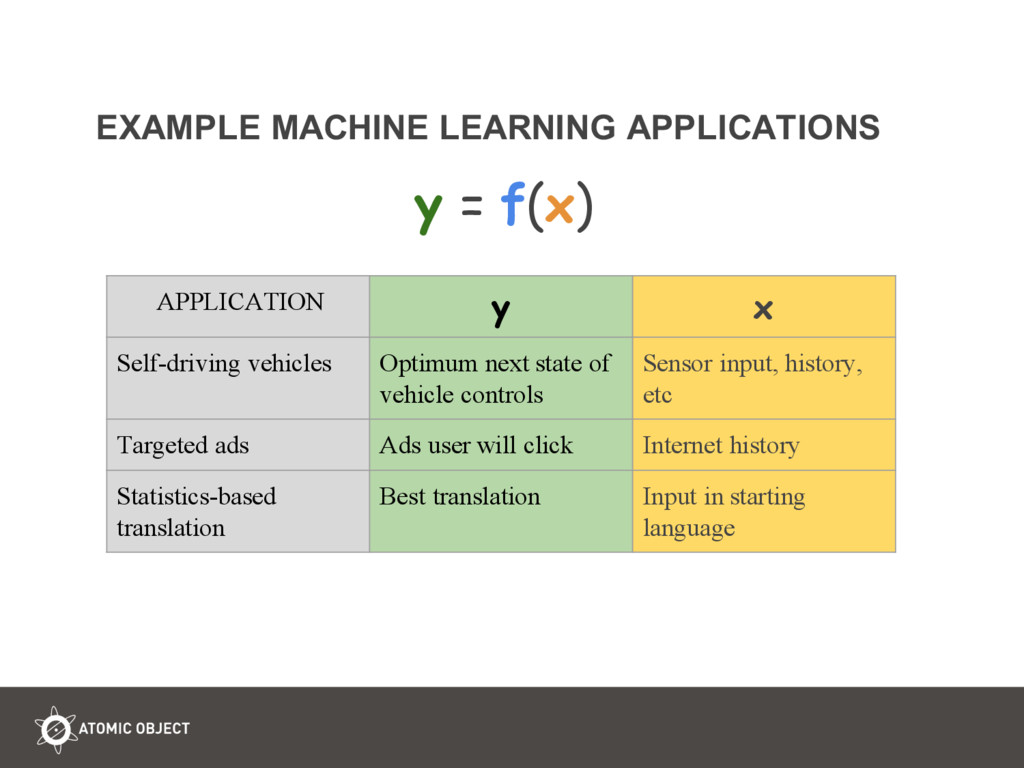
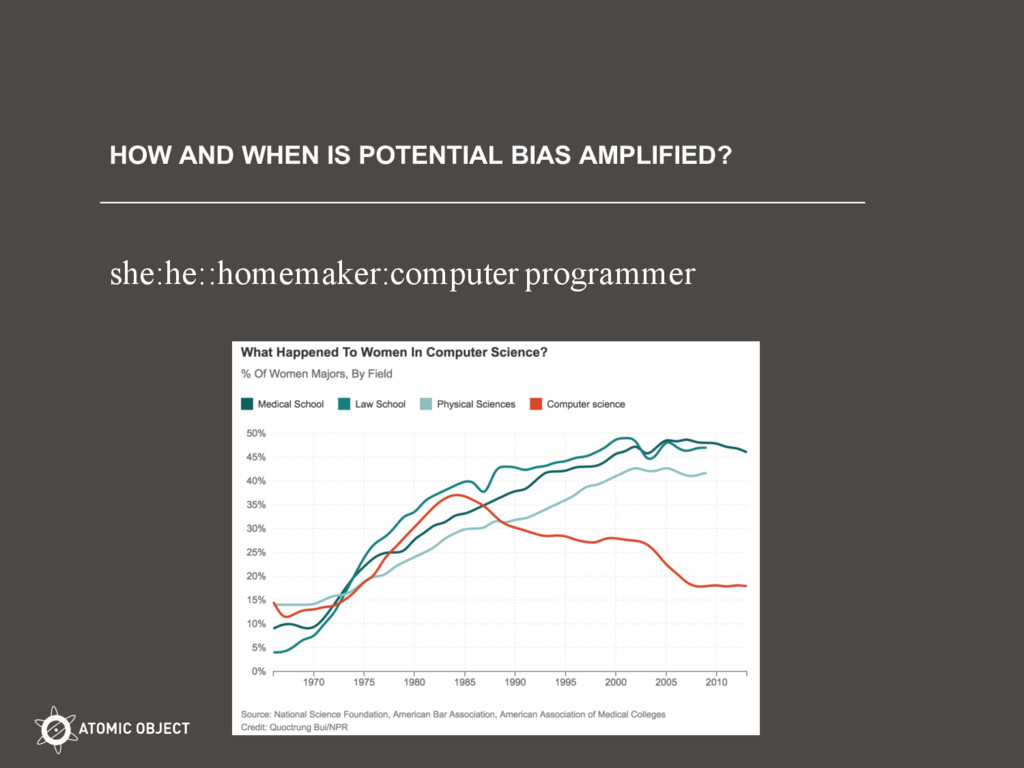
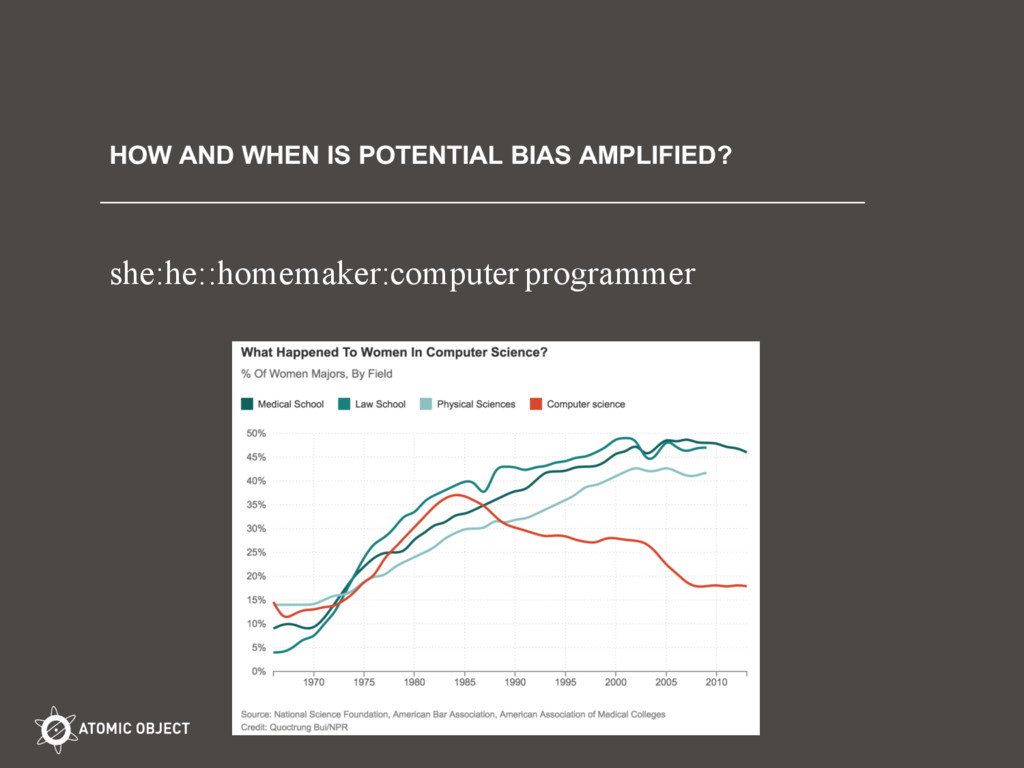
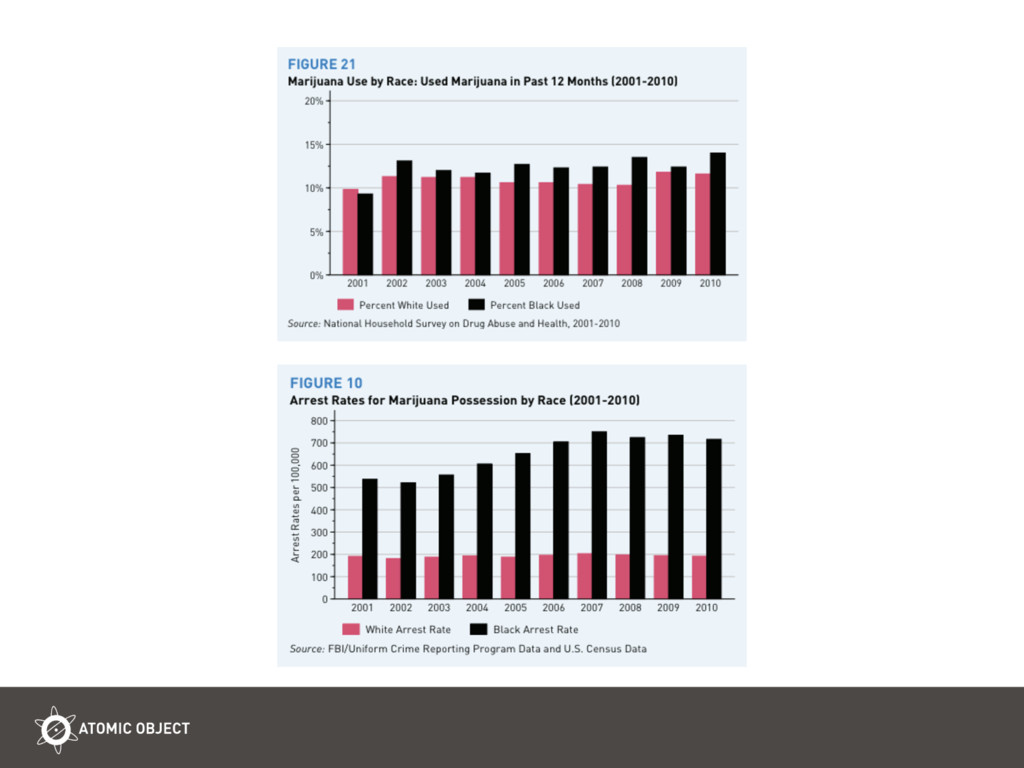
Machine learning and predictive statistics systems learn human biases when they rely on data generated by humans. Humans generate data like text, search terms, browser histories, grades and employment status, criminal and financial records, etc. This talk uses exciting work at MIT about how Google’s word2vec learns gender bias in Google News training data. Then comes the good news that we can use vector math ‘debias’ word2vec’s learned representation of English words and their relationships. The second half of the talk explores the use of predictive statistics in criminal sentencing. It opens up questions we need to ask when applying machine learning to humans: 1) Will the future resemble the past? Do we want it to? 2) How objective is raw data? 3) Is there an acceptable margin of error? 4) Is more data always better? 4) How and when is a slight bias in raw amplified in a machine learning application? The audience is encouraged to go after the opportunity to use de-biasing in such sensitive applications, and the opportunity for deep discussions about how we want to treat each other in light of the data and biases we live with.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}