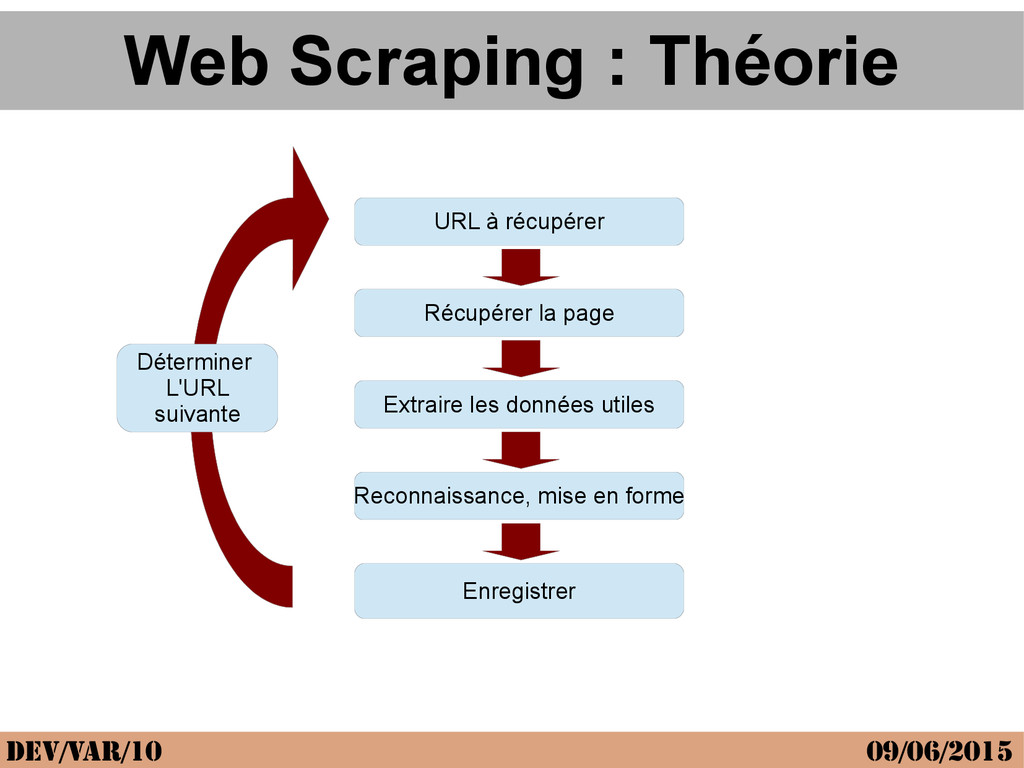
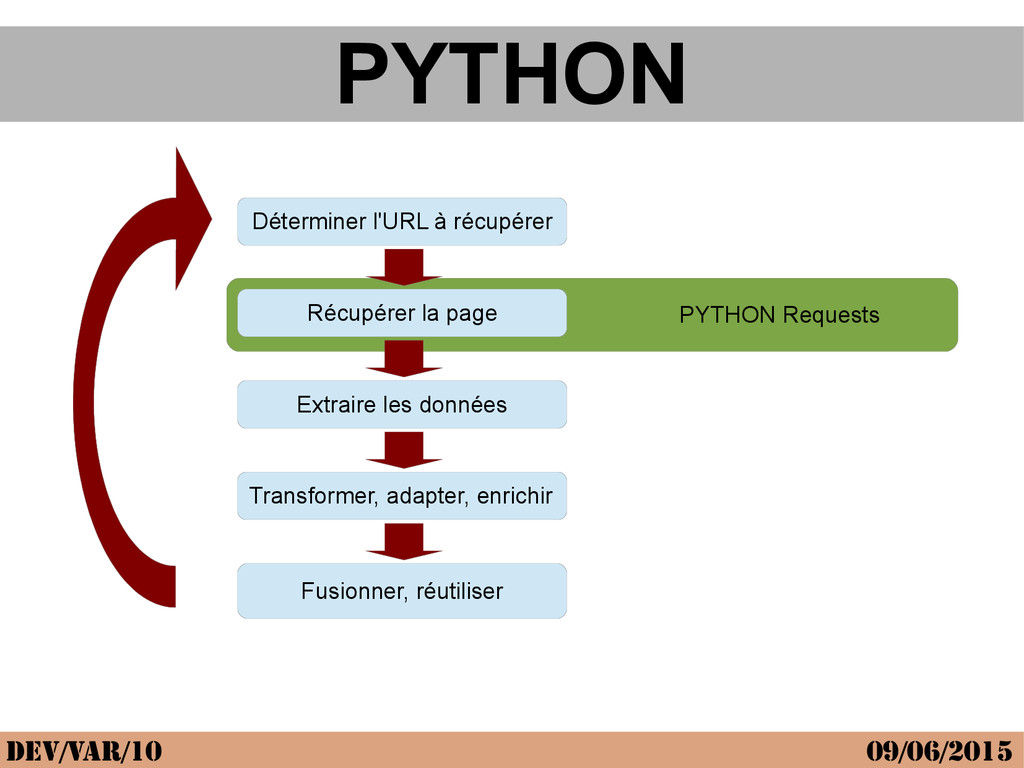
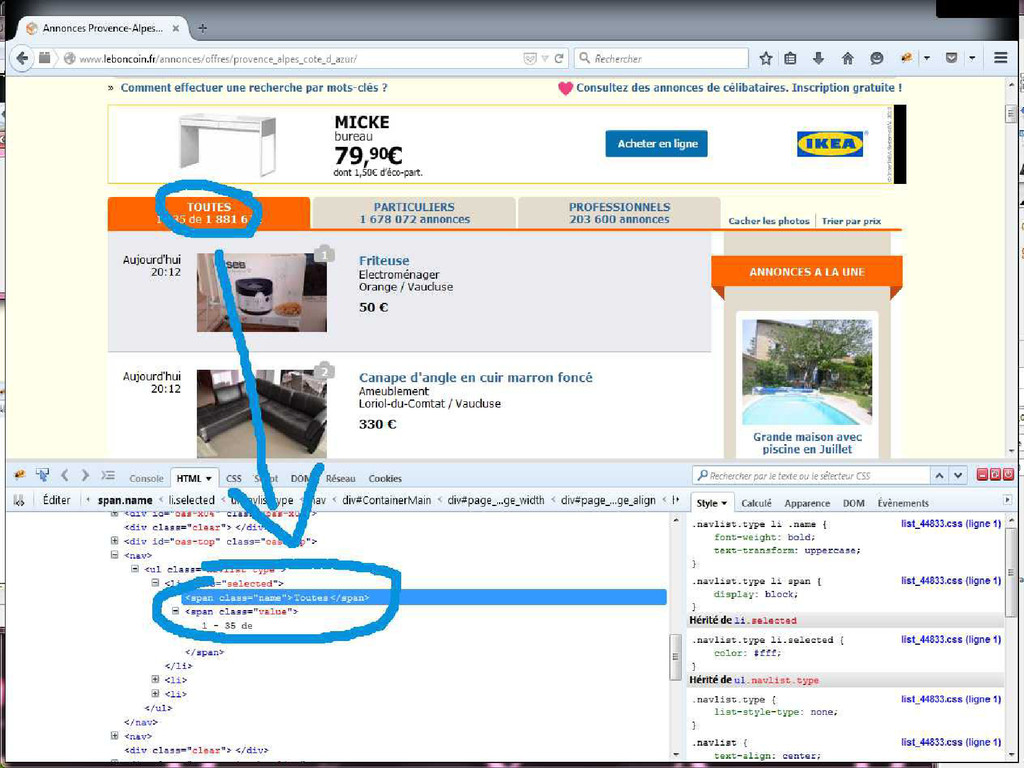
Sur le web on ne croise pas que des internautes, il y a une armée de robots, plus ou moins bien intentionnés. Les robots les plus connus sont les robots d'indexation (googlebot) qu'on appelle des spiders car ce sont des robots qui suivent les liens entre sites comme des araignées. D'autres robots vont un peu plus loin et collectent des données sur le web pour analyse, statistiques, recopie etc ... Le web scraping est justement le fait d'automatiser l'extraction de données en ligne, à les analyser, et les exploiter. Par exemple pour faire des statistiques sur un site de petites annonces, pour générer des news (news.google.fr) etc ... L'intervention propose donc de faire un point sur cette technologie.
