The presentation from PiterPy Meetup #10 Hardcore about the data structures used in databases for storing and retrieving data.
Two approaches to data processing are considered: OLTP and OLAP.
SQL, NoSQL and New SQL databases are discussed.
The tradeoffs that the developers face when creating storage systems are shown.
Also the methods of data storage and interaction with the database provides CPython are considered.
The presentation and the list of references and books helps more easily navigate the data storage engines and understand which tool is better suited for a particular task.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Database indices - Hash indices [50] 19](https://files.speakerdeck.com/presentations/01ef6971fe4f4a9799f3ba06b71288b7/slide_18.jpg){kind=link}
![Database indices - Hash indices [50] - B-tree [50] 20](https://files.speakerdeck.com/presentations/01ef6971fe4f4a9799f3ba06b71288b7/slide_19.jpg){kind=link}
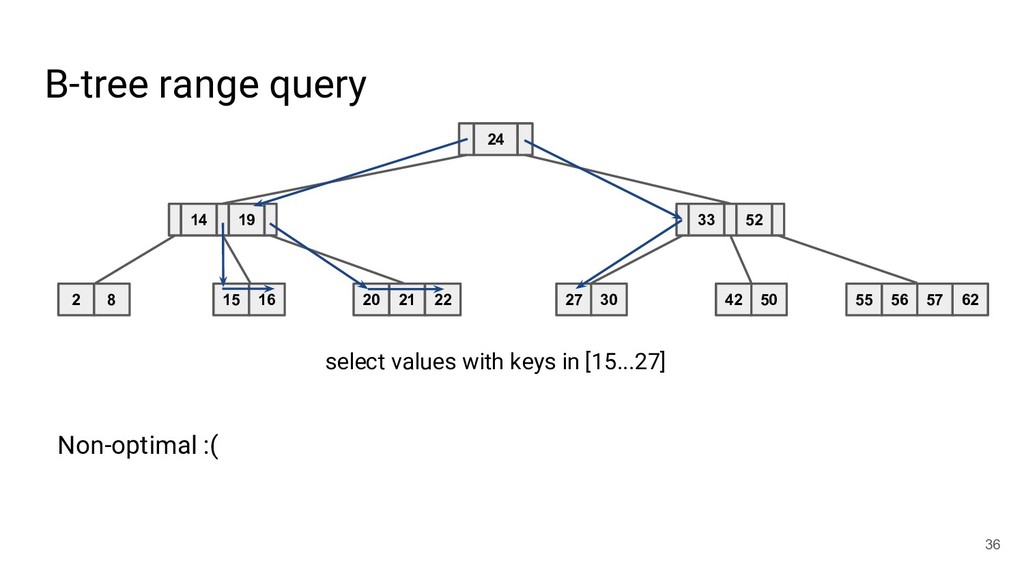
