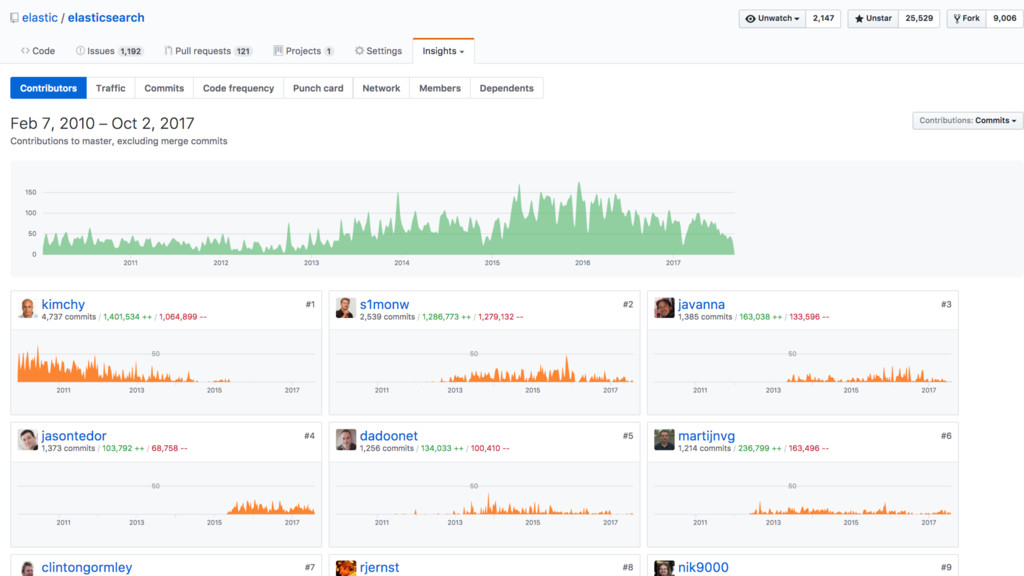
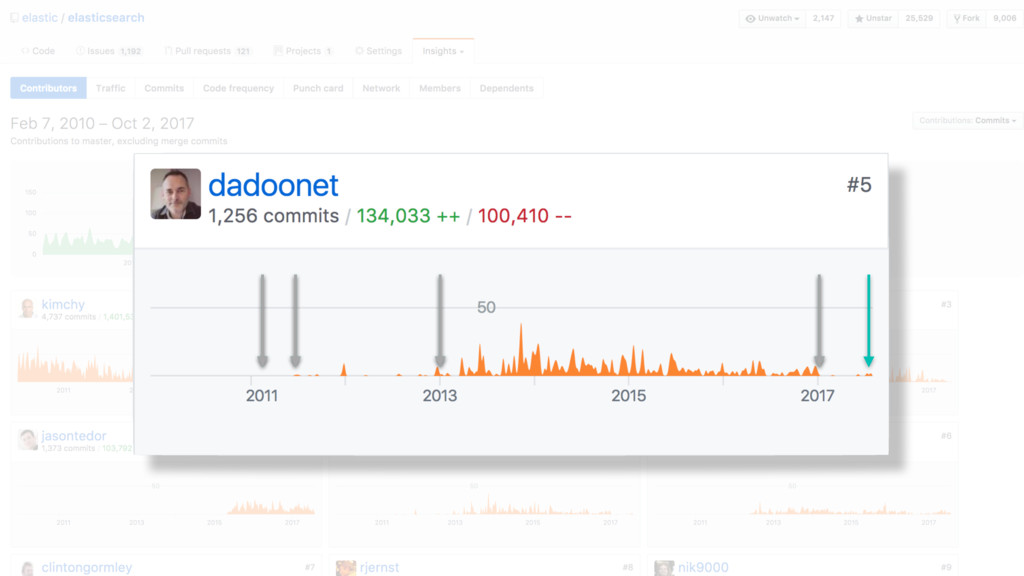
Surveiller une application complexe n'est pas une tâche aisée, mais avec les bons outils, ce n'est pas si sorcier. Néanmoins, des périodes fortes telles que les opérations de type "Black Friday" (Vendredi noir) ou période de Noël peuvent pousser votre application aux limites de ce qu'elle peut supporter, ou pire, la faire crasher. Parce que le système est fortement sollicité, il génère encore davantage de logs qui peuvent également mettre à mal votre système de supervision.
