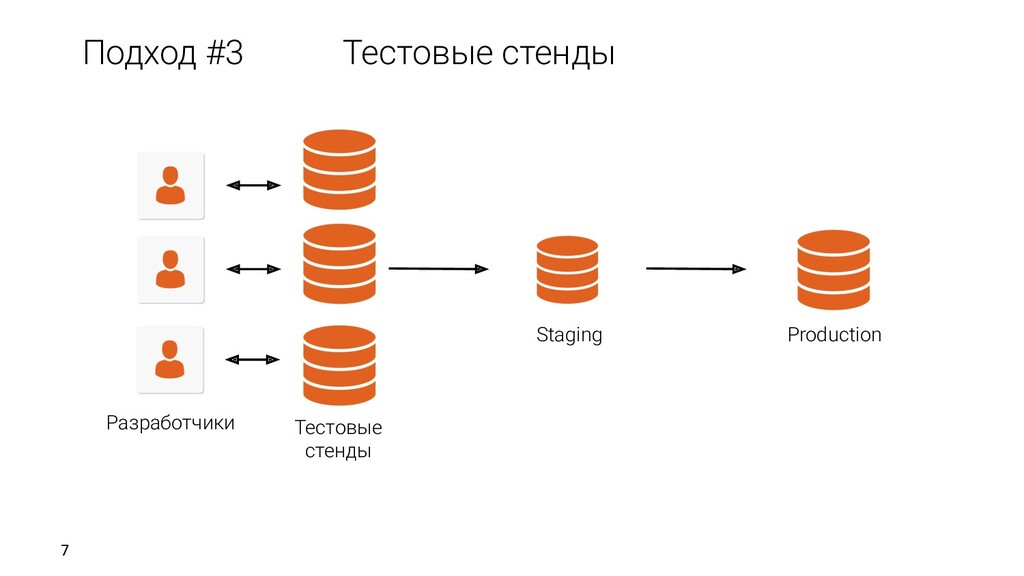
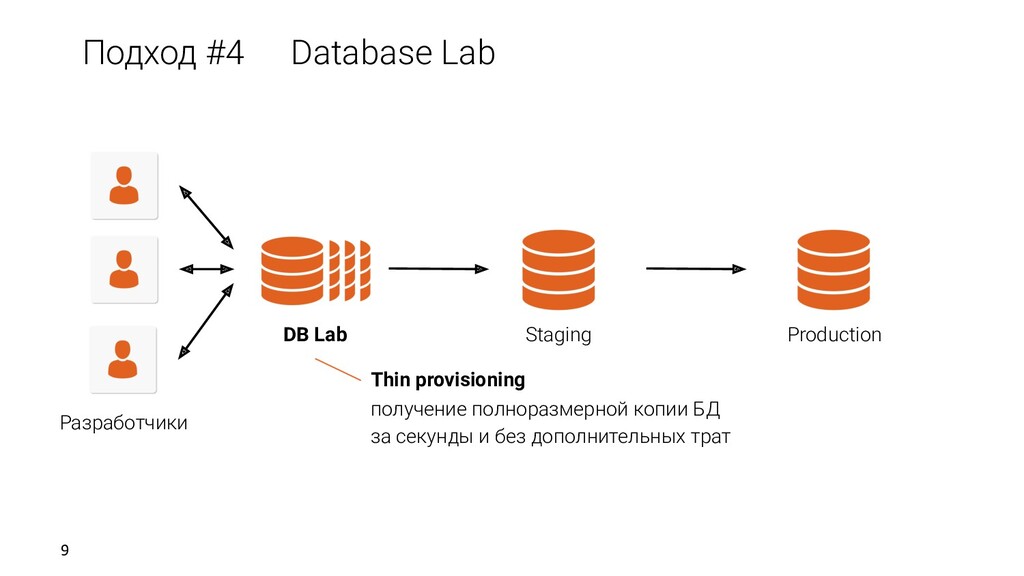
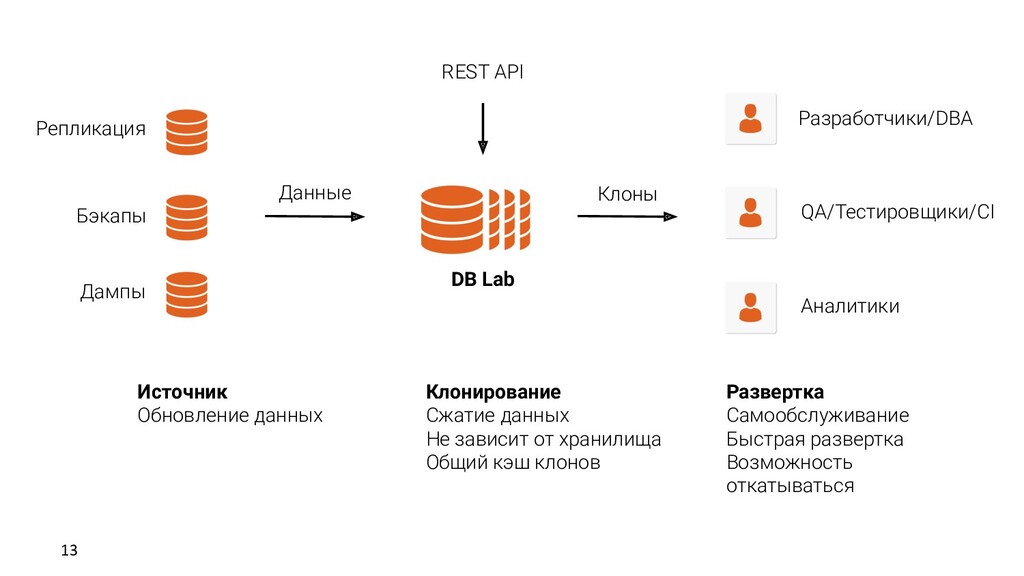
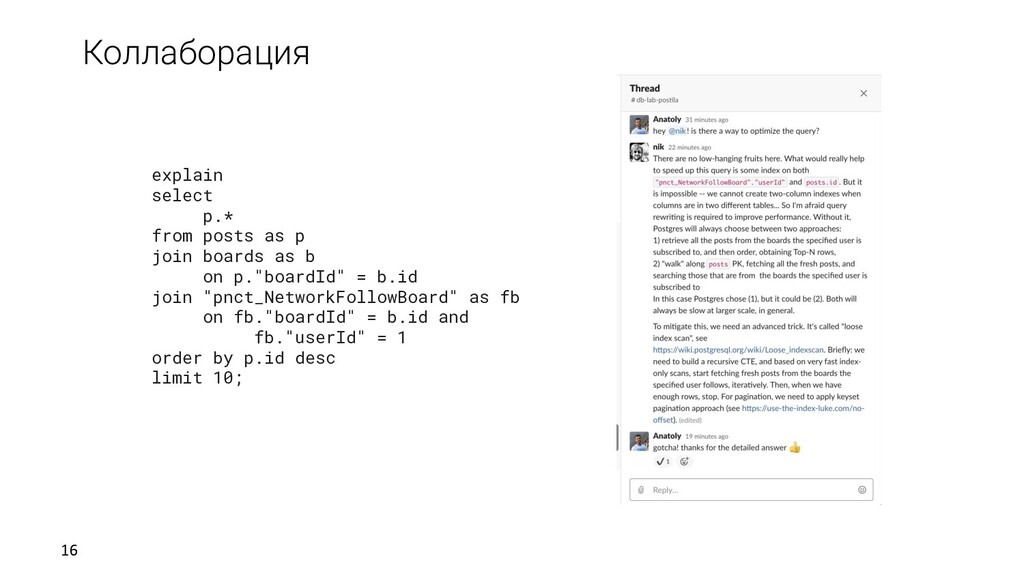
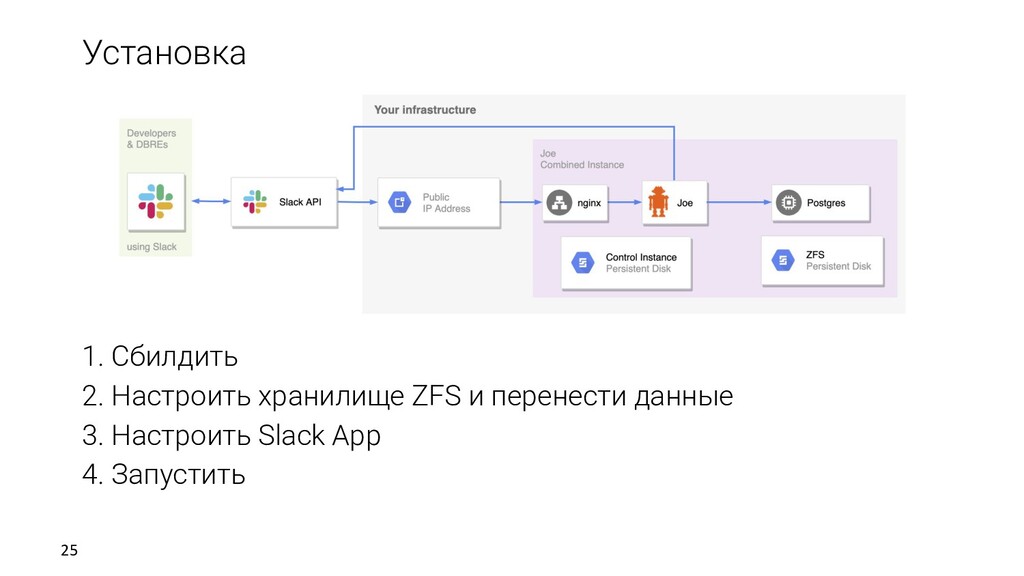