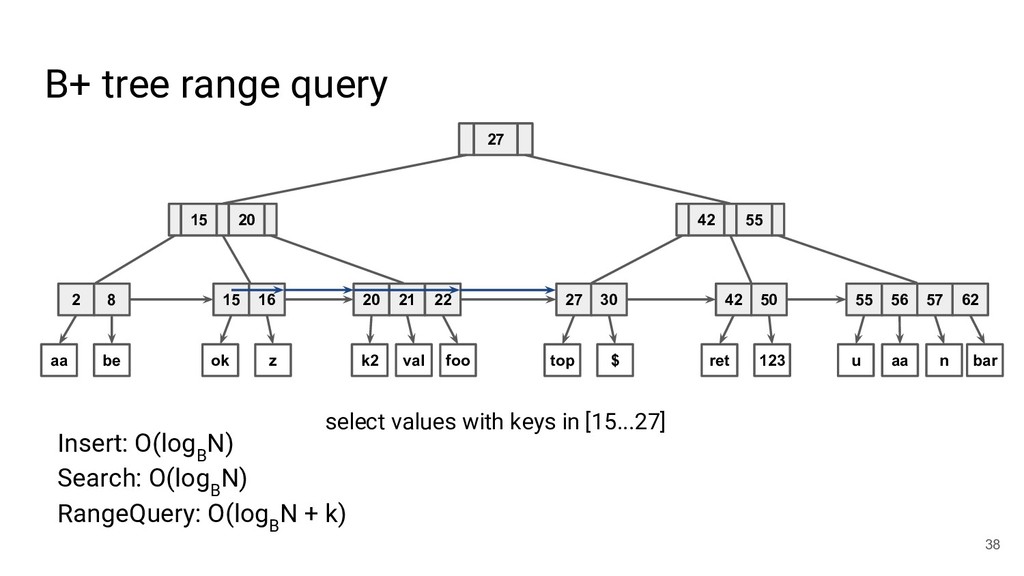
![Database indices - Hash indices [50] - B-tree [50] -](https://files.speakerdeck.com/presentations/01ef6971fe4f4a9799f3ba06b71288b7/slide_20.jpg){kind=link}
![Database indices - Hash indices [50] - B-tree [50] -](https://files.speakerdeck.com/presentations/01ef6971fe4f4a9799f3ba06b71288b7/slide_21.jpg){kind=link}
![Database indices - Hash indices [50] - B-tree [50] -](https://files.speakerdeck.com/presentations/01ef6971fe4f4a9799f3ba06b71288b7/slide_22.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![40 Memory Prices [34] Price per MB ($) Year](https://files.speakerdeck.com/presentations/01ef6971fe4f4a9799f3ba06b71288b7/slide_39.jpg){kind=link}
![41 Memory vs Disk [56, 57, 58, 59] Operation Time,](https://files.speakerdeck.com/presentations/01ef6971fe4f4a9799f3ba06b71288b7/slide_40.jpg){kind=link}
{kind=link}
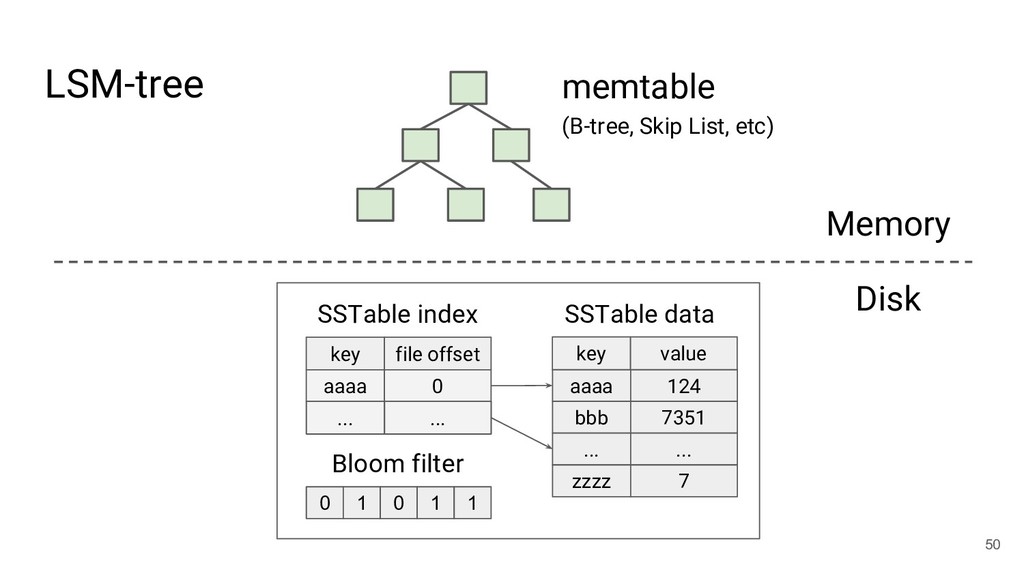
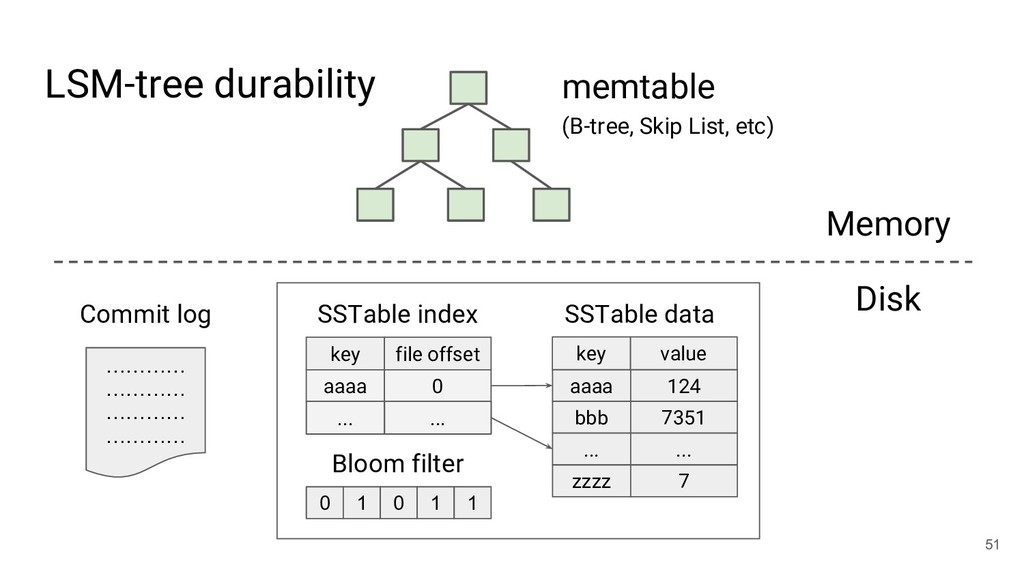
