Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Building a real time analytics engine in JRuby
Search
David Dahl
March 02, 2013
Programming
540
1
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Building a real time analytics engine in JRuby
David Dahl
March 02, 2013
More Decks by David Dahl
See All by David Dahl
Nosql - getting over the bad parts
effata
1
120
Other Decks in Programming
See All in Programming
Haskell/Servantを通してWebミドルウェアを捉え直す
pizzacat83
1
600
The Past, Present, and Future of Enterprise Java
ivargrimstad
0
300
AIキャラアプリkaiwaの低遅延音声通話基盤をどう作ったか - AWS Gravitonで支える低遅延・低コストAI Agent基盤
mogamit
0
170
Generative UI & AI-Assistants for Your Angular Solutions
manfredsteyer
PRO
0
120
壊れたパーサから始める関数型設計と構成的なパーサ #fp_matsuri
raiga0310
2
360
PHP初心者セッション2026 〜生成AIでは見えない裏側を知る:今だからLAMPを通して仕組みを学ぶ〜
kashioka
0
580
鹿野さんに聞く!『TypeScriptコードレシピ集』で磨く実践力
tonkotsuboy_com
4
1.1k
継続モナドとリアクティブプログラミング
yukikurage
3
610
AIが無かった頃の素敵な出会いの話
codmoninc
1
130
act2-costs.pdf
sumedhbala
0
120
分散システム、なんですぐ死んでしまうん?耐障害性を高めたいあなたのためのレジリエンスパターン入門
mshibuya
7
6.5k
才能?センス?知らん、 続けたもん勝ちだ。-- 結婚・出産・癌を越えてなお、私がプロダクトを創り続ける理由
16bitidol
2
880
Featured
See All Featured
Avoiding the “Bad Training, Faster” Trap in the Age of AI
tmiket
0
190
How to audit for AI Accessibility on your Front & Back End
davetheseo
0
470
Measuring Dark Social's Impact On Conversion and Attribution
stephenakadiri
2
240
Ecommerce SEO: The Keys for Success Now & Beyond - #SERPConf2024
aleyda
1
2.1k
Accessibility Awareness
sabderemane
1
160
Navigating the moral maze — ethical principles for Al-driven product design
skipperchong
2
420
The Organizational Zoo: Understanding Human Behavior Agility Through Metaphoric Constructive Conversations (based on the works of Arthur Shelley, Ph.D)
kimpetersen
PRO
0
390
Agile Leadership in an Agile Organization
kimpetersen
PRO
0
190
Navigating the Design Leadership Dip - Product Design Week Design Leaders+ Conference 2024
