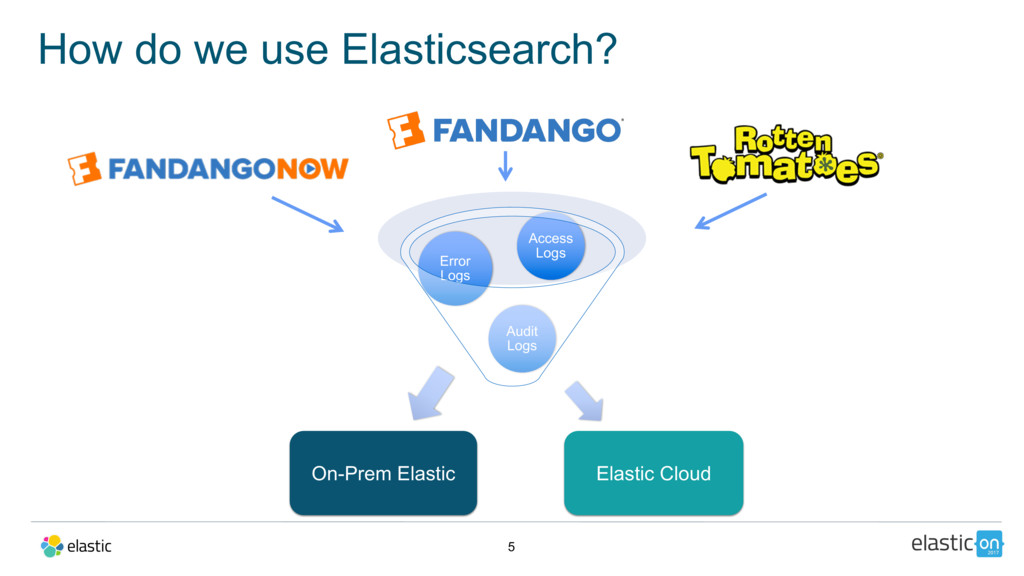
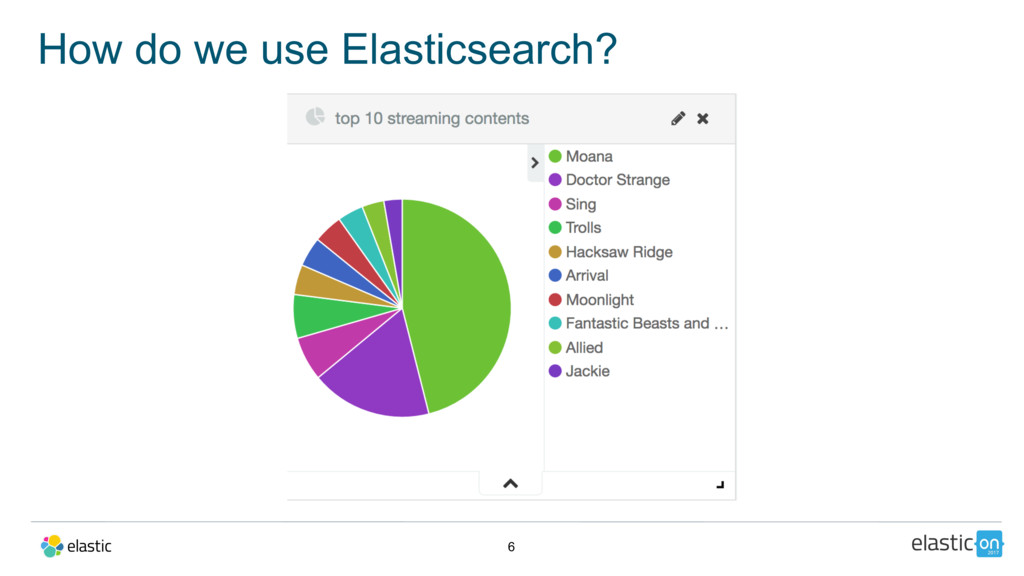
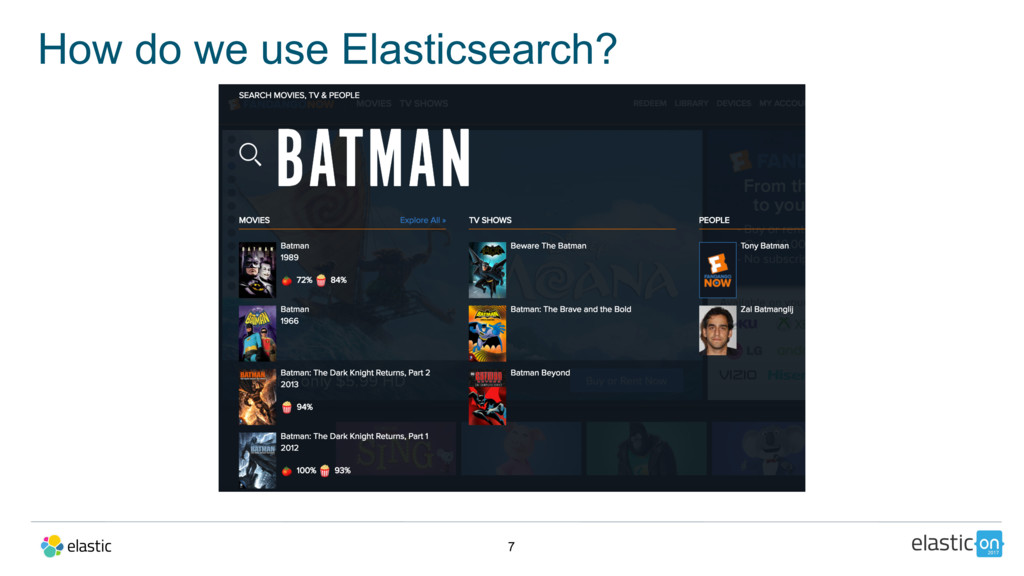
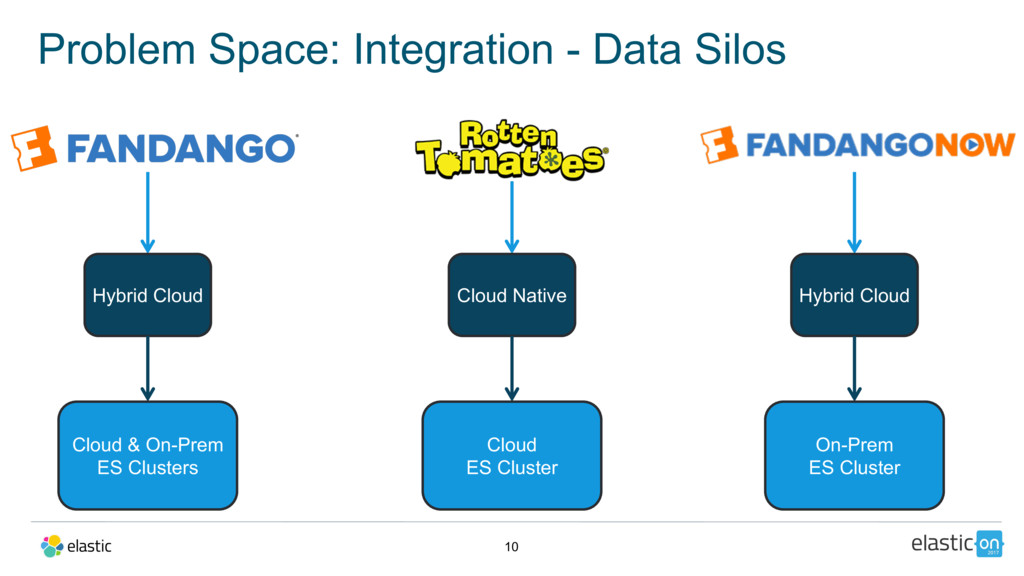
Every month, more than 60 million people visit Fandango’s website to browse movie tickets as well as rent or buy TV and movie content. In order to best understand the effectiveness of their outbound marketing and offer campaigns, Fandango deployed the Elastic Stack to monitor and analyze over 5 billion web logs monthly.
