Learn how Blizzard Entertainment -- makers of Overwatch and World of Warcraft -- leverages Elasticsearch, Kibana, Logstash, Kafka, tribes, and Node.js to generate actionable value from gamer and server events.
Chris Burkhart l Technical Lead, Data Team l Blizzard Entertainment
Jordan Irwin l Technical Lead, Battle.net Engineering Systems l Blizzard Entertainment
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
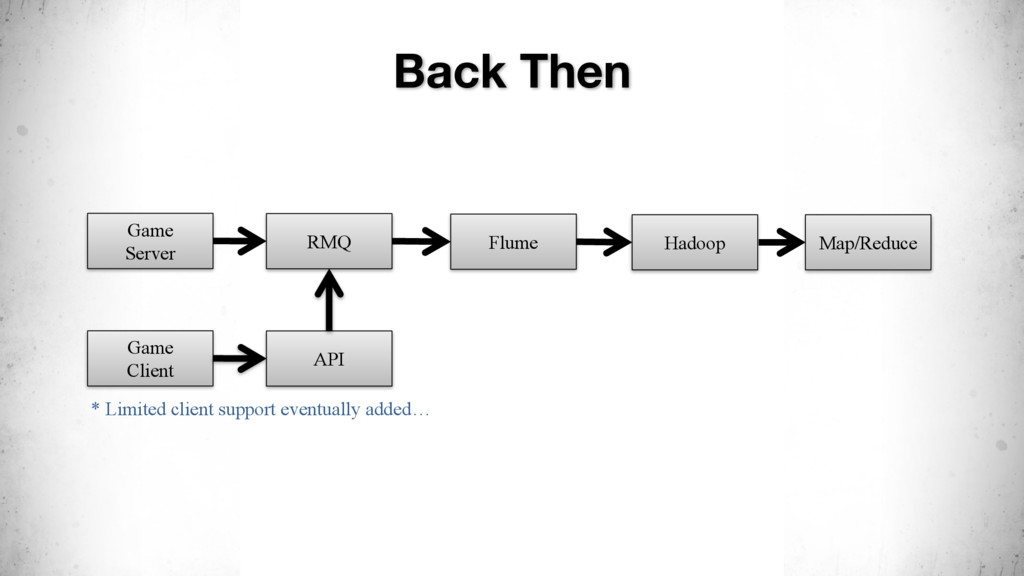{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
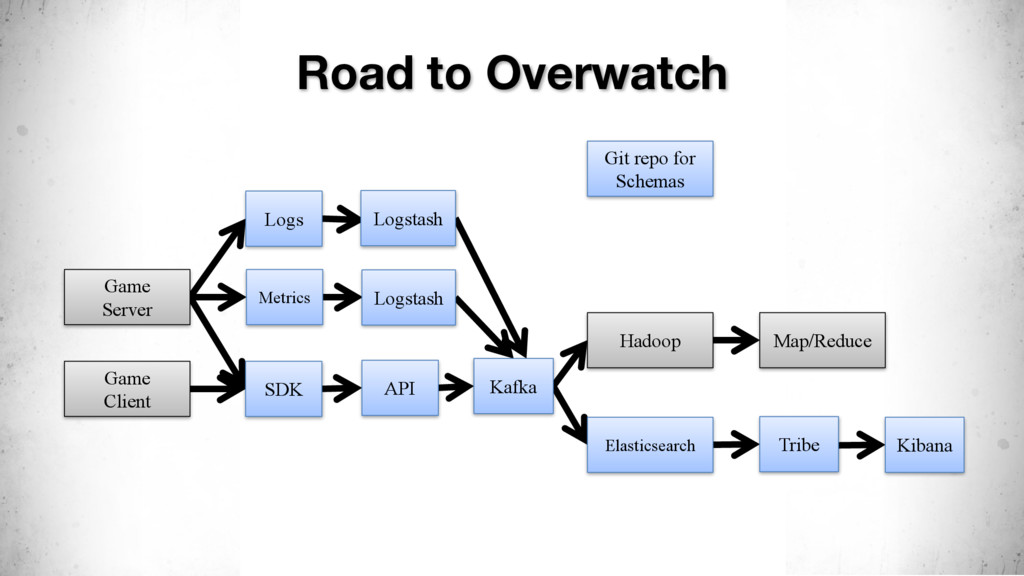{kind=link}
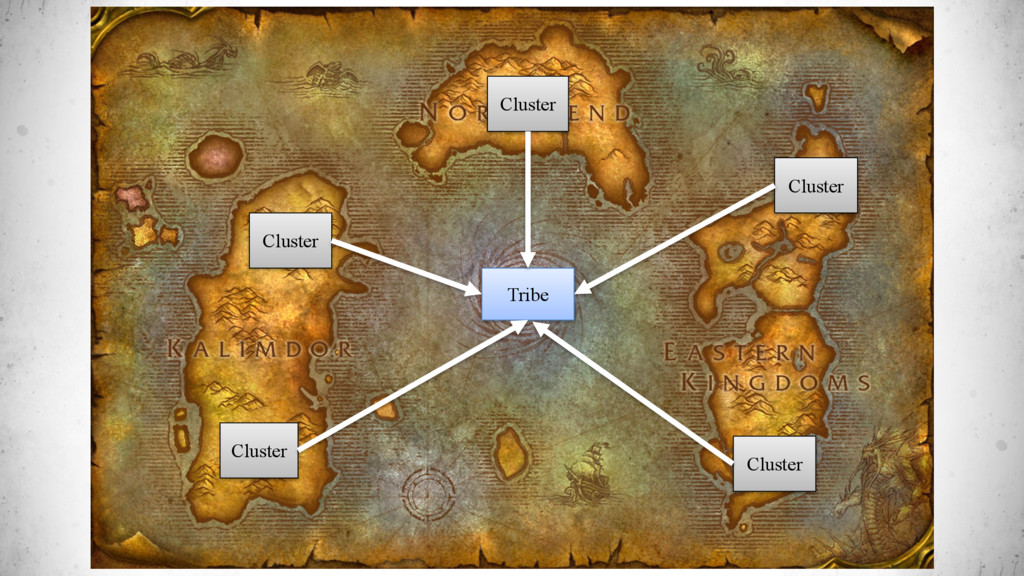{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
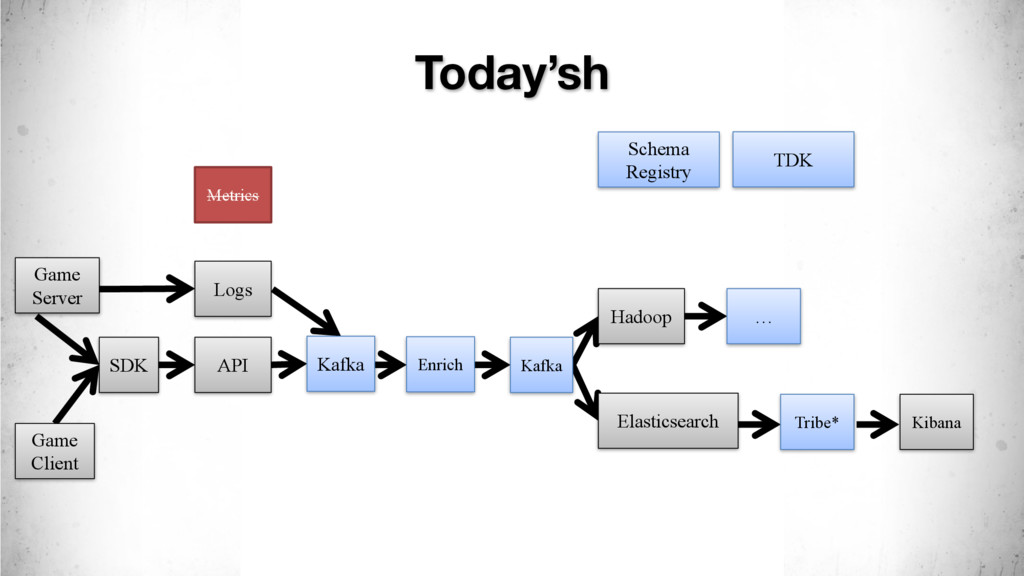{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}