apolaine
1
370
sira's awesome portfolio website redesign presentation
elsirapls
0
300
16th Malabo Montpellier Forum Presentation
akademiya2063
PRO
0
260
Reality Check: Gamification 10 Years Later
codingconduct
0
2.2k
Transcript
Building a real time analytics engine in JRuby David Dahl
@effata
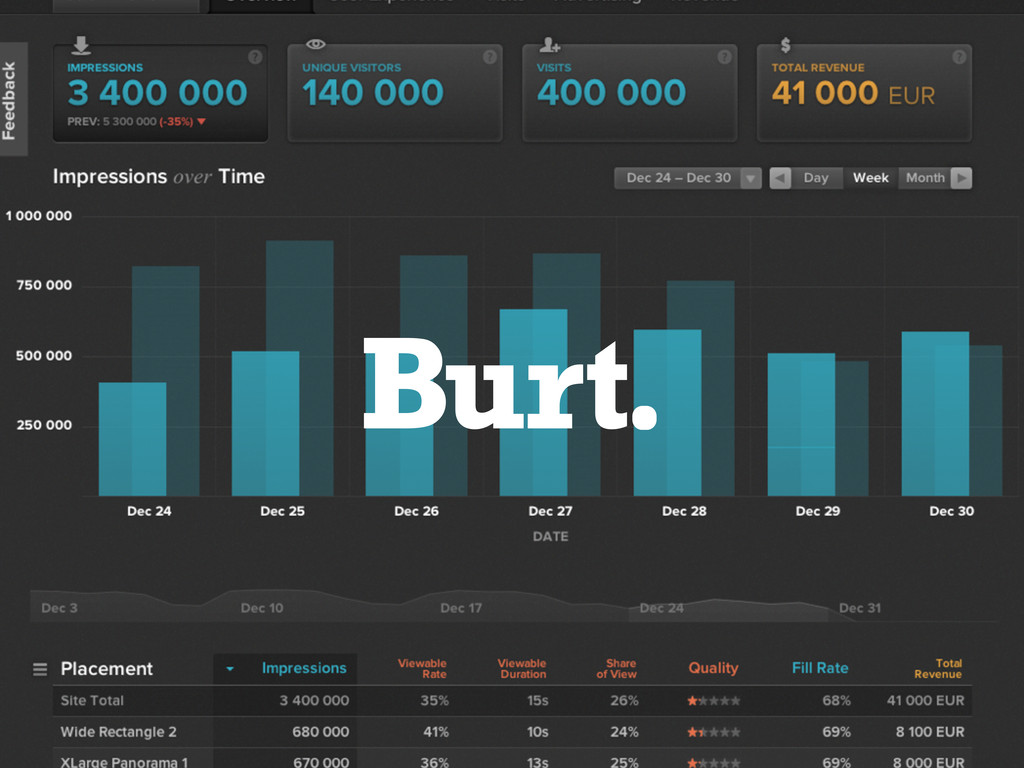
whoami ‣ Senior developer at Burt ‣ Analytics for online
advertising ‣ Ruby lovers since 2009 ‣ AWS
None
None
None
Getting started ‣ Writing everything to mysql, querying for every
report - Broke down on first major campaign ‣ Precalculate all the things! ‣ Every operation in one application - Extremely scary to deploy ‣ Still sticking to MRI
None
Stuck ‣ Separate and buffer with RabbitMQ - Eventmachine ‣
Store stuff with MongoDB - Blocking operations ‣ Bad things
Java? ‣ Threading ‣ “Enterprise” ‣ Lots of libraries Think
about creating something Java ecosystem Discover someone has made it for you already Profit!
Moving to JRuby ‣ Threads! ‣ A real GC ‣
JIT ‣ Every Java, Scala, Ruby lib ever made ‣ Wrapping java libraries is fun! ‣ Bonus: Not hating yourself
Challenges
“100%” uptime ‣ We can “never” be down! ‣ But
we can pause ‣ Don’t want to fail on errors ‣ But it’s ok to die
Buffering ‣ Split into isolated services ‣ Add a buffering
pipeline between - We LOVE RabbitMQ ‣ Ack and persist in a “transaction” ‣ Figure out if you want - at most once - at least once
Databases ‣ Pick the right tool for the job ‣
MongoDB everywhere = bad ‣ Cassandra ‣ Redis ‣ NoDB - keep it streaming!
Java.util.concurrent
Shortcut
Executors Better than doing Thread.new
thread_pool = ! Executors.new_fixed_thread_pool(16) stuff.each do |item| thread_pool.submit do crunch_stuff(item)
end end
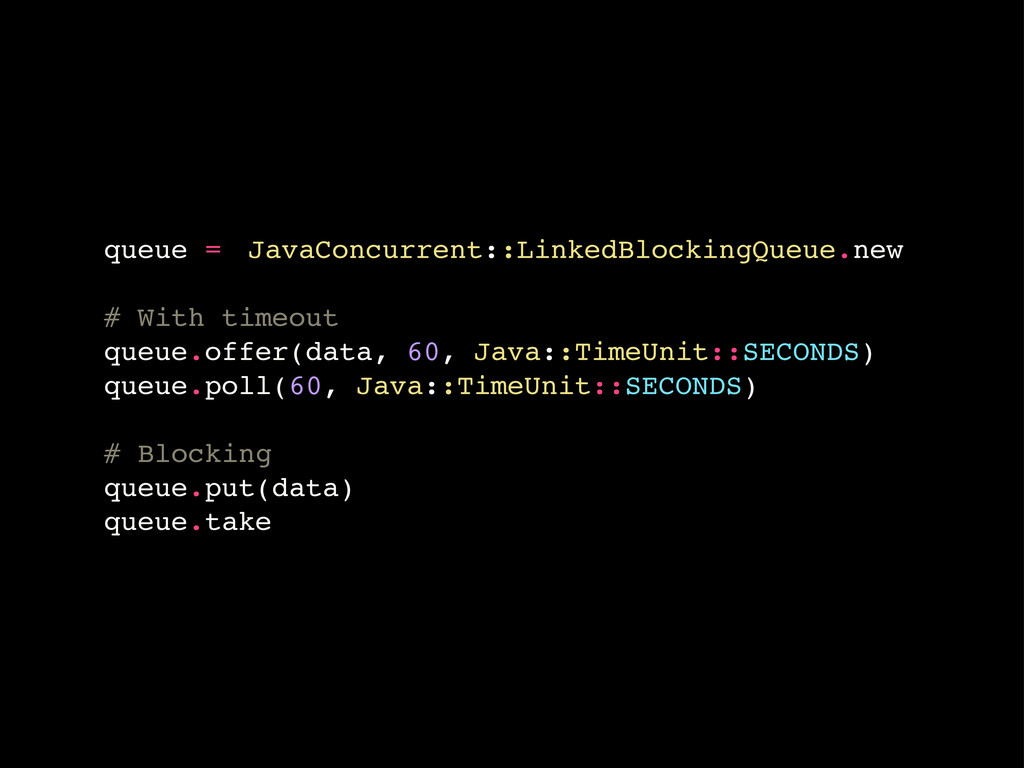
Blocking queues Producer/consumer pattern made easy Don’t forget back pressure!