Dans cette session, j'aborderai les bonnes pratiques d'utilisation de la suite Elastic pour centraliser et monitorer vos logs. Je partagerai également avec vous quelques trucs et astuces pour vous aider à passer sans souci vos Vendredis noirs !
Nous verrons :
* Les architectures de monitoring
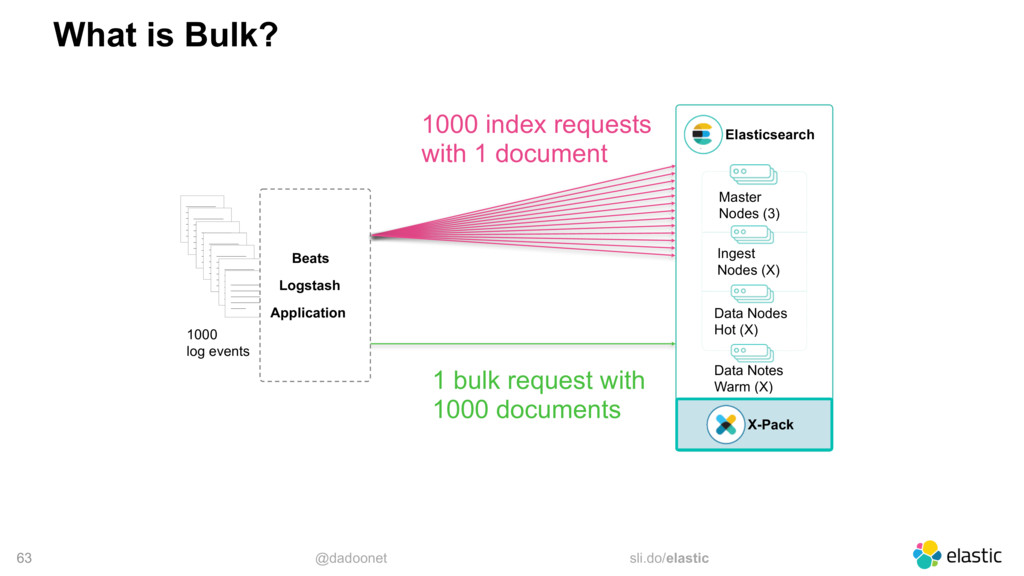