Présentation donnée à la Cantine pour /dev/var/10 le 9 juin 2015.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
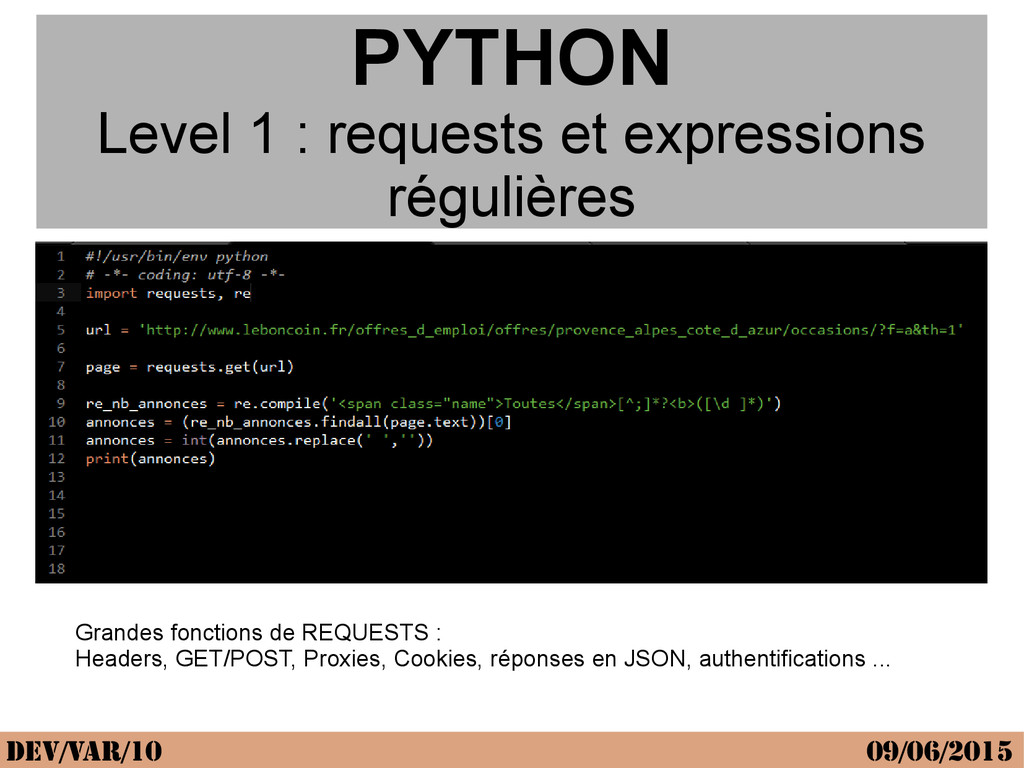{kind=link}
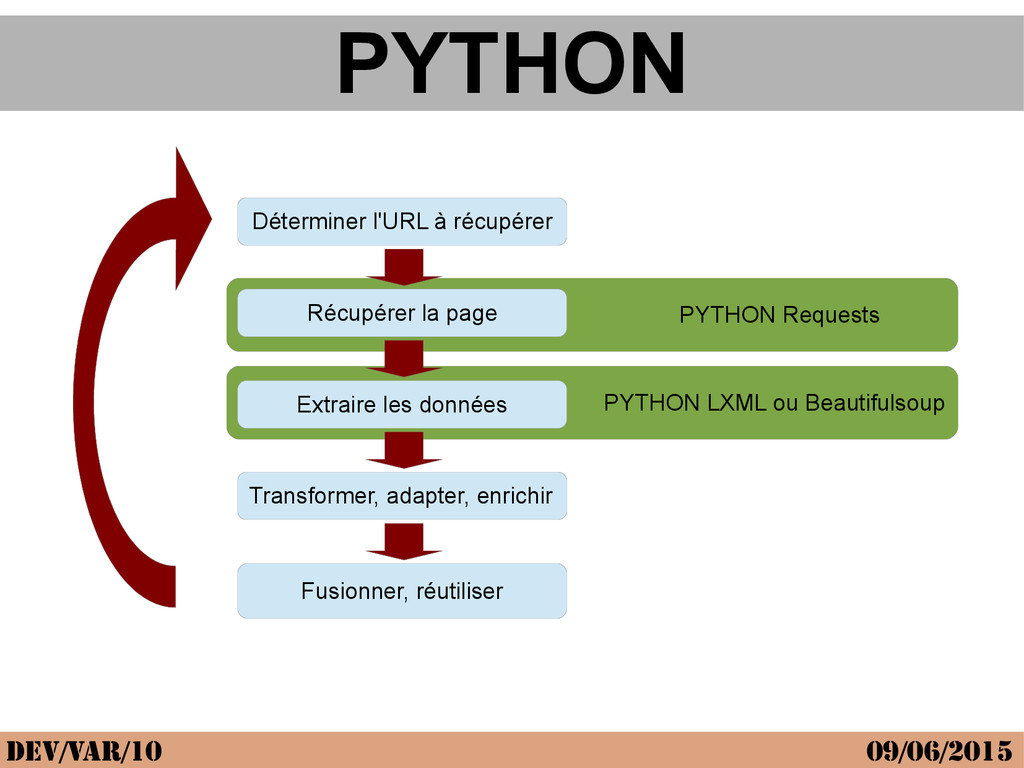{kind=link}
