n-th Fibonacci number')), Assign(targets=[Name(id='a', ctx=Store())], value=Num(n=0)), Assign(targets=[Name(id='b', ctx=Store())], value=Num(n=1)), If(test=Compare(left=Name(id='n', ctx=Load()), ops=[Lt()], comparators=[Num(n=1)]), body=[ Return(value=Name(id='a', ctx=Load())) ], orelse=[]), Assign(targets=[Name(id='i', ctx=Store())], value=Num(n=0)), While(test=Compare(left=Name(id='i', ctx=Load()), ops=[Lt()], comparators=[Name(id='n', ctx=Load())]), body=[ Assign(targets=[Name(id='temp', ctx=Store())], value=Name(id='a', ctx=Load())), Assign(targets=[Name(id='a', ctx=Store())], value=Name(id='b', ctx=Load())), Assign(targets=[Name(id='b', ctx=Store())], value=BinOp( left=Name(id='temp', ctx=Load()), op=Add(), right=Name(id='b', ctx=Load()))), AugAssign(target=Name(id='i', ctx=Store()), op=Add(), value=Num(n=1)) ], orelse=[]), Return(value=Name(id='a', ctx=Load())) ], decorator_list=[Name(id='jit', ctx=Load())]) ])
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![AST Module(body=[ FunctionDef(name='fibonacci', args=arguments(args=[Name(id='n', ctx=Param())], vararg=None, kwarg=None, defaults=[]), body=[ Expr(value=Str(s='Returns](https://files.speakerdeck.com/presentations/42514b3cb72944818b7cadd6eec1e257/slide_17.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
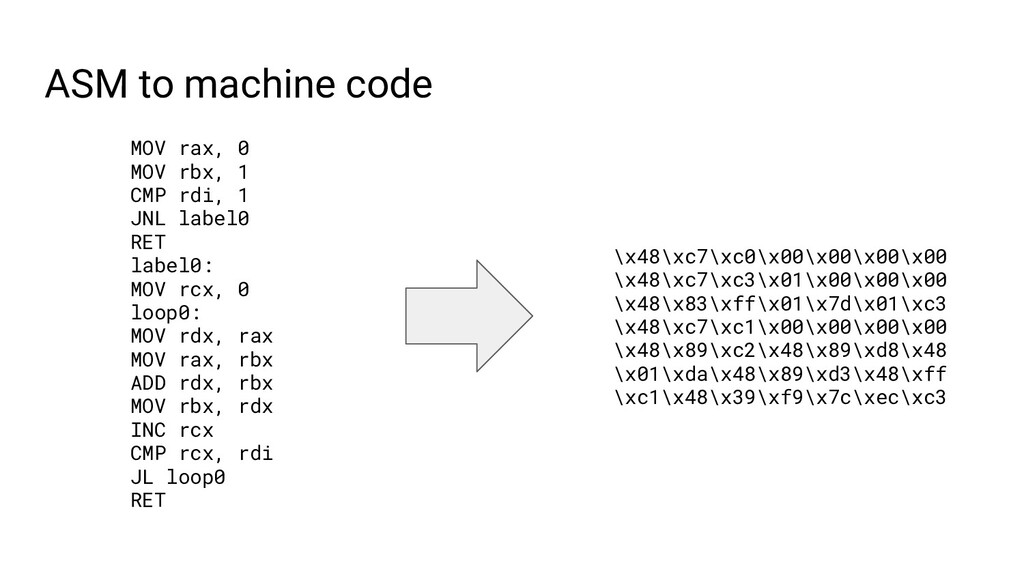{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
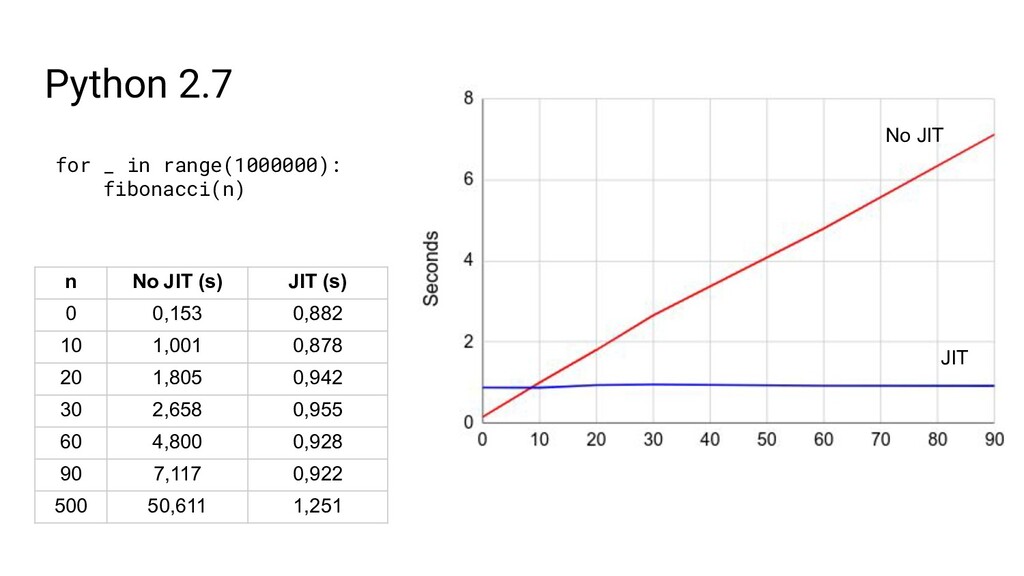{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}