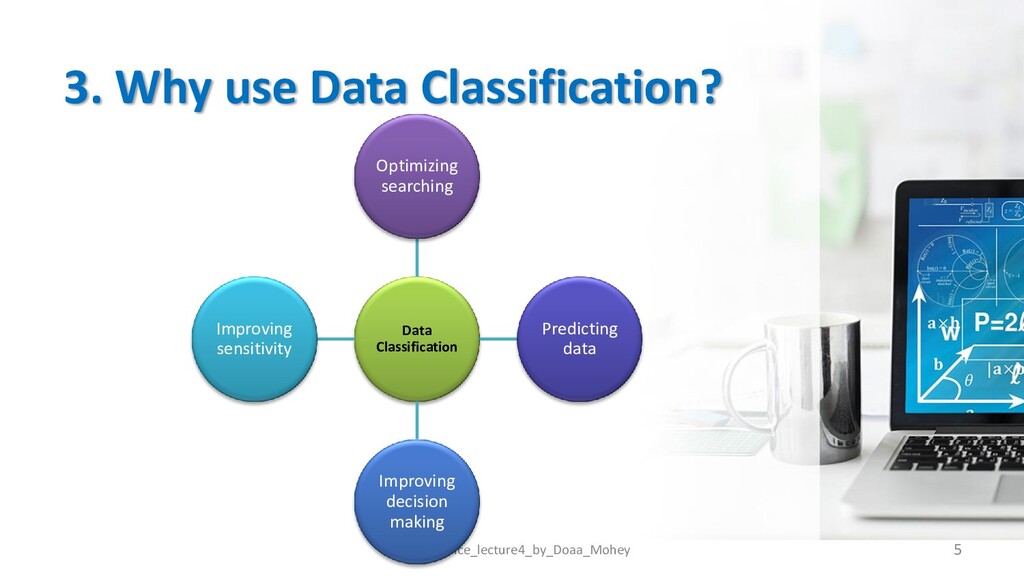
Classification Terminologies ? • Why use Data Classification? • How use Data Classification in real life? • Data Classification Techniques • Data Classification Validation • How choose the suitable data classification technique? • Data Classification Challenges • Data Classification Trends 2 Data_Science_lecture4_by_Doaa_Mohey
“the process of analyzing structured and unstructured data for organizing data into classes based on file type, content, and metadata”. – Classification is a supervised learning. – Uses training sets which has correct answers (class label attributes). – A model is created by running the algorithm on the training data. 3 Data_Science_lecture4_by_Doaa_Mohey
An algorithm that maps the input data to a specific category. A classification model draws some conclusion from the input values given for training. It will predict the class labels/categories for the new data. Data Classification Terminologies: A feature refers to an individual measurable property of a phenomenon being observed. Binary Classification: refers to a task with two possible outcomes. e.g: Gender classification (Male / Female) Multi-class classification: refers to a classification that interprets with more than two classes. Each sample is assigned to one and only one target label. e.g: An animal can be cat or dog but not both at the same time Multi-label classification: refers to a classification task where each sample is mapped to a set of target labels (more than one class). e.g: A news article can be about sports, a person, and location at the same time. Data_Science_lecture4_by_Doaa_Mohey 4
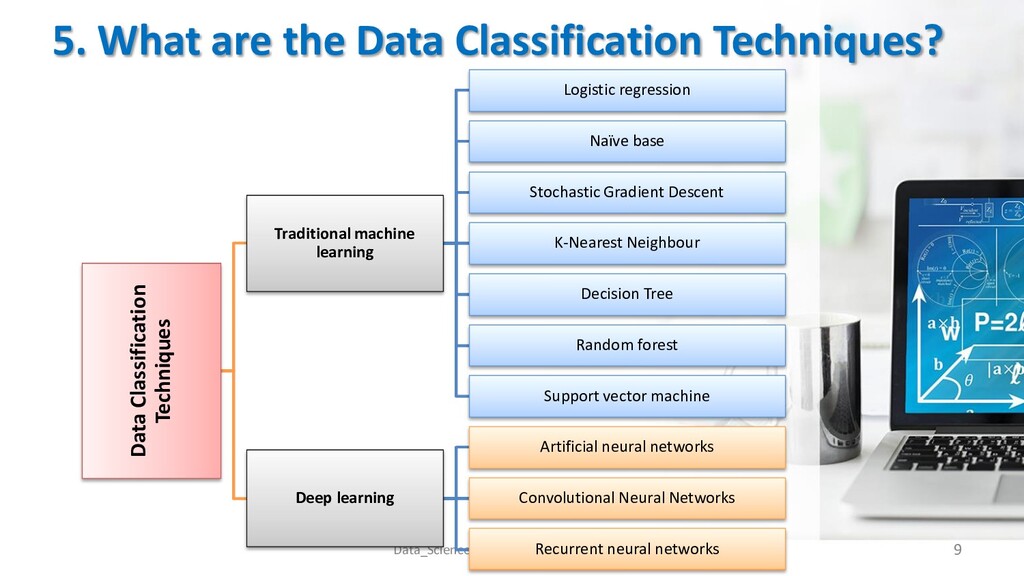
classification requires interpreting in: 1. Input data: • Data Type (image, video, audio, text). • One dimension or multivariate dimensions. • All data the same type or variant types. • Treating missed or outliers data. 2. Choice a suitable Algorithm: • Logistic Regression - Random Forest • Naïve Bayes - Support Vector machine • Stochastic Gradient Descent. • K-Nearest Neighbours. - Deep learning algorithms. • Decision Tree. 6 Data_Science_lecture4_by_Doaa_Mohey
