"The devil is in the details" is the way I like to describe how simple yet powerful, Dockerfiles are. There are different ways of accomplishing the same thing, yet few of those routes implement good practices, and we often end up shooting ourselves in the foot.
Dockerfiles are also maintained by both Dev and Ops (shared responsibility == no responsibility!), which leads to constant debate and struggle over tooling, security, release process.
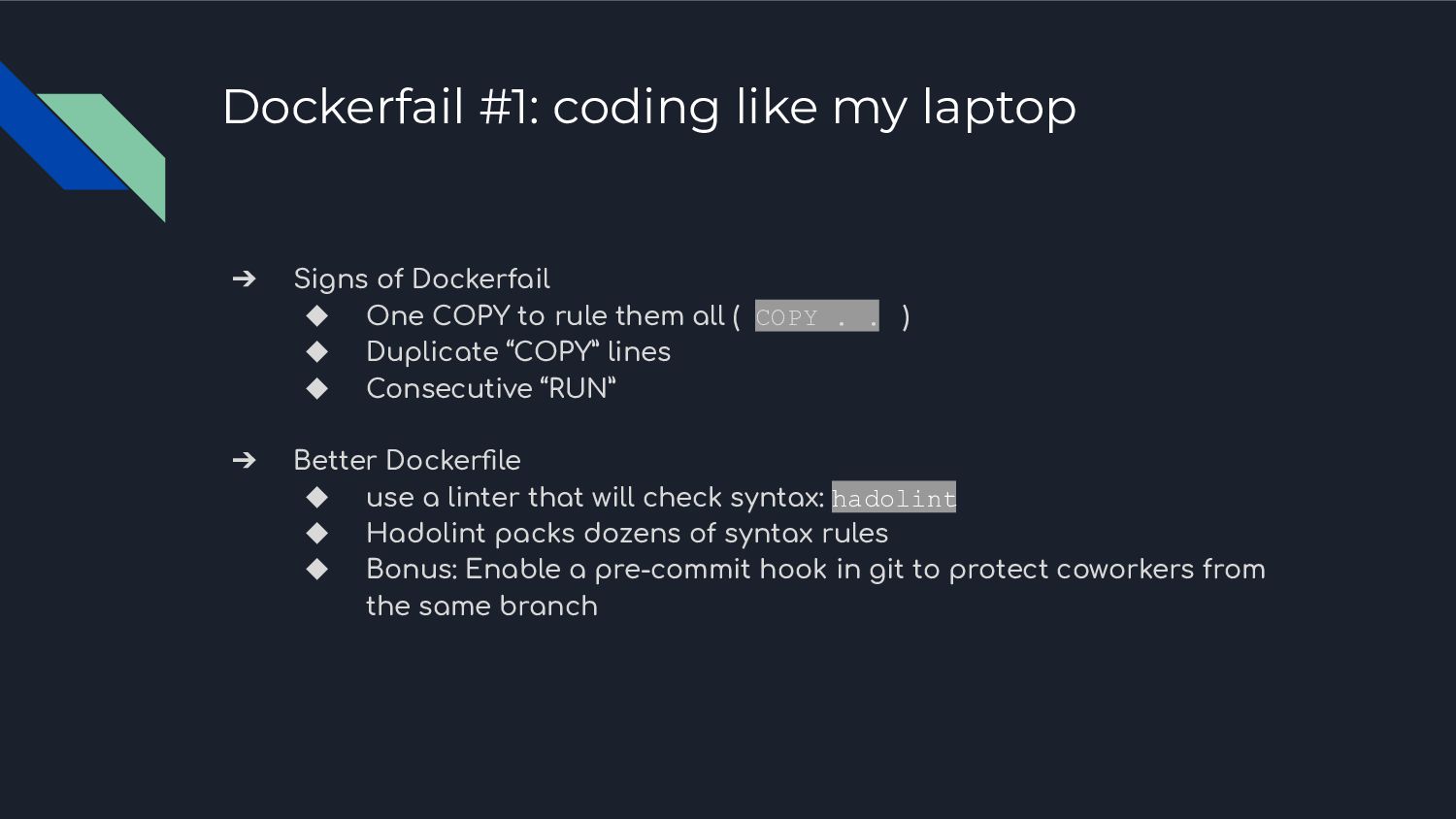
In this session we compiled 10 horror Dockerfiles don'ts, a.k.a “Dockerfails”. To end on an optimist note, we will showcase the maximum good practices in some populare CI/CD tools (github/gitlab/jenkins) with a touch of GitOps.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}