Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Nosql - getting over the bad parts
Search
David Dahl
March 04, 2013
Programming
120
1
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Nosql - getting over the bad parts
Talk held at Scandinavian Developer Conference in Gothenburg
David Dahl
March 04, 2013
More Decks by David Dahl
See All by David Dahl
Building a real time analytics engine in JRuby
effata
1
540
Other Decks in Programming
See All in Programming
エンジニアにデザインハーネスを 〜デザインプロセスを規定するためのハーネス〜 / Design harness from an engineer's perspective
rkaga
2
1.6k
AI 輔助遺留系統現代化的經驗分享
jame2408
1
1.2k
Foundation Models frameworkで画像分析
ryodeveloper
1
120
Apache Hive: Toward a Cloud Native Lakehouse
okumin
0
140
act2-costs.pdf
sumedhbala
0
120
Claude Team Plan導入・ガイド
tk3fftk
0
220
Generative UI & AI-Assistants for Your Angular Solutions
manfredsteyer
PRO
0
120
AI がコードを書く時代における新卒エンジニアの仕事風景 (2026) / New Graduate Engineers in the Era of AI Coding (2026)
sushichan044
0
220
ルールを書いて終わらせないハーネスエンジニアリング
yug1224
3
1.6k
Prismを使った型安全な暗号化_関数型まつり2026
_fhhmm
0
140
SLOをサービス品質の共通言語にするために 取り組んできたこと
wakana0222
0
520
광주소프트웨어마이스터고등학교 DevFest 특강 - 바이브 코딩 시대에서 주니어 개발자로 살아남는 방법
utilforever
1
150
Featured
See All Featured
Leo the Paperboy
mayatellez
8
1.9k
Digital Ethics as a Driver of Design Innovation
axbom
PRO
1
350
A Guide to Academic Writing Using Generative AI - A Workshop
ks91
PRO
1
350
Navigating Algorithm Shifts & AI Overviews - #SMXNext
aleyda
1
1.5k
Writing Fast Ruby
sferik
630
63k
Tell your own story through comics
letsgokoyo
1
1k
Building a A Zero-Code AI SEO Workflow
portentint
PRO
0
640
ピンチをチャンスに:未来をつくるプロダクトロードマップ #pmconf2020
aki_iinuma
128
56k
The Art of Programming - Codeland 2020
erikaheidi
57
14k
Intergalactic Javascript Robots from Outer Space
tanoku
273
27k
Avoiding the “Bad Training, Faster” Trap in the Age of AI
tmiket
0
190
GitHub's CSS Performance
jonrohan
1033
470k
Transcript
“nosql” Getting over the bad parts David Dahl @effata
Rant
Overview ‣ Real life lessons ‣ Production systems ‣ Write
heavy ‣ MongoDB ‣ Redis ‣ Cassandra
generic ‣ Took a DB class? - Forget everything you
learned! ‣ Denormalize all the things - Up to a limit ‣ Consistency is your responsibility ‣ Primary keys - Give them a lot of thought
None
{ "_id" : ObjectId("51235a80472689978000004e"), "access" : { "admin": ['some_app'], "deep_access":
{ "another_level": 1 } }, "apps" : [ 'some_app', 'some_other_app' ], "created_at" : ISODate("2012-07-23T13:31:17Z"), "email" : "
[email protected]
", "state" : "active" }
Default behaviour Reckless writes
Brutally Slow Object Notation
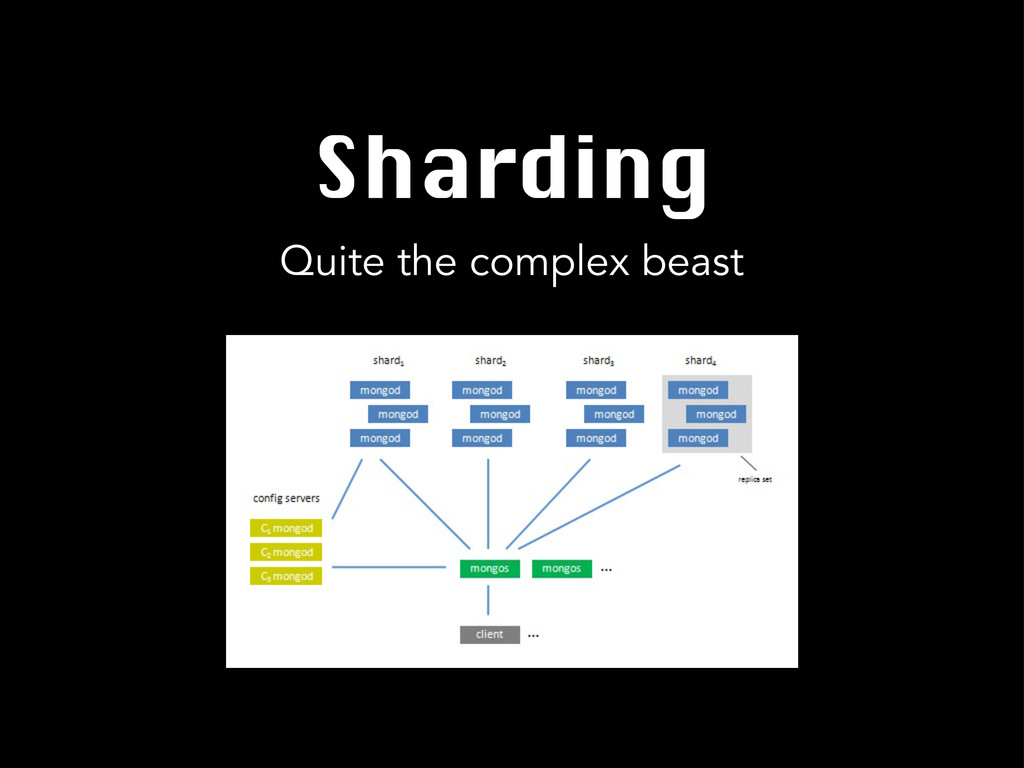
Quite the complex beast Sharding
Global Write Lock Really? ... Actually, not anymore.