Choice validation algorithm: • Precision, recall, or F-measure (Accuracy) • Loss function (Error function) • Other validations, performance & optimization. • Data Classification applications in real life such as the following: Diseases , Market, or Marks. 4. Choice validation algorithm: • Precision, recall, or F-measure (Accuracy) • Loss function (Error function) • Other validations, performance & optimization. 7 Data_Science_lecture4_by_Doaa_Mohey
Data Classification applications in real life such as the following: – Classify Diseases , – Classify profit of Market, or – Marks. • COVID-19 classification is a hot trend of classification based on image classes and analysis classes. 8 Data_Science_lecture4_by_Doaa_Mohey
(LR) Data_Science_lecture4_by_Doaa_Mohey 10 Definition It refers to the probabilities description of the possible output of single trial based on using Logistic Function Advantages It is a powerful of meaning influence of several variables Disadvantages It works only when the predicted variable is binary, assumes all predictors are independent of each other, and It assumes data is free of missing values
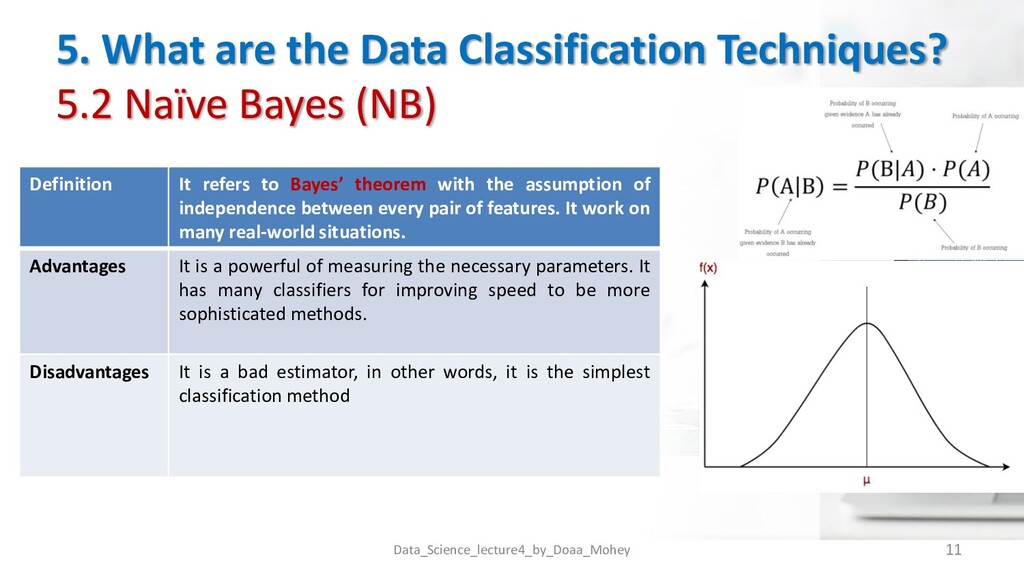
(NB) Data_Science_lecture4_by_Doaa_Mohey 11 Definition It refers to Bayes’ theorem with the assumption of independence between every pair of features. It work on many real-world situations. Advantages It is a powerful of measuring the necessary parameters. It has many classifiers for improving speed to be more sophisticated methods. Disadvantages It is a bad estimator, in other words, it is the simplest classification method
Descent (SGD) Data_Science_lecture4_by_Doaa_Mohey 12 Definition It refers to a simple and very efficient approach to fit linear models. It is particularly useful when the number of samples is very large. It supports different loss functions and penalties for classification. Advantages It is efficiency and easy to implement. Disadvantages It requires being based on a number of hyper-parameters. It is a powerful and sensitive to feature scaling.