queue = ! JavaConcurrent::LinkedBlockingQueue.new # With timeout queue.offer(data, 60, Java::TimeUnit::SECONDS)
queue.poll(60, Java::TimeUnit::SECONDS) # Blocking queue.put(data) queue.take
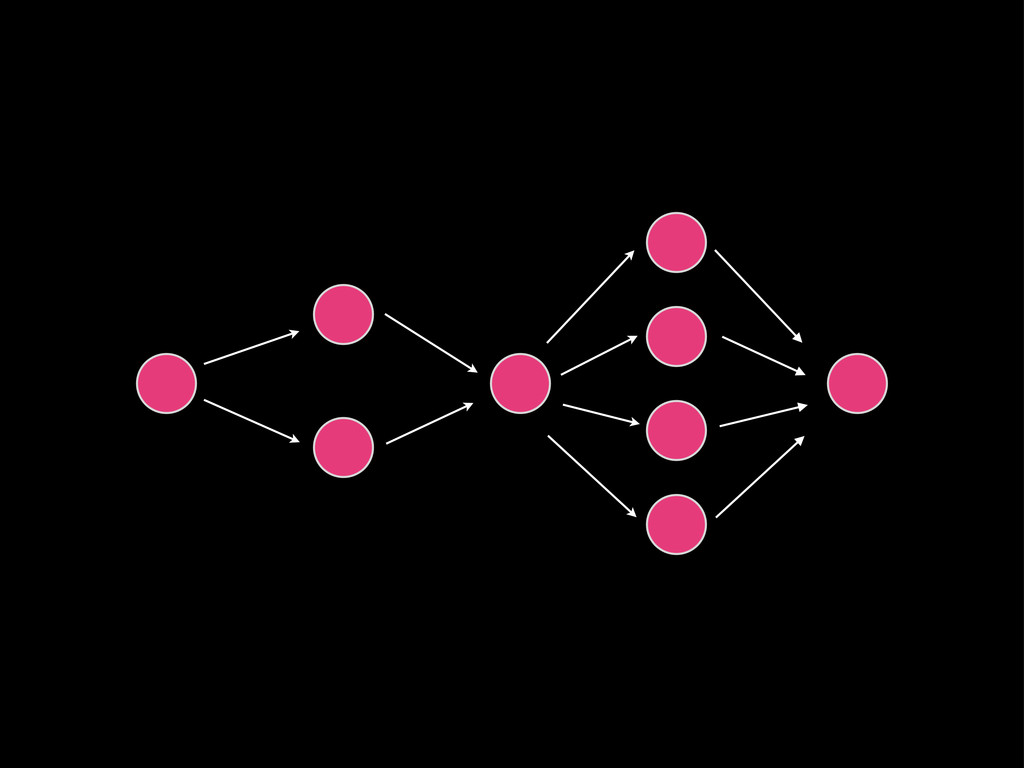
Back pressure Storage Timer Data processing Queue State
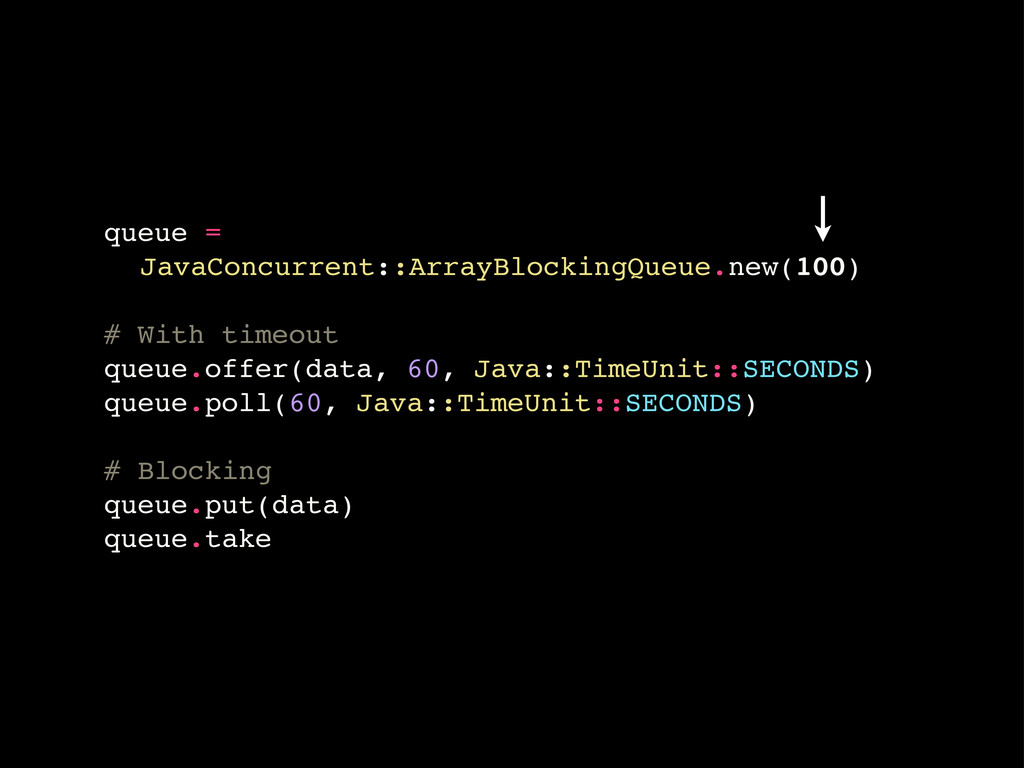
queue = ! JavaConcurrent::ArrayBlockingQueue.new(100) # With timeout queue.offer(data, 60, Java::TimeUnit::SECONDS)
queue.poll(60, Java::TimeUnit::SECONDS) # Blocking queue.put(data) queue.take
More awesomeness ‣ Java.util.concurrent - Atomic(Boolean/Integer/Long) - ConcurrentHashMap - CountDownLatch
