Let’s talk about search improvements coming soon to an Elasticsearch near you!
Range Fields:
Want to create a global television guide to find broadcasts airing during certain time periods? Thanks to recent advancements in Lucene this desire is now a reality.
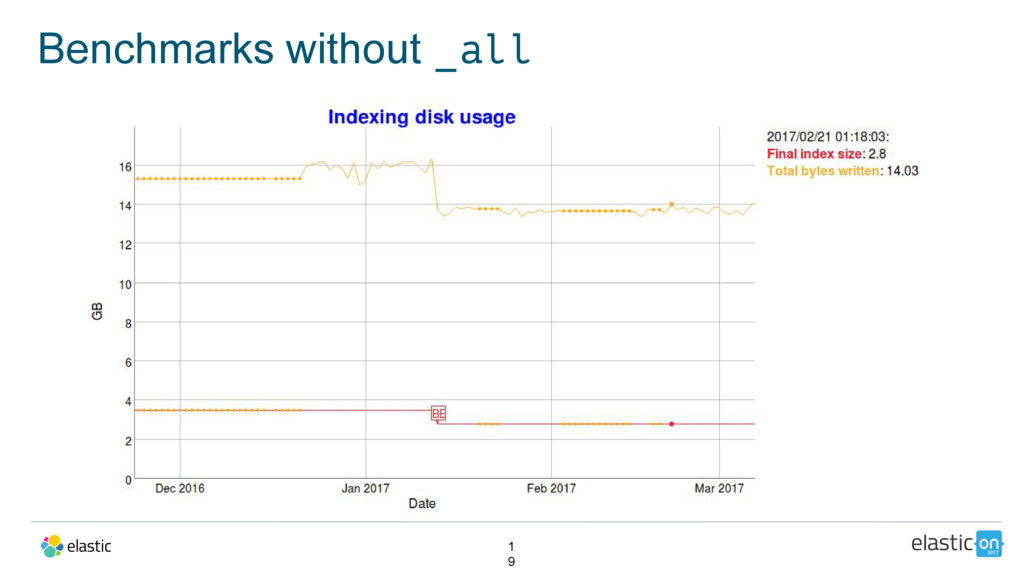
Removing the _all field:
The _all field can be either a boon or a burden. Come hear about why the _all field is going away and what it’s being replaced with!
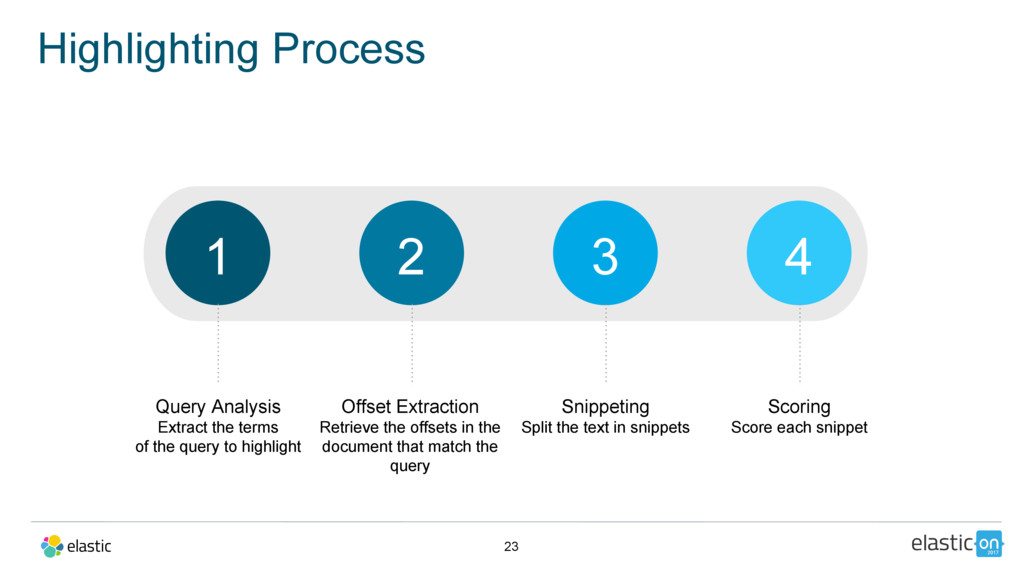
Unified Highlighter:
Starting in 5.3, a fourth highlighter called `unified` is available in Elasticsearch.
This highlighter has landed from Lucene with a goal in mind: he wants to rule them all ! We’ll see how and why this highlighter can advantageously replace your highlighter of choice.
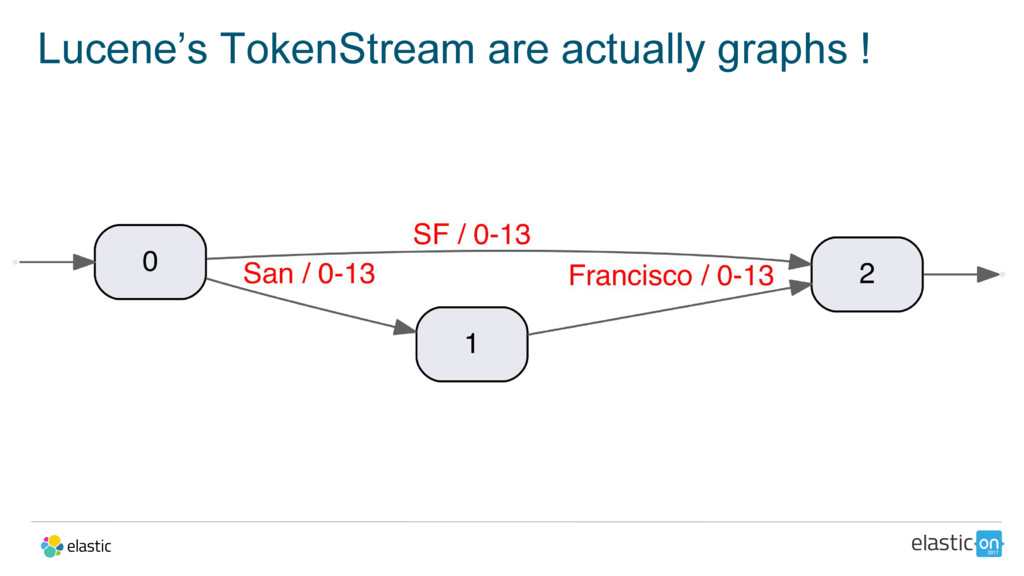
The Synonym Graph Filter:
Multi-term synonyms have long been buggy in Lucene and Elasticsearch, but this issue is now fixed thanks to the addition of the new synonym_graph token filter, along with support for graph token streams in query parsers.
Jim Ferenczi l Software Engineer l Elastic
Lee Hinman l Software Engineer l Elastic
Nick Knize l Geospatial Software Engineer l Elastic
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}