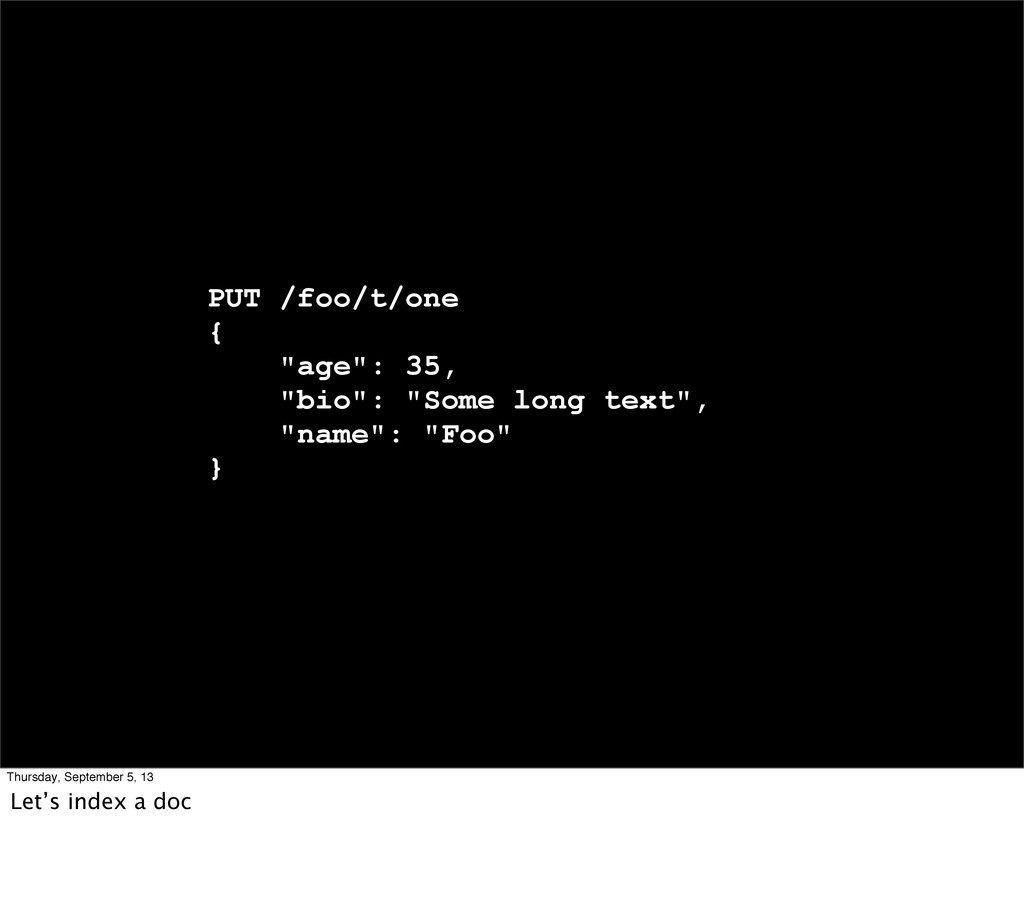
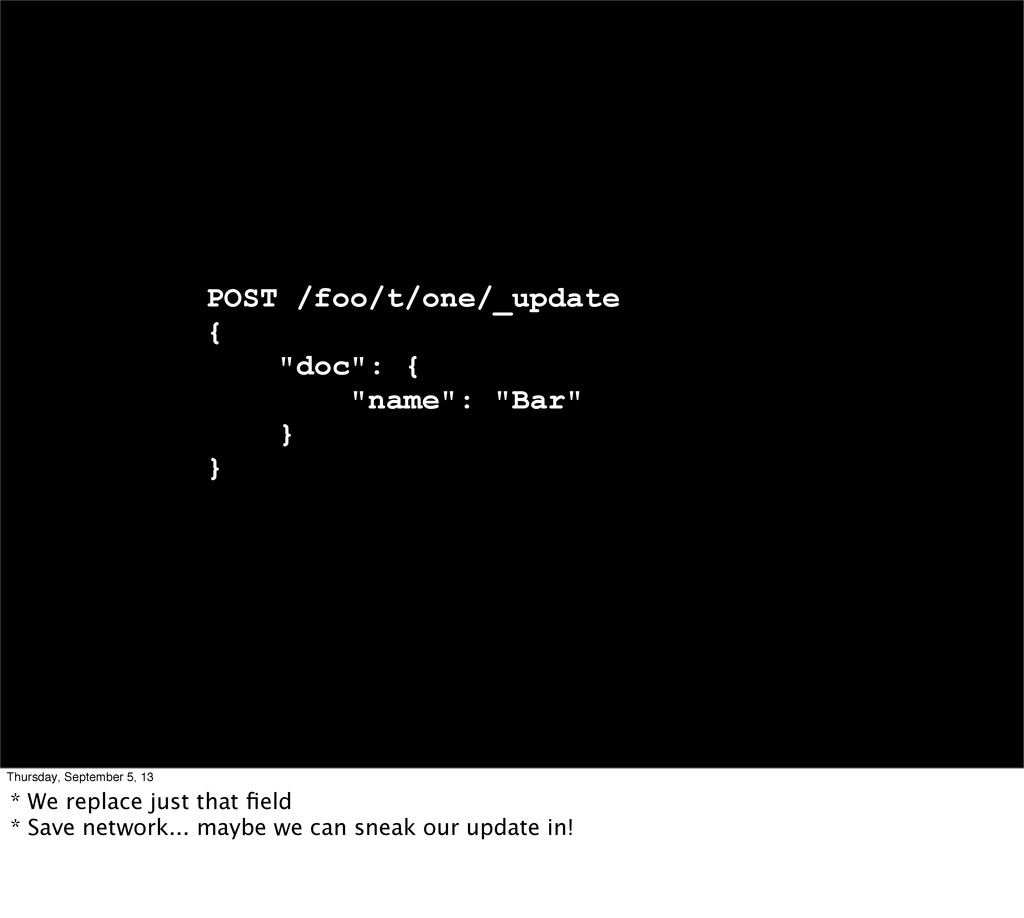
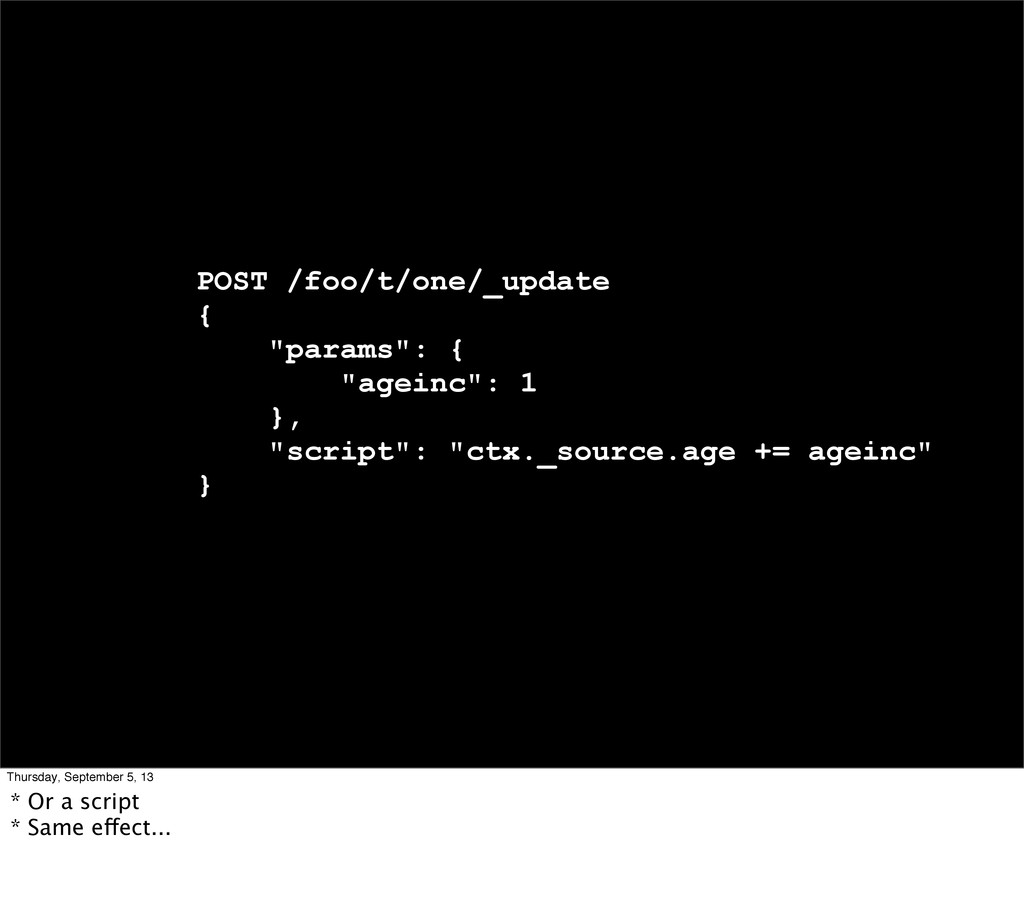
Introduction * Local training Oct 21-22, early bird ends Sept 21 * Why this topic? - I come from a mostly read-only archiving use, lots of people ask about update perf...