/ Semaphore ‣ Google Guava ‣ LMAX Disruptor
Easy mode ‣ Thread safety is hard ‣ Use j.u.c
‣ Avoid shared mutual state if possible ‣ Back pressure
Actors Another layer of abstractions
Akka Concurrency library in Scala Most famous for its actor
implementation
Mikka Small ruby wrapper around Akka
class SomeActor < Mikka::Actor def receive(message) # do the thing
end end
Storm github.com/colinsurprenant/redstorm
We broke it But YOU should definitely try it out!
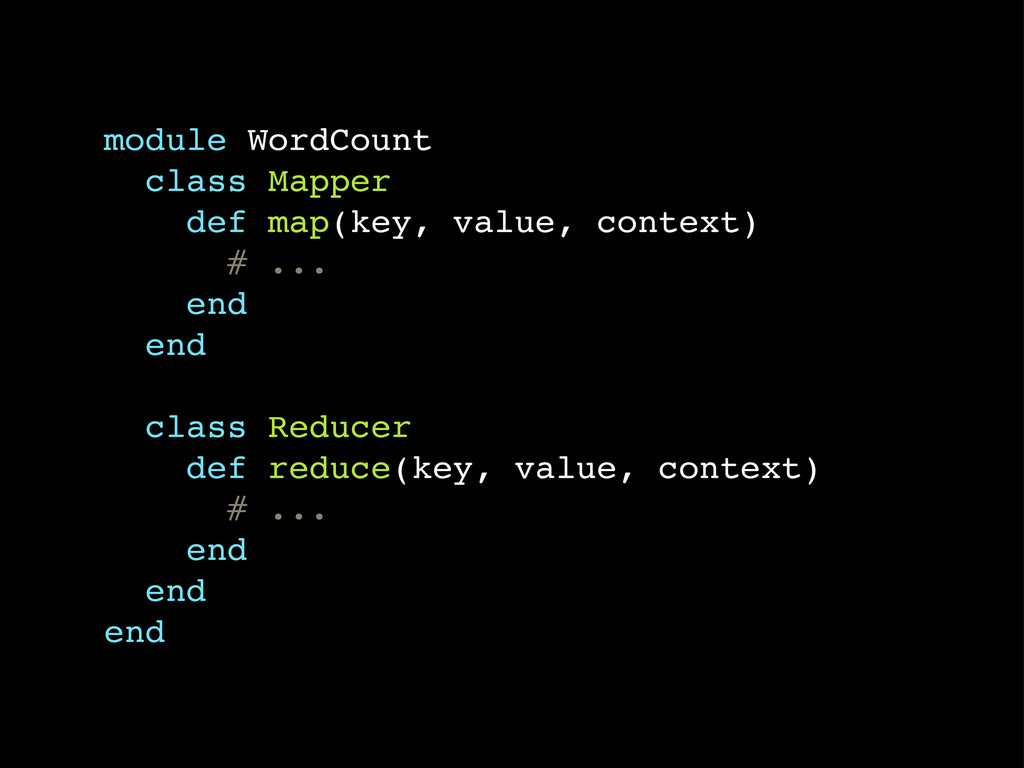
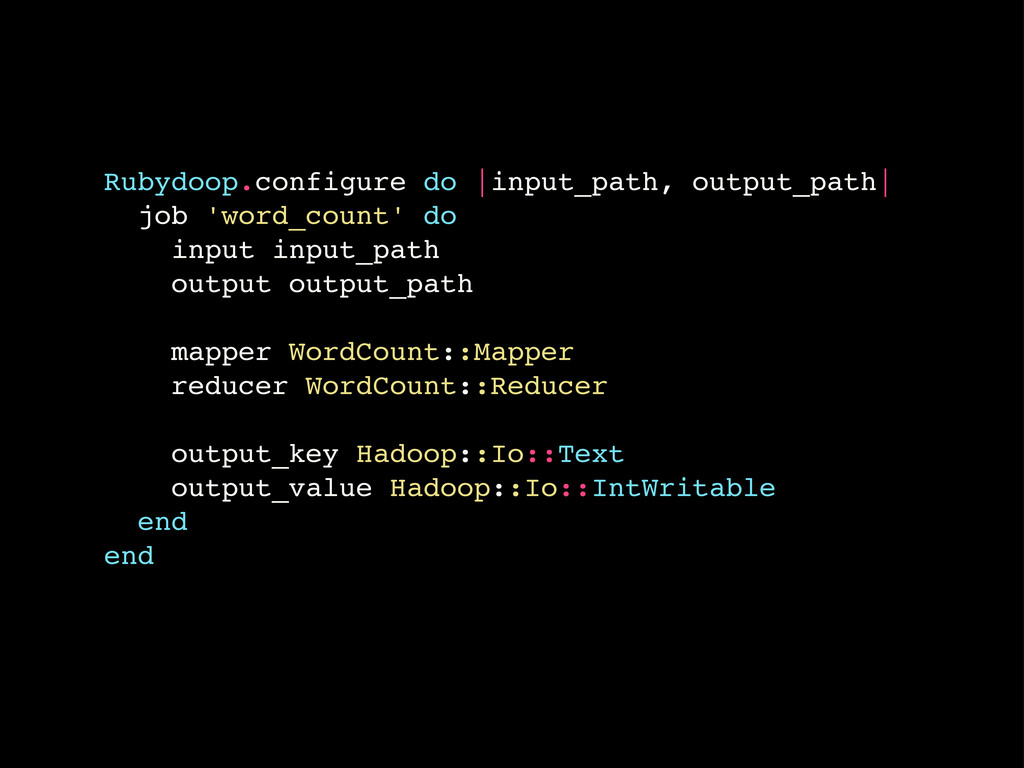
Hadoop github.com/iconara/rubydoop
module WordCount class Mapper def map(key, value, context) # ...
end end class Reducer def reduce(key, value, context) # ... end end end
Rubydoop.configure do |input_path, output_path| job 'word_count' do input input_path output
output_path mapper WordCount::Mapper reducer WordCount::Reducer output_key Hadoop::Io::Text output_value Hadoop::Io::IntWritable end end
Other cool stuff ‣ Hotbunnies ‣ Eurydice ‣ Bundesstrasse ‣
Multimeter
Thank you @effata
[email protected]
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Thank you @effata [email protected]](https://files.speakerdeck.com/presentations/e6d96680657c0130b23612313b0318ca/slide_34.jpg){kind=link}