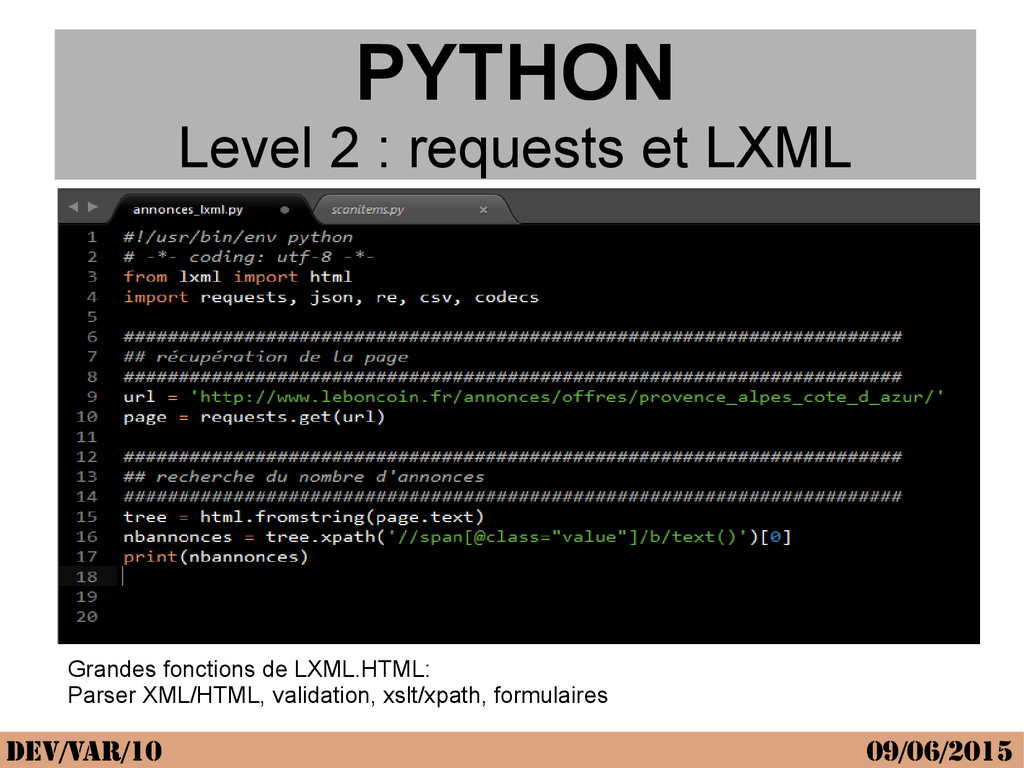{kind=link}
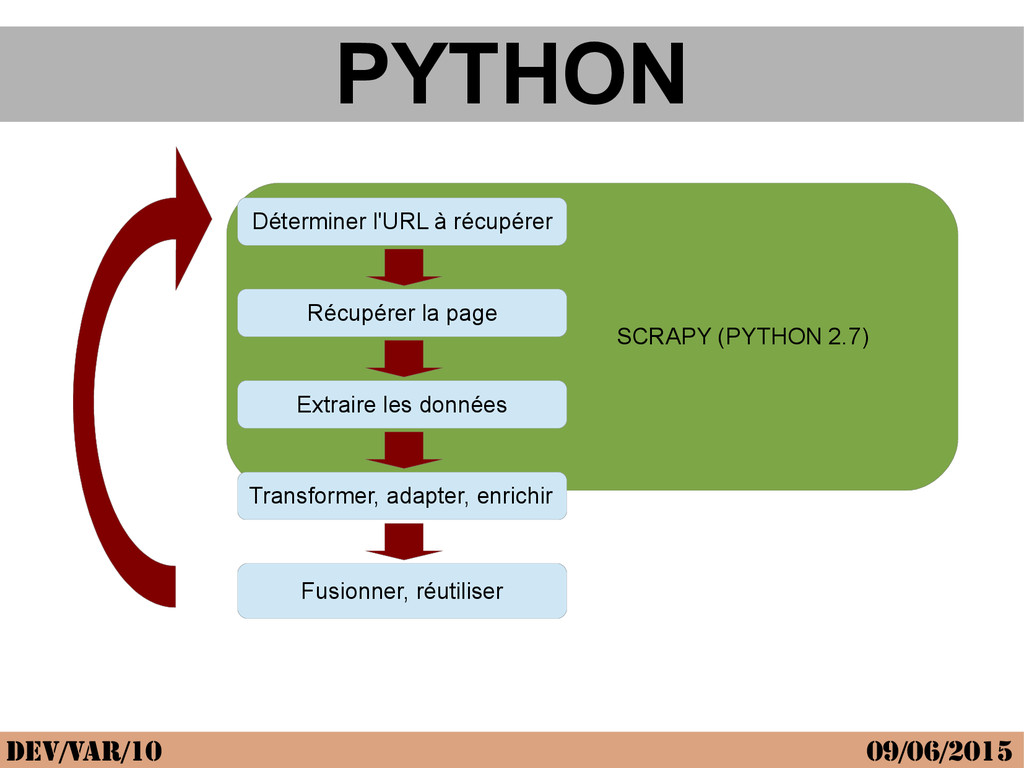{kind=link}
{kind=link}