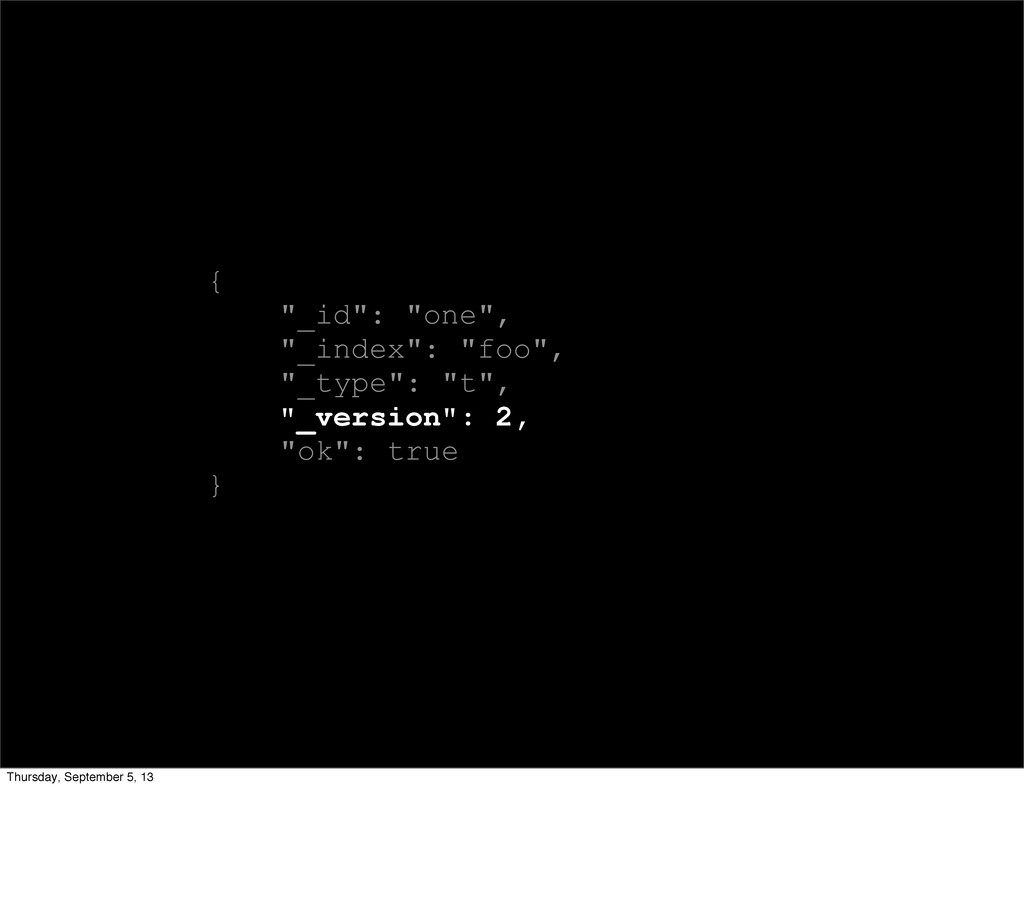
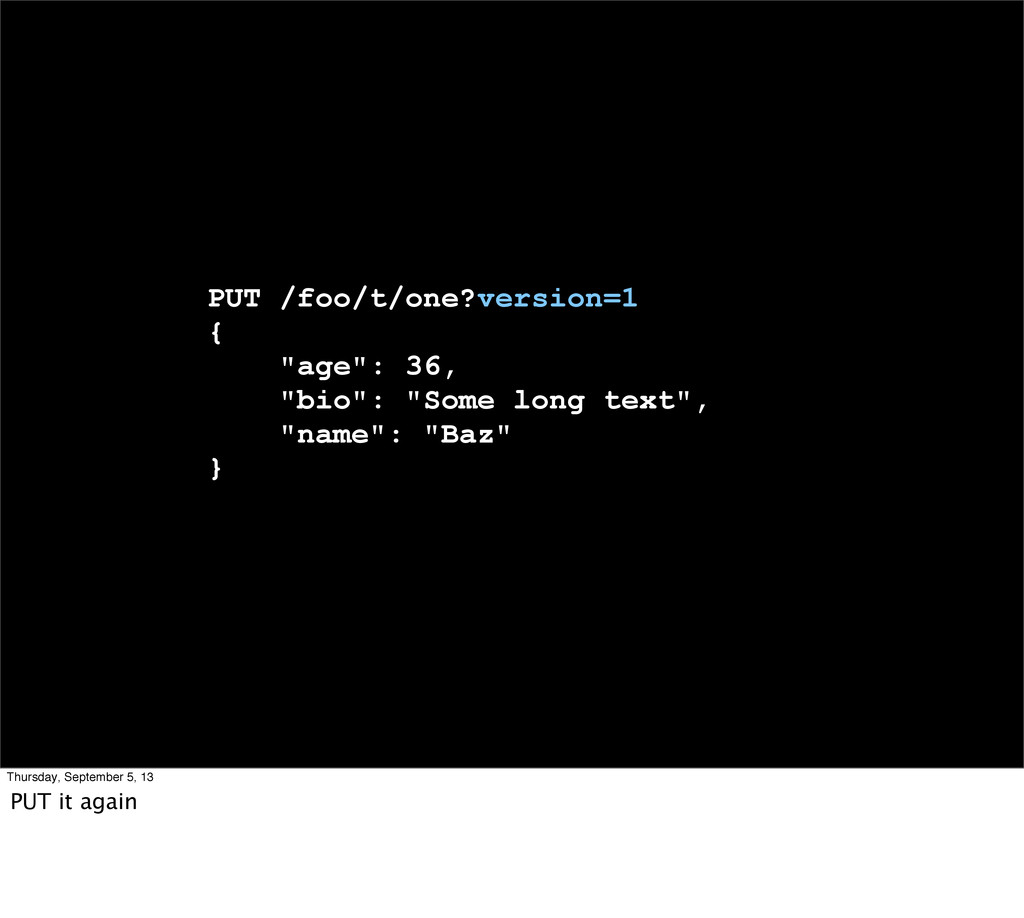
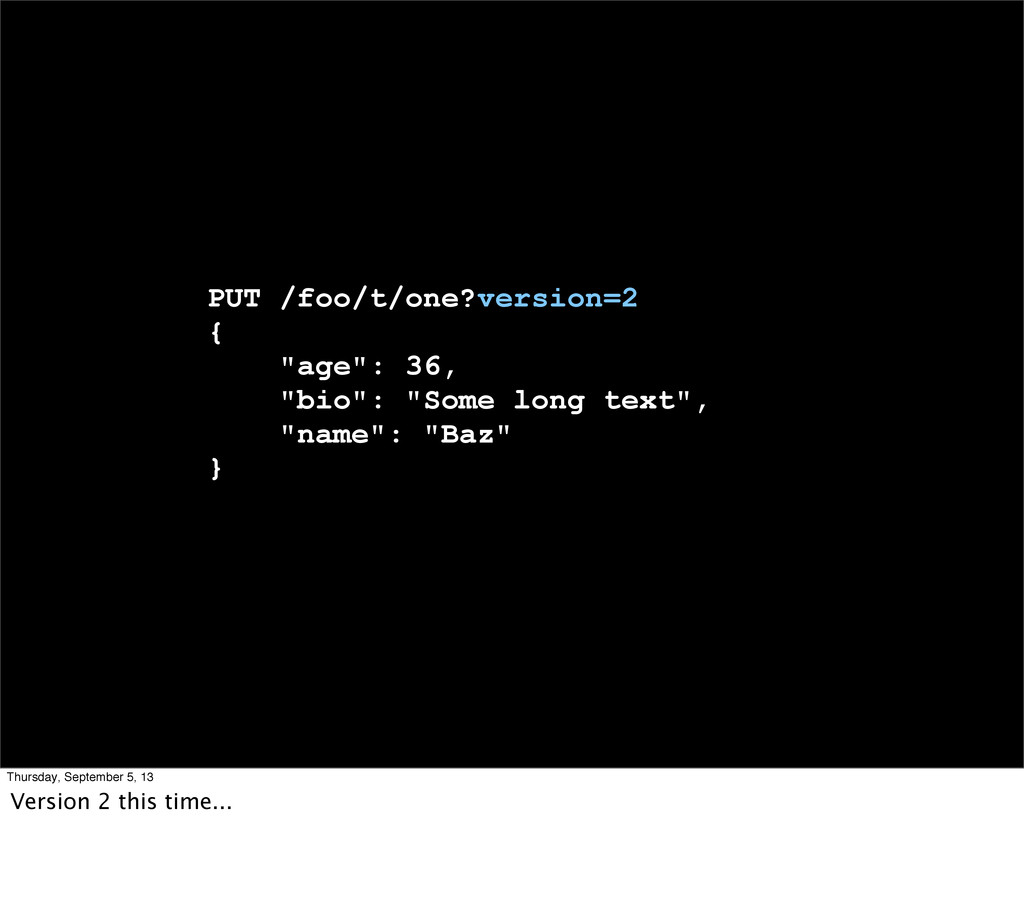
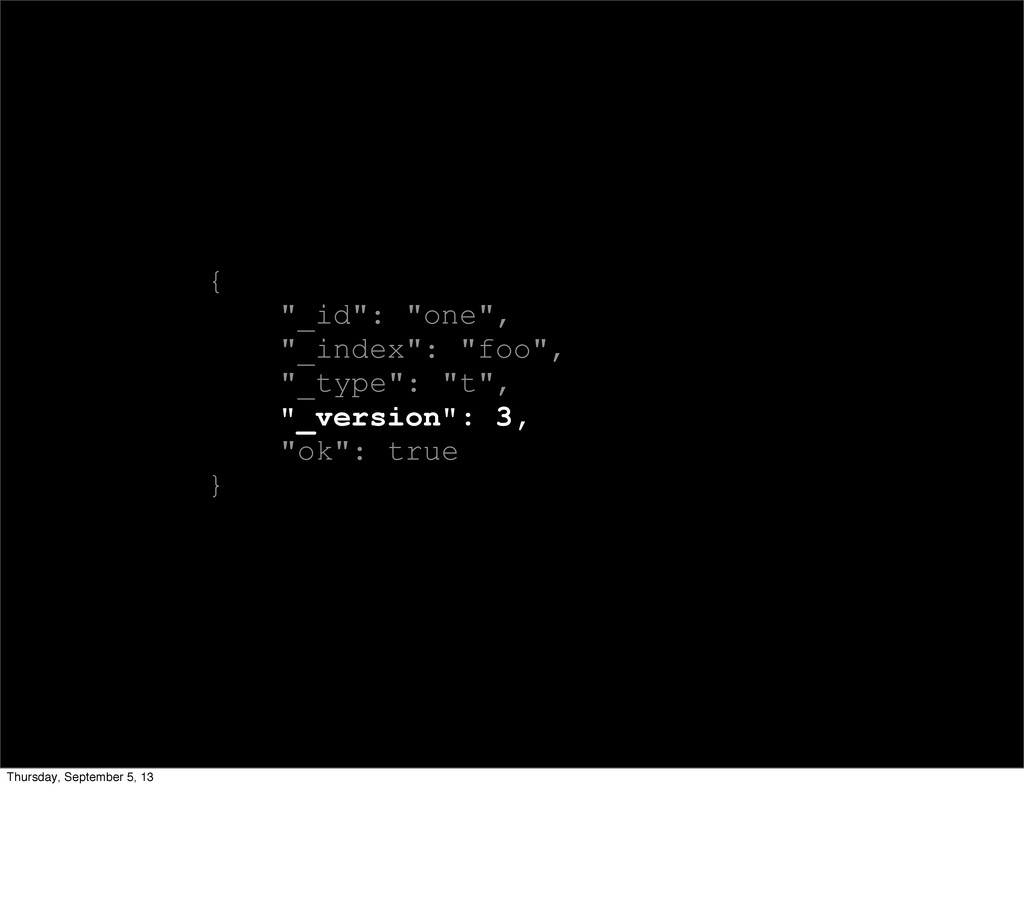
Index, update, delete.... Same end result! * Immutability! * Optimistic concurrency control * Fast, no locks, no magic, HTTP is stateless anyway (ETags)
deployment (already have nice distributed data store) * Can lose some perf during consume (publish