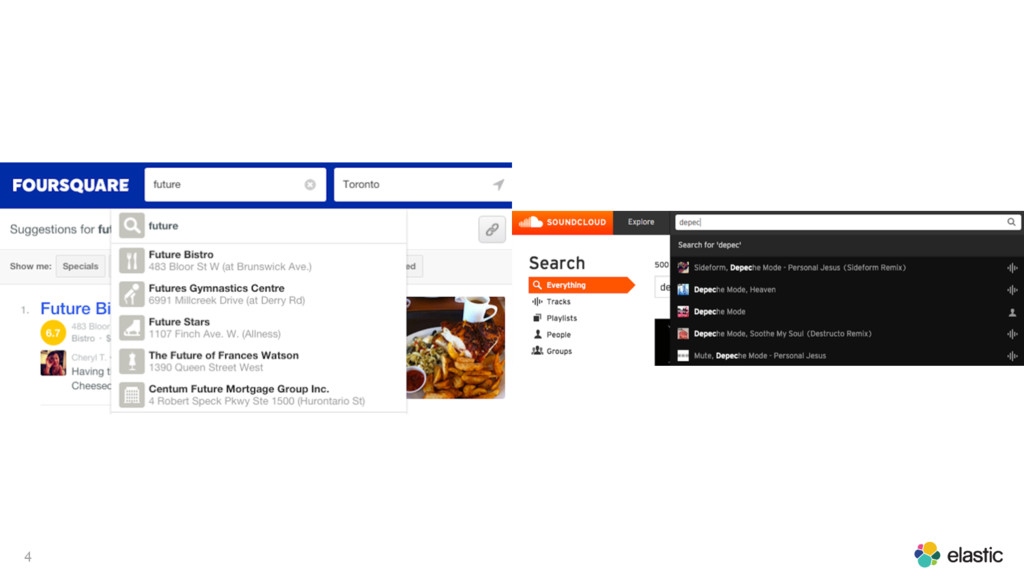
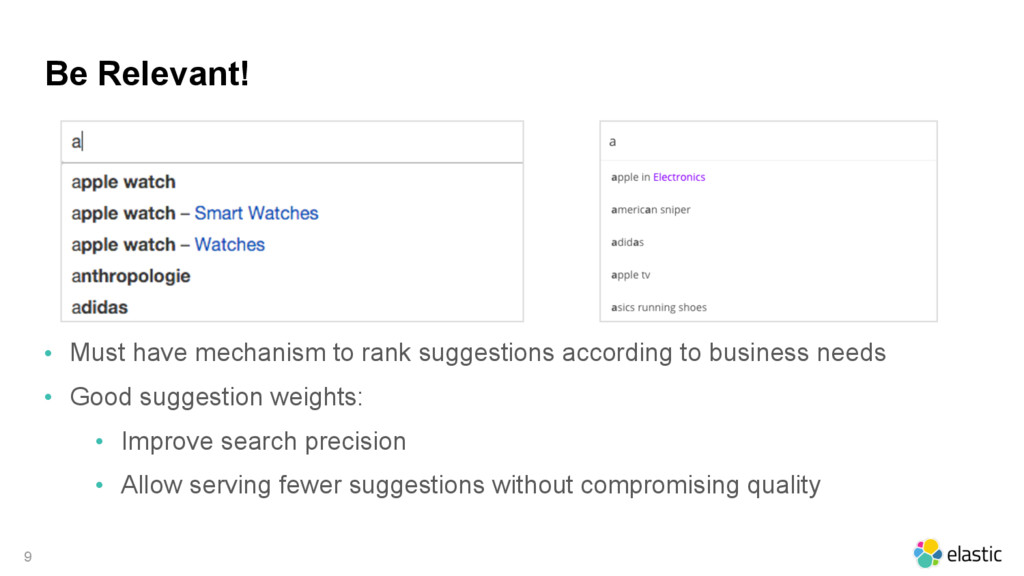
Autocomplete is a key feature of search applications. Good autocomplete solutions get users to the right content in a few keystrokes while bad ones frustrate and confuse. This talk will explore technical considerations in designing such systems, what Elasticsearch has to offer, and what’s to come next.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}