This are slides from my talk at Self.Conference 2017. Machine learning techniques rely on some assumptions, like that the future will resemble the past, and that data is objective. Those assumptions have held up well in machine learning applications like advertising and self driving cars. But what about applications that predict a person’s future actions and use that prediction to make a big decision about that person’s life? What if we train our machine learning systems on data containing human biases that we do not want to reinforce in the future? This talk first dives into how Google's Word2Vec learns gender biases from input data, and promising work from MIT on how we can use math to 'unteach' the system these biases. It then looks at statistics-based prediction techniques used to make decisions in criminal sentencing - how racial bias comes into these systems, the risks and consequences of exacerbating that bias, and the possibility of accounting for it in a way that the systems can 'unlearn' the bias. Throughout, we consider a set of questions we must ask when applying machine learning to make decisions about one another. The audience is invited to take apply these questions to other human-focused applications such as in health, hiring, insurance, finance, education, and media.
{kind=link}
{kind=link}
{kind=link}
![[email protected] Q: HOW DO MACHINE LEARNING TOOLS LEARN HUMAN BIASES?](https://files.speakerdeck.com/presentations/a26d083be85944afb6271402d6eca044/slide_3.jpg){kind=link}
![[email protected] Q: HOW DO MACHINE LEARNING TOOLS LEARN HUMAN BIASES?](https://files.speakerdeck.com/presentations/a26d083be85944afb6271402d6eca044/slide_4.jpg){kind=link}
![[email protected] Q: CAN WE UNTEACH THEM? A: Yes . .](https://files.speakerdeck.com/presentations/a26d083be85944afb6271402d6eca044/slide_5.jpg){kind=link}
![[email protected] Q: CAN WE UNTEACH THEM? A: Yes . .](https://files.speakerdeck.com/presentations/a26d083be85944afb6271402d6eca044/slide_6.jpg){kind=link}
![[email protected] WHAT’S AT STAKE? When we make decisions about a](https://files.speakerdeck.com/presentations/a26d083be85944afb6271402d6eca044/slide_7.jpg){kind=link}
![[email protected] WHAT’S AT STAKE? When we make decisions about a](https://files.speakerdeck.com/presentations/a26d083be85944afb6271402d6eca044/slide_8.jpg){kind=link}
![[email protected] THE ROUTE FOR TODAY o Machine learning in five](https://files.speakerdeck.com/presentations/a26d083be85944afb6271402d6eca044/slide_9.jpg){kind=link}
![[email protected] QUESTIONS ALONG THE WAY o Will the future resemble](https://files.speakerdeck.com/presentations/a26d083be85944afb6271402d6eca044/slide_10.jpg){kind=link}
{kind=link}
![[email protected] WHO ARE WE TRAVELING WITH?](https://files.speakerdeck.com/presentations/a26d083be85944afb6271402d6eca044/slide_12.jpg){kind=link}