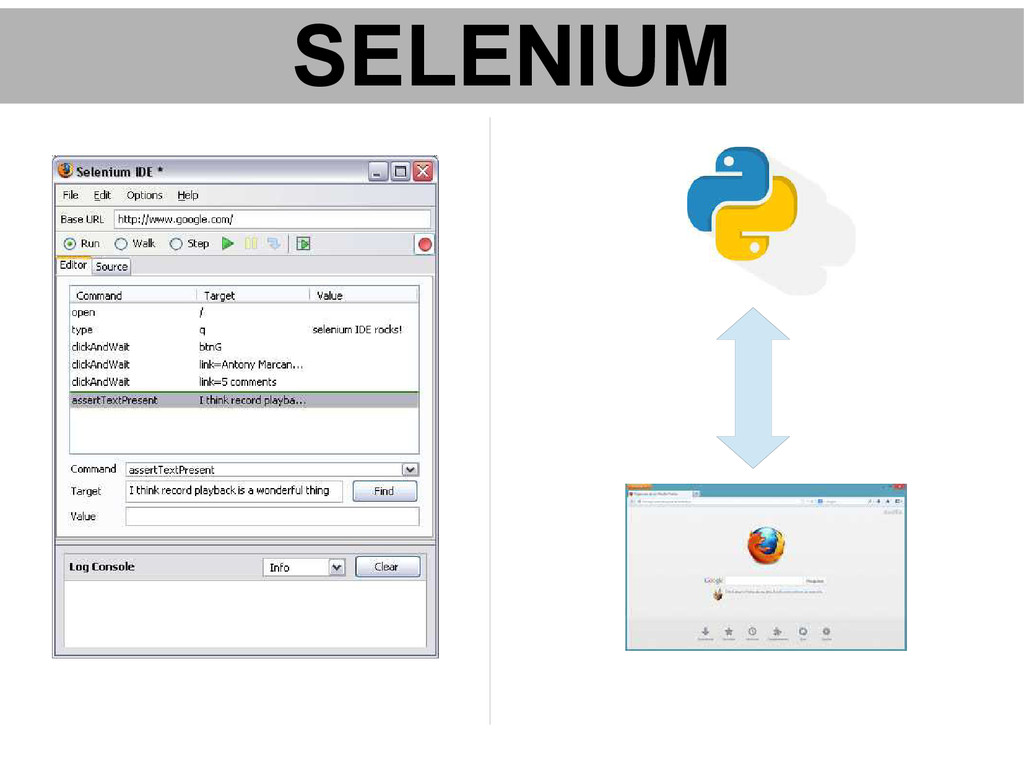{kind=link}
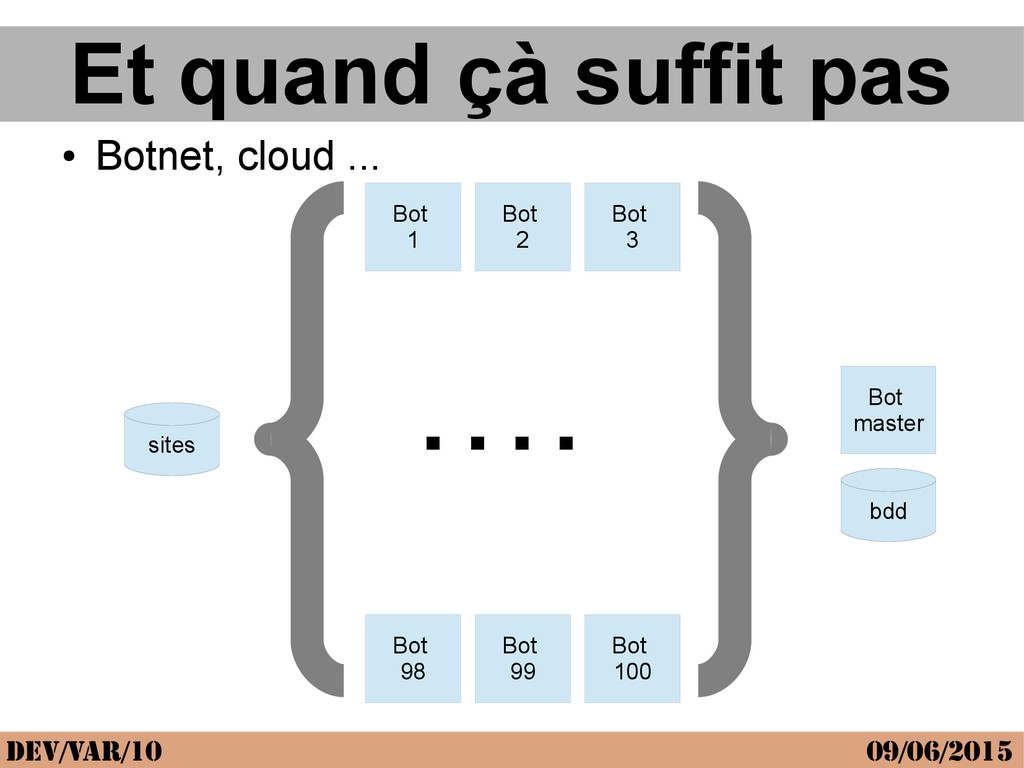{kind=link}
{kind=link}
