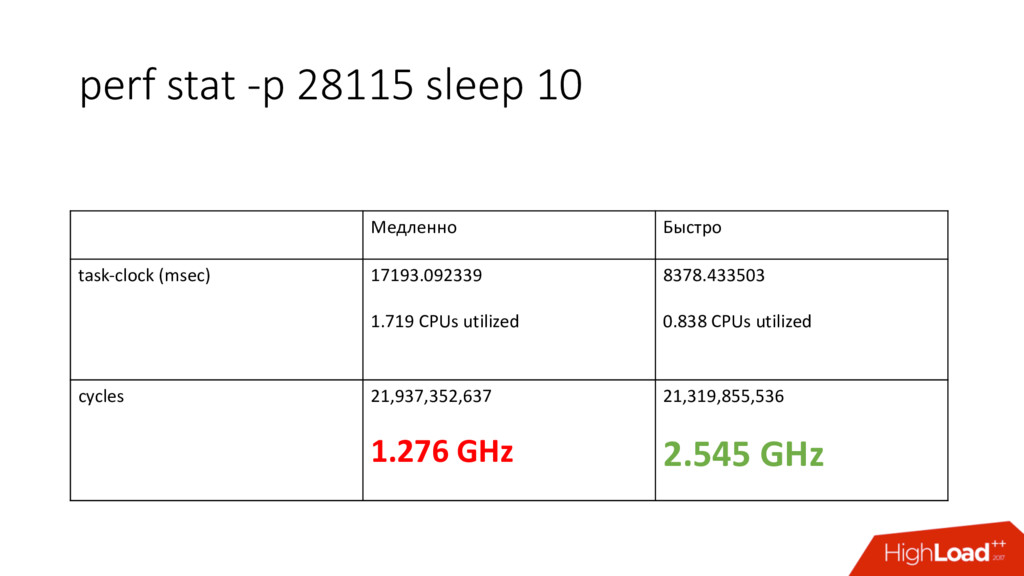
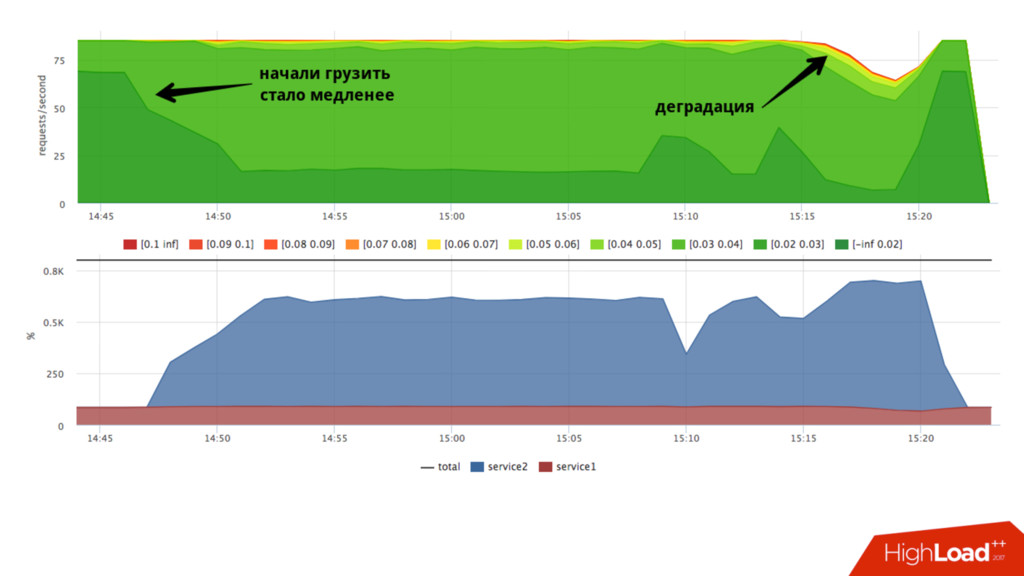
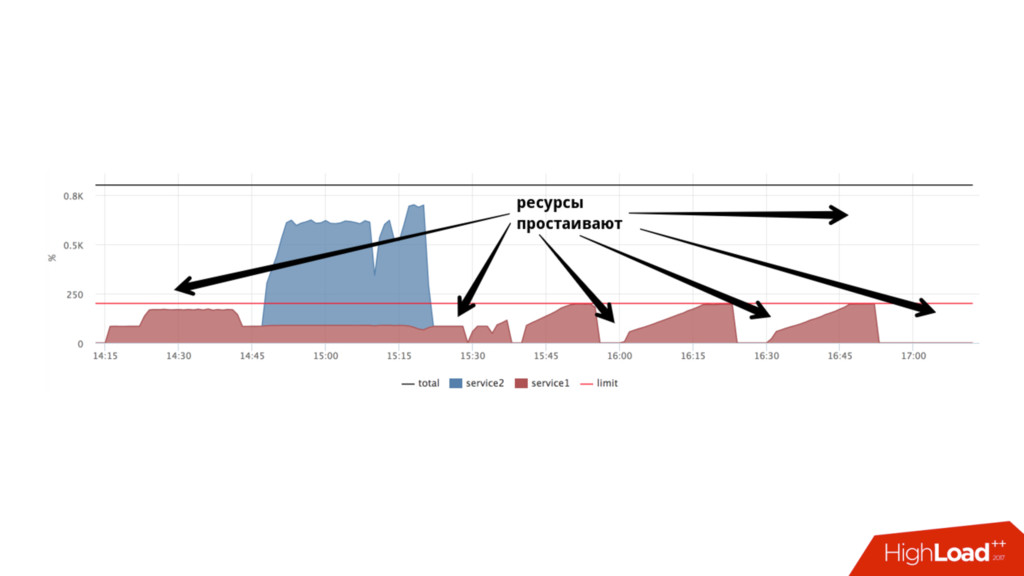
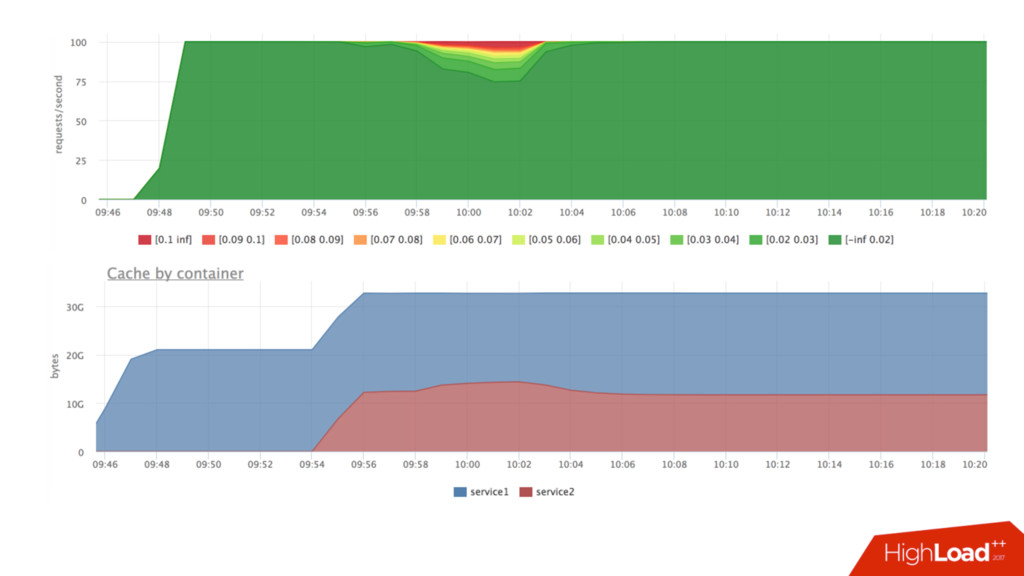
shares 1024:1024 • Процессы не ограничены в процессорном времени пока нет конкуренции • Пока на service2 не будет нагрузки, service1 сможет утилизировать больше ресурсов • Если мы хотим стабильности, нам нужен стабильный худший случай