![Patrick O'Neil et al., introduced in 1996 [54] LSM-tree (Log-structured](https://files.speakerdeck.com/presentations/01ef6971fe4f4a9799f3ba06b71288b7/slide_42.jpg){kind=link}
![Patrick O'Neil et al., introduced in 1996 [54] Used in:](https://files.speakerdeck.com/presentations/01ef6971fe4f4a9799f3ba06b71288b7/slide_43.jpg){kind=link}
![Patrick O'Neil et al., introduced in 1996 [54] Used in:](https://files.speakerdeck.com/presentations/01ef6971fe4f4a9799f3ba06b71288b7/slide_44.jpg){kind=link}
![Patrick O'Neil et al., introduced in 1996 [54] Used in:](https://files.speakerdeck.com/presentations/01ef6971fe4f4a9799f3ba06b71288b7/slide_45.jpg){kind=link}
![Patrick O'Neil et al., introduced in 1996 [54] Used in:](https://files.speakerdeck.com/presentations/01ef6971fe4f4a9799f3ba06b71288b7/slide_46.jpg){kind=link}
![Patrick O'Neil et al., introduced in 1996 [54] Used in:](https://files.speakerdeck.com/presentations/01ef6971fe4f4a9799f3ba06b71288b7/slide_47.jpg){kind=link}