Deleting stuff
Good stuff ‣ Replication - It just works, and it
works REALLY well - rs.init(), rs.add(“second.node”) ‣ Schemaless + secondary indexes - Add whatever, query however ‣ Javascript CLI - db.find({name: “Clive”, birthdate: {$gte: ISODate(“1975-05-01”)}})
None
‘some/arbitary/key’ => ‘string’ {‘single_level’: ‘hash’} [‘list’, ‘of’, ‘items’] Set(‘a’, ‘b’)
Moar memory! In memory database
Single threaded a.k.a That 30s list command i just ran
blocked the entire production system (that totally never happened)
Persistance ‣ RDB - point in time snapshot - Entire
process forks. - Enable overcommit memory! ‣ AOF - write log - Very slow on startup ‣ AOF has higher priority on startup - Enable at runtime or loose stuff ‣ Monitor your log files!
No clustering ‣ Only master-slave replication - No failover ‣
Redis sentinel - promising but not ready ‣ Redis cluster - unstable/”not production ready” ‣ Twemproxy
Good stuff ‣ Wicked fast - To a limit ‣
Deletion - not a problem ‣ TTL - on key level
None
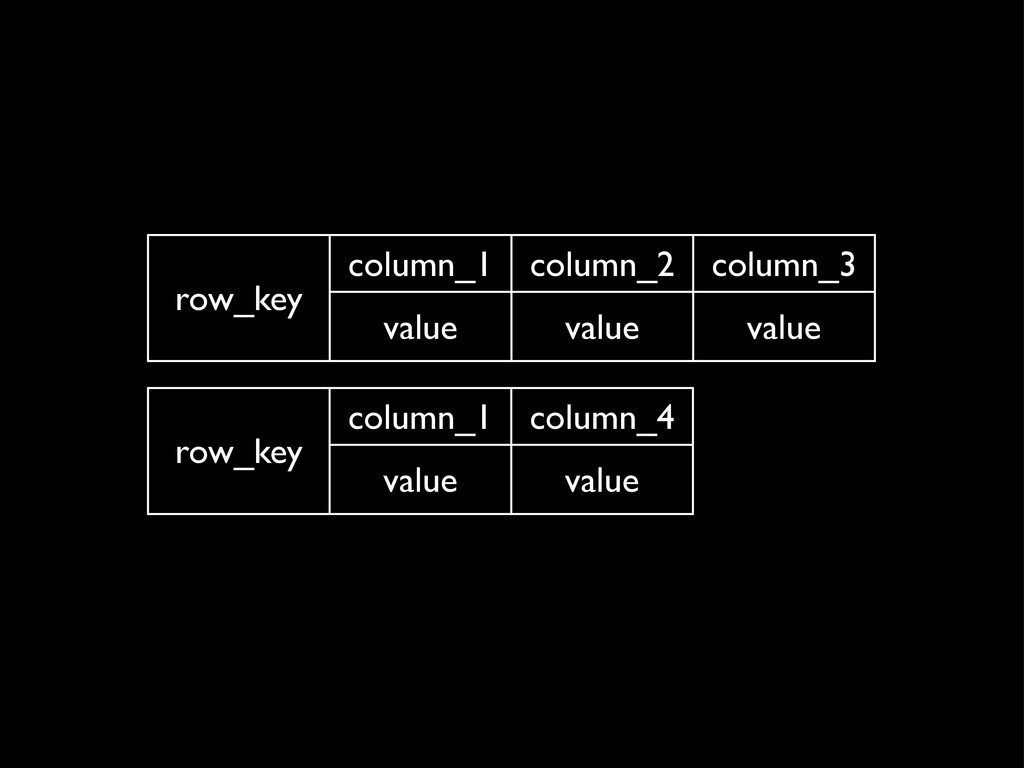
row_key column_1 column_2 column_3 row_key value value value row_key column_1
column_4 row_key value value
Dynamo By Amazon Not to be confused with DynamoDB -
by Amazon
Black magic Or maybe I’m just dumb
Extremely java centric Some of you might think thats a
good thing... 1.2 and CQL3 makes things a lot better
Data modeling Spend a lot of time on it!
“No” indexes Secondary indexes only good for low uniqueness (make
your own)
Good stuff ‣ Black magic - Complex, but well made
‣ TTL on rows and columns ‣ Writes scale linearly “to infinity” - Netflix benchmarked 1 million writes/s (EC2)
Thank you @effata
[email protected]
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![{ "_id" : ObjectId("51235a80472689978000004e"), "access" : { "admin": ['some_app'], "deep_access":](https://files.speakerdeck.com/presentations/d62c646066e50130d62f1231394264b2/slide_5.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![‘some/arbitary/key’ => ‘string’ {‘single_level’: ‘hash’} [‘list’, ‘of’, ‘items’] Set(‘a’, ‘b’)](https://files.speakerdeck.com/presentations/d62c646066e50130d62f1231394264b2/slide_13.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Thank you @effata [email protected]](https://files.speakerdeck.com/presentations/d62c646066e50130d62f1231394264b2/slide_27.jpg){kind=link}