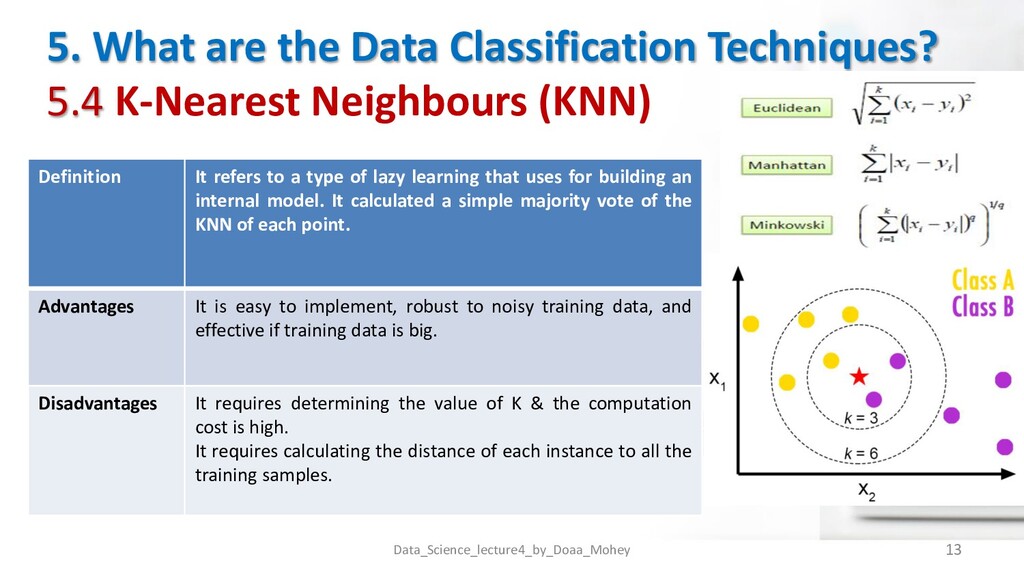
(KNN) Data_Science_lecture4_by_Doaa_Mohey 13 Definition It refers to a type of lazy learning that uses for building an internal model. It calculated a simple majority vote of the KNN of each point. Advantages It is easy to implement, robust to noisy training data, and effective if training data is big. Disadvantages It requires determining the value of K & the computation cost is high. It requires calculating the distance of each instance to all the training samples.
(DT) Data_Science_lecture4_by_Doaa_Mohey 14 Definition It refers to interpret data attributes based on classes, decision tree. It produces a sequence of rules that can be used to classify the data. Advantages It is simple to understand and easy to visualize. It needs making categorization data. Disadvantages It constructs complex trees & decision trees to be unstable due to small data variations.
(RF) Data_Science_lecture4_by_Doaa_Mohey 15 Definition It refers to a meta-estimator that fits a number of decision trees on various sub-samples of datasets. It uses for the average evaluation for enhancing the predictive accuracy model and controls over-fitting. Advantages It is powerful of reduction in over-fitting & random forest classifier. It is more accurate than decision trees in most cases. Disadvantages It is slow real time prediction. It is hard to implement and complex technique.