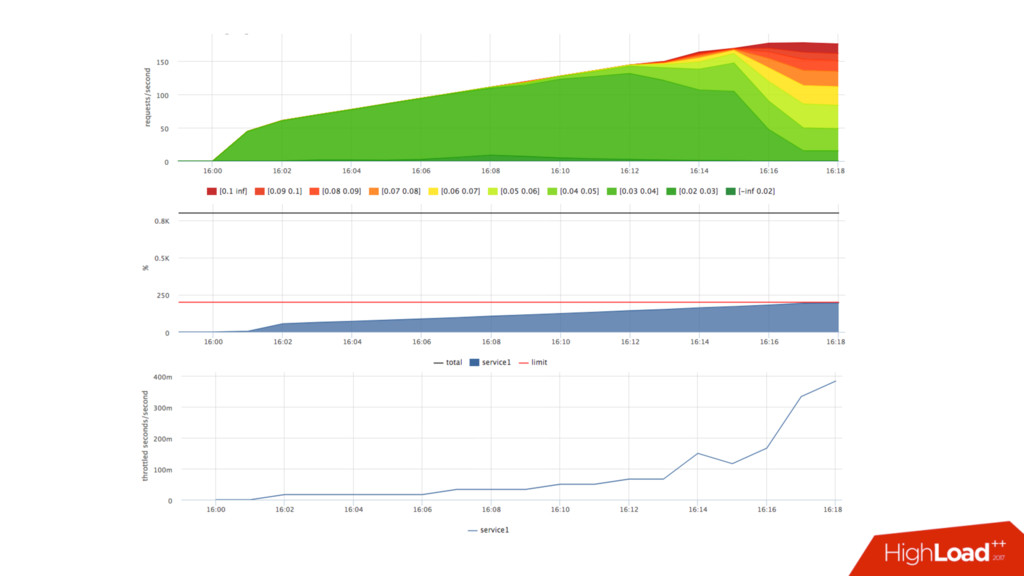
сколько процессорного времени можно потратить за period • Если хотим отрезать 2 ядра: quota = 2 * period • Если процесс потратил quota, процессорное время ему не выделяется (throttling), пока не кончится текущий period
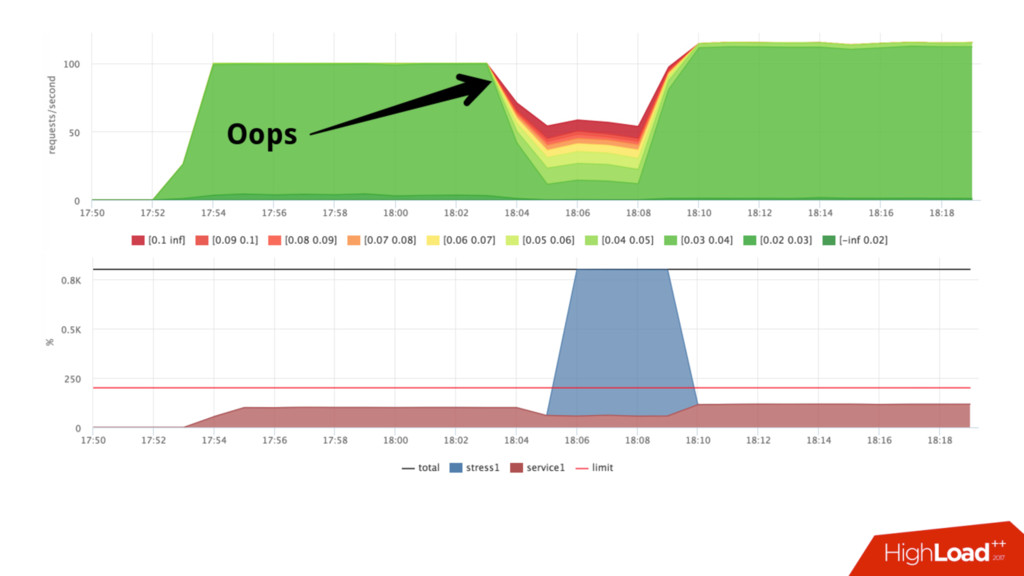
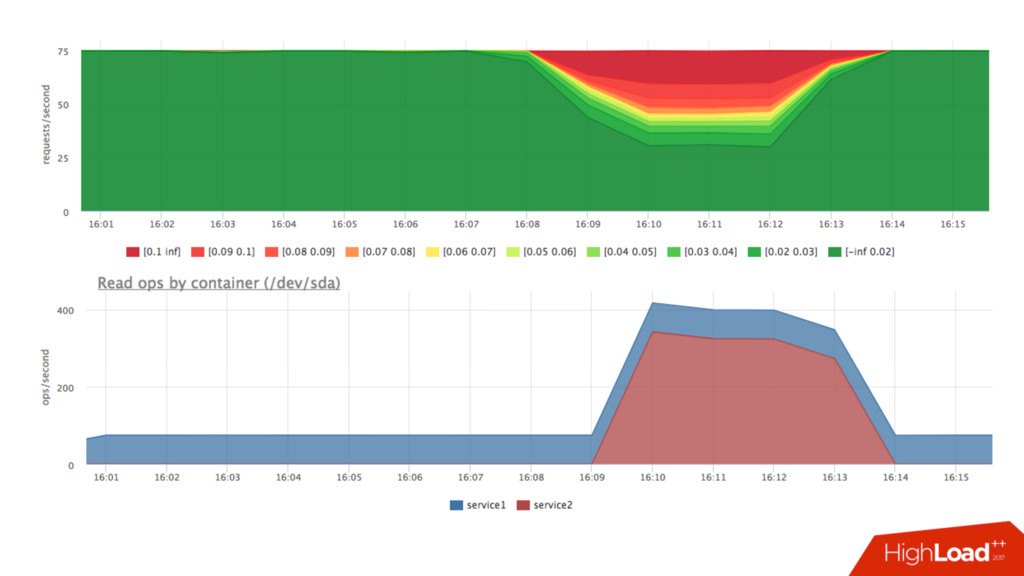
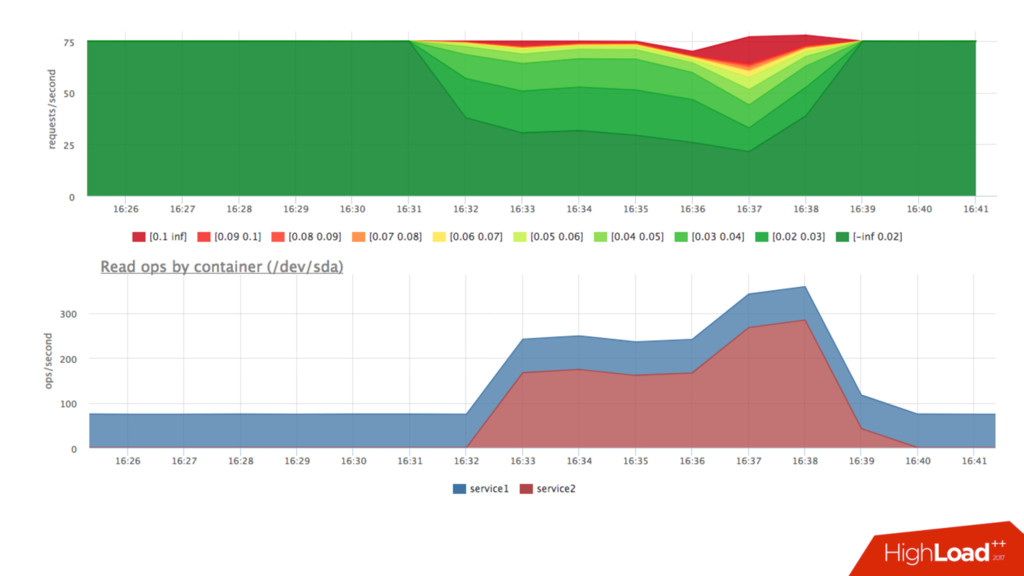
