Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
KubernetesでGPUを使おう
Search
Sponsored
·
SiteGround - Reliable hosting with speed, security, and support you can count on.
→
Dodai-Dodai
February 27, 2025
Programming
480
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
KubernetesでGPUを使おう
大阪工業大学 ネットワークデザイン学科 LT大会 2025v1 で発表した資料です
Dodai-Dodai
February 27, 2025
Other Decks in Programming
See All in Programming
ECSアプリログをFireLensでコスト削減しようとしたけど諦めた話 in Fargate×Node.js
akihisaikeda
2
4.2k
キャリア迷子上等 ─ "ない道"は自分で作ればいい
16bitidol
3
2.1k
3Dシーンの圧縮
fadis
1
770
タクシーアプリ『GO』の バックエンド開発のおける AI利活用と若者のすべて
pyama86
3
2k
Vue × Nuxt × Oxc どこまで使える?実運用の現在地
andpad
0
250
Inside Stream API
skrb
1
710
dRuby over BLE
makicamel
2
340
Javaの型とAI時代に型が大事な理由 / java types and type in AI era
kishida
2
130
The NotImplementedError Problem in Ruby
koic
1
780
気圧・高度・GPSを記録&可視化するアプリ「Koudo」を作った話
hjmkth
1
240
軽量Java基盤の設計 DIコンテナに頼らない、長期保守と1秒起動の実現 JJUG CCC 2026 Spring
macha64
0
510
AIだと陥りがちなJakarta EE最新技術への移行時の落とし穴と解決策
tnagao7
0
110
Featured
See All Featured
Mozcon NYC 2025: Stop Losing SEO Traffic
samtorres
1
250
Rebuilding a faster, lazier Slack
samanthasiow
85
9.5k
The AI Search Optimization Roadmap by Aleyda Solis
aleyda
1
5.9k
Lightning Talk: Beautiful Slides for Beginners
inesmontani
PRO
2
580
Efficient Content Optimization with Google Search Console & Apps Script
katarinadahlin
PRO
1
620
The Illustrated Guide to Node.js - THAT Conference 2024
reverentgeek
1
380
Joys of Absence: A Defence of Solitary Play
codingconduct
1
390
技術選定の審美眼(2025年版) / Understanding the Spiral of Technologies 2025 edition
twada
PRO
118
120k
How to Talk to Developers About Accessibility
jct
2
230
Java REST API Framework Comparison - PWX 2021
mraible
34
9.4k
The Success of Rails: Ensuring Growth for the Next 100 Years
eileencodes
47
8.2k
The Director’s Chair: Orchestrating AI for Truly Effective Learning
tmiket
1
190
Transcript
KubernetesでGPUを使おう ⼤阪⼯業⼤学 Dodai-Dodai
⾃⼰紹介 • Dodai-Dodai • ⼤阪⼯業⼤学 情報科学部 ネットワークデザイン学科4年 • 通信⽅式研究室 •
ネットワークやサーバーをいじってます • JANOG 55 NOC運営/ICTSC2024 運営
モチベーション 格安で譲ってもらったゲーミングPC を⾃宅鯖として利⽤している • スペック: I7-12700kf, RAM 64GM, RTX3060 12GB
• 運⽤: Proxmox(KVM)で仮想マシンを複 数実⾏ • GPUが勿体無い!! • せっかくだからLLM(⼤規模⾔語モ デル)でも回してみよう!! • どうせなら複数タスクで扱えるよう にしたい!!
仮想マシンでGPUを使う… • GeforceシリーズのGPUは、複数の仮想マシンで共有できな い。 • 1台のVMにしかパススルーできないため、リソースが固定される • これでは効率的にGPUを利⽤できない • NVIDIA
Container Toolkit & k8s-device-plugin がある • コンテナ単位でGPUを利⽤可能にするツール • DockerなどからGPUを利⽤可能となる • 加えてKubernetesを使えば、GPUを効率的に分配できる!
