Shared Nothing tries to eliminate any shared resources • At worst, it puts shared resources in appropriate, easily scaled data stores – e.g. sessions in memcached, search in ElasticSearch Shared Nothing
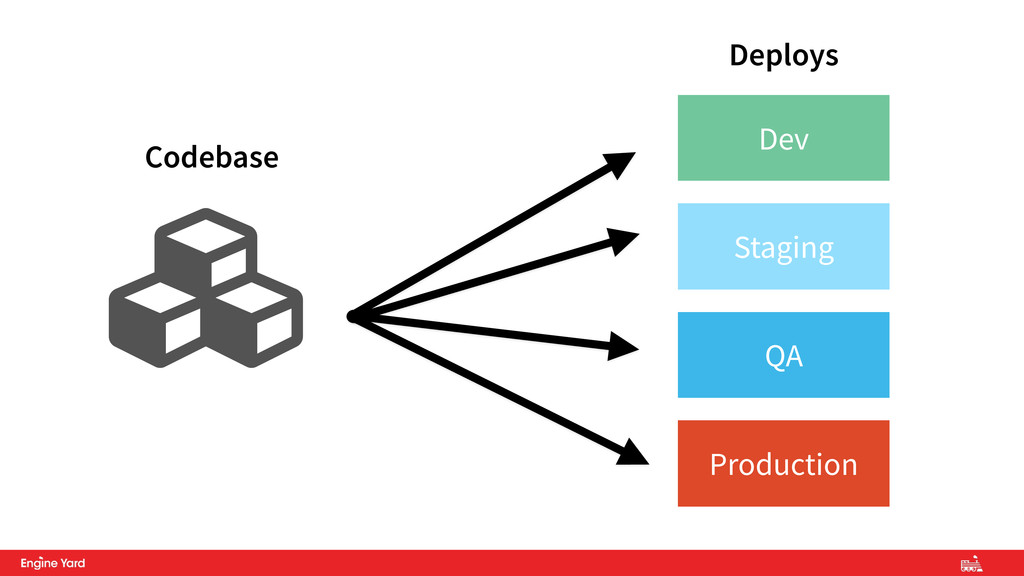
• Multiple codebases = distributed system • Shared code should be in re-usable libraries • Micro-services architecture good – Each service must itself adhere to 12-factor! • Environments should be functionally identical 1. Codebase
qa/staging/prod) – Database credentials – Service credentials – Service locations • Stored in Environment Variables – Language/OS agnostic – Easy to change – You won’t accidentally commit things like passwords into RCS 3. Config
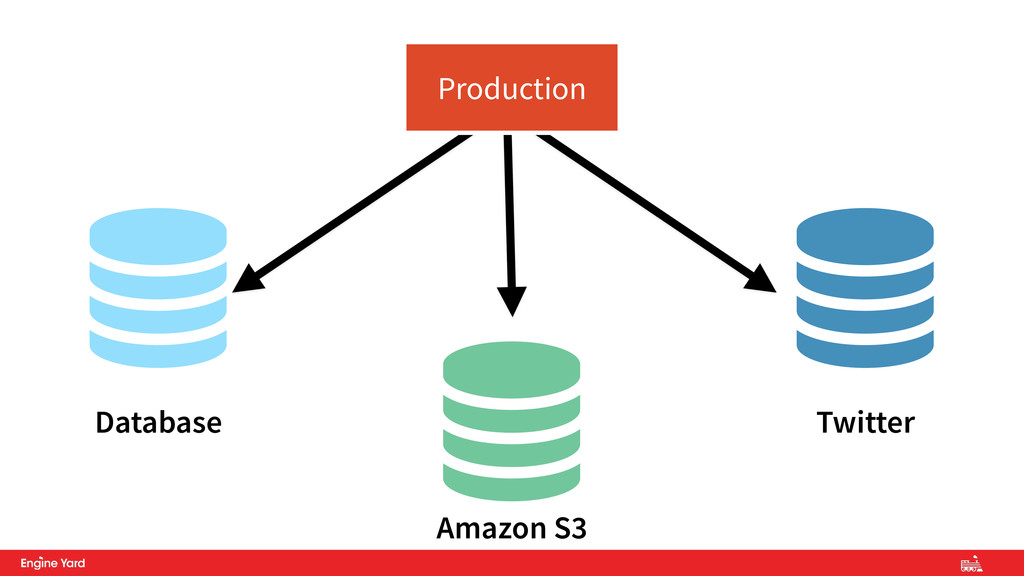
and third-party services identically • All resources should be accessed via an API, making them an implementation detail that can be switched out • Service Locations and Credentials stored in the shared config 4. Backing Services
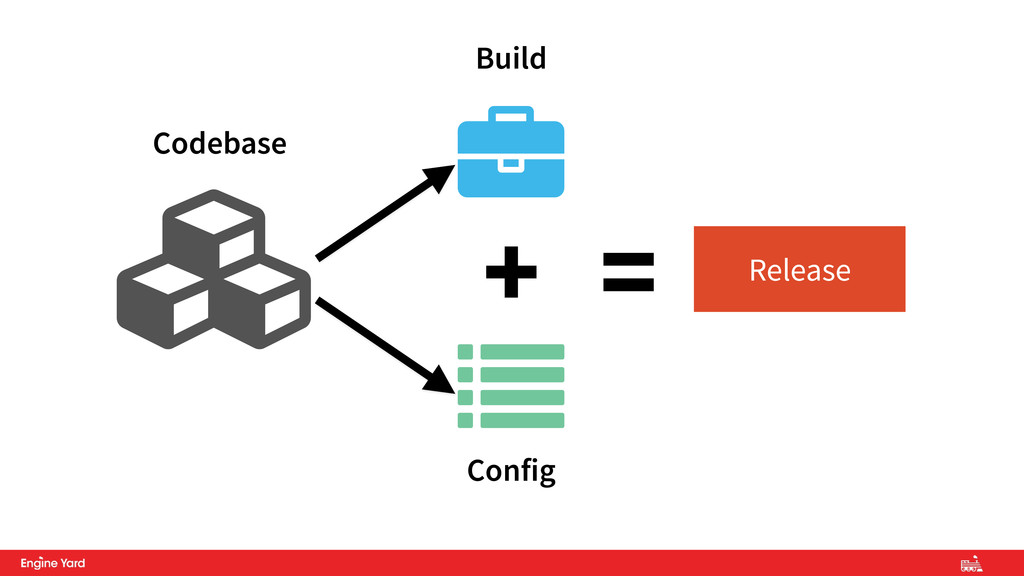
of the code base – Bundle dependencies – Compiles binaries – Builds assets • The Release combines the Build with the Config • The Run is the actual execution of the release in it’s intended environment 5. Build, Release, Run
• Any data that needs to persist must be stored in a stateful backing service • Memory and local FS may be used as a brief, single transaction cache (such as handling large files) • Dependencies are incorporated during the build, rather than on deploy • Sticky sessions are a violation of 12-factor. Use a shared session store. 6. Processes