![[email protected] MACHINE LEARNING* IN < 5 MINUTES *aka Artificial Intelligence](https://files.speakerdeck.com/presentations/a26d083be85944afb6271402d6eca044/slide_13.jpg){kind=link}
![[email protected] PREDICTIVE STATS IN < 5 MINUTES 1. Ask a](https://files.speakerdeck.com/presentations/a26d083be85944afb6271402d6eca044/slide_14.jpg){kind=link}
![[email protected] PREDICTIVE STATS IN < 5 MINUTES 1. Ask a](https://files.speakerdeck.com/presentations/a26d083be85944afb6271402d6eca044/slide_15.jpg){kind=link}
![[email protected] PREDICTIVE STATS IN < 5 MINUTES 1. Ask a](https://files.speakerdeck.com/presentations/a26d083be85944afb6271402d6eca044/slide_16.jpg){kind=link}
![[email protected] PREDICTIVE STATS IN < 5 MINUTES 1. Ask a](https://files.speakerdeck.com/presentations/a26d083be85944afb6271402d6eca044/slide_17.jpg){kind=link}
![[email protected] PREDICTIVE STATS IN < 5 MINUTES 1. Ask a](https://files.speakerdeck.com/presentations/a26d083be85944afb6271402d6eca044/slide_18.jpg){kind=link}
![[email protected] EXAMPLE MACHINE LEARNING APPLICATIONS APPLICATION y x Self-driving vehicles](https://files.speakerdeck.com/presentations/a26d083be85944afb6271402d6eca044/slide_19.jpg){kind=link}
![[email protected] EXAMPLE MACHINE LEARNING APPLICATIONS APPLICATION y x Self-driving vehicles](https://files.speakerdeck.com/presentations/a26d083be85944afb6271402d6eca044/slide_20.jpg){kind=link}
![[email protected] ASSUMPTIONS IN THIS PROCESS o The future will resemble](https://files.speakerdeck.com/presentations/a26d083be85944afb6271402d6eca044/slide_21.jpg){kind=link}
![[email protected] WHERE ARE WE NOW? o Machine learning in five](https://files.speakerdeck.com/presentations/a26d083be85944afb6271402d6eca044/slide_22.jpg){kind=link}
![[email protected] THE CURIOUS CASE OF GOOGLE’S WORD2VEC](https://files.speakerdeck.com/presentations/a26d083be85944afb6271402d6eca044/slide_23.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![[email protected] WHAT IS A WORD EMBEDDING? y = f(x) similar](https://files.speakerdeck.com/presentations/a26d083be85944afb6271402d6eca044/slide_31.jpg){kind=link}
{kind=link}
![[email protected] less gendered more gendered](https://files.speakerdeck.com/presentations/a26d083be85944afb6271402d6eca044/slide_33.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![[email protected] ASSUMPTIONS IN MACHINE LEARNING o The future will resemble](https://files.speakerdeck.com/presentations/a26d083be85944afb6271402d6eca044/slide_38.jpg){kind=link}
![[email protected] QUESTIONS ALONG THE WAY o Will the future resemble](https://files.speakerdeck.com/presentations/a26d083be85944afb6271402d6eca044/slide_39.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![[email protected] RAW DATA WITH LITTLE TO NO HUMAN BIAS Weather](https://files.speakerdeck.com/presentations/a26d083be85944afb6271402d6eca044/slide_44.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![[email protected] less gendered more gendered](https://files.speakerdeck.com/presentations/a26d083be85944afb6271402d6eca044/slide_54.jpg){kind=link}
