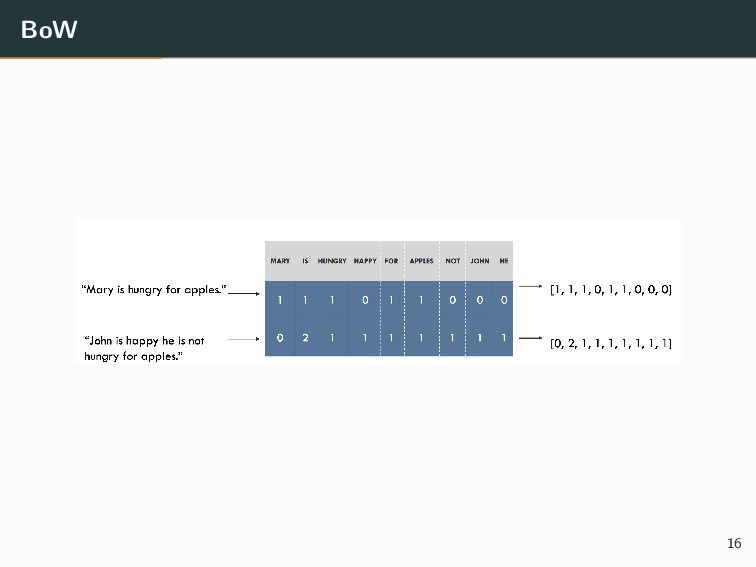
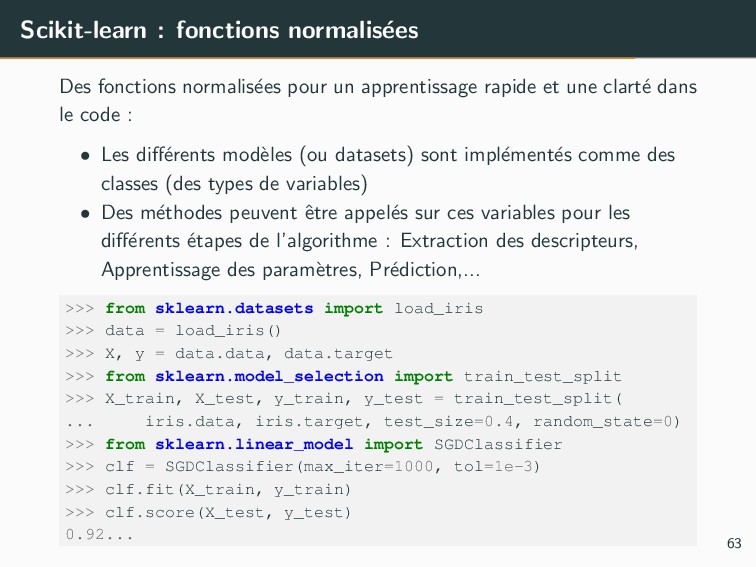
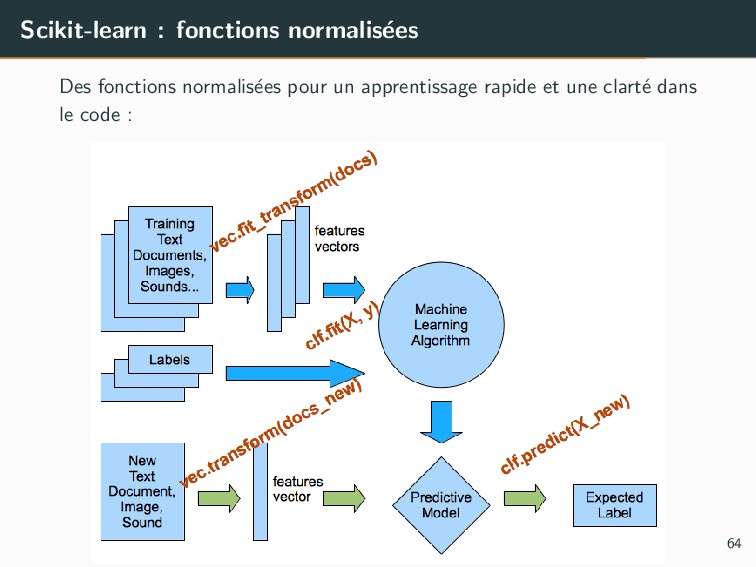
pour vectoriser facilement des descripteurs • Depuis des dictionnaires : sklearn.feature extraction • Depuis des images : sklearn.feature extraction.image • Depuis du texte : sklearn.feature extraction.text >>> from sklearn.feature_extraction.text import CountVectorizer >>> corpus = [ ... 'This is the first document.', ... 'This is the second second document.', ... 