сервисом, компанией или группой разработки • Представленная информация может быть неточной или устаревшей • План доклада: • Пример работы сервиса • Общая схема работы • Описание модуля распознавания симптомов • Описание модуля предсказания диагноза • Результаты и сравнение с аналогичными сервисами
симптомов из произвольного текста • Natural Language Processing: нейронные сети 2. Генерация уточняющих вопросов, получение ответов и вывод предварительных диагнозов • Итеративный процесс • Байесовская сеть
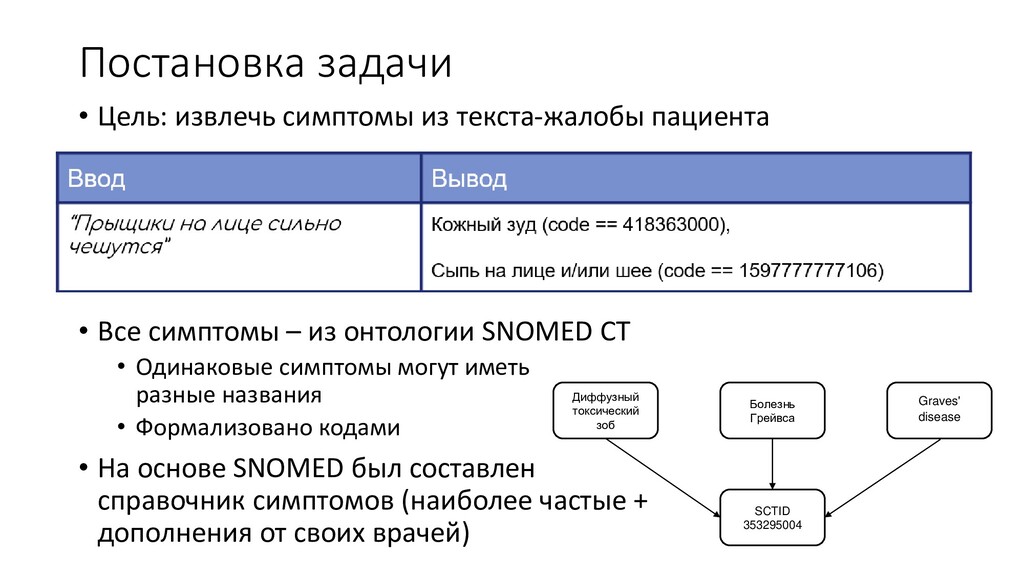
Все симптомы – из онтологии SNOMED CT • Одинаковые симптомы могут иметь разные названия • Формализовано кодами • На основе SNOMED был составлен справочник симптомов (наиболее частые + дополнения от своих врачей) Диффузный токсический зоб Болезнь Грейвса Graves' disease SCTID 353295004
и тот же симптом можно выразить очень по разному • Концентрированные короткие тексты • Мало деталей и конкретики • Сложность выявления паттернов • Дорогая и трудоемкая экспертная разметка • Необходимо медицинское образование • Текущее решение: классификация текста
середина грудь одышка” • Предложение разбивается на скип-граммы • Каждая скип-грамма отправляется на вход классификатору (нейронная сеть), который определяет вероятную область медицины • Далее отправляется в классификатор конкретной области медицины • Или в generic модель, если определить область не удалось
Цели: • Определение области медицины • Определение симптома из конкретной области (для врача из этой области) • Нюансы: • Добавление и учет альтернативных формулировок • Источника данных для разметки – форумы медицинских консультаций • Вместо ручной разметки текста – предварительная автоматическая разметка на основе cosine similarity (word2vec), а затем передача результатов врачам для исправления ошибок (и ошибок, и ошибок, и ошибок...)