a bunch and walk away, workers busy anyway) * Just want a highly available place to store messages
* No new deployment (already have nice distributed data store) * Can lose some perf during consume (publish a bunch and walk away, workers busy anyway) * Just want a highly available place to store messages
13 Lightweight work queue * No new deployment (already have nice distributed data store) * Can lose some perf during consume (publish a bunch and walk away, workers busy anyway) * Just want a highly available place to store messages
about AMQP Thursday, September 5, 13 Lightweight work queue * No new deployment (already have nice distributed data store) * Can lose some perf during consume (publish a bunch and walk away, workers busy anyway) * Just want a highly available place to store messages
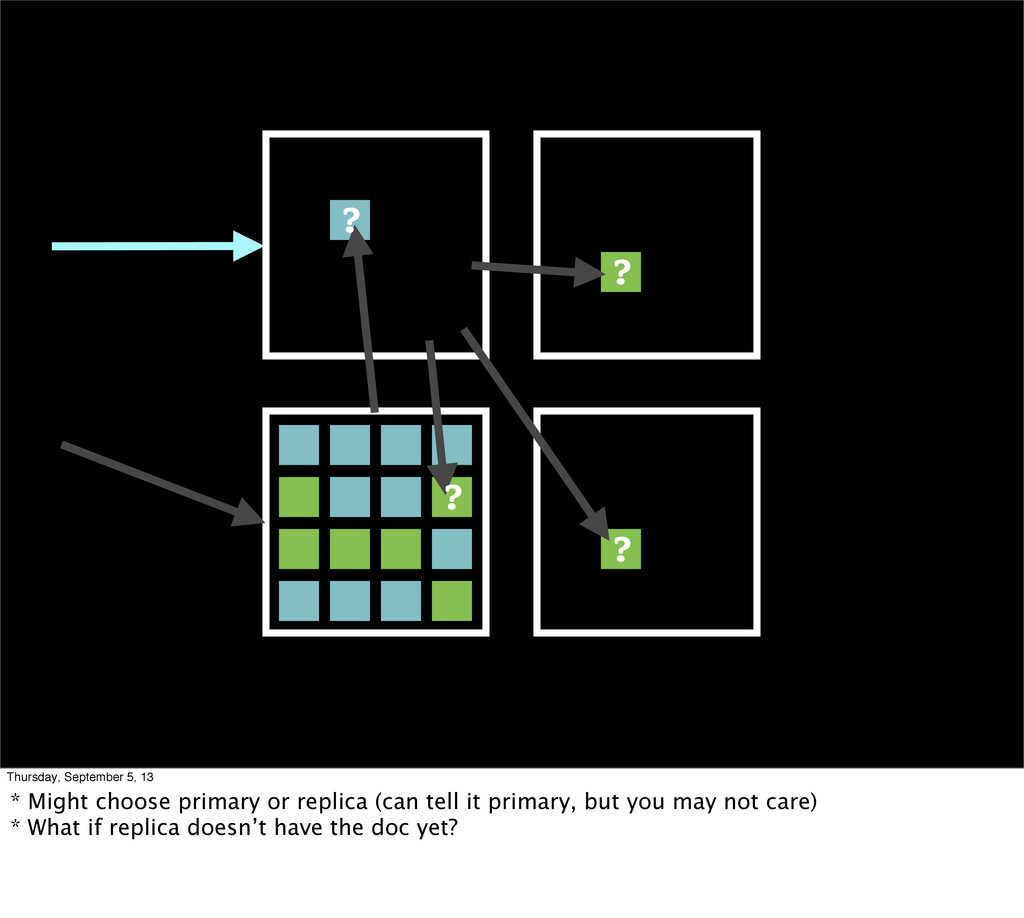