Kubernetesって? • 軽量な仮想マシン(コンテナ)を操作す るためのツール • コンテナの起動や停⽌、負荷分散や障 害からの復旧を⾃動で⾏う
環境構築 • Kubernetesには様々なディストリビューションがある • Kubeadm • Minikube • MicroK8s •
などなど 基本的にはこれらを構築した上で NVIDIAのGPUを利⽤する設定を⾏う
環境構築 • NVIDIA Driver ‧ Nvidia Container Toolkitのinstall • Docker
runでGPUが 認識されているか確 かめる
Kubernetes(Minikube)の起動
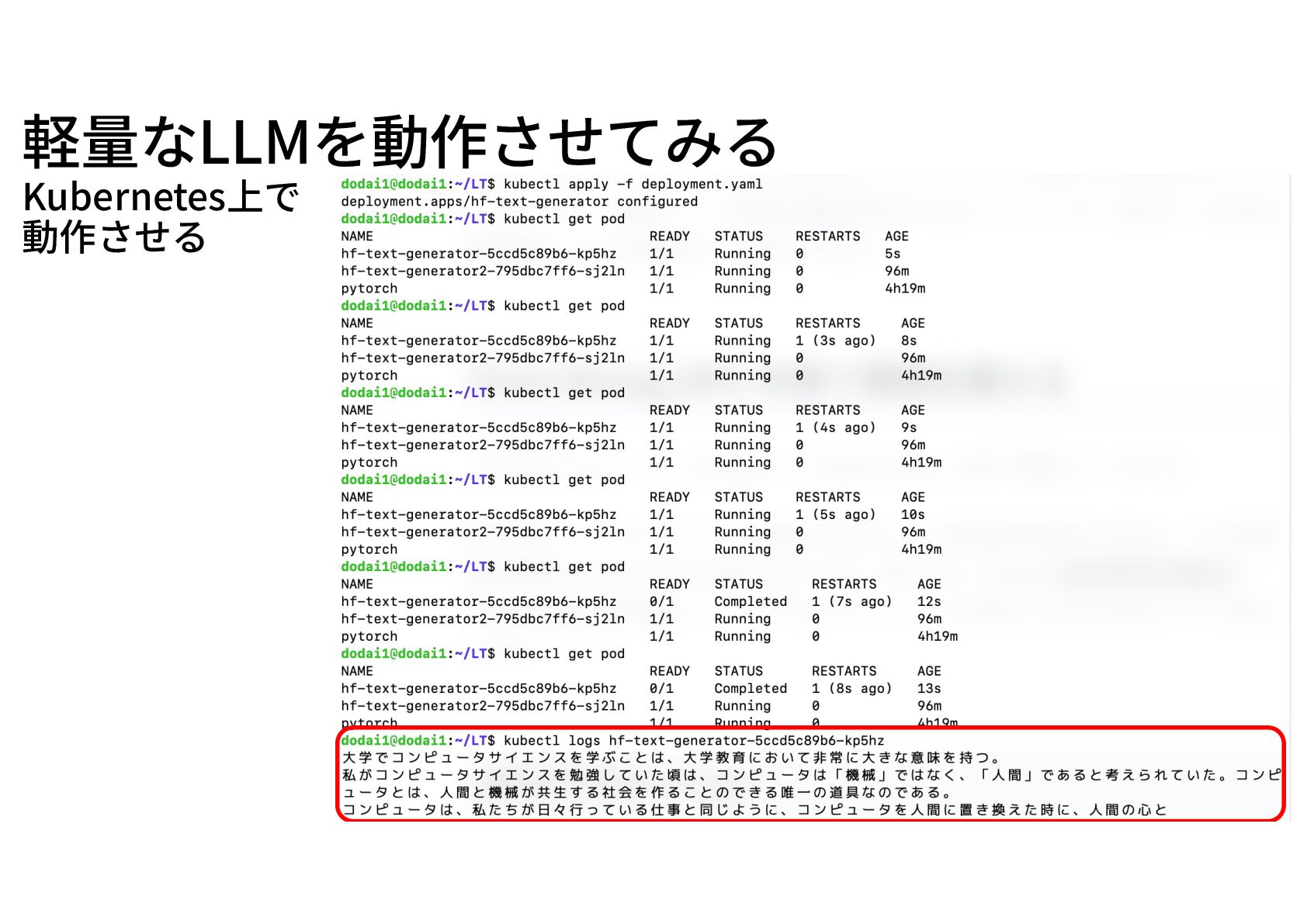
軽量なLLMを動作させてみる 軽量なLLMであるcyberagent/open-calm-smallのサンプルコードを⽤意 import torch from transformers import AutoModelForCausalLM, AutoTokenizer model_name
= "cyberagent/open-calm-small" # モデルとトークナイザーのロード model = AutoModelForCausalLM.from_pretrained(model_name, device_map="auto", torch_dtype=torch.float16) tokenizer = AutoTokenizer.from_pretrained(model_name) # 入力データ inputs = tokenizer("大学でコンピュータサイエンスを学ぶことは", return_tensors="pt").to(model.device) # テキスト生成 with torch.no_grad(): tokens = model.generate( **inputs, max_new_tokens=64, do_sample=True, temperature=0.7, top_p=0.9, repetition_penalty=1.05, pad_token_id=tokenizer.pad_token_id, ) # 出力のデコード output = tokenizer.decode(tokens[0], skip_special_tokens=True) print(output)
軽量なLLMを動作させてみる サンプルコードが動くDockerImageを作るDockerfile # ベースイメージ FROM python:3.10 # 作業ディレクトリの作成 WORKDIR /app
# 必要なパッケージのインストール RUN apt-get update && apt-get install -y git && rm -rf /var/lib/apt/lists/* # Pythonライブラリのインストール RUN pip install --no-cache-dir torch transformers accelerate # モデルを事前にダウンロード(キャッシュ用) RUN python -c "from transformers import AutoModelForCausalLM, AutoTokenizer; ¥ AutoModelForCausalLM.from_pretrained('cyberagent/open-calm-small'); ¥ AutoTokenizer.from_pretrained('cyberagent/open-calm-small')" # スクリプトのコピー COPY generate.py /app/generate.py # スクリプトの実行 CMD ["python", "generate.py"] $ docker build -t hf-text-generator . # Docker Imageをビルド
軽量なLLMを動作させてみる DockerfileをKubernetes上で動作させるためのdeployment.yaml apiVersion: apps/v1 kind: Deployment metadata: name: hf-text-generator spec:
replicas: 1 selector: matchLabels: app: hf-text-generator template: metadata: labels: app: hf-text-generator spec: containers: - name: hf-text-generator image: hf-text-generator:latest resources: limits: nvidia.com/gpu: 1 memory: "4Gi" requests: nvidia.com/gpu: 1 imagePullPolicy: IfNotPresent
軽量なLLMを動作させてみる Kubernetes上で 動作させる
