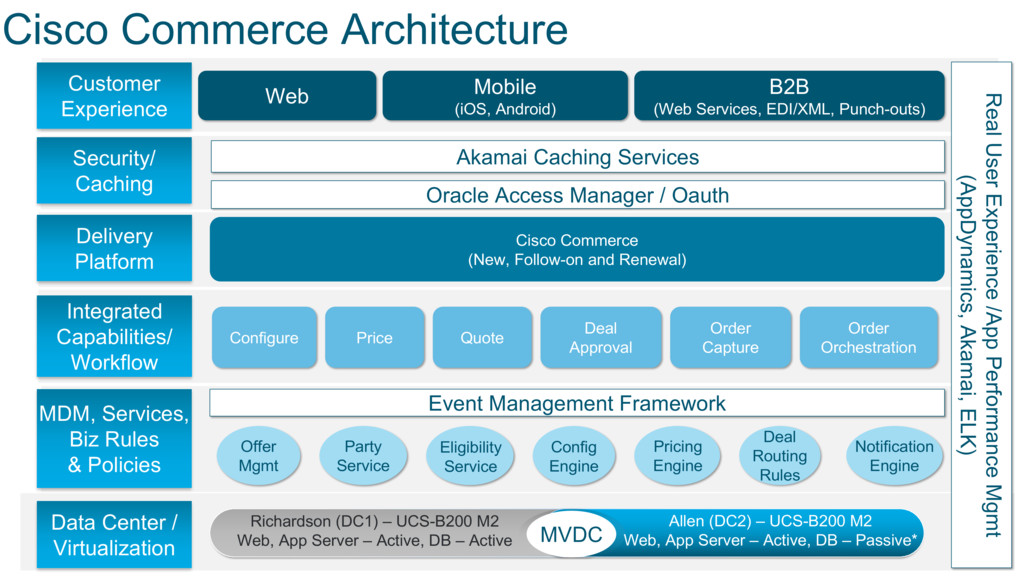
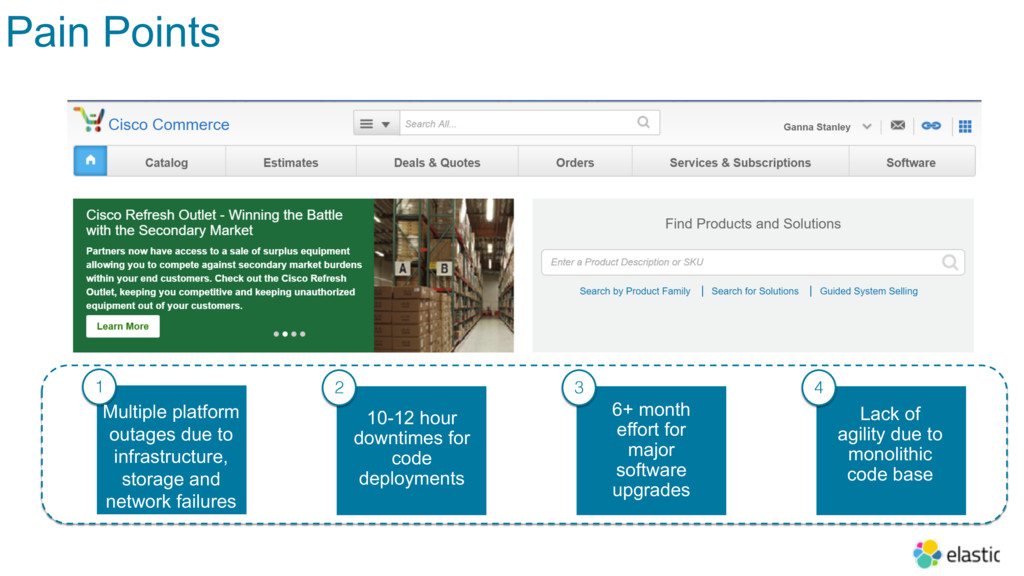
Cisco’s Commerce Platform, a suite of 35 applications and 300+ services, powers product configuration, pricing, quoting, export compliance, credit checks, and order booking across all Cisco product lines. With a high average financial value of each transaction, the Platform is a critical part of Cisco’s business.
