DeNA では様々な事業で AI を活用しており、事業毎に異なる制約条件のもとデータサイエンティストが様々なモデルをつくっています。
データサイエンティストがつくったモデルはそのままでは利用できず、実際に利用するために機械学習基盤やインフラを用意したり、フロントエンドの開発を行うなど、様々なサポートが必要となります。そういった AI 以外の全てをサポートするのが MLOps エンジニアであり、様々な課題を解決することが求められます。
本発表では、DeNA の MLOps エンジニアの業務を俯瞰しながら、主に機械学習基盤周りの話をご紹介するとともに、MLOps エンジニアがどのような課題と日々向き合っているのかお話します。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
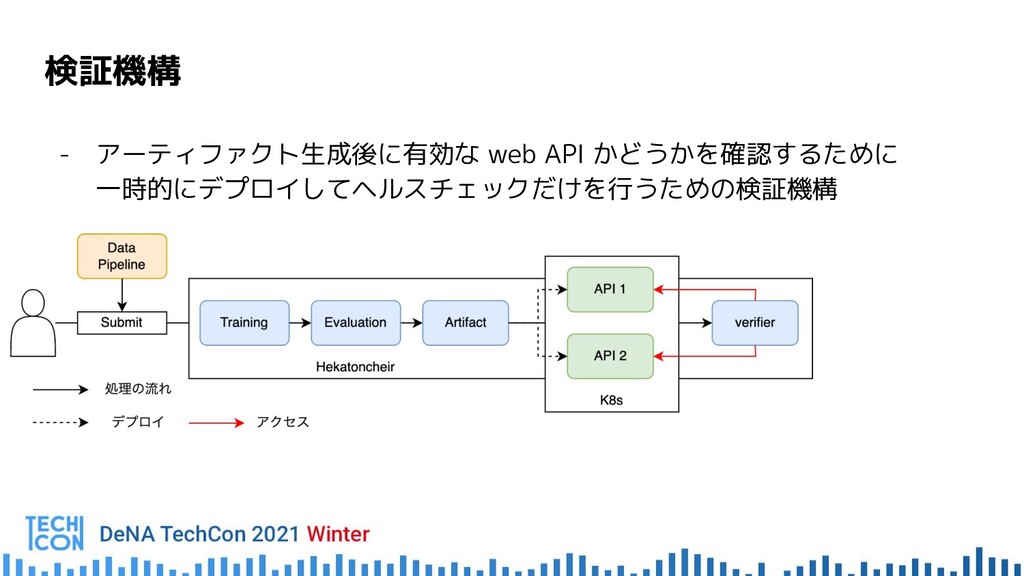{kind=link}
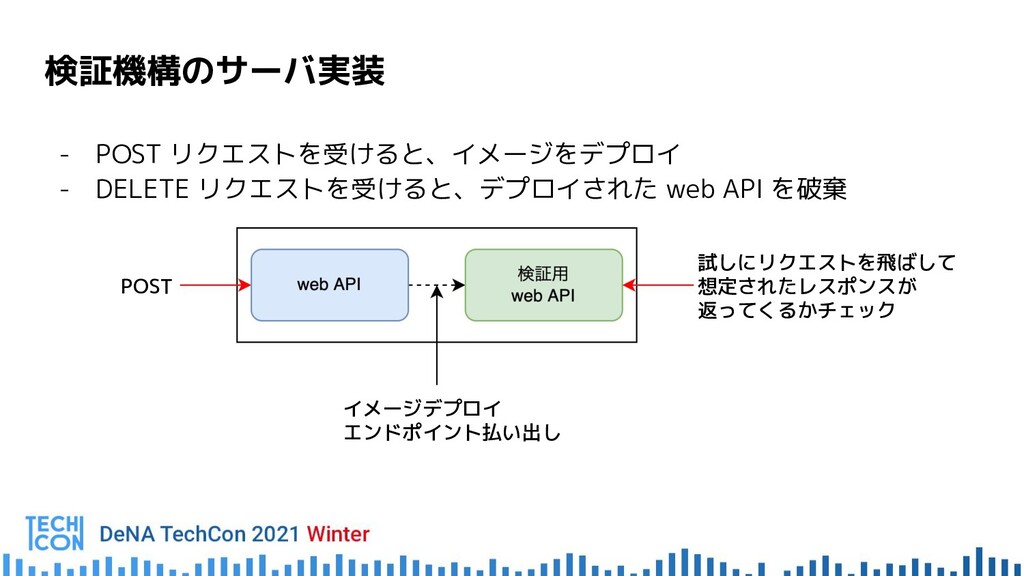{kind=link}
{kind=link}
{kind=link}
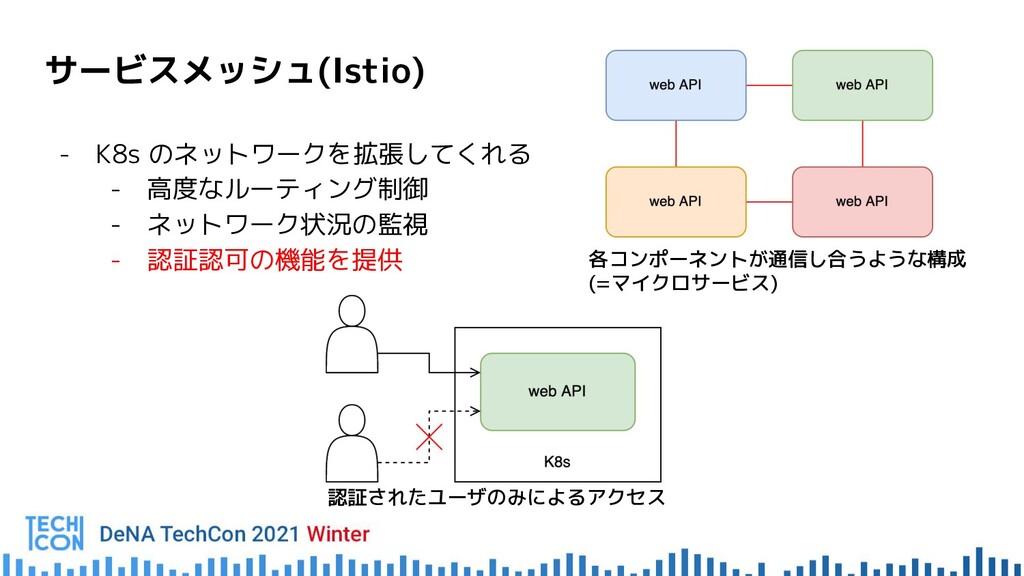{kind=link}
{kind=link}
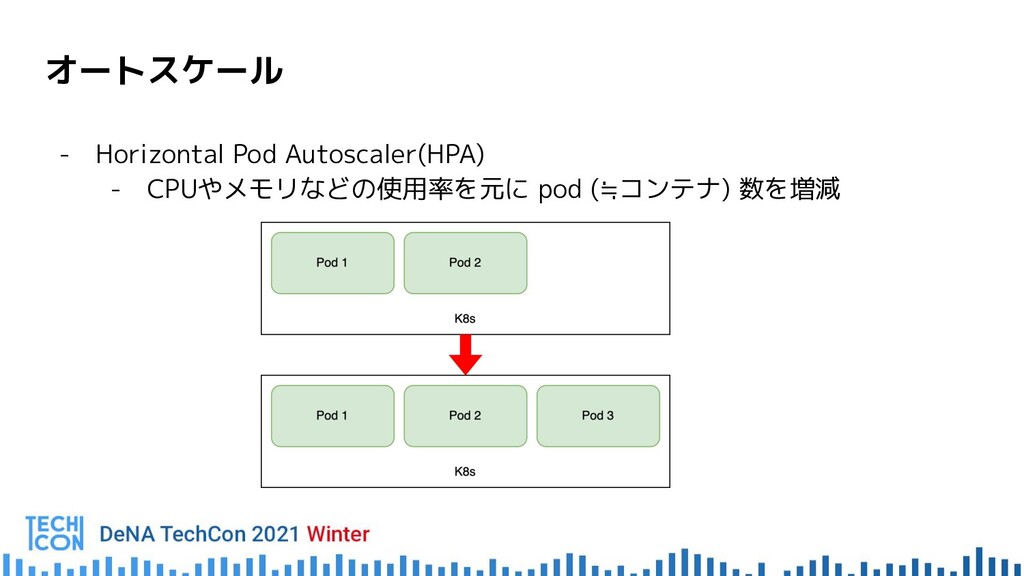{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}