![Patrick O'Neil et al., introduced in 1996 [54] Used in:](https://files.speakerdeck.com/presentations/01ef6971fe4f4a9799f3ba06b71288b7/slide_48.jpg){kind=link}
{kind=link}
{kind=link}
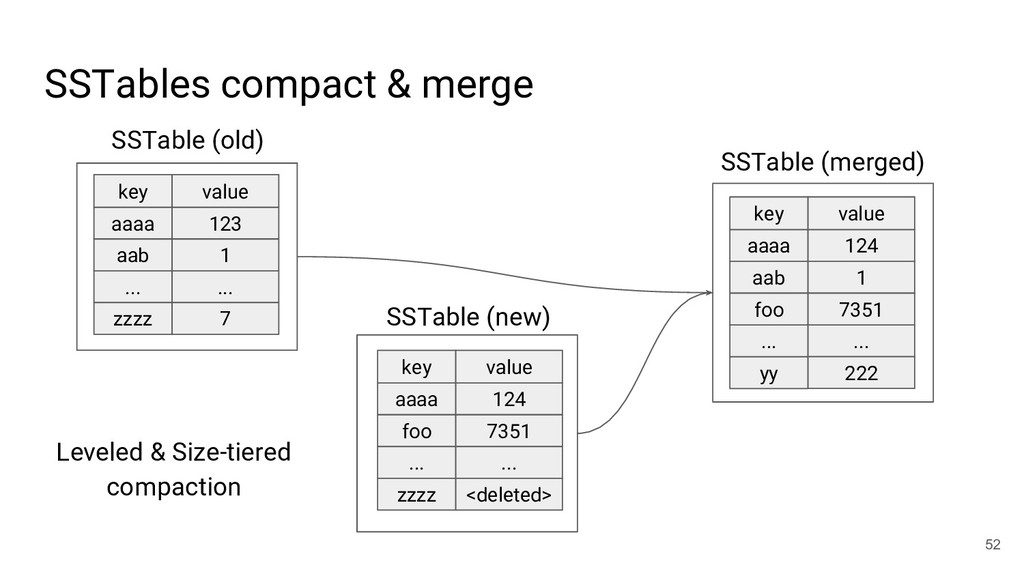{kind=link}
![Bloom filter [73] 53 Created by Burton Howard Bloom in](https://files.speakerdeck.com/presentations/01ef6971fe4f4a9799f3ba06b71288b7/slide_52.jpg){kind=link}
![Bloom filter [73] 54 Created by Burton Howard Bloom in](https://files.speakerdeck.com/presentations/01ef6971fe4f4a9799f3ba06b71288b7/slide_53.jpg){kind=link}
![Bloom filter [73] 55 Created by Burton Howard Bloom in](https://files.speakerdeck.com/presentations/01ef6971fe4f4a9799f3ba06b71288b7/slide_54.jpg){kind=link}
![Bloom filter [73] 56 Created by Burton Howard Bloom in](https://files.speakerdeck.com/presentations/01ef6971fe4f4a9799f3ba06b71288b7/slide_55.jpg){kind=link}
![Bloom filter [73] 57 Created by Burton Howard Bloom in](https://files.speakerdeck.com/presentations/01ef6971fe4f4a9799f3ba06b71288b7/slide_56.jpg){kind=link}