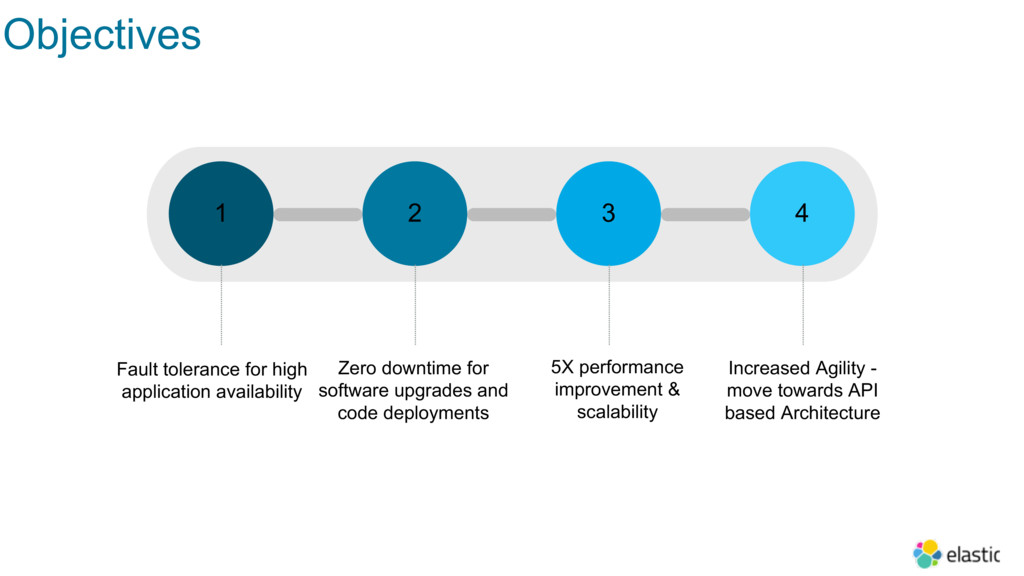
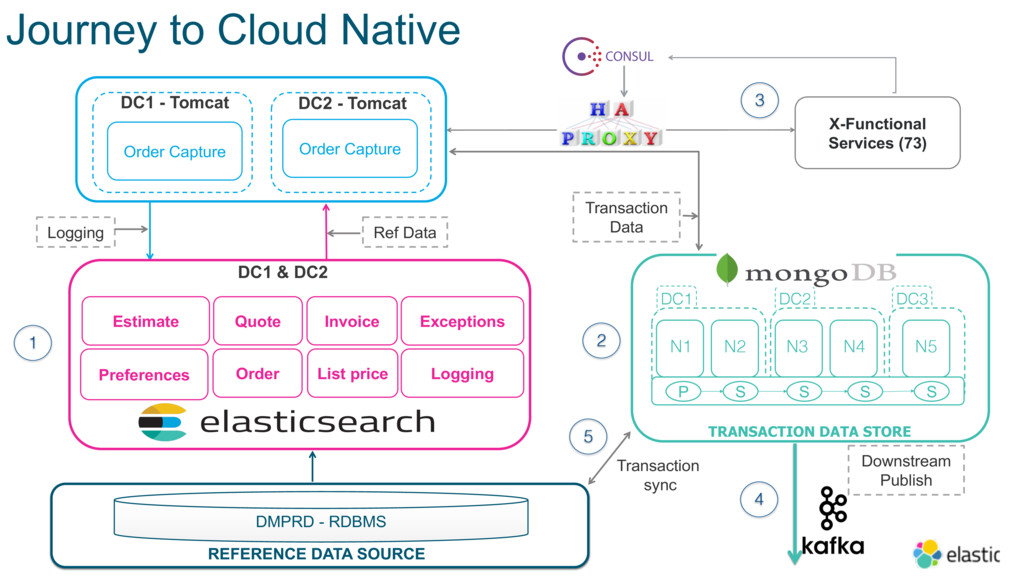
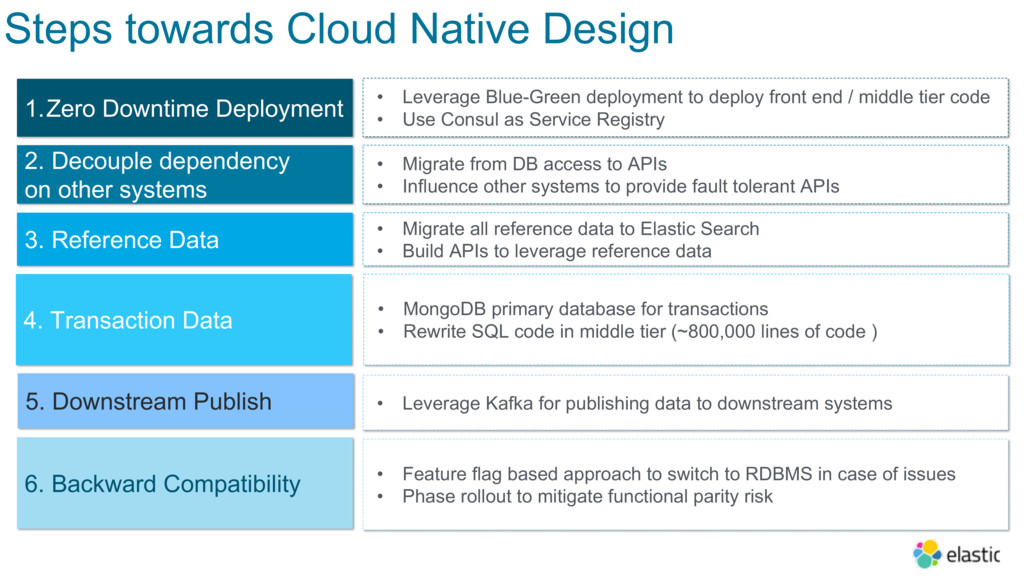
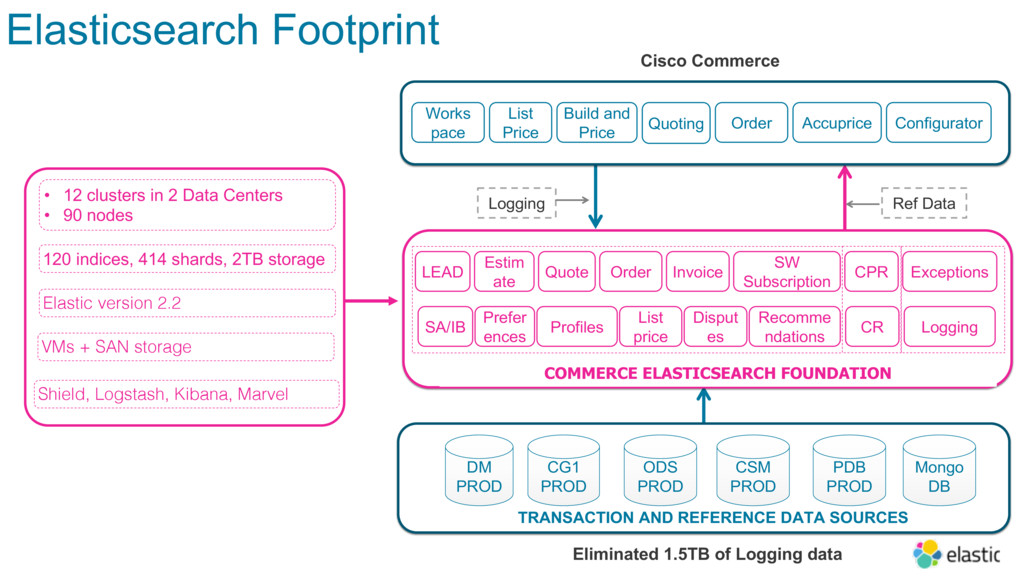
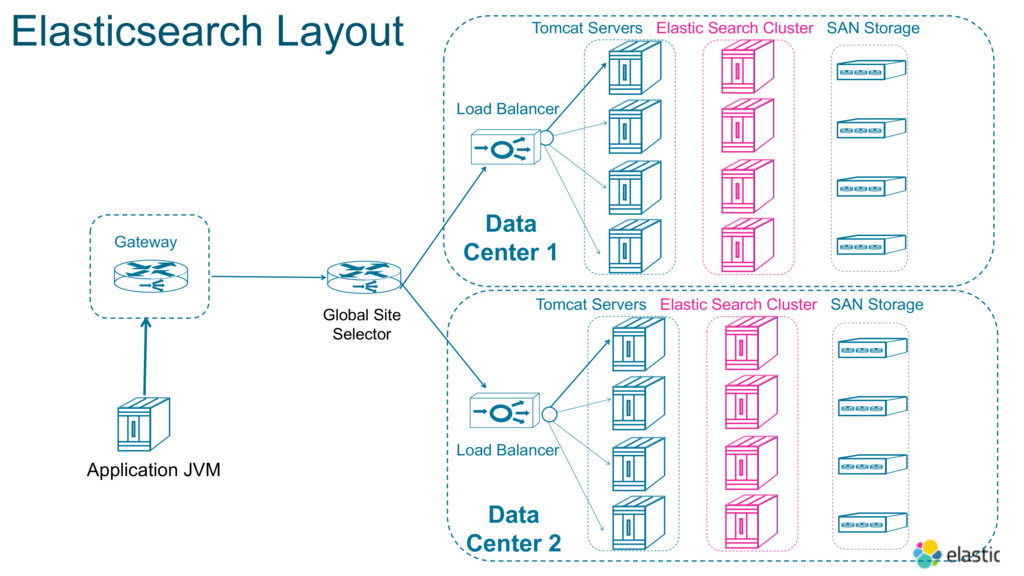
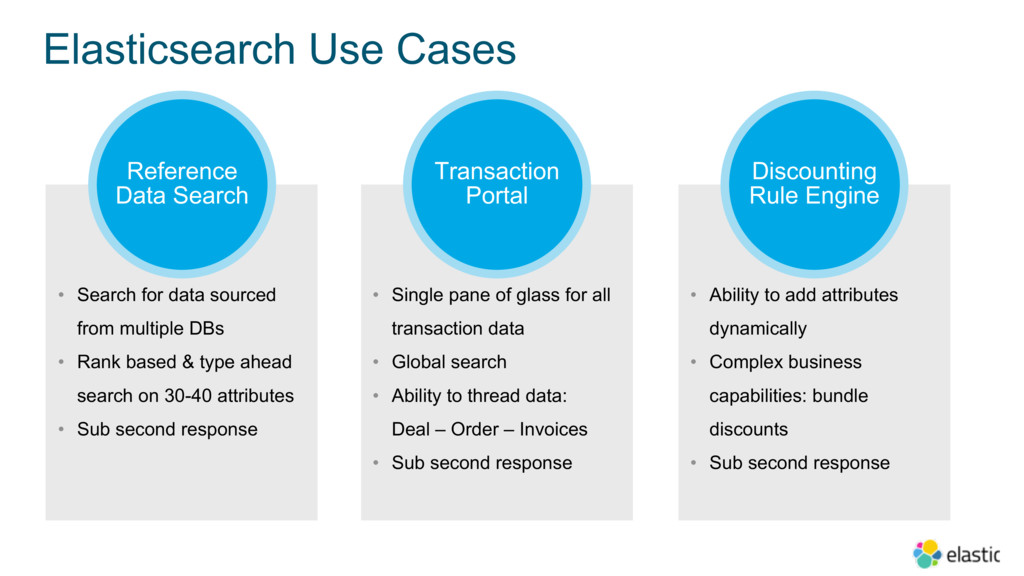
In order to improve customer experience and business agility, Cisco decided to transition the Platform to cloud-native technologies, starting with modernizing the underlying database layer. In this session, Dharmesh will share details around how they’ve implemented a 180+ node Elasticsearch deployment to query reference data, and are now experiencing significant resiliency advantages and zero downtime deployment and performance.
Dharmesh Panchmatia l Director, IT l Cisco
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}