Faster than the speed of print: Reconciling ‘big data’ social media analysis and academic scholarship. First Monday, 18(10). Abgerufen von http://firstmonday.org/ojs/index.php/fm/article/view/4879 De Choudhury, M., Lin, Y. R., Sundaram, H., Candan, K. S., Xie, L., & Kelliher, A. (2010). How does the data sampling strategy impact the discovery of information diffusion in social media. In Proceedings of the 4th International AAAI Conference on Weblogs and Social Media (S. 34–41). Abgerufen von http://www.aaai.org/ocs/index.php/ICWSM/ICWSM10/paper/viewFile/1521/1832 Gehrau / Fretwurst / Krause (2005) (Hrsg.) Auswahlverfahren in der Kommunikationswissenschaft. Köln: Herbert von Halem Verlag. Gerlitz, C., & Rieder, B. (2013). Mining One Percent of Twitter: Collections, Baselines, Sampling. M/C Journal, 16(2). Abgerufen von http://journal.media- culture.org.au/index.php/mcjournal/article/view/620 Giglietto, F., Rossi, L., & Bennato, D. (2012). The Open Laboratory: Limits and Possibilities of Using Facebook, Twitter, and YouTube as a Research Data Source. Journal of Technology in Human Services, 30(3-4), 145–159. doi:10.1080/15228835.2012.743797 González-Bailón, S., Wang, N., Rivero, A., Borge-Holthoefer, J., & Moreno, Y. (2012). Assessing the bias in communication networks sampled from twitter. Available at SSRN 2185134. Abgerufen von http://papers.ssrn.com/sol3/papers.cfm?abstract_id=2185134 Mahrt, M., & Scharkow, M. (2013). The Value of Big Data in Digital Media Research. Journal of Broadcasting & Electronic Media, 57(1), 20–33. doi:10.1080/08838151.2012.761700 Morstatter, F., Pfeffer, J., Liu, H., & Carley, K. M. (2013). Is the sample good enough? comparing data from twitter’s streaming api with twitter’s firehose. Proceedings of ICWSM. Abgerufen von http://www.public.asu.edu/~fmorstat/paperpdfs/icwsm2013.pdf Seibold, B. (2002). Die flüchtigen Web-Informationen einfangen. Publizistik, 47(1), 45–56. doi:10.1007/s11616-002-0003-3 Vis, F. (2013). A critical reflection on Big Data: Considering APIs, researchers and tools as data makers. First Monday, 18(10). doi:10.5210/fm.v18i10.4878 Welker, M., & Wünsch, C. (Hrsg.). (2010). Die Online-Inhaltsanalyse: Forschungsobjekt Internet. Köln: Halem. 9.11.2013 Facepager 20
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
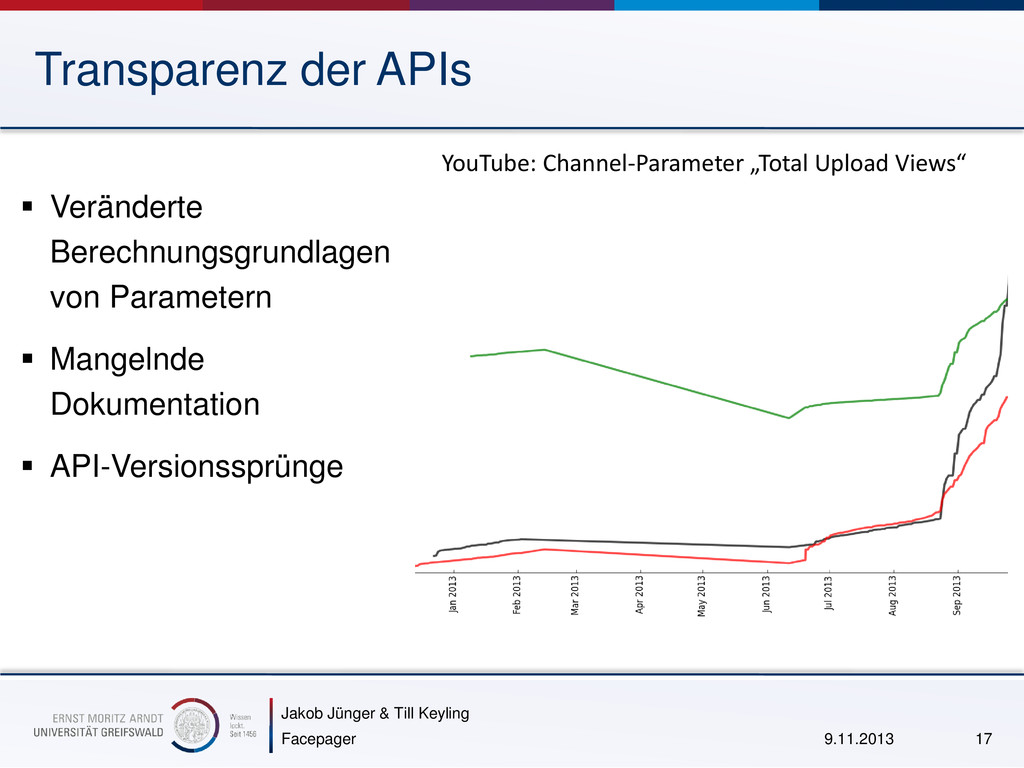{kind=link}
{kind=link}
{kind=link}
{kind=link}