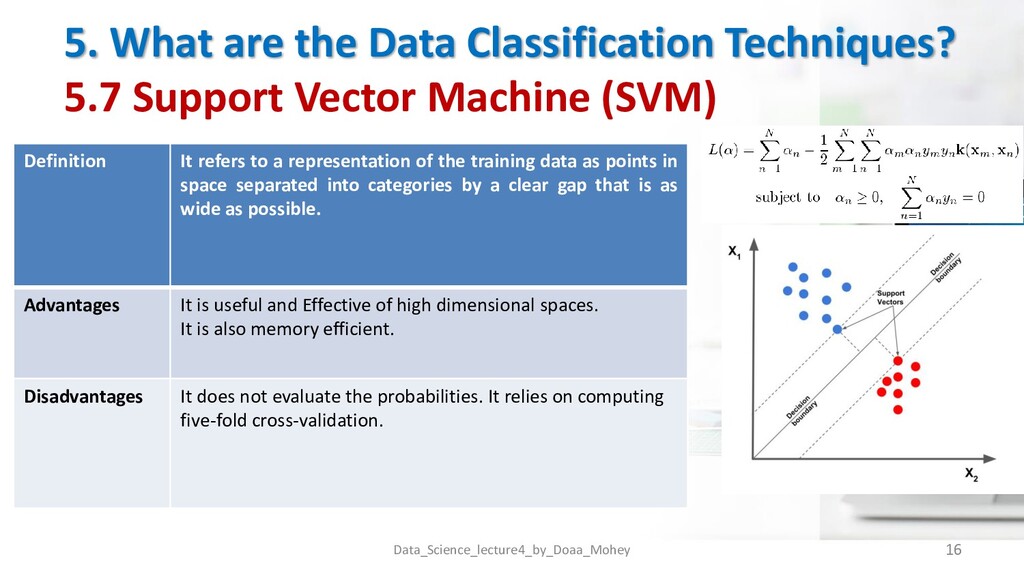
Machine (SVM) Data_Science_lecture4_by_Doaa_Mohey 16 Definition It refers to a representation of the training data as points in space separated into categories by a clear gap that is as wide as possible. Advantages It is useful and Effective of high dimensional spaces. It is also memory efficient. Disadvantages It does not evaluate the probabilities. It relies on computing five-fold cross-validation.
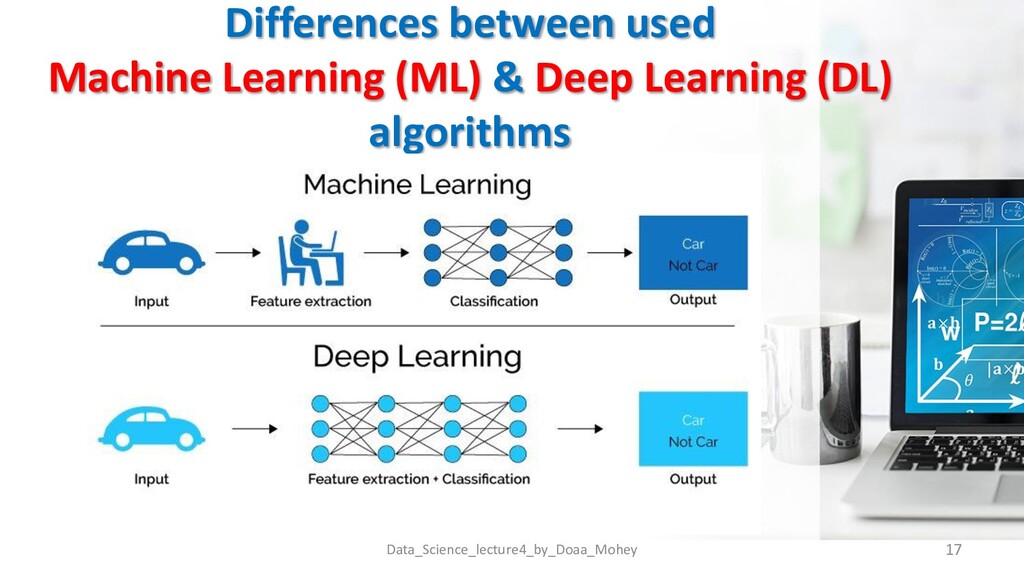
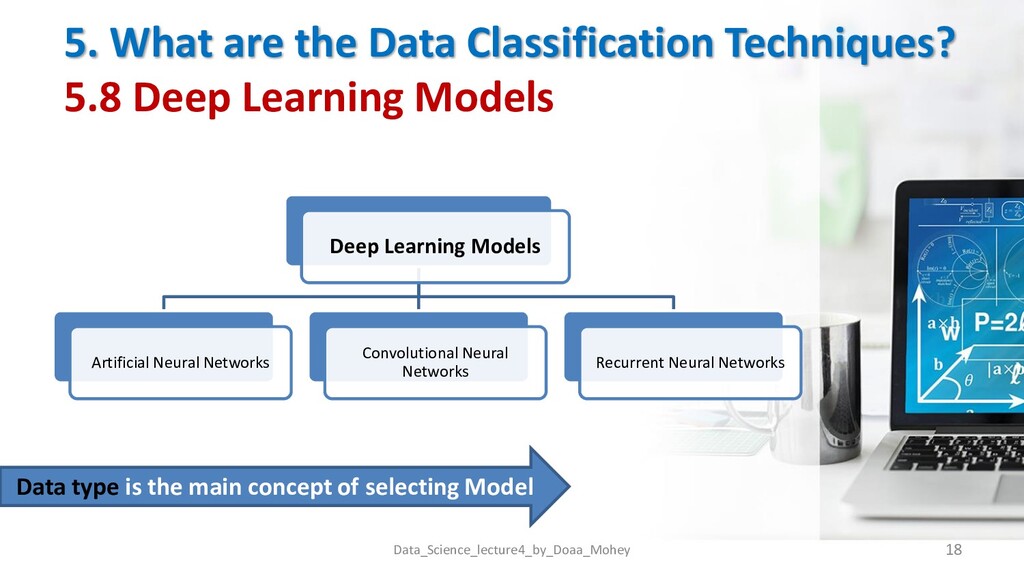
Models Data_Science_lecture4_by_Doaa_Mohey 18 Deep Learning Models Artificial Neural Networks Convolutional Neural Networks Recurrent Neural Networks Data type is the main concept of selecting Model
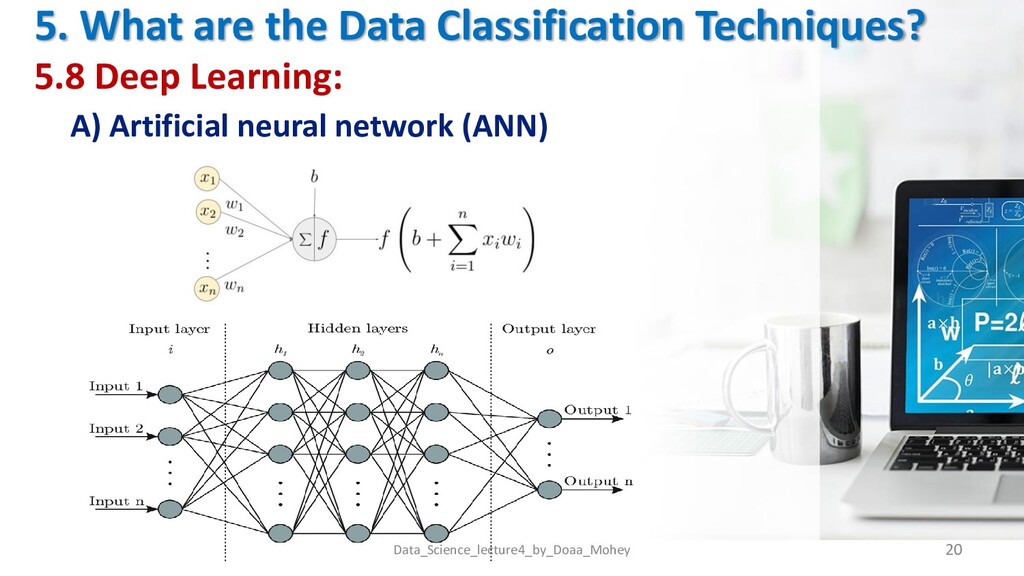
A) Artificial neural network (ANN) Data_Science_lecture4_by_Doaa_Mohey 19 Definition is the piece of a computing system designed to simulate the way the human brain analyzes and