![Bloom filter [73] 58 Created by Burton Howard Bloom in](https://files.speakerdeck.com/presentations/01ef6971fe4f4a9799f3ba06b71288b7/slide_57.jpg){kind=link}
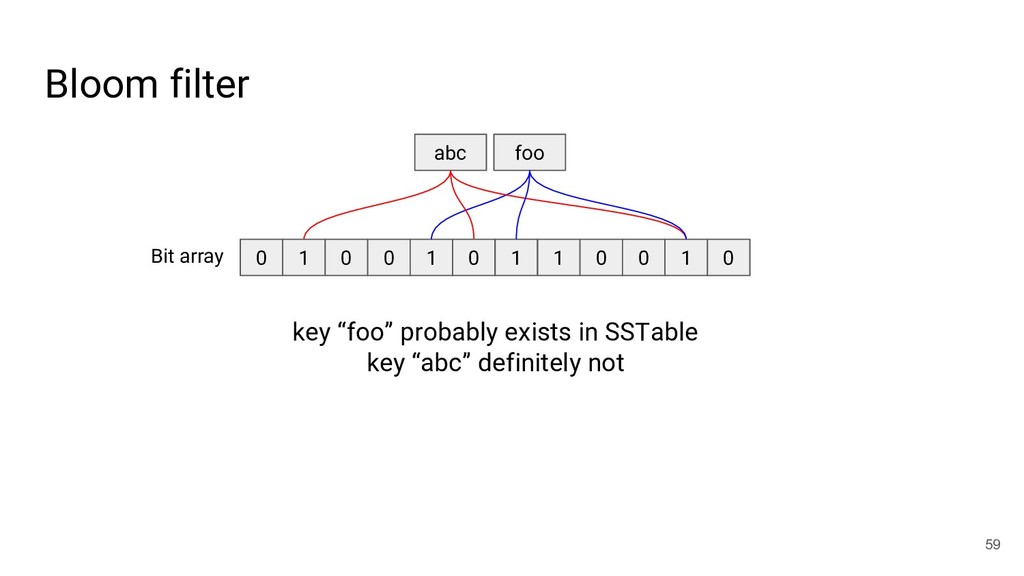{kind=link}
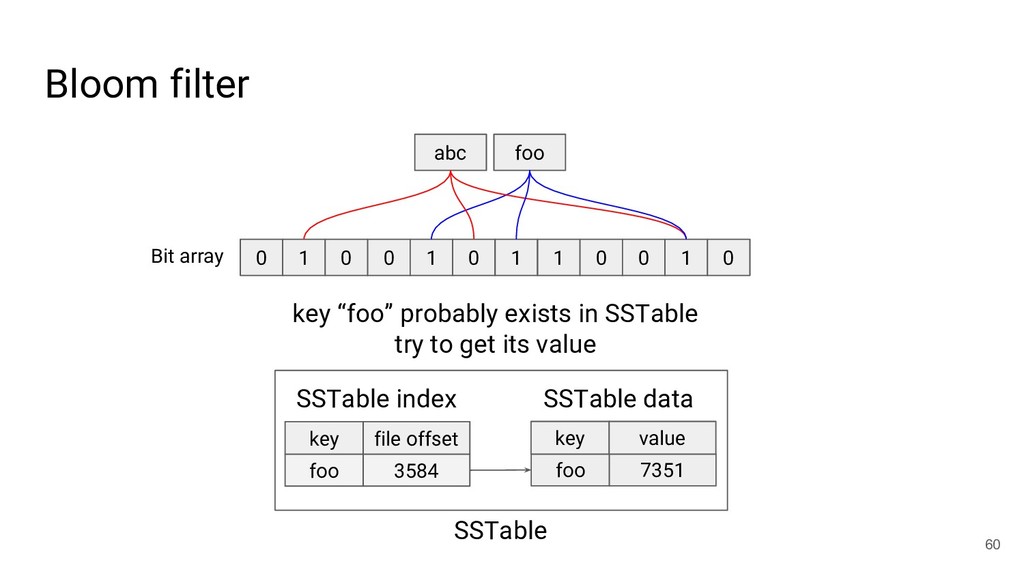{kind=link}
{kind=link}
![R-tree 62 Proposed by Antonin Guttman in 1984 [82]](https://files.speakerdeck.com/presentations/01ef6971fe4f4a9799f3ba06b71288b7/slide_61.jpg){kind=link}
![R-tree 63 Proposed by Antonin Guttman in 1984 [82] Tree](https://files.speakerdeck.com/presentations/01ef6971fe4f4a9799f3ba06b71288b7/slide_62.jpg){kind=link}
![R-tree 64 Proposed by Antonin Guttman in 1984 [82] Tree](https://files.speakerdeck.com/presentations/01ef6971fe4f4a9799f3ba06b71288b7/slide_63.jpg){kind=link}
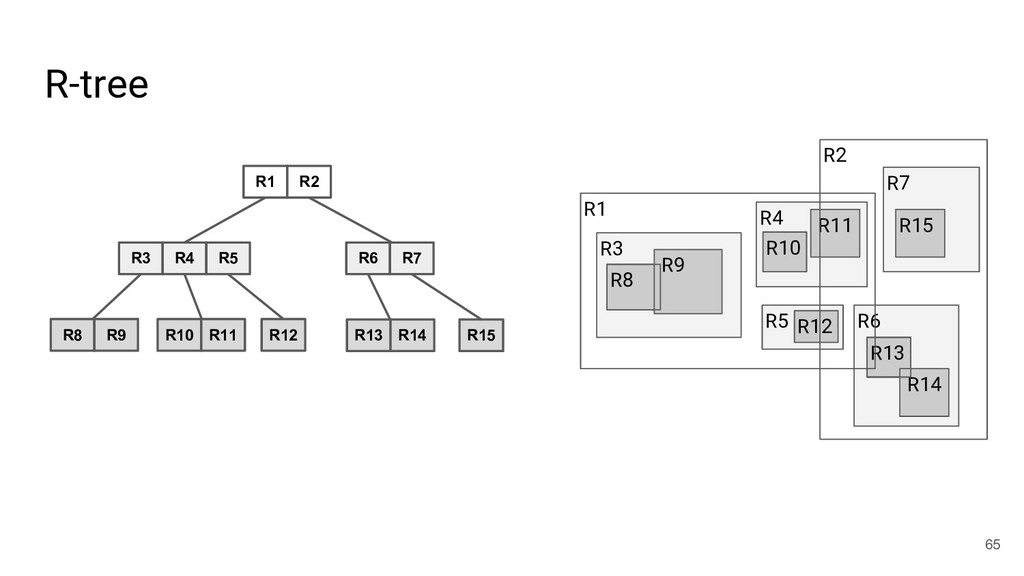{kind=link}
{kind=link}
![Block Range Index (BRIN) [80] 67 Proposed by Alvaro Herrera](https://files.speakerdeck.com/presentations/01ef6971fe4f4a9799f3ba06b71288b7/slide_66.jpg){kind=link}
