PyData Berlin 2016 talk
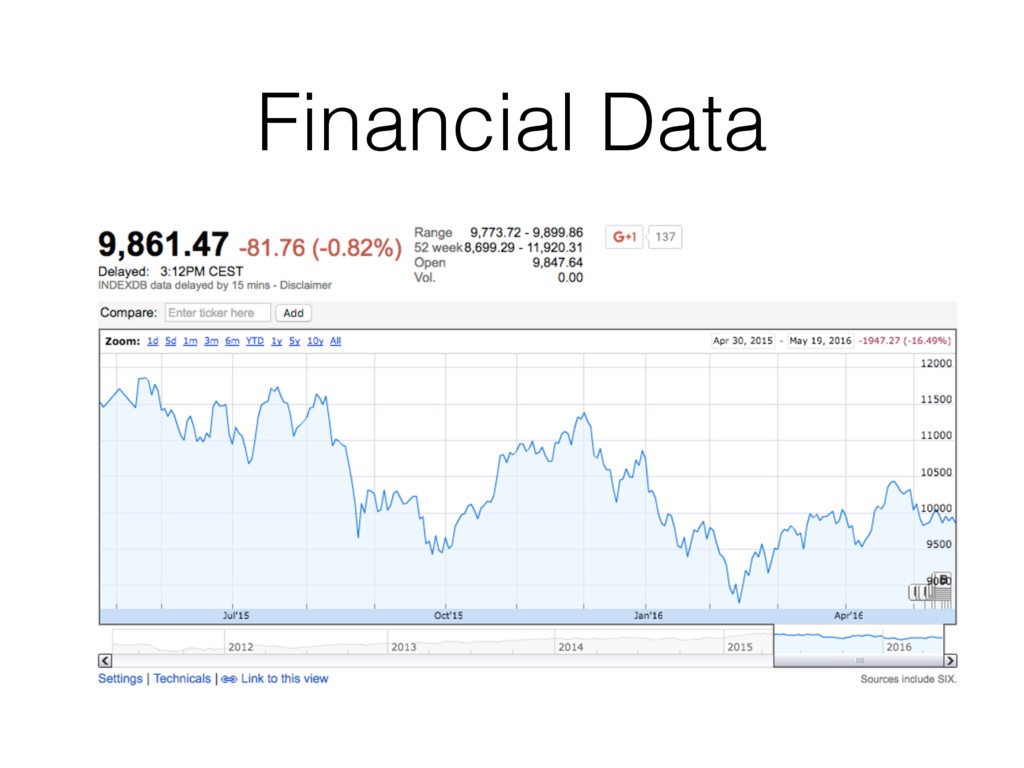
Description: Building an equities portfolio is a challenging task for a finance professional as it requires, among others, future correlations between stock prices. As this data is not always available, in