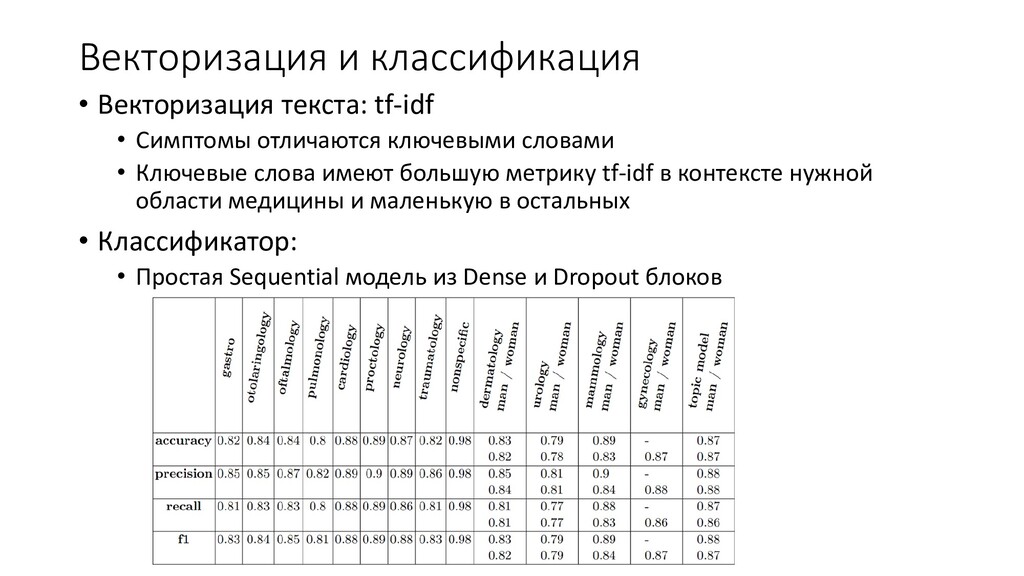
ключевыми словами • Ключевые слова имеют большую метрику tf-idf в контексте нужной области медицины и маленькую в остальных • Классификатор: • Простая Sequential модель из Dense и Dropout блоков
Уточнение симптомов • Постановка вероятных диагнозов • На основе учтенных факторов риска и симптомов • Инструмент: дискретные байесовские сети • 15 разных сетей для разных областей медицины • Огромный плюс – объяснимость результатов, что важно для медицины
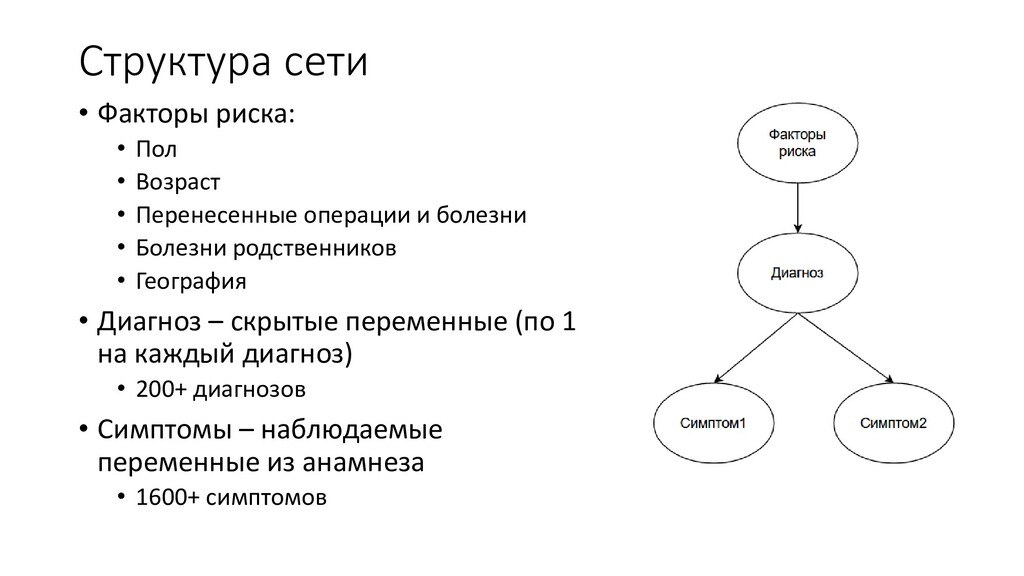
Перенесенные операции и болезни • Болезни родственников • География • Диагноз – скрытые переменные (по 1 на каждый диагноз) • 200+ диагнозов • Симптомы – наблюдаемые переменные из анамнеза • 1600+ симптомов
фактов • Свертка наблюдений в одно (рост + вес == индекс массы тела) • Обогащение данных дополнительной информацией (текущий сезон) • Автоматическое вычисление некоторых фактов по симптомам • «нет боли в животе» -> «боль внизу живота отсутствует» + «боль вверху живота отсутствует» + ... • Исключение фактов • Некоторые наборы фактов взаимоисключающи – их можно вычислить и автоматически проставить как отсутствующие • Пример: «воспаление миндалин» -> NOT «миндалины отсутствуют» • На практике немного сложнее и с матлогикой
вопросы почти всегда необходимо задать • «болит живот» -> необходимо локализовать место боли • «кашель» -> «сухой или мокрый?» • Быстрее, чем делать инференс по сети Этап 4. Инференс по сети • Маркировка симптомов и факторов риска, полученных на предыдущих этапах • Инференс сети
пока неизвестных симптомов, знание которых даст наибольшее количество информации • Определяется по информационной мере Этап 2-5 (Б). Параллельно: вычисление доп. вопросов по факторам риска • Эти вопросы обычно задаются в конце – ими удобно подтверждать диагноз, но не вычислять • «Болели ли ваши родственники XXX?»
диагнозов) Этап 7. Построение пути решения • Рассказывает, какие факторы наиболее повлияли на выбранные диагнозы на текущий моменты • Необходимо для визуализации и объяснения пользователю или мед. эксперту при составлении диагноза • Реализовано, но не отображается на настоящий момент