{kind=link}
![[email protected] WHERE ARE WE NOW? o Machine learning in five](https://files.speakerdeck.com/presentations/a26d083be85944afb6271402d6eca044/slide_56.jpg){kind=link}
![[email protected] HIGH STAKES PREDICTIVE STATISTICS IN THE CRIMINAL SYSTEM](https://files.speakerdeck.com/presentations/a26d083be85944afb6271402d6eca044/slide_57.jpg){kind=link}
{kind=link}
![[email protected] THE WHAT Risk assessments such as COMPAS, which assign](https://files.speakerdeck.com/presentations/a26d083be85944afb6271402d6eca044/slide_59.jpg){kind=link}
![[email protected]](https://files.speakerdeck.com/presentations/a26d083be85944afb6271402d6eca044/slide_60.jpg){kind=link}
![[email protected] QUESTIONS THAT COME TO MIND? Risk assessments such as](https://files.speakerdeck.com/presentations/a26d083be85944afb6271402d6eca044/slide_61.jpg){kind=link}
![[email protected] THE WHAT y = f(x) risk of future arrest](https://files.speakerdeck.com/presentations/a26d083be85944afb6271402d6eca044/slide_62.jpg){kind=link}
![[email protected] THE WHEN - at arrest, to assign bail (y](https://files.speakerdeck.com/presentations/a26d083be85944afb6271402d6eca044/slide_63.jpg){kind=link}
![[email protected] THE OPPORTUNITIES - keep low-risk people out of the](https://files.speakerdeck.com/presentations/a26d083be85944afb6271402d6eca044/slide_64.jpg){kind=link}
![[email protected] THE DOUBLE-EDGED SWORDS - accuracy and errors are systematic](https://files.speakerdeck.com/presentations/a26d083be85944afb6271402d6eca044/slide_65.jpg){kind=link}
![[email protected] THE HOLY GRAIL](https://files.speakerdeck.com/presentations/a26d083be85944afb6271402d6eca044/slide_66.jpg){kind=link}
![[email protected] THE HOLY GRAIL “We are at unique time in](https://files.speakerdeck.com/presentations/a26d083be85944afb6271402d6eca044/slide_67.jpg){kind=link}
![[email protected] THE CONTROVERSY Makers of COMPAS: “no racial bias.” ProPublica’s](https://files.speakerdeck.com/presentations/a26d083be85944afb6271402d6eca044/slide_68.jpg){kind=link}
![[email protected] SOURCES OF CONTROVERSY - The model and algorithm are](https://files.speakerdeck.com/presentations/a26d083be85944afb6271402d6eca044/slide_69.jpg){kind=link}
![[email protected] THE POINT OF AGREEMENT If black people in general](https://files.speakerdeck.com/presentations/a26d083be85944afb6271402d6eca044/slide_70.jpg){kind=link}
![[email protected]](https://files.speakerdeck.com/presentations/a26d083be85944afb6271402d6eca044/slide_71.jpg){kind=link}
![[email protected] THE POINT OF AGREEMENT People’s behavior is biased.](https://files.speakerdeck.com/presentations/a26d083be85944afb6271402d6eca044/slide_72.jpg){kind=link}