This allows for a completely self-contained application • I strongly disagree with this! • Great for dev, often terrible for production (particularly in PHP) • Doesn’t work with middle-ware type stacks, like WSGI and PSR-7 7. Port Binding
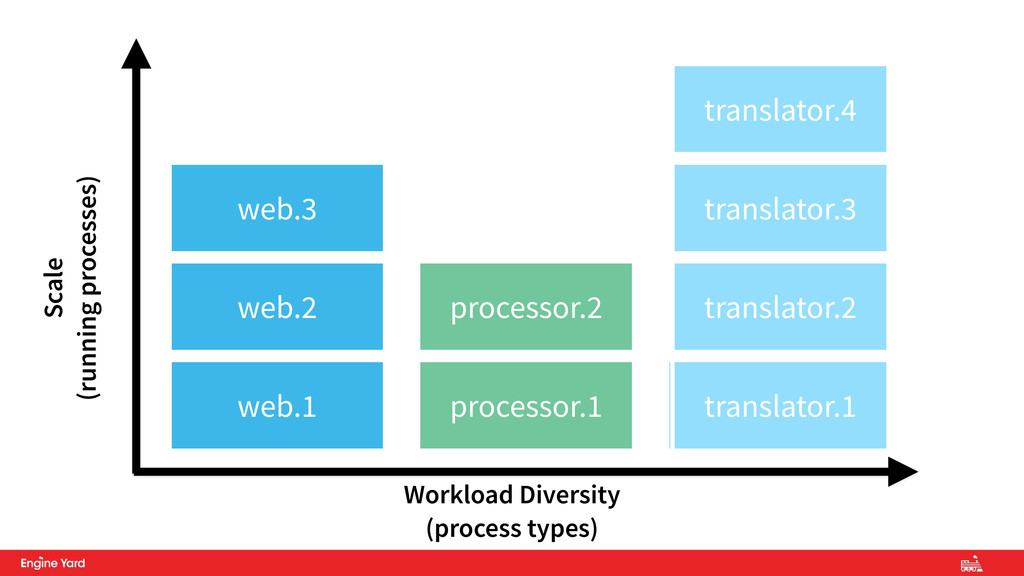
enables easy horizontal scaling • Shared-nothing makes this easy • By using micro services and different process types we can easily scale different workloads with different resource needs 8. Concurrency
rapid deployment • All processes should gracefully handle SIGTERM (e.g. return job to the queue) • Handling of unexpected death should be handled when possible • All jobs should ideally be idempotent, and must be reentrant — running them again after death should be possible • Processes should minimize startup time 9. Disposability
Quick deploys ensures that the codebases diverge minimally – Personnel: Code authors should also be deploying it – Tools: Use the same tools in both systems, do not use lightweight alternatives (e.g. SQLite) or different OSes (use a VM if necessary) 10. Dev/Production Parity
All processes should emit logs to STDOUT • During development, a developer should have these visible in the foreground • In other deploys the environment is responsible for collating these all together into a single cohesive event stream • Routed to one or more final destinations (file, network storage, splunk) 11. Logs
be run as one-off processes. • Run in a duplicate environment with the same config (so that it points to the same data sources) • Run against a specific release • Admin processes must ship the release code alongside to avoid sync issues 12. Admin Processes
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}