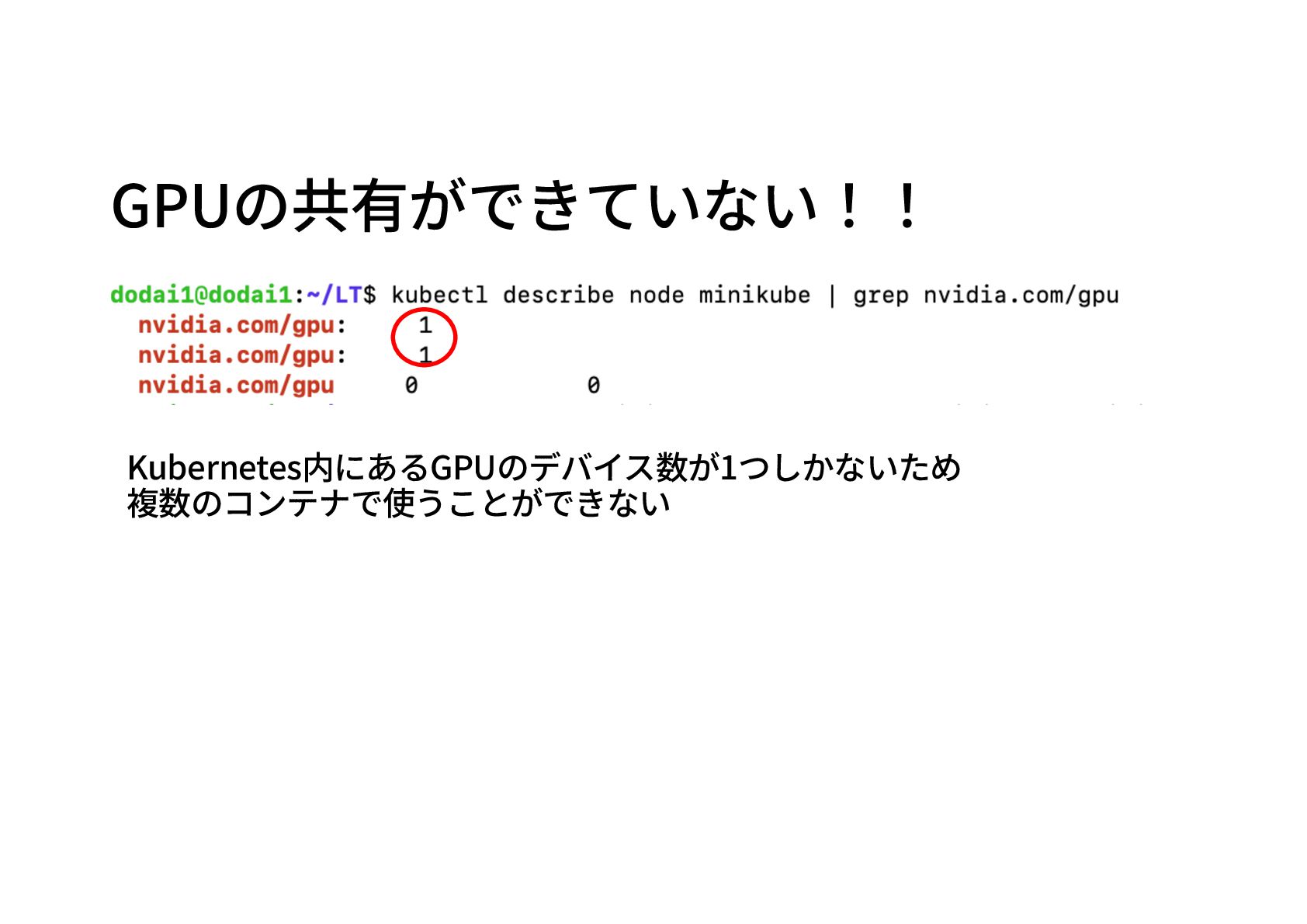
GPUの共有ができていない!! Kubernetes内にあるGPUのデバイス数が1つしかないため 複数のコンテナで使うことができない
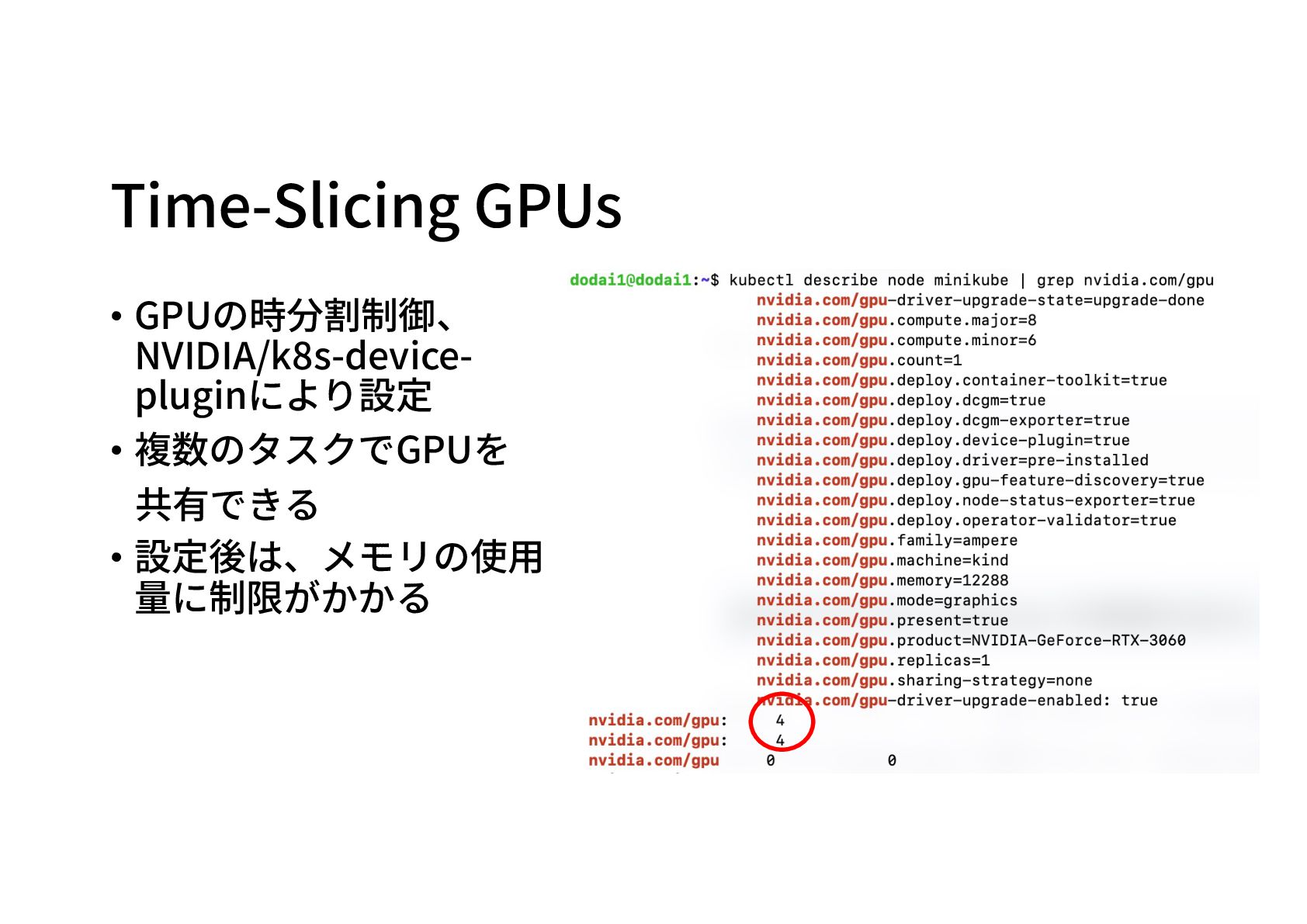
Time-Slicing GPUs • GPUの時分割制御、 NVIDIA/k8s-device-pluginにより設定 • これにより複数のタスクでGPUを共有できるようになる apiVersion: v1 kind:
ConfigMap metadata: name: time-slicing-config-all data: any: |- version: v1 flags: migStrategy: none sharing: timeSlicing: resources: - name: nvidia.com/gpu replicas: 4 # 4つに分割
Time-Slicing GPUs • GPUの時分割制御、 NVIDIA/k8s-device- pluginにより設定 • 複数のタスクでGPUを 共有できる •
設定後は、メモリの使⽤ 量に制限がかかる
感想 • 業務⽤の⾼いGPUを調達することなく、GPUを複数タスクで共 有できる環境ができたのはよかったところ • (当然ながら)分割によりVRAMの制限が厳しくなるのでワーク ロードの向き不向きが出てしまうのは⽋点 • 結局、複数台のGPUがあることがベストプラクティスかも…
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}