• Можем посчитать в % утилизацию cpu сервисом: • Факт: /sys/fs/cgroup/cpu/docker/<id>/cpuacct.usage • Лимит: period/quota • Триггер: [service1] cpu usage > 90% • Если уперлись в quota — растёт nr_throttled и throttled_time из • /sys/fs/cgroup/cpu/docker/<id>/cpu.stat
latency-sensitive сервисов (quota) • Если готовимся к повышению нагрузки – запускаем каждого сервиса столько, чтобы потребление было < N % • Если есть умный оркестратор и желание – делаем это динамически • Количество свободных слотов – наш запас, держим его на комфортном уровне
выделяется слотами (slices) • Можно крутить разные ручки: sysctl –a |grep kernel.sched_ • Я все тестировал на дефолтовых настройках и крутить не было желания
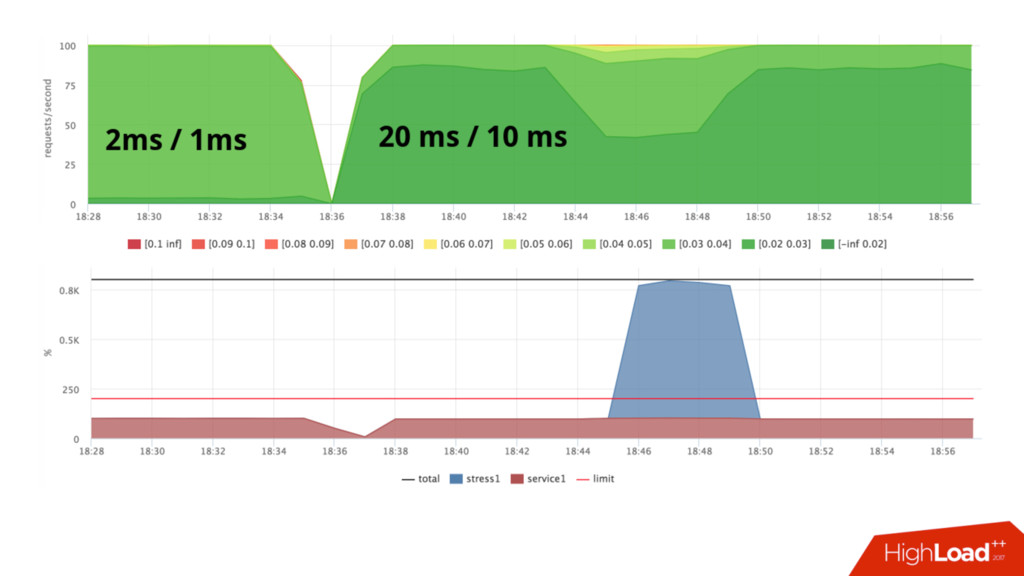
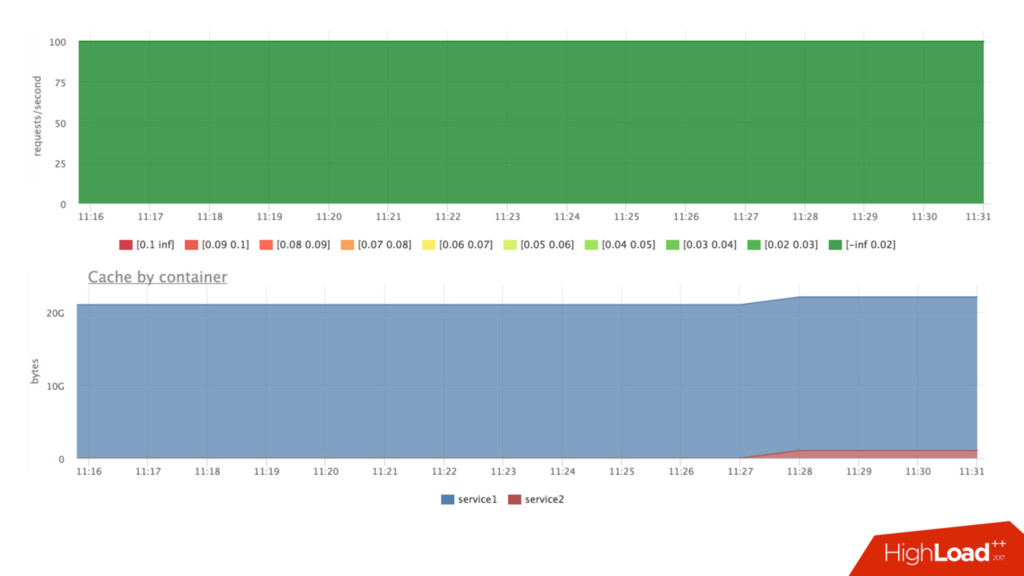