клонов Развертка Самообслуживание Быстрая развертка Возможность откатываться Источник Обновление данных Разработчики/DBA QA/Тестировщики/CI Аналитики Репликация Бэкапы Дампы DB Lab Данные Клоны REST API
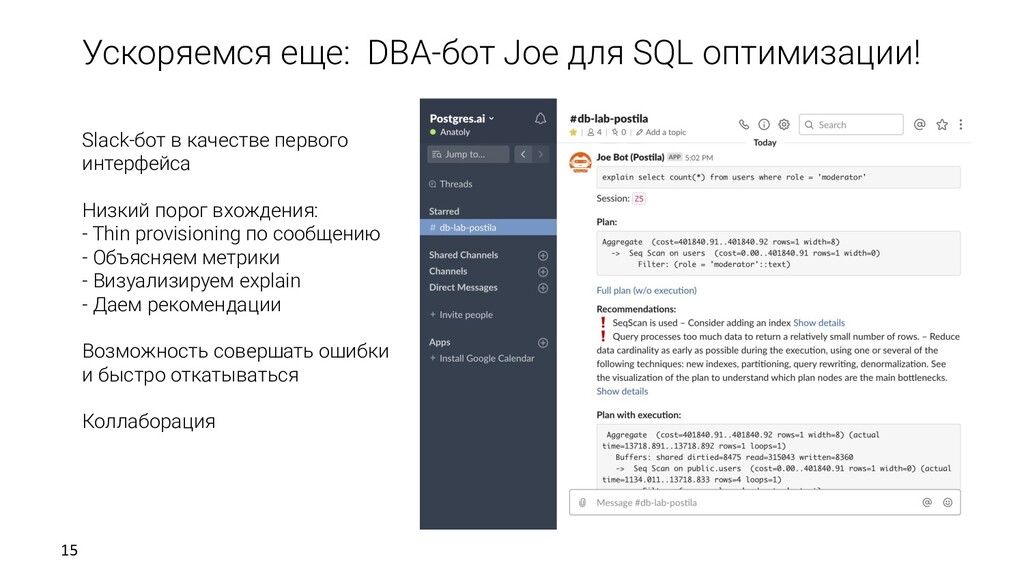
Thin provisioning по сообщению - Объясняем метрики - Визуализируем explain - Даем рекомендации Возможность совершать ошибки и быстро откатываться Коллаборация Ускоряемся еще: DBA-бот Joe для SQL оптимизации!