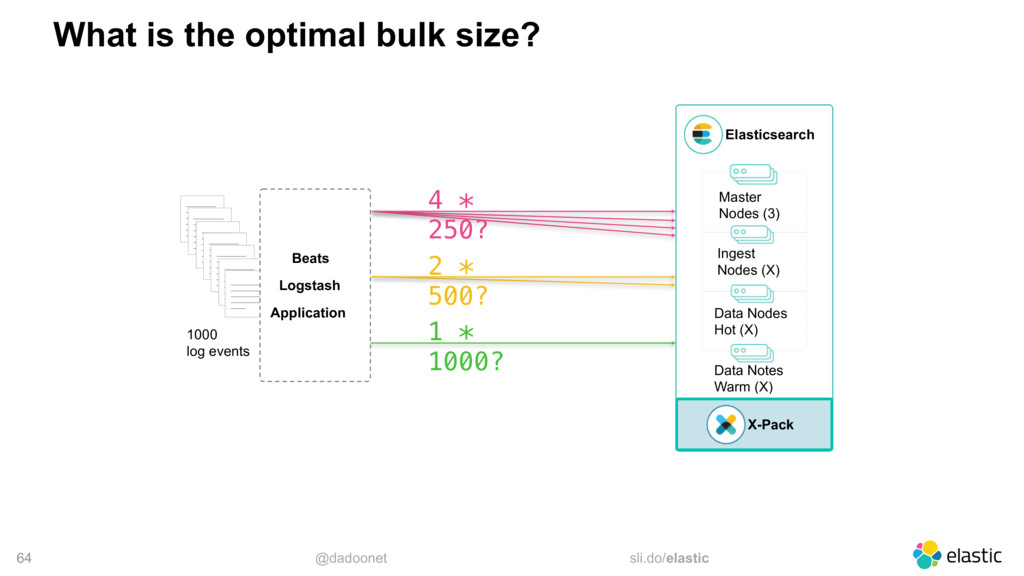
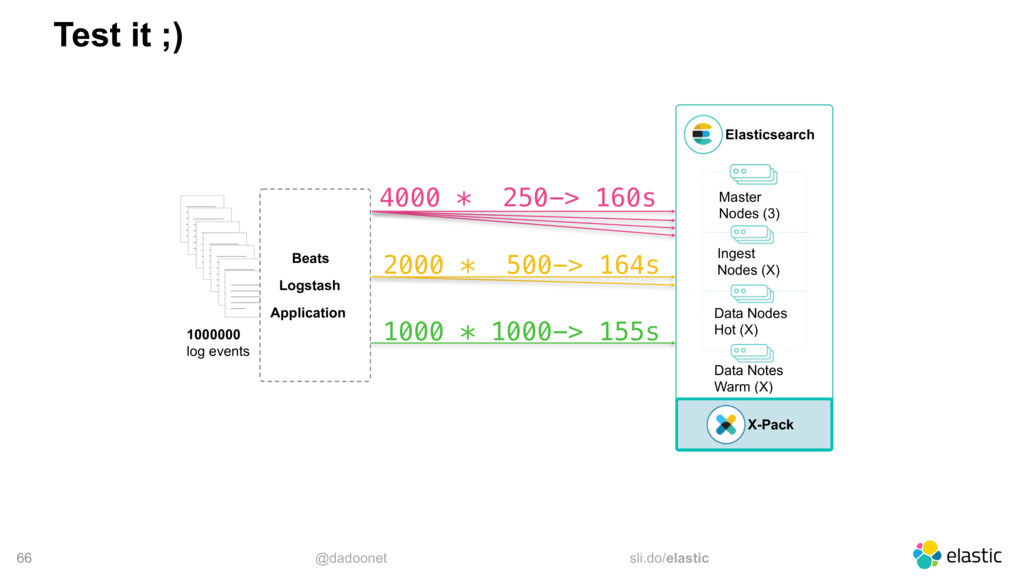
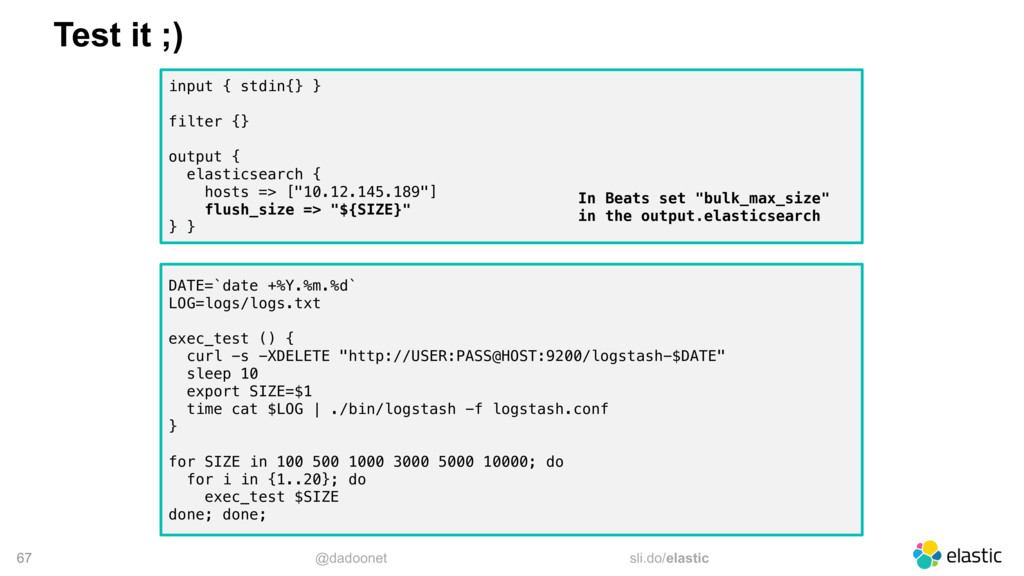
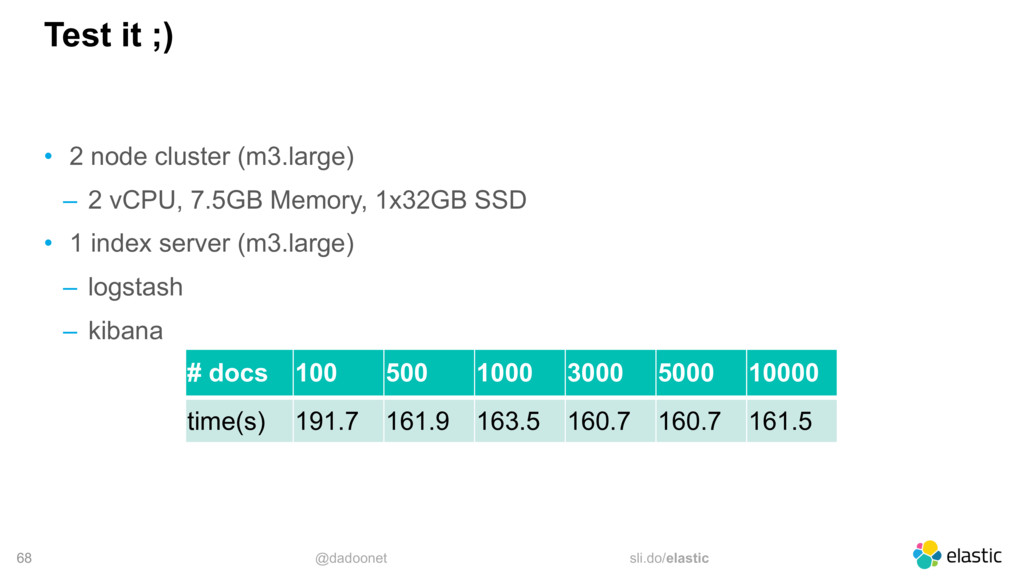
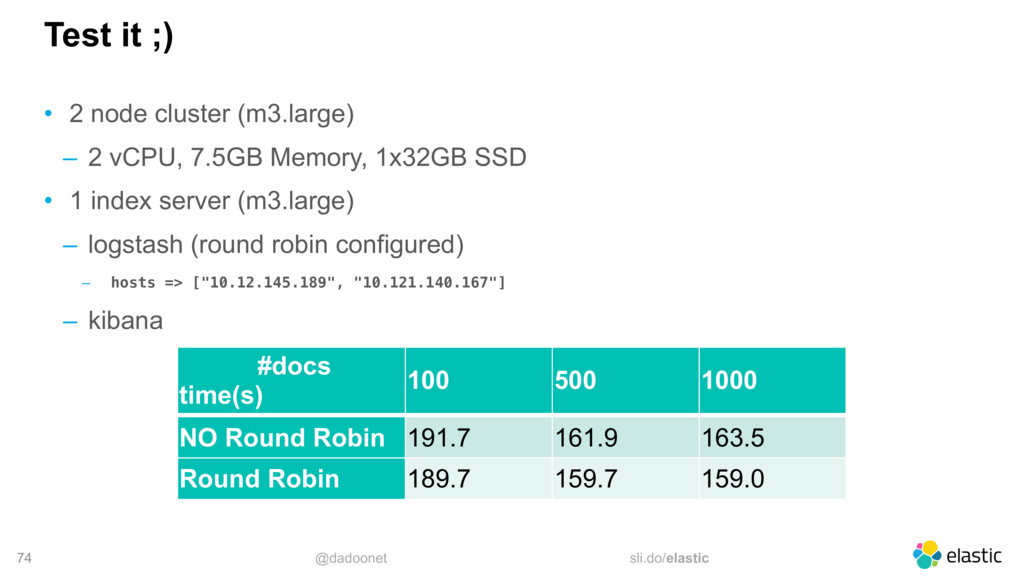