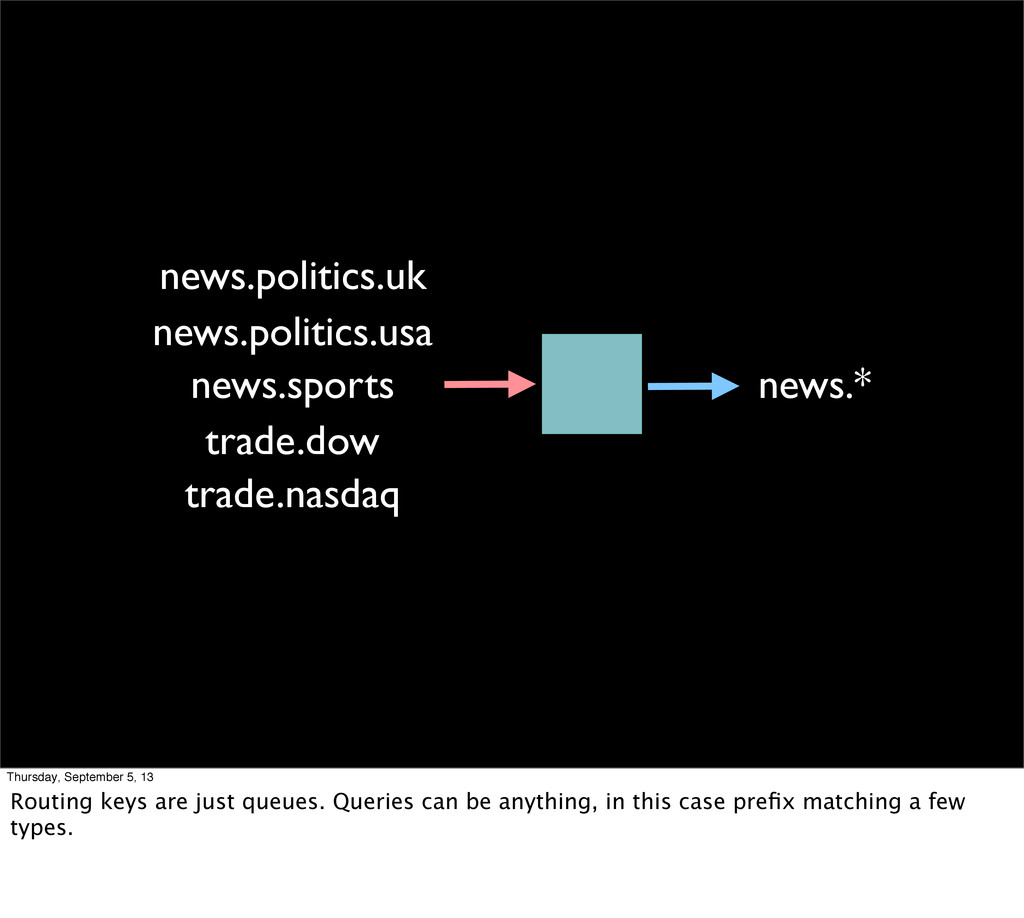
with different shard configurations and risk profiles * Can look for newest message in queue, or ones from Tuesday * Can look for ones containing the job referencing cats
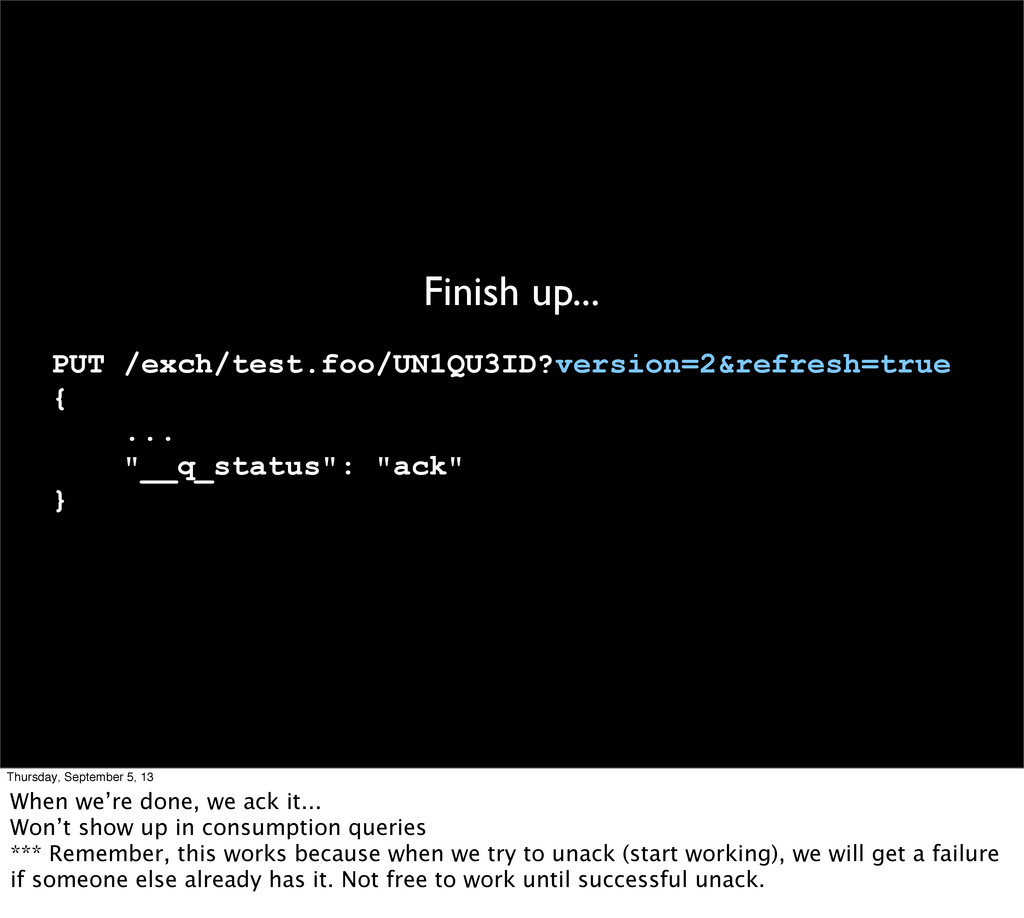
September 5, 13 When we’re done, we ack it... Won’t show up in consumption queries *** Remember, this works because when we try to unack (start working), we will get a failure if someone else already has it. Not free to work until successful unack.
20k msgs/sec on little 4-core MBA Consuming... constant refresh is slow... segment explosion, lots of merging, but still 50-100 msgs/sec In the typical work queue scenario, adding a few ms or secs to a job that may run for minutes is acceptable
in ES, lots of trade-offs users can decide to make * Finding data is often more important and nuanced than storing it. Search is king. * RDBMS not going anywhere, neither are graph databases. Right tool yada... * ?
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![{ "error": "VersionConflict... current [2], provided [1]]", "status": 409 }](https://files.speakerdeck.com/presentations/7b057110f8c7013021af6a9e10441d41/slide_39.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}