'And the third one.', ... 'Is this the first document?', ... ] >>> X = vectorizer.fit_transform(corpus).toarray() array([[0, 1, 1, 1, 0, 0, 1, 0, 1], [0, 1, 0, 1, 0, 2, 1, 0, 1], [1, 0, 0, 0, 1, 0, 1, 1, 0], [0, 1, 1, 1, 0, 0, 1, 0, 1]]...) 65
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
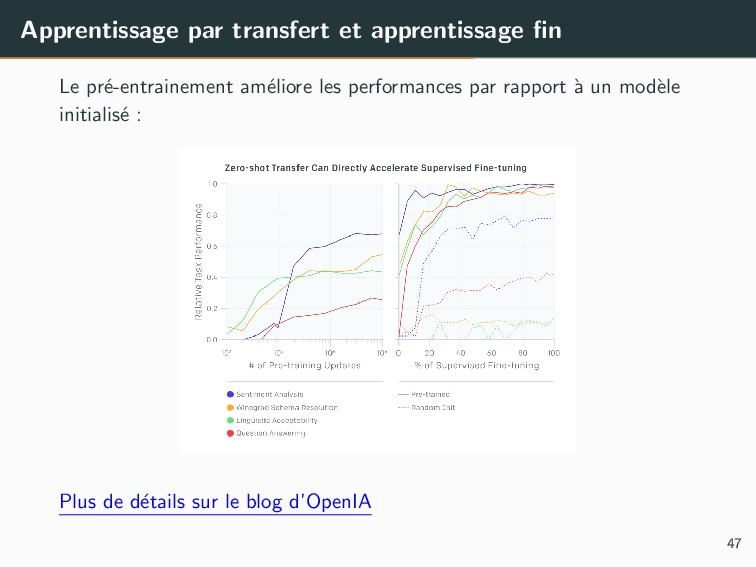{kind=link}
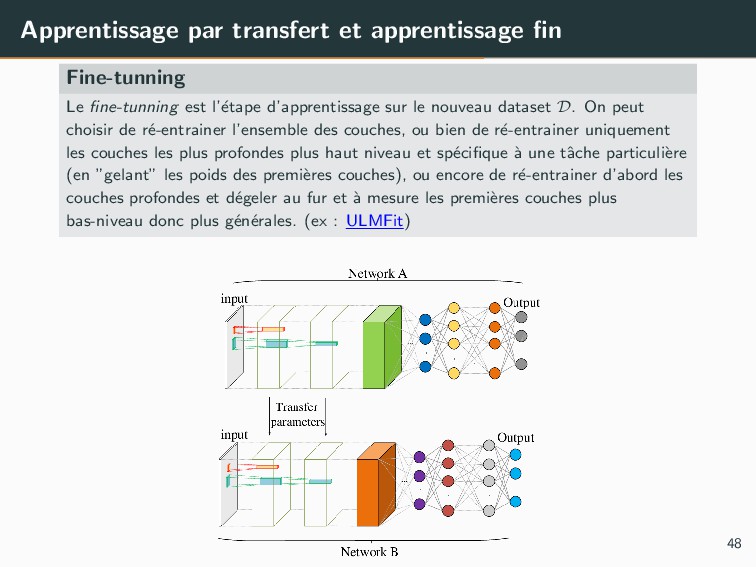{kind=link}
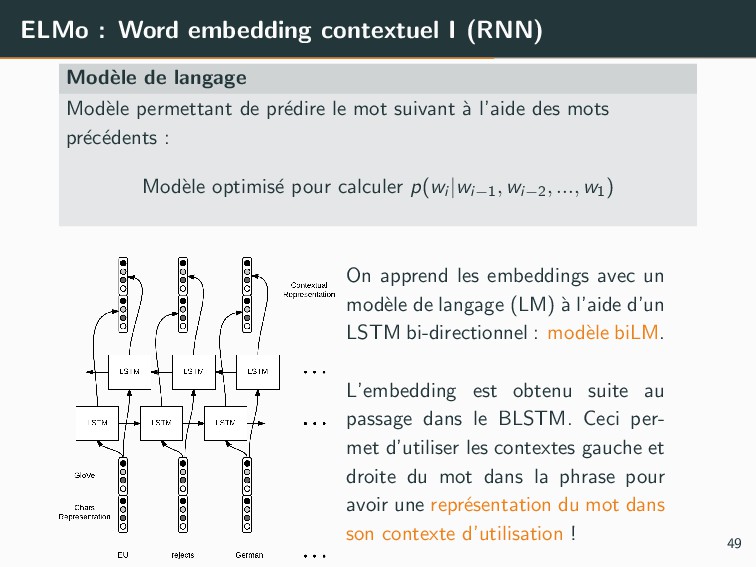{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}