processes information. ANNs have self-learning capabilities that enable them to produce better results as more data becomes available. Advantages • Store information on the entire network. • The ability to work with insufficient knowledge • Good falt tolerance: • Distributed memory • Gradual Corruption • Ability to train machine • The ability of parallel processing: Disadvantages • Hardware Dependence • Unexplained functioning of the network • Assurance of proper network structure • The difficulty of showing the problem to the network • The duration of the network is unknown
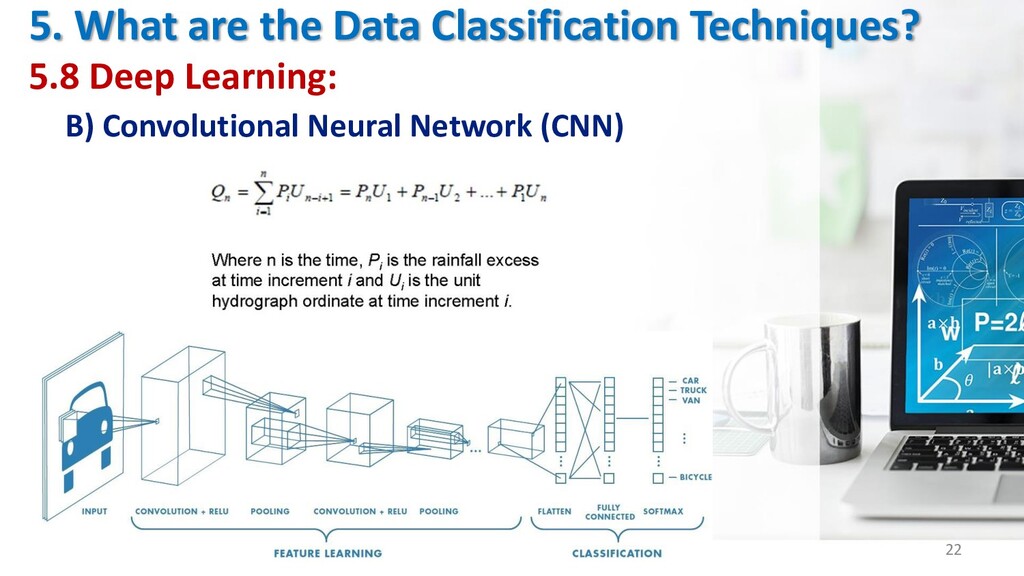
B) Convolutional Neural Network (CNN) Data_Science_lecture4_by_Doaa_Mohey 21 Definition It is a Neural Network that uses for many targets such as data classification many dataset that uses for training purposes, and predicts the possible future labels to be assigned. The CNN architecture consists of several kinds of