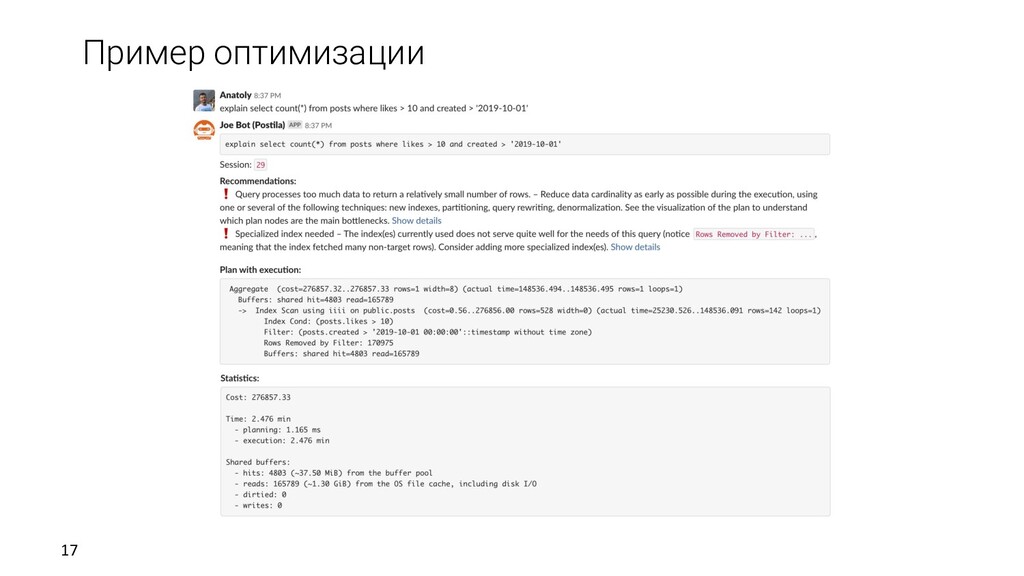
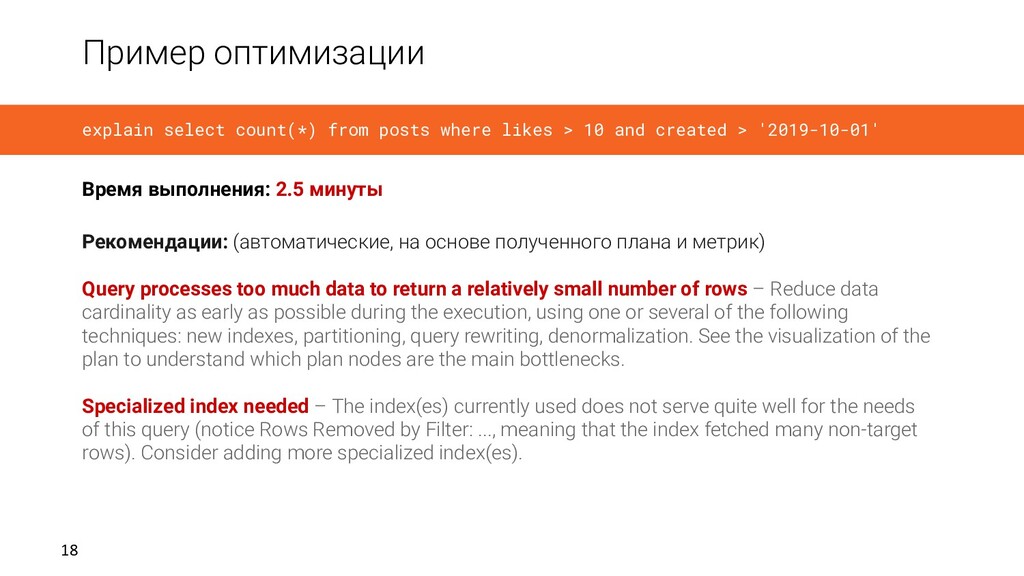
> 10 and created > '2019-10-01' Рекомендации: (автоматические, на основе полученного плана и метрик) Query processes too much data to return a relatively small number of rows – Reduce data cardinality as early as possible during the execution, using one or several of the following techniques: new indexes, partitioning, query rewriting, denormalization. See the visualization of the plan to understand which plan nodes are the main bottlenecks. Specialized index needed – The index(es) currently used does not serve quite well for the needs of this query (notice Rows Removed by Filter: ..., meaning that the index fetched many non-target rows). Consider adding more specialized index(es). Время выполнения: 2.5 минуты
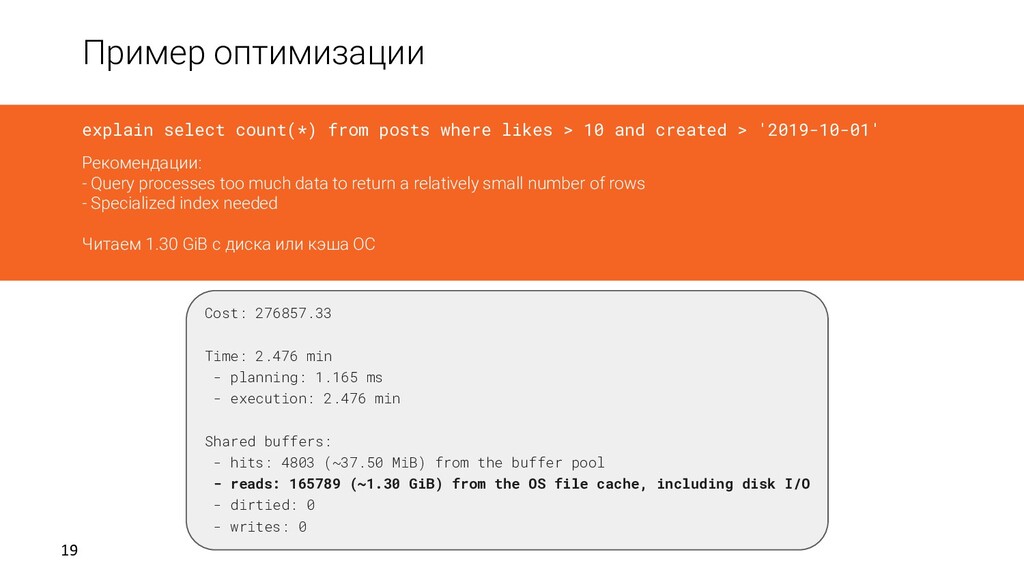
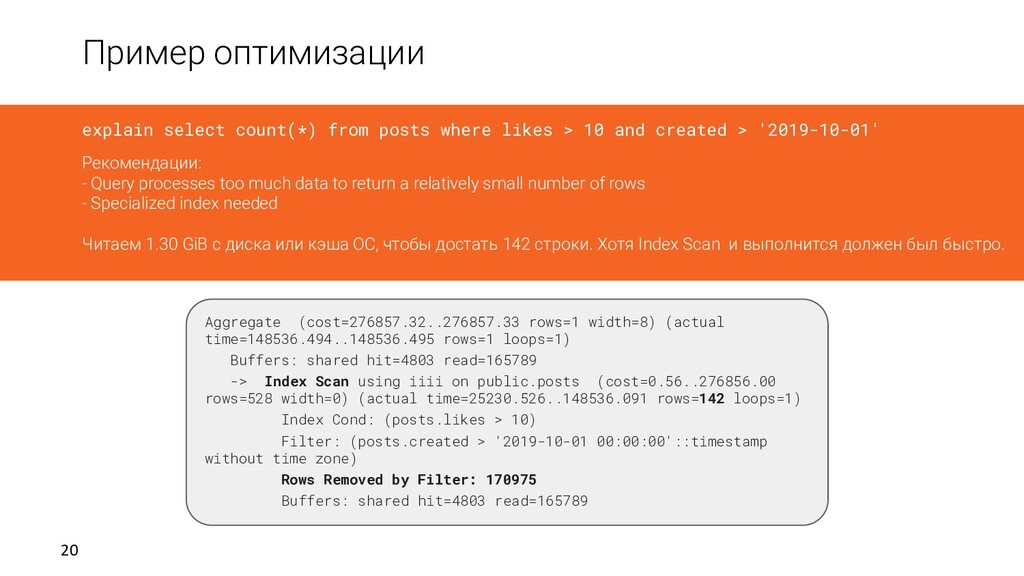
1.165 ms - execution: 2.476 min Shared buffers: - hits: 4803 (~37.50 MiB) from the buffer pool - reads: 165789 (~1.30 GiB) from the OS file cache, including disk I/O - dirtied: 0 - writes: 0 explain select count(*) from posts where likes > 10 and created > '2019-10-01' Рекомендации: - Query processes too much data to return a relatively small number of rows - Specialized index needed Читаем 1.30 GiB с диска или кэша ОС
loops=1) Buffers: shared hit=4803 read=165789 -> Index Scan using iiii on public.posts (cost=0.56..276856.00 rows=528 width=0) (actual time=25230.526..148536.091 rows=142 loops=1) Index Cond: (posts.likes > 10) Filter: (posts.created > '2019-10-01 00:00:00'::timestamp without time zone) Rows Removed by Filter: 170975 Buffers: shared hit=4803 read=165789 explain select count(*) from posts where likes > 10 and created > '2019-10-01' Рекомендации: - Query processes too much data to return a relatively small number of rows - Specialized index needed Читаем 1.30 GiB с диска или кэша ОС, чтобы достать 142 строки. Хотя Index Scan и выполнится должен был быстро.