![Block Range Index (BRIN) [80] 68 Proposed by Alvaro Herrera](https://files.speakerdeck.com/presentations/01ef6971fe4f4a9799f3ba06b71288b7/slide_67.jpg){kind=link}
![Block Range Index (BRIN) [80] 69 Proposed by Alvaro Herrera](https://files.speakerdeck.com/presentations/01ef6971fe4f4a9799f3ba06b71288b7/slide_68.jpg){kind=link}
![Block Range Index (BRIN) [80] 70 Proposed by Alvaro Herrera](https://files.speakerdeck.com/presentations/01ef6971fe4f4a9799f3ba06b71288b7/slide_69.jpg){kind=link}
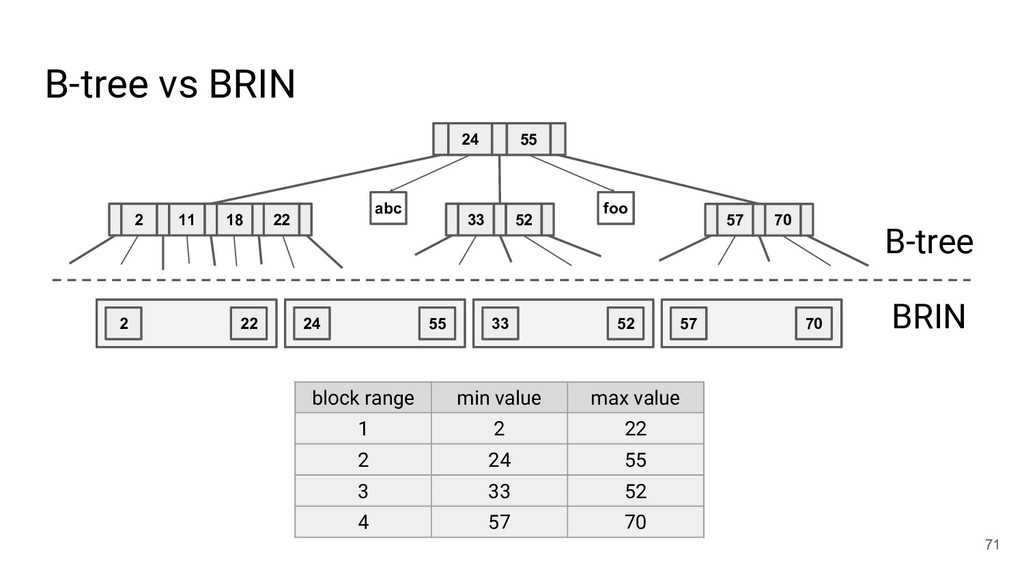{kind=link}
{kind=link}
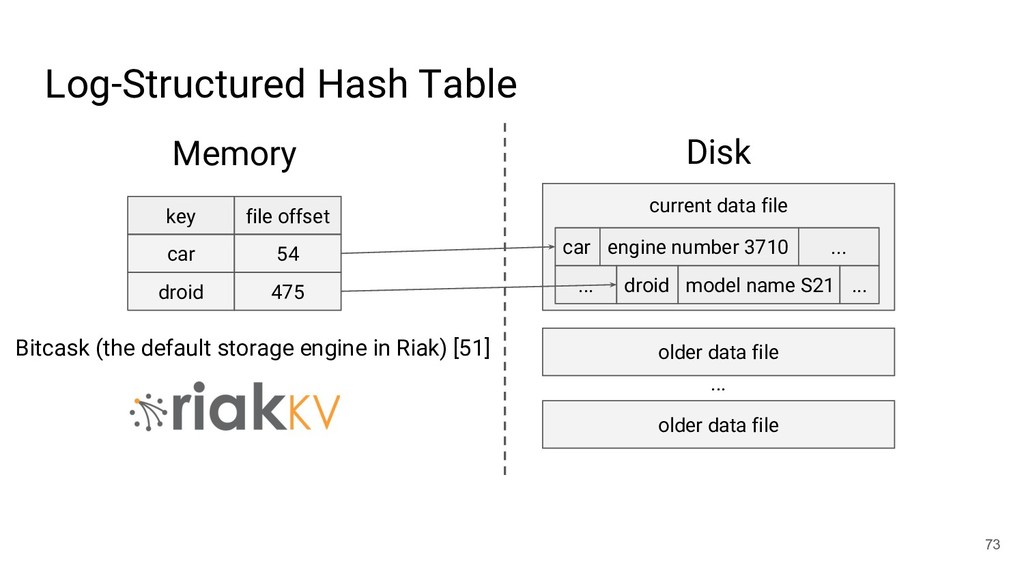{kind=link}
{kind=link}
{kind=link}
![RUM Conjecture [38, 39] 76 Read Optimized Update Optimized Memory](https://files.speakerdeck.com/presentations/01ef6971fe4f4a9799f3ba06b71288b7/slide_75.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Interesting projects The periodic table of data structures [41] 83](https://files.speakerdeck.com/presentations/01ef6971fe4f4a9799f3ba06b71288b7/slide_82.jpg){kind=link}