this talk I look at an alternative to historical correlations as proxy for future correlations: using graph analysis techniques and text similarity measures based on Wikipedia data.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
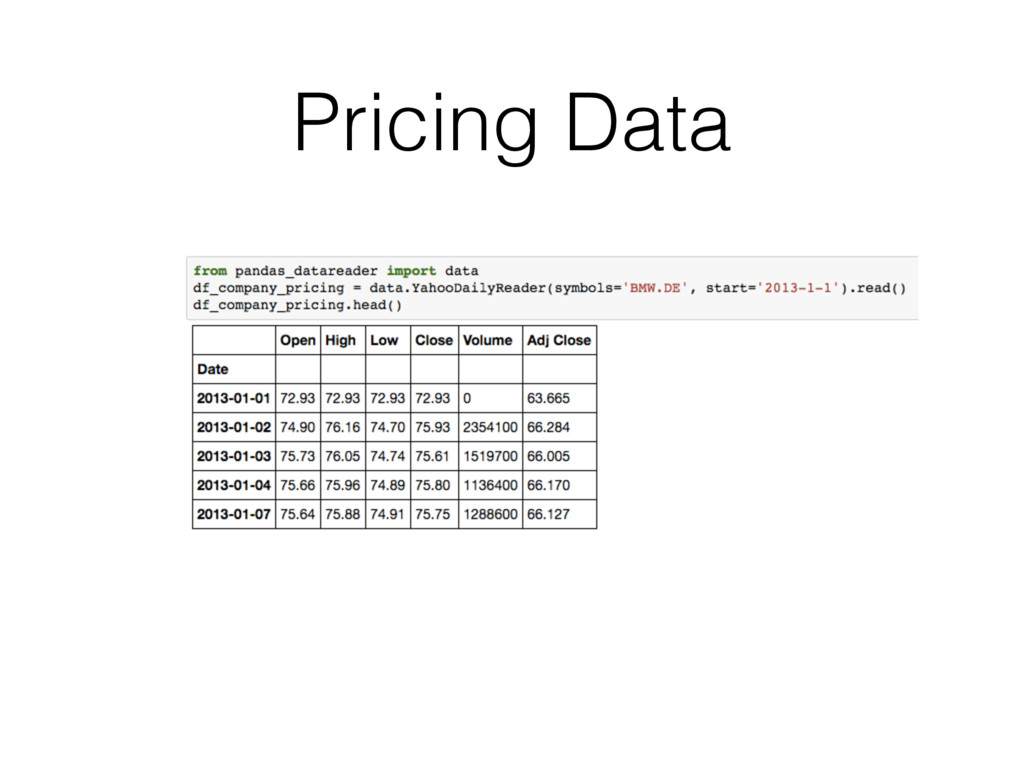{kind=link}
{kind=link}
{kind=link}
{kind=link}
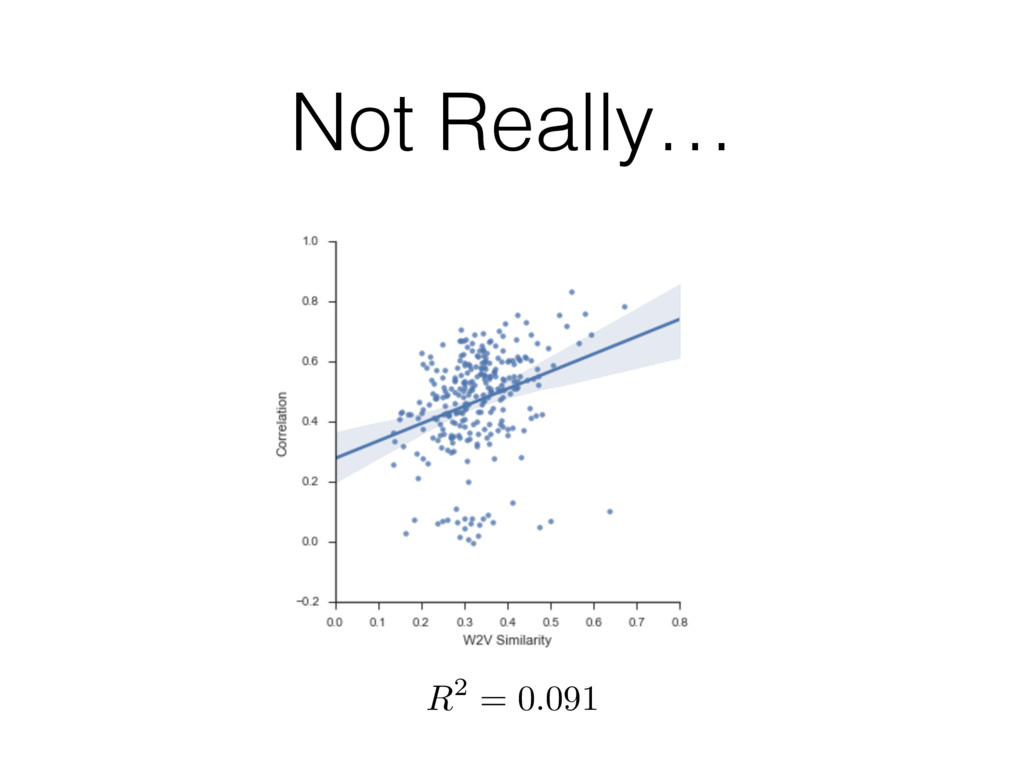{kind=link}
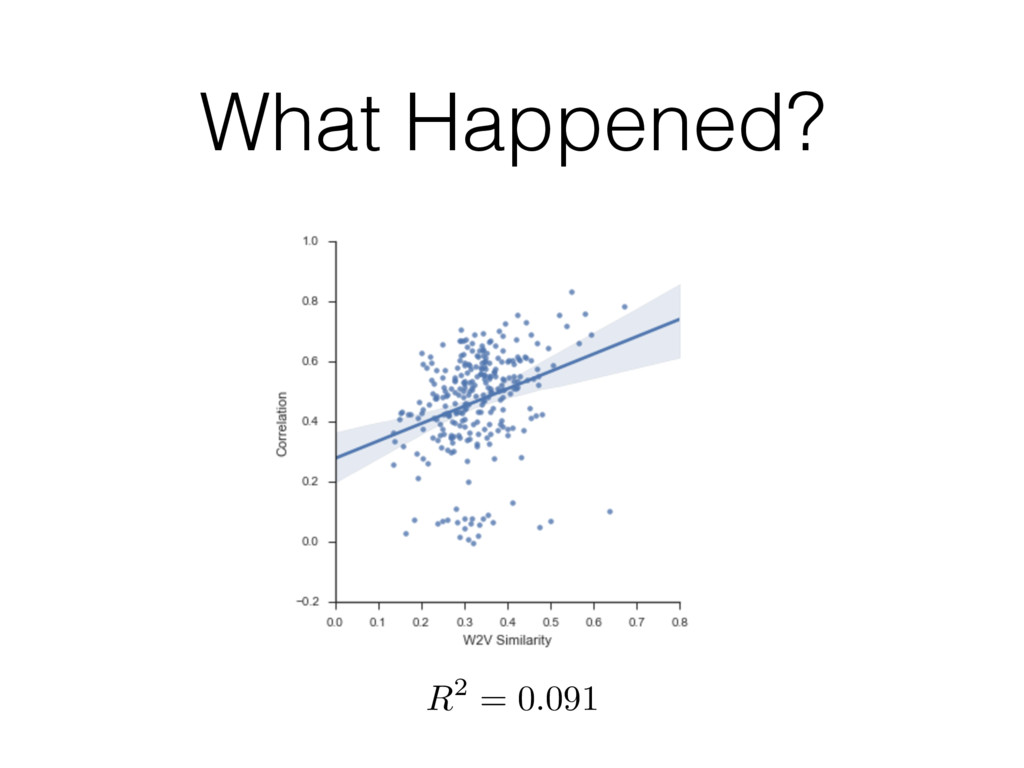{kind=link}
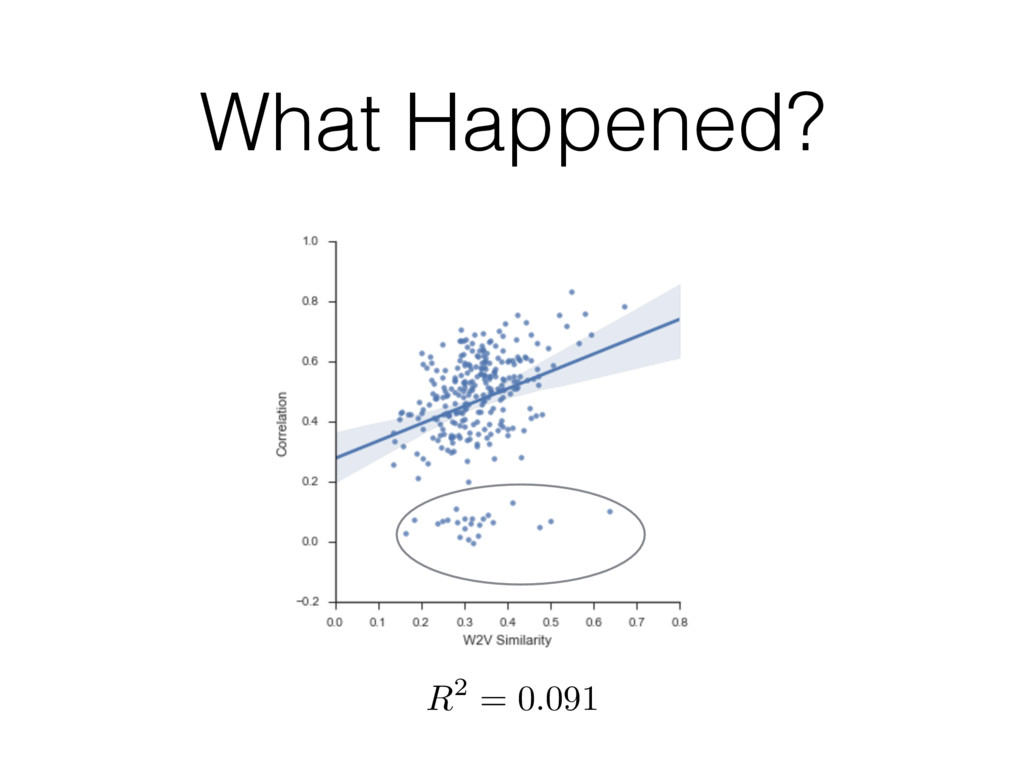{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}