![[email protected] THE POINT OF AGREEMENT People’s behavior is biased. People’s](https://files.speakerdeck.com/presentations/a26d083be85944afb6271402d6eca044/slide_73.jpg){kind=link}
![[email protected] THE POINT OF AGREEMENT People’s behavior is biased. People’s](https://files.speakerdeck.com/presentations/a26d083be85944afb6271402d6eca044/slide_74.jpg){kind=link}
![[email protected] REPHRASED FOR WHITE SUPREMACY . . . People learn](https://files.speakerdeck.com/presentations/a26d083be85944afb6271402d6eca044/slide_75.jpg){kind=link}
![[email protected] QUESTIONS ALONG THE WAY o Will the future resemble](https://files.speakerdeck.com/presentations/a26d083be85944afb6271402d6eca044/slide_76.jpg){kind=link}
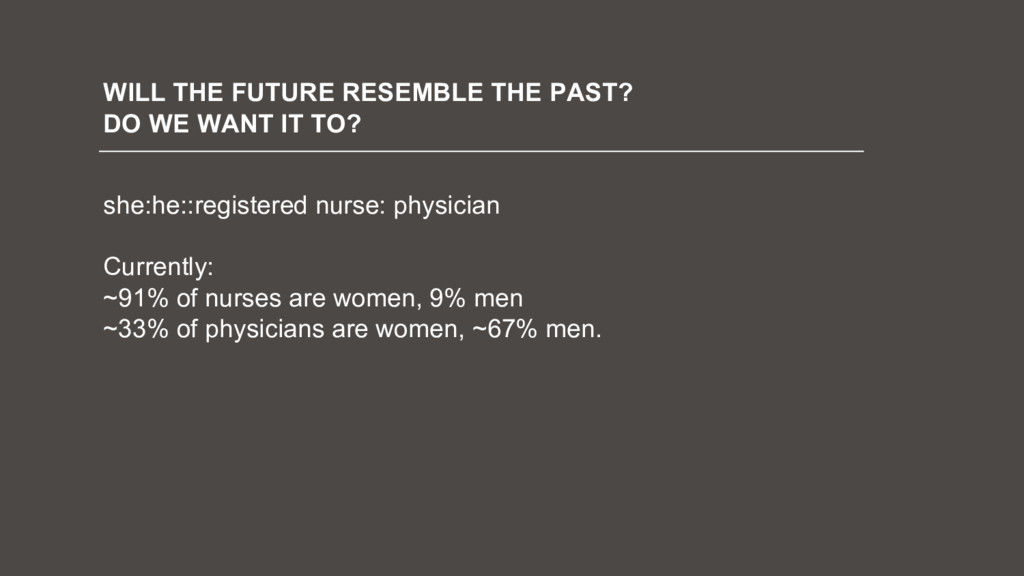
![[email protected] WILL THE FUTURE RESEMBLE THE PAST? DO WE WANT](https://files.speakerdeck.com/presentations/a26d083be85944afb6271402d6eca044/slide_77.jpg){kind=link}
![[email protected] WILL THE FUTURE RESEMBLE THE PAST? DO WE WANT](https://files.speakerdeck.com/presentations/a26d083be85944afb6271402d6eca044/slide_78.jpg){kind=link}
![[email protected] WILL THE FUTURE RESEMBLE THE PAST? DO WE WANT](https://files.speakerdeck.com/presentations/a26d083be85944afb6271402d6eca044/slide_79.jpg){kind=link}
![[email protected] HOW OBJECTIVE IS RAW DATA?](https://files.speakerdeck.com/presentations/a26d083be85944afb6271402d6eca044/slide_80.jpg){kind=link}
![[email protected] HOW OBJECTIVE IS RAW DATA? The raw data is:](https://files.speakerdeck.com/presentations/a26d083be85944afb6271402d6eca044/slide_81.jpg){kind=link}
![[email protected] HOW OBJECTIVE IS RAW DATA? The raw data is:](https://files.speakerdeck.com/presentations/a26d083be85944afb6271402d6eca044/slide_82.jpg){kind=link}
![[email protected] HOW OBJECTIVE IS RAW DATA? Part of the argument](https://files.speakerdeck.com/presentations/a26d083be85944afb6271402d6eca044/slide_83.jpg){kind=link}
![[email protected] HOW OBJECTIVE IS RAW DATA? Part of the argument](https://files.speakerdeck.com/presentations/a26d083be85944afb6271402d6eca044/slide_84.jpg){kind=link}
![[email protected] IS THERE AN ACCEPTABLE MARGIN OF ERROR?](https://files.speakerdeck.com/presentations/a26d083be85944afb6271402d6eca044/slide_85.jpg){kind=link}
![[email protected] IS THERE AN ACCEPTABLE MARGIN OF ERROR? - False](https://files.speakerdeck.com/presentations/a26d083be85944afb6271402d6eca044/slide_86.jpg){kind=link}
![[email protected] IS THERE AN ACCEPTABLE MARGIN OF ERROR? - False](https://files.speakerdeck.com/presentations/a26d083be85944afb6271402d6eca044/slide_87.jpg){kind=link}
![[email protected] IS MORE DATA ALWAYS BETTER?](https://files.speakerdeck.com/presentations/a26d083be85944afb6271402d6eca044/slide_88.jpg){kind=link}
![[email protected] IS MORE DATA ALWAYS BETTER? More samples -> usually.](https://files.speakerdeck.com/presentations/a26d083be85944afb6271402d6eca044/slide_89.jpg){kind=link}