задать вопрос) в набор вопросов • «Потенциально болит живот» -> «болит ли живот?», «где болит?», и т.д. Этап 9. Демонстрация вопросов пользователю • Задает вопрос(ы) пользователю и собирает ответы • Далее переходит на этап 4 (инференс по сети), или 2-5 (Б) доп. вопросы по факторам риска, или в конец работы.
Люди с медицинским образованием и соответствующим опытом работы в нужной сфере медицины 2. Анализ клинических данных и консультация с практикующими врачами или исследователями • Уточнение структуры сети, коррекция модели
Проблемы: данных в хорошем виде (пригодном для обучения) очень мало • Большая часть: агрегация информации по врачам • Усреднение мнений врачей о диагнозе по симптомам • Telegram бот для сбора данных: • Используя структуру сети, генерирует вопросы вида «как часто головная боль встречается при XXX?» • Использовали Noisy-Max (см. Noisy-Or, Pearl 1988) и Noisy-Adder (Zagorecki, 2010) • Сильно сократило размеры таблиц и очень сильно уменьшило число врачам (с условных 10 000 до 1000)
тестовый фреймворк и тесты ☺ • См. пример теста справа • Использованные метрики: • Топ-1 и топ-3 попаданий правильной болезни в ответы • Процент найденных скрытых данных • Некоторые симптомы «присутствовали» в тесте, но не были выданы сети, а ждали правильного вопроса • Нагрузочные тесты TakeAPerson() .WhoHas(…) .And .WhoHas(…) .And […] .And .MakeInferForHim() .InferenceResultMust .IncludeAdditionalQuestionAbout(…) .OnThatPersonAnswer(…) .Then .MakeNewInferForPerson();
вычислений • figaro • pymc3 • pyro • stan • Edward • Smile Engine • Infer.Net • Как задать пользователю поменьше вопросов • Как задать наиболее важные вопросы
под лицензией MIT • .NET Standard 2.0 • Т.е. можно под .NET Framework 4.6.1+ (Windows) и .NET Core 3.1+ (Linux, Windows, etc.) • Генерирует код, описывающий структуру модели и ее связи • Позволяет использовать разные алгоритмы инференса • Используемый на текущий момент – Expectation Propagation • Модель компилируется в dll, подгружается и используется отдельным сервисом • Внутренний параллелизм (PLINQ) и борьба с ним ☺
симптомов • Меньшее число вопросов • Генерация дополнительных вопросов после инференса модели • Аналогичные сервисы: • Ada • Babylon • SymptomAid • И др.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}