* Trouver la taille optimale pour l'API `_bulk`
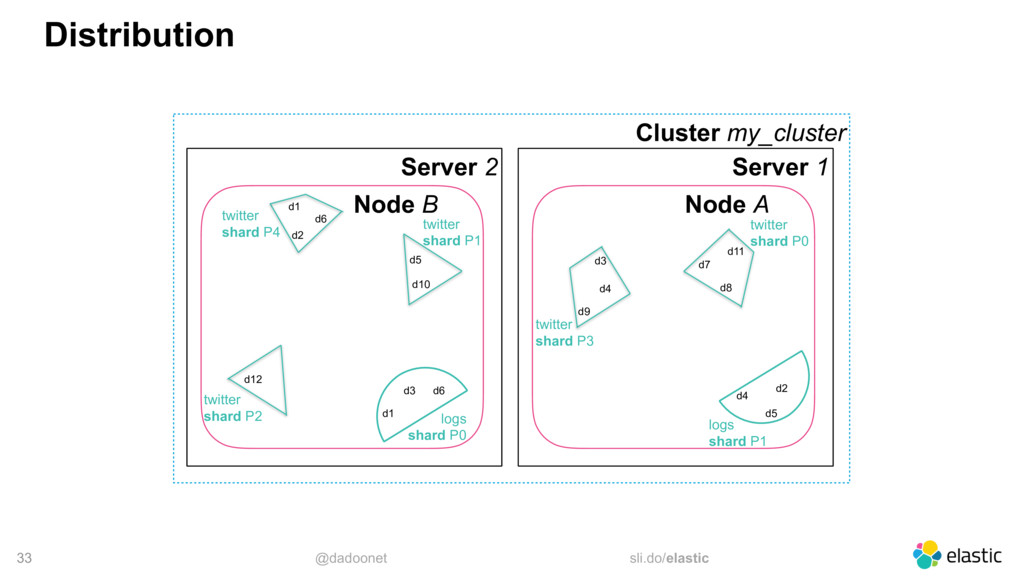
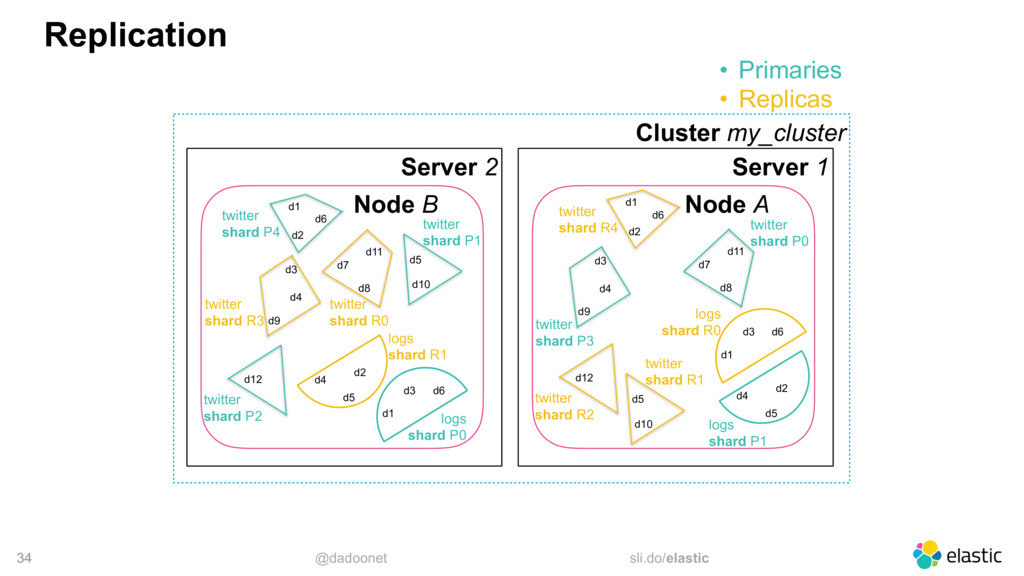
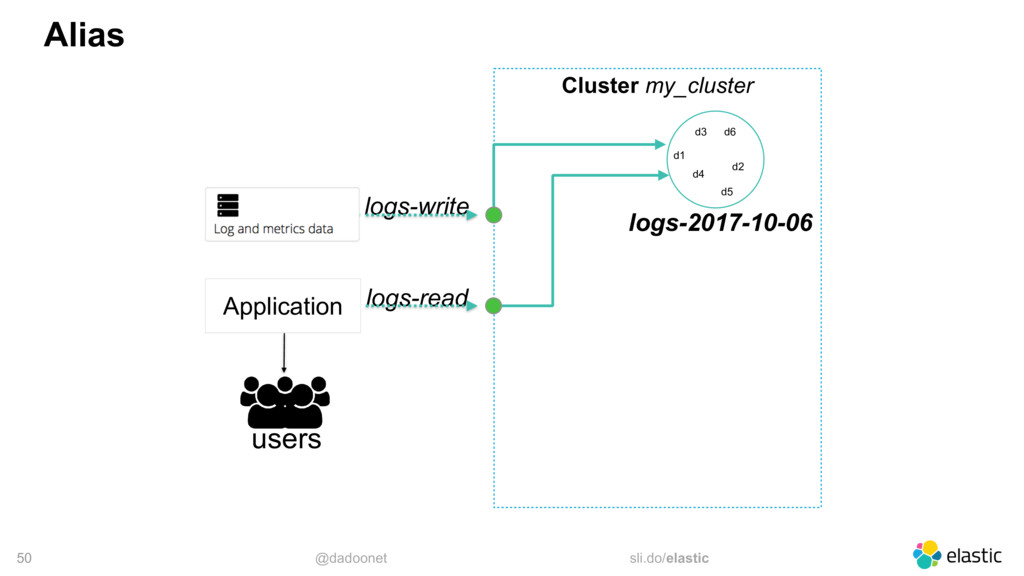