{kind=link}
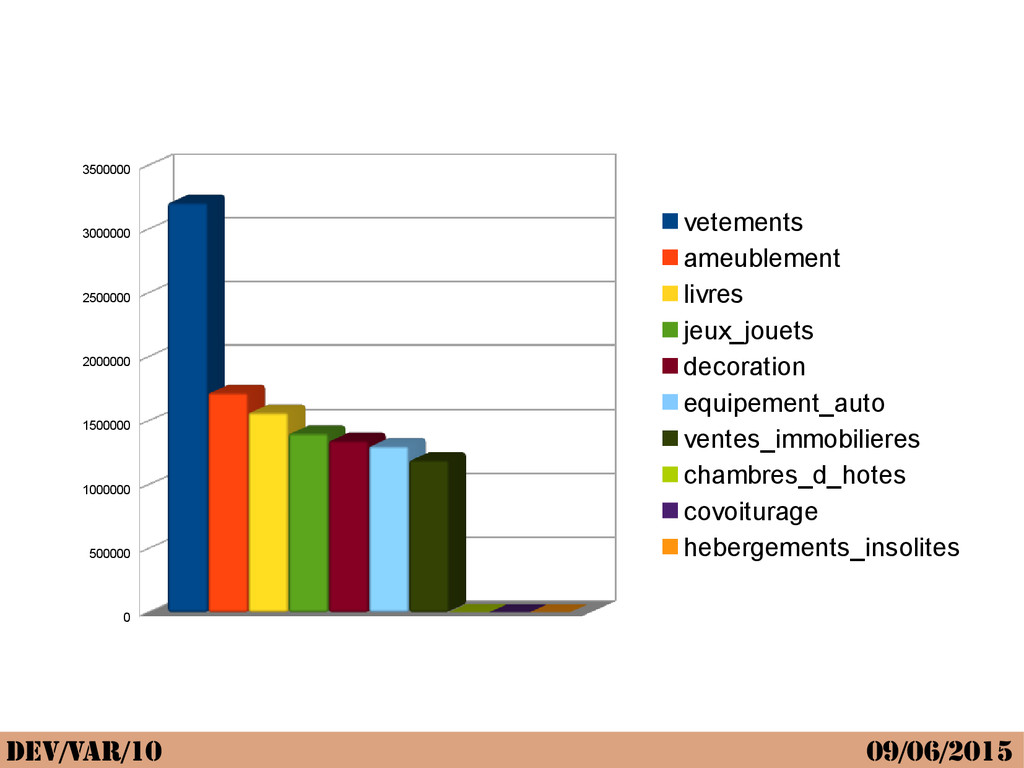{kind=link}
{kind=link}
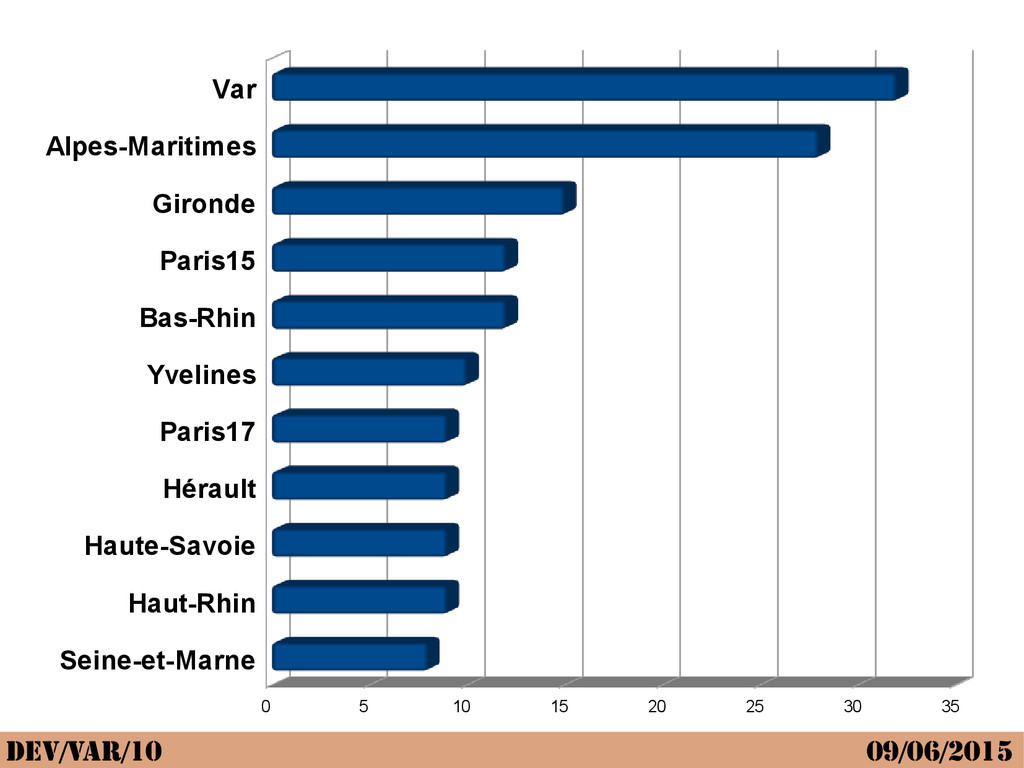{kind=link}