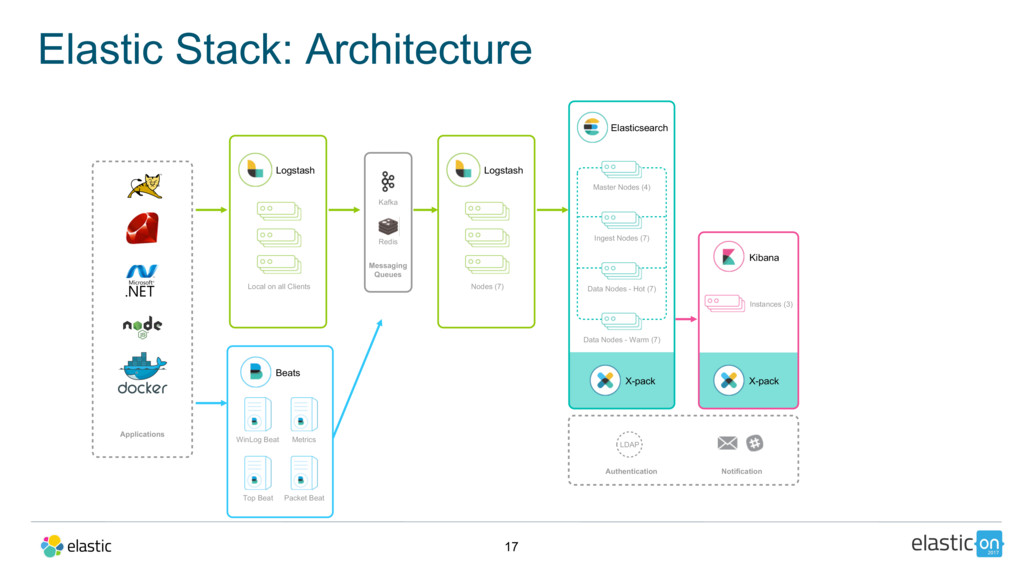
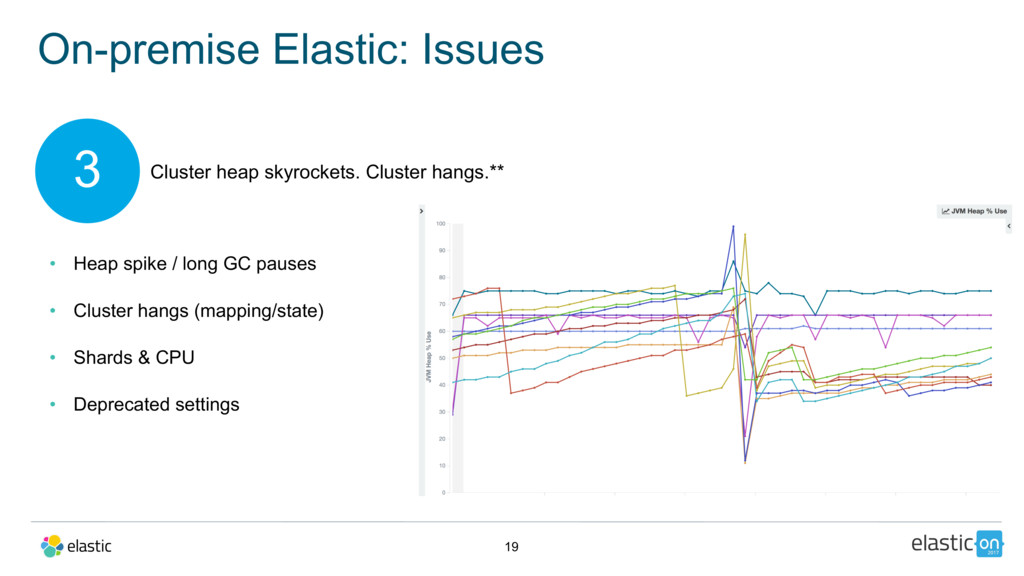
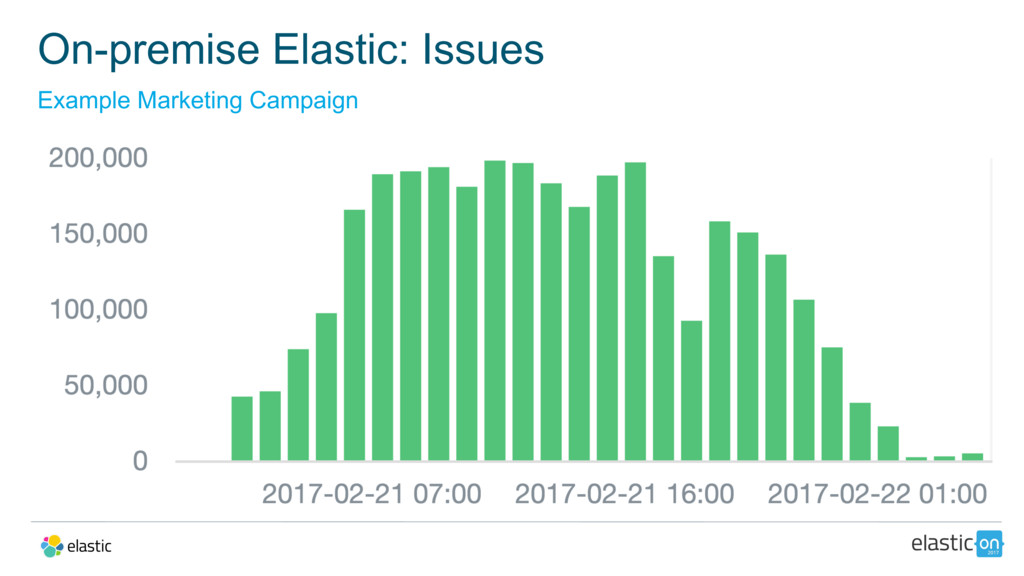
In this talk, Adam will walk you through how, in one weekend, the team at FandangoNOW redesigned and re-architected their prior on-premise deployment onto Elastic Cloud in order to hit their launch date. He’ll cover their lessons learned and the journey scaling up to analyzing up to 500 million records per day.