![Interesting projects The periodic table of data structures [41] Data](https://files.speakerdeck.com/presentations/01ef6971fe4f4a9799f3ba06b71288b7/slide_83.jpg){kind=link}
![Interesting projects The periodic table of data structures [41] Data](https://files.speakerdeck.com/presentations/01ef6971fe4f4a9799f3ba06b71288b7/slide_84.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
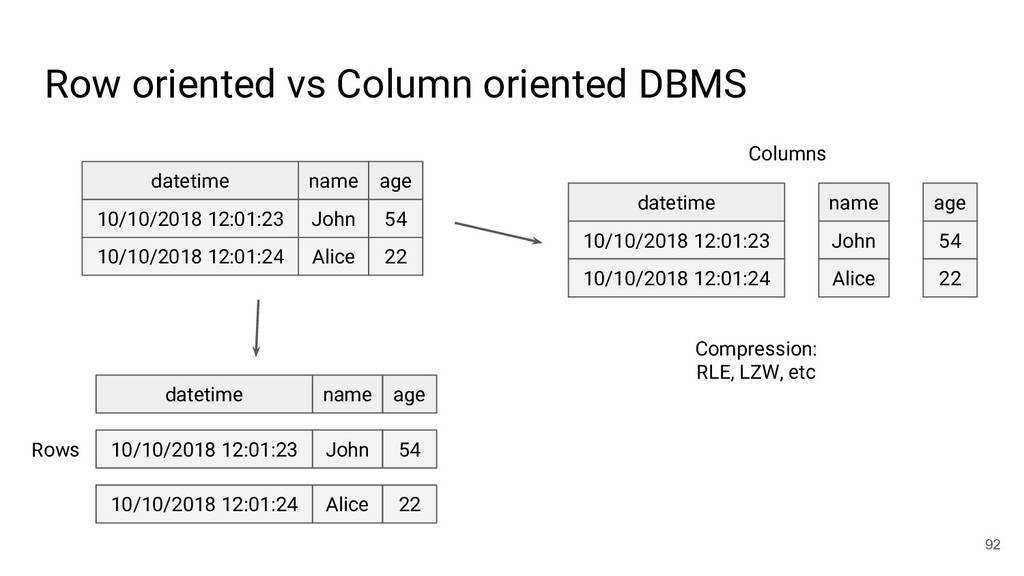{kind=link}
{kind=link}
{kind=link}
![95 RDBMS/SQL, NoSQL, NewSQL [72] RDBMS/SQL NoSQL NewSQL Relational Yes](https://files.speakerdeck.com/presentations/01ef6971fe4f4a9799f3ba06b71288b7/slide_94.jpg){kind=link}
![96 Matthew Aslett, The 451 Group [55]](https://files.speakerdeck.com/presentations/01ef6971fe4f4a9799f3ba06b71288b7/slide_95.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![106 Books [1, 28]](https://files.speakerdeck.com/presentations/01ef6971fe4f4a9799f3ba06b71288b7/slide_105.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}