{kind=link}
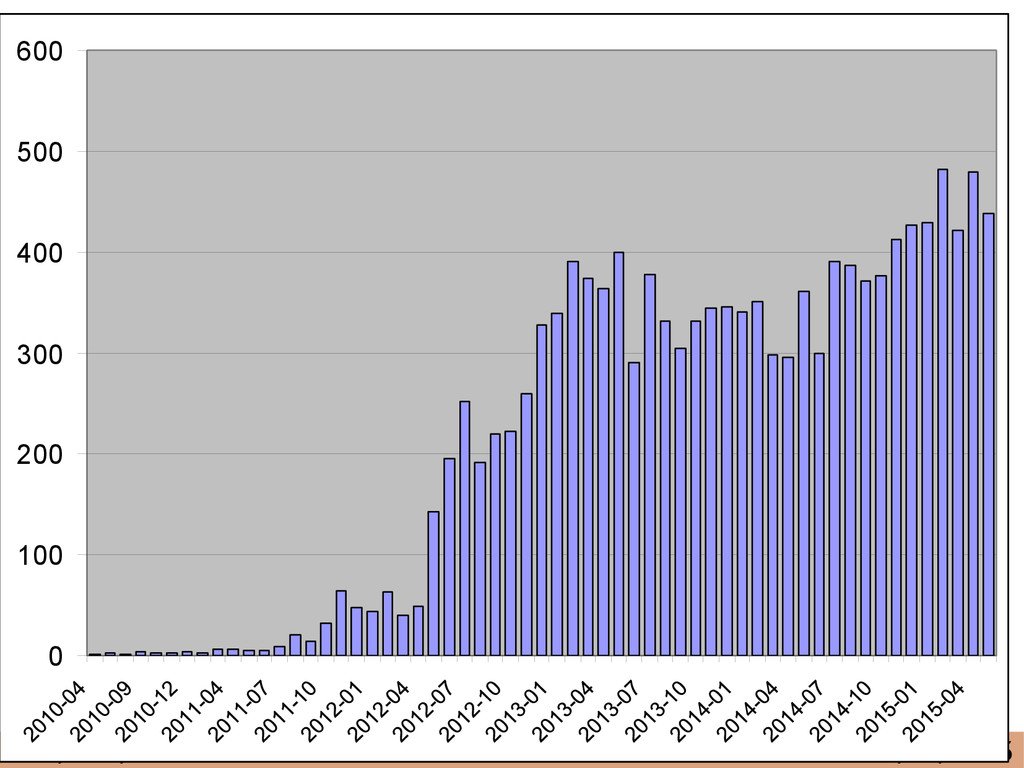{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}