Adam Kane l Director of Engineering l Fandango
Jason Rojas l Sr. Manager, Engineering Effectiveness l Fandango
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
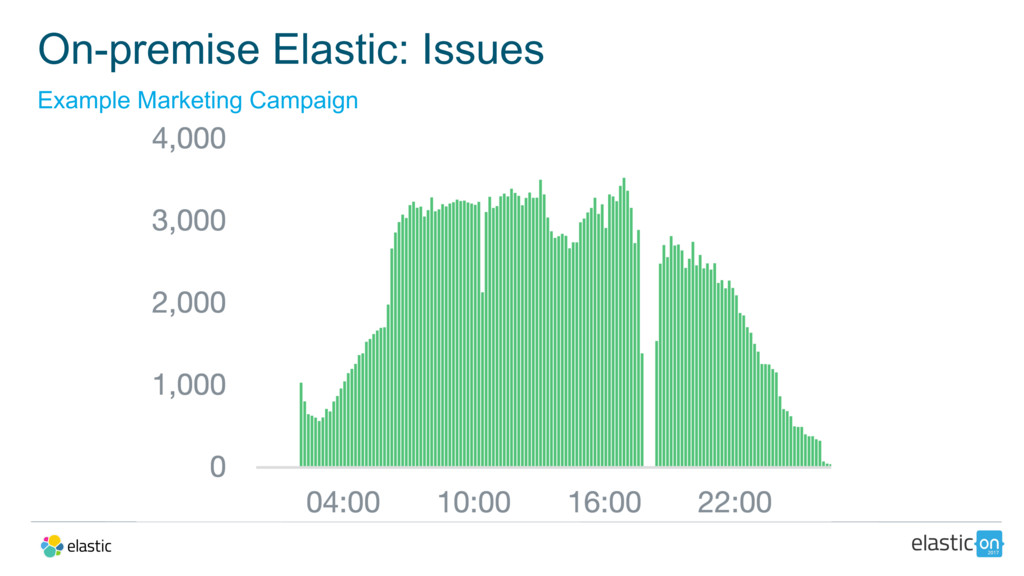{kind=link}