layers; Convolutional layer, pooling layer, fully connected input layer, fully connected layer and fully connected output layer. Advantages Powerful and Efficacy Disadvantages Over-fitting and Adversarial examples
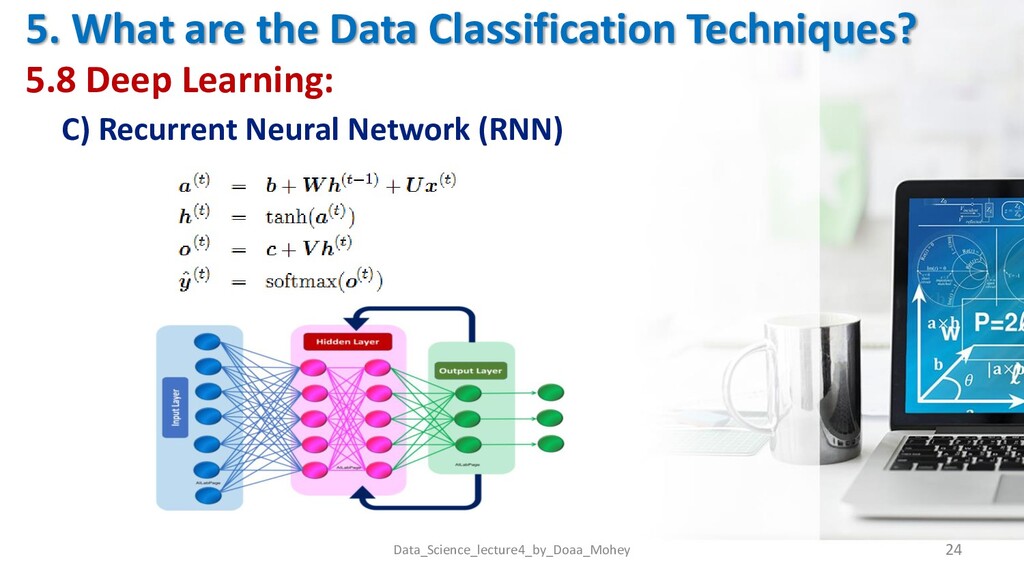
C) Recurrent Neural Network (RNN) Data_Science_lecture4_by_Doaa_Mohey 23 Definition Artificial Neural Network is capable of learning any nonlinear function. Hence, these networks are popularly known as Universal Function Approximates. ANNs have the capacity to learn weights that map any input to the output. Advantages • Model sequential data where each sample can be assumed to be dependent on historical ones is one of the advantage. • Used with convolution layers to extend the pixel effectiveness. Disadvantages • Gradient vanishing and exploding problems. • Training recurrent neural nets could be a difficult task • Difficult to process long sequential data using ReLU as an activation function.