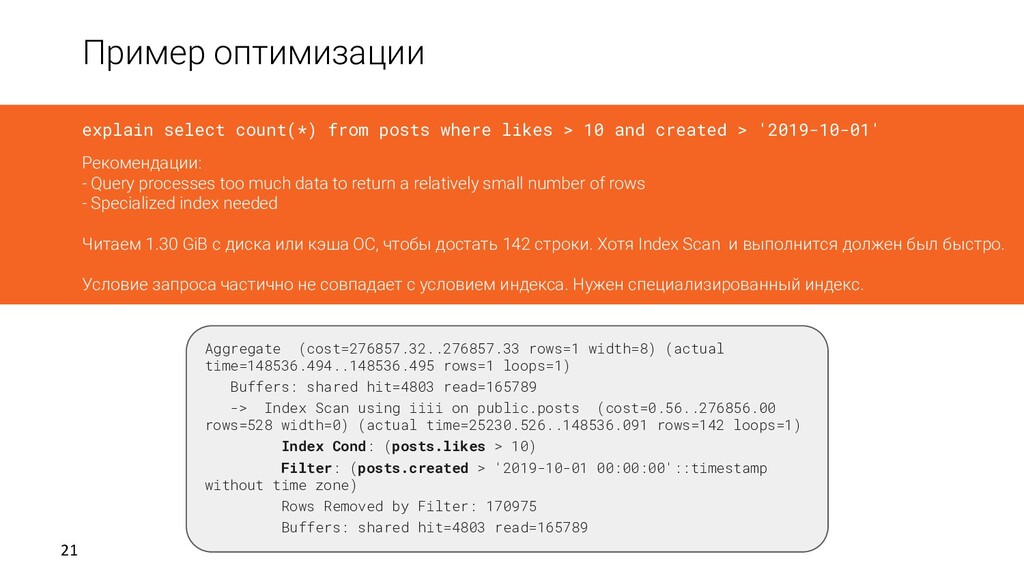
> 10 and created > '2019-10-01' Рекомендации: - Query processes too much data to return a relatively small number of rows - Specialized index needed Читаем 1.30 GiB с диска или кэша ОС, чтобы достать 142 строки. Хотя Index Scan и выполнится должен был быстро. Условие запроса частично не совпадает с условием индекса. Нужен специализированный индекс. Aggregate (cost=276857.32..276857.33 rows=1 width=8) (actual time=148536.494..148536.495 rows=1 loops=1) Buffers: shared hit=4803 read=165789 -> Index Scan using iiii on public.posts (cost=0.56..276856.00 rows=528 width=0) (actual time=25230.526..148536.091 rows=142 loops=1) Index Cond: (posts.likes > 10) Filter: (posts.created > '2019-10-01 00:00:00'::timestamp without time zone) Rows Removed by Filter: 170975 Buffers: shared hit=4803 read=165789
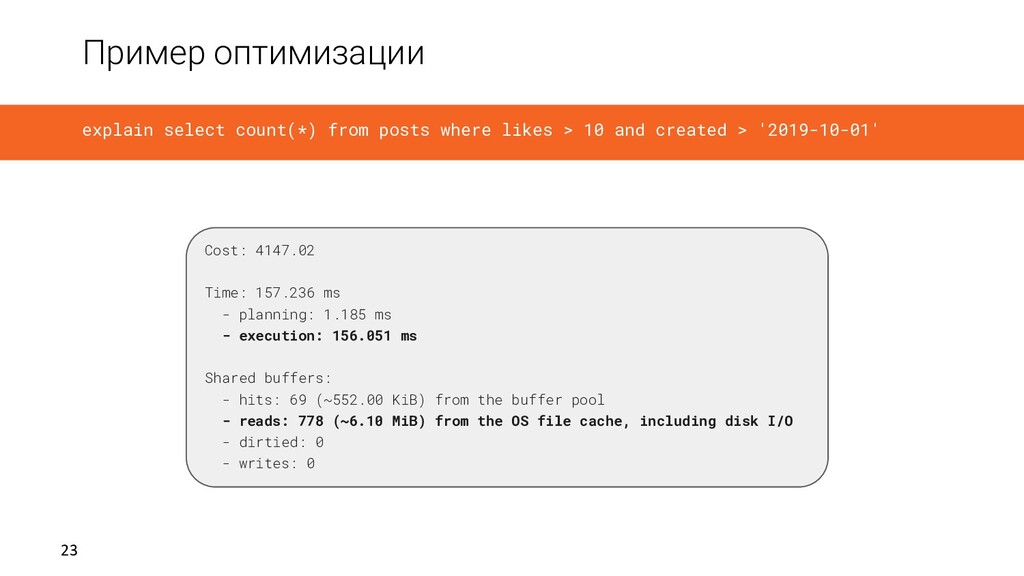
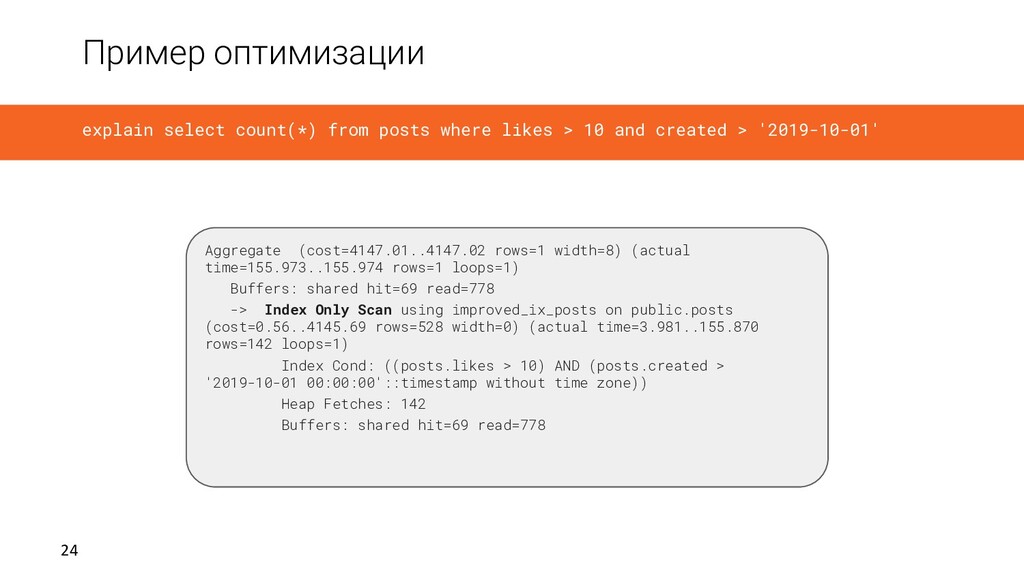
1.185 ms - execution: 156.051 ms Shared buffers: - hits: 69 (~552.00 KiB) from the buffer pool - reads: 778 (~6.10 MiB) from the OS file cache, including disk I/O - dirtied: 0 - writes: 0 explain select count(*) from posts where likes > 10 and created > '2019-10-01'
loops=1) Buffers: shared hit=69 read=778 -> Index Only Scan using improved_ix_posts on public.posts (cost=0.56..4145.69 rows=528 width=0) (actual time=3.981..155.870 rows=142 loops=1) Index Cond: ((posts.likes > 10) AND (posts.created > '2019-10-01 00:00:00'::timestamp without time zone)) Heap Fetches: 142 Buffers: shared hit=69 read=778 explain select count(*) from posts where likes > 10 and created > '2019-10-01'
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![30 Анатолий Станслер [email protected] tg: @anatolystansler https://gitlab.com/postgres-ai/joe https://gitlab.com/postgres-ai/db-lab https://Postgres.ai Спасибо!](https://files.speakerdeck.com/presentations/332b272e85004b8089512afedd0b06ff/slide_29.jpg){kind=link}