выделяется слотами (slices) • Можно крутить разные ручки: sysctl –a |grep kernel.sched_ • Я все тестировал на дефолтовых настройках и крутить не было желания • Мы поставили квоту 2ms/1ms, это уменьшило размер слота, который может потратить наш сервис
но время ответа сервиса осталось на приемлемом уровне • Нужно тестировать и подбирать параметры • “Слоты” + фоновая нагрузка – рабочая модель распределения ресурсов
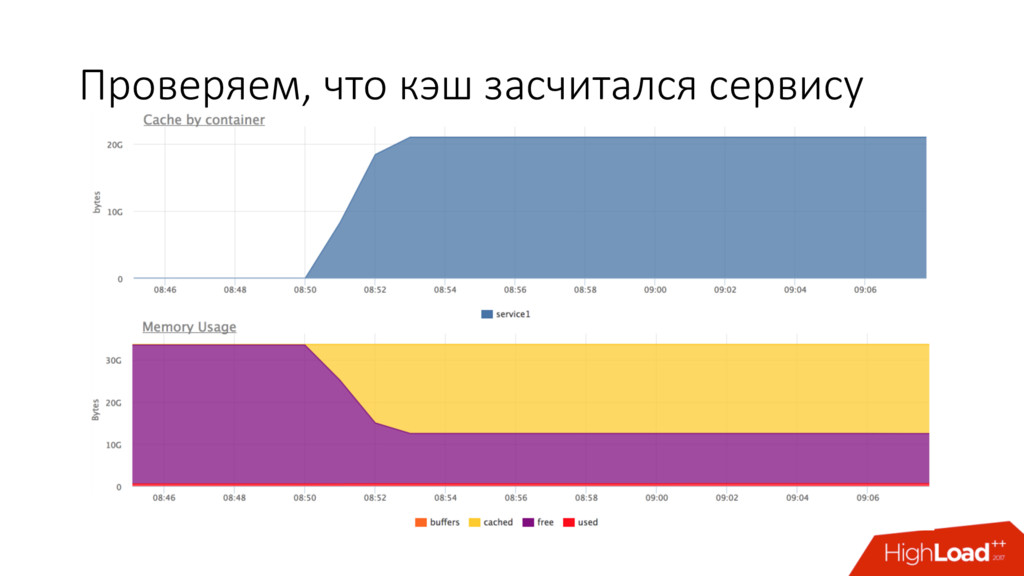
• Получаем статистику /sys/fs/cgroup/memory/<cgroup>/memory.stat • Самое крутое — можем узнать, кто сколько page cache съел (засчитывается той группе, которая первая использовала страницу)
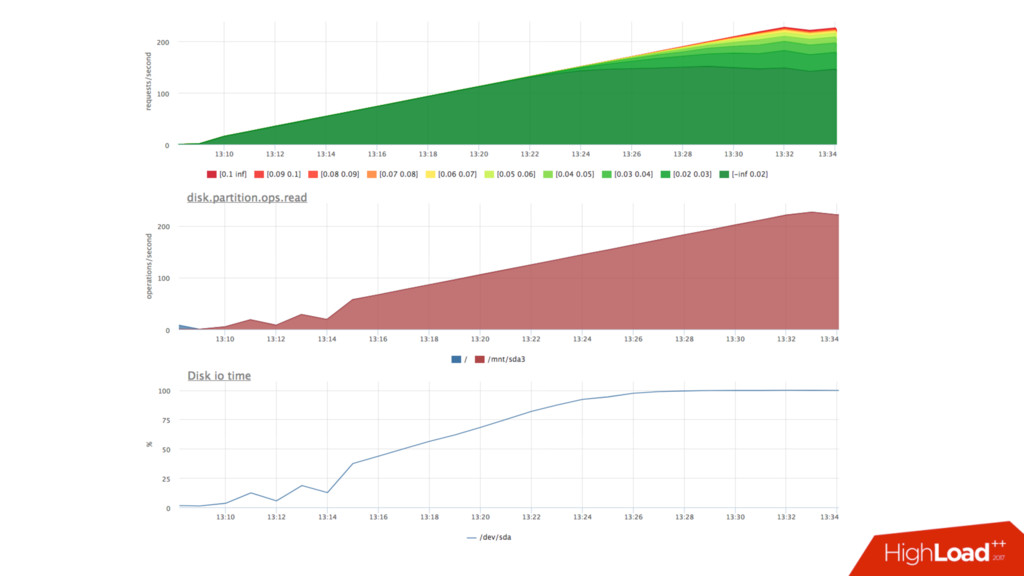
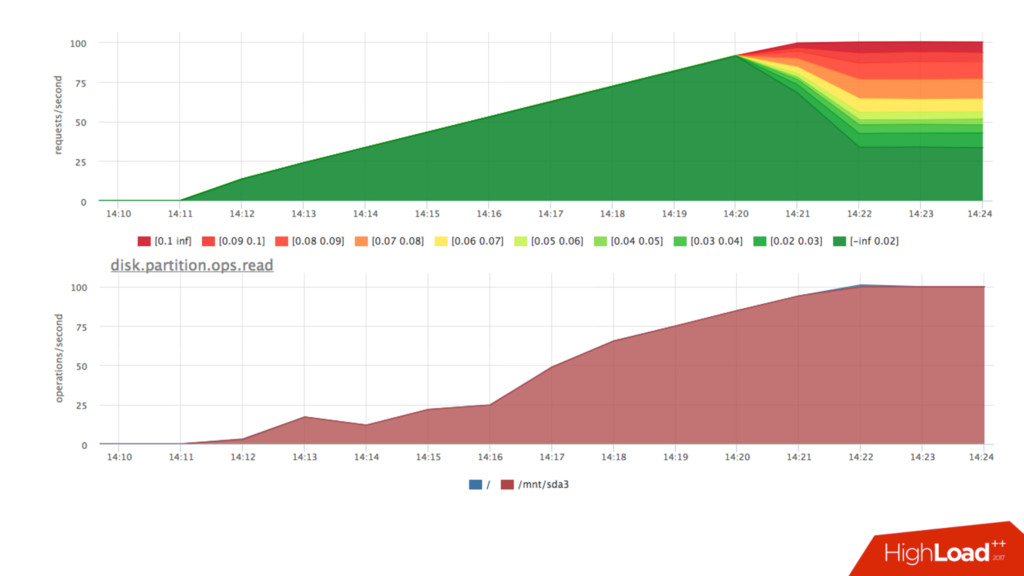
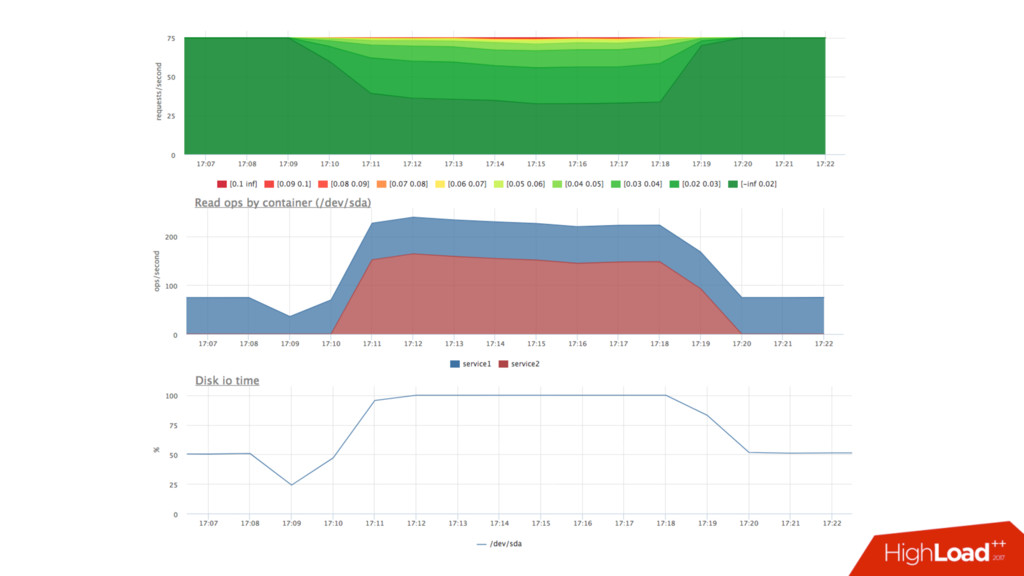
там есть, что покрутить • Говорят, что deadline лучше подходит, когда важно latency • echo deadline > /sys/block/sda/queue/scheduler • echo 1 > /sys/block/sda/queue/iosched/fifo_batch • echo 250 > /sys/block/sda/queue/iosched/read_expire
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Вопросы? Николай Сивко [email protected]](https://files.speakerdeck.com/presentations/1315691ccd694239bea8200e51c3168e/slide_81.jpg){kind=link}