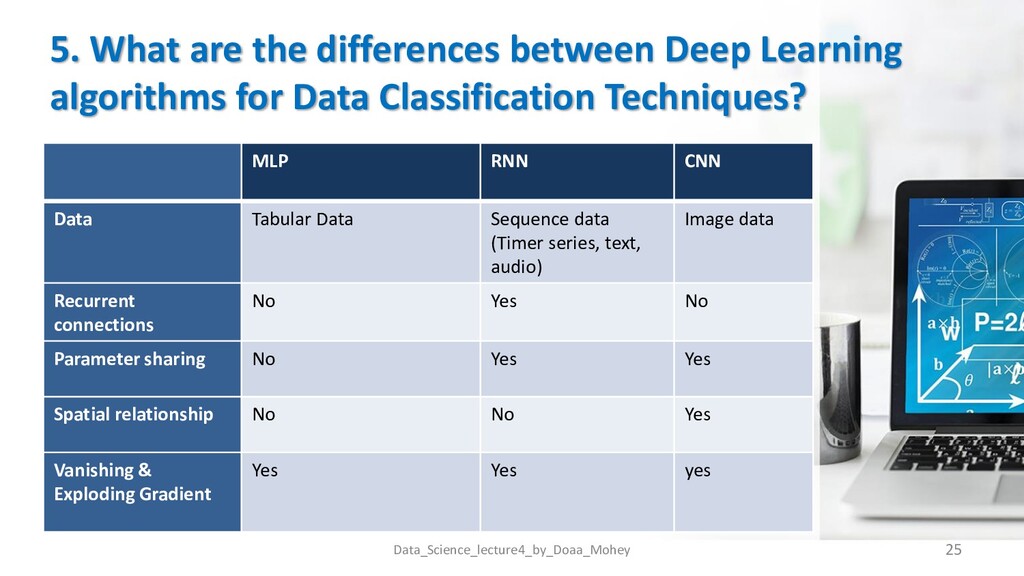
Data Classification Techniques? Data_Science_lecture4_by_Doaa_Mohey 25 MLP RNN CNN Data Tabular Data Sequence data (Timer series, text, audio) Image data Recurrent connections No Yes No Parameter sharing No Yes Yes Spatial relationship No No Yes Vanishing & Exploding Gradient Yes Yes yes
True Negative) / Total Population • Accuracy is a ratio of correctly predicted observation to the total observations. • Accuracy is the most intuitive performance measure. • True Positive (TP): The number of correct predictions that the occurrence is positive. • True Negative (TN): The number of correct predictions that the occurrence is negative. F1-Score: (2 x Precision x Recall) / (Precision + Recall) • F1-Score is the weighted average of Precision and Recall used in all types of classification algorithms. Therefore, this score takes both false positives and false negatives into account. F1-Score is usually more useful than accuracy, especially if you have an uneven class distribution. • Precision: When a positive value is predicted, how often is the prediction correct? • Recall: When the actual value is positive, how often is the prediction correct? Data_Science_lecture4_by_Doaa_Mohey 26
Data_Science_lecture4_by_Doaa_Mohey 28 Most researches recommend Machine learning (ML) Algorithm for classification: Random Forest (RF) is one of the most effective and versatile machine learning (ML) algorithm for wide variety of classification and regression tasks. It is hard to construct a bad random forest. Most researches recommend Deep Learning (DL) Algorithm for classification: Convolutional Neural Networks (CNNs) is the most popular neural network model that almost uses for image classifications. The big idea behind CNNs is that a local understanding of an image is good enough.
data: 1. Missing data or outliers in data Resources. 2. Hardness of learning from data. 3. No standardization of classification for various domains. 4. Privilege Management 5. Maintain Compliance Data_Science_lecture4_by_Doaa_Mohey 29
various data type in various domains is a research trend. It requires making motivations for improving classification with high accuracy and best performance time. The optimization dimension becomes important in recent researches. “COVID-19 classification domain” is a hottest domain for making a research and achieving the best results for classifications. Data_Science_lecture4_by_Doaa_Mohey 30
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}