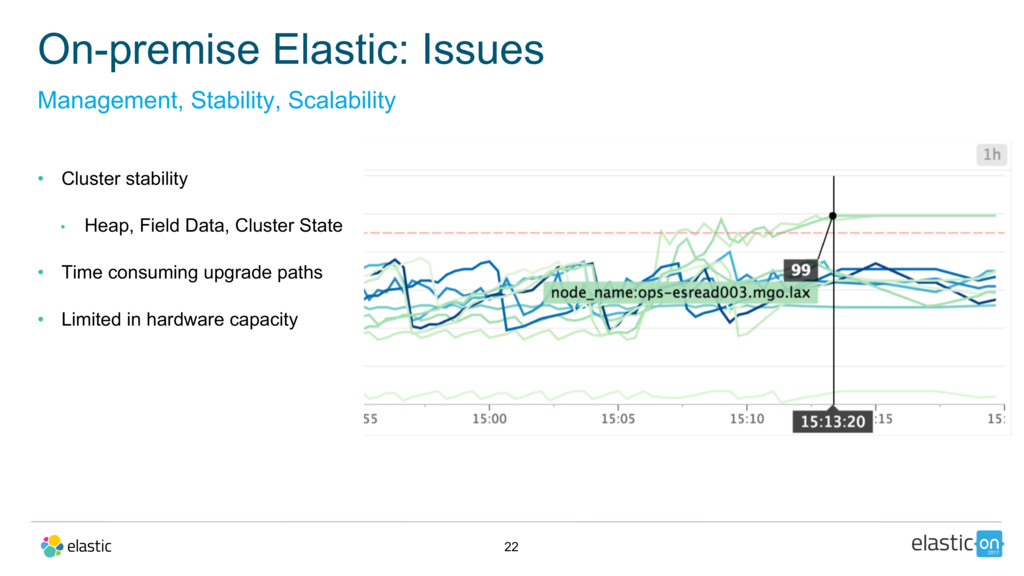{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
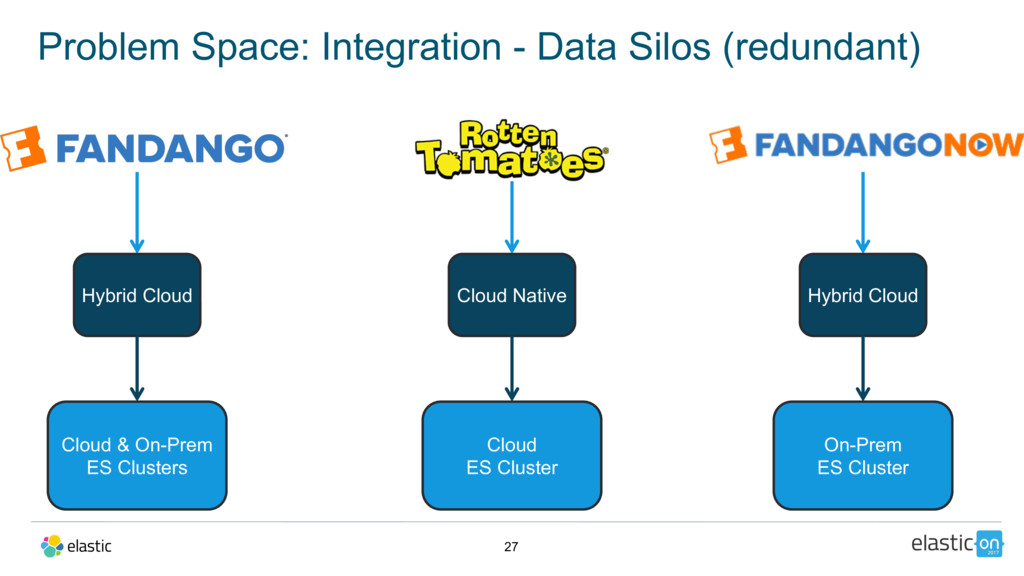{kind=link}
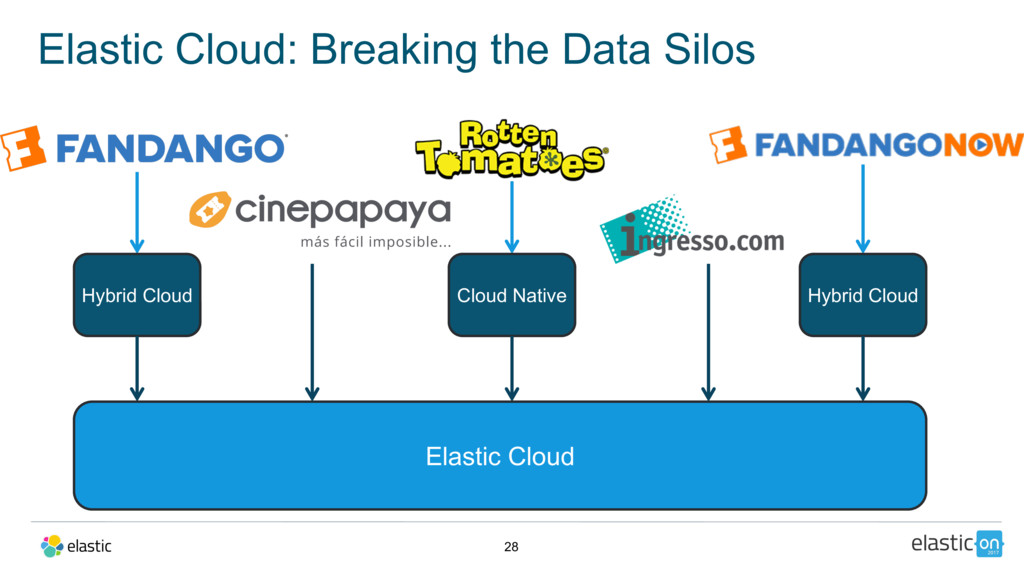{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}