![[email protected] IS MORE DATA ALWAYS BETTER? More samples -> usually.](https://files.speakerdeck.com/presentations/a26d083be85944afb6271402d6eca044/slide_90.jpg){kind=link}
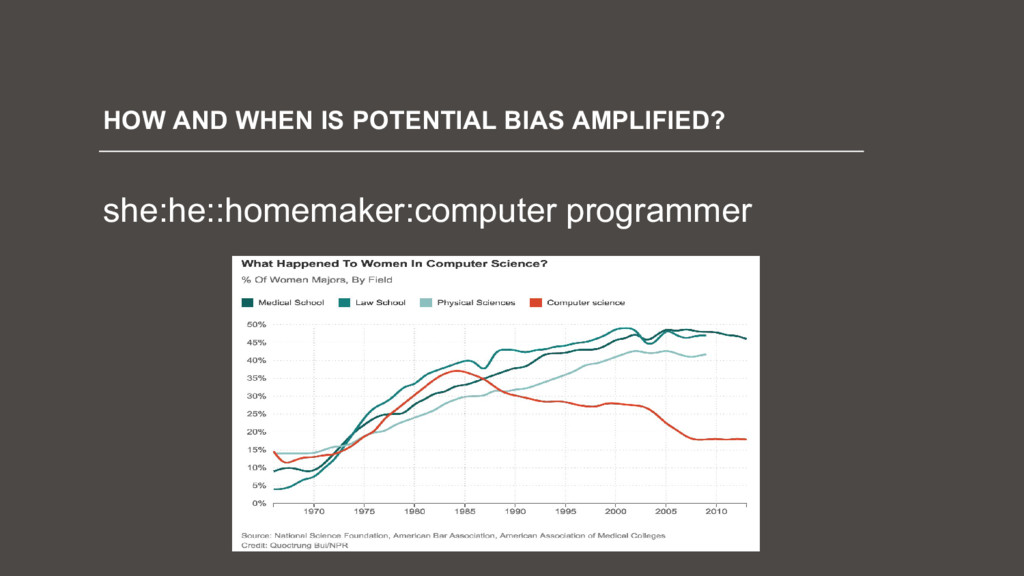
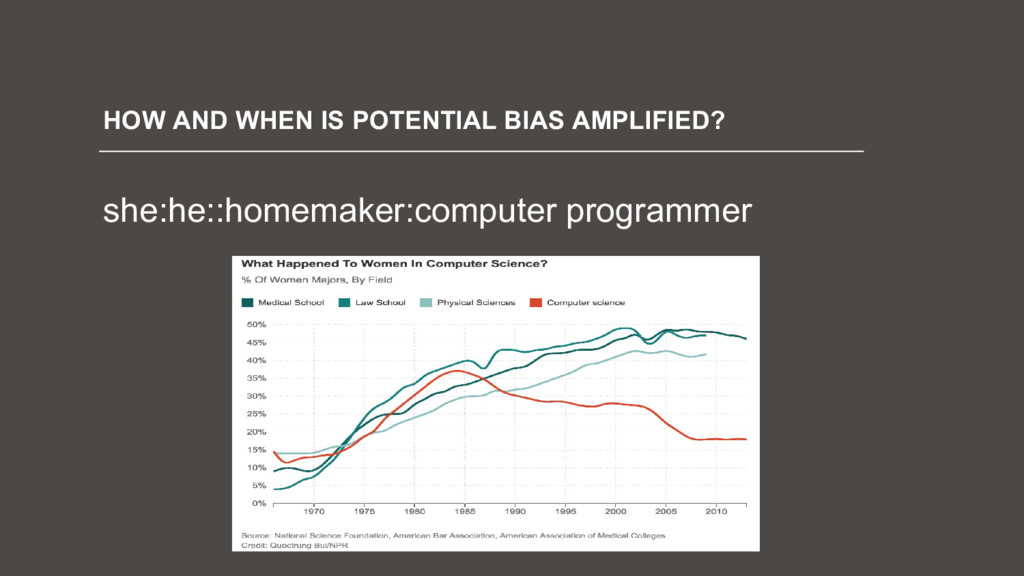
![[email protected] HOW AND WHEN MIGHT BIAS BE AMPLIFIED?](https://files.speakerdeck.com/presentations/a26d083be85944afb6271402d6eca044/slide_91.jpg){kind=link}
![[email protected] HOW AND WHEN MIGHT BIAS BE AMPLIFIED? 1) The](https://files.speakerdeck.com/presentations/a26d083be85944afb6271402d6eca044/slide_92.jpg){kind=link}
![[email protected] HOW AND WHEN MIGHT BIAS BE AMPLIFIED? 1) The](https://files.speakerdeck.com/presentations/a26d083be85944afb6271402d6eca044/slide_93.jpg){kind=link}
![[email protected] HOW AND WHEN MIGHT BIAS BE AMPLIFIED? 1) The](https://files.speakerdeck.com/presentations/a26d083be85944afb6271402d6eca044/slide_94.jpg){kind=link}
![[email protected] HOW AND WHEN MIGHT BIAS BE AMPLIFIED? 1) The](https://files.speakerdeck.com/presentations/a26d083be85944afb6271402d6eca044/slide_95.jpg){kind=link}
![[email protected] HOW AND WHEN MIGHT BIAS BE AMPLIFIED? 1) The](https://files.speakerdeck.com/presentations/a26d083be85944afb6271402d6eca044/slide_96.jpg){kind=link}
![[email protected] HOW AND WHEN MIGHT BIAS BE AMPLIFIED? 1) The](https://files.speakerdeck.com/presentations/a26d083be85944afb6271402d6eca044/slide_97.jpg){kind=link}
![[email protected] THE OPPORTUNITY Almost all data can be represented in](https://files.speakerdeck.com/presentations/a26d083be85944afb6271402d6eca044/slide_98.jpg){kind=link}
![[email protected] THE OPPORTUNITY Almost all data can be represented in](https://files.speakerdeck.com/presentations/a26d083be85944afb6271402d6eca044/slide_99.jpg){kind=link}
![[email protected] THE OPPORTUNITY Almost all data can be represented in](https://files.speakerdeck.com/presentations/a26d083be85944afb6271402d6eca044/slide_100.jpg){kind=link}
![[email protected] WHERE ARE WE NOW? o Machine learning in five](https://files.speakerdeck.com/presentations/a26d083be85944afb6271402d6eca044/slide_101.jpg){kind=link}
![[email protected] THE BIG POINT Raw data that is generated by](https://files.speakerdeck.com/presentations/a26d083be85944afb6271402d6eca044/slide_102.jpg){kind=link}
![[email protected] WHAT’S NEW WHAT’S NOT - The mask of ‘objective](https://files.speakerdeck.com/presentations/a26d083be85944afb6271402d6eca044/slide_103.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![[email protected]](https://files.speakerdeck.com/presentations/a26d083be85944afb6271402d6eca044/slide_109.jpg){kind=link}
![[email protected]](https://files.speakerdeck.com/presentations/a26d083be85944afb6271402d6eca044/slide_110.jpg){kind=link}
![[email protected] THANK YOU! Join #talk-machine-learning on Slack for links!](https://files.speakerdeck.com/presentations/a26d083be85944afb6271402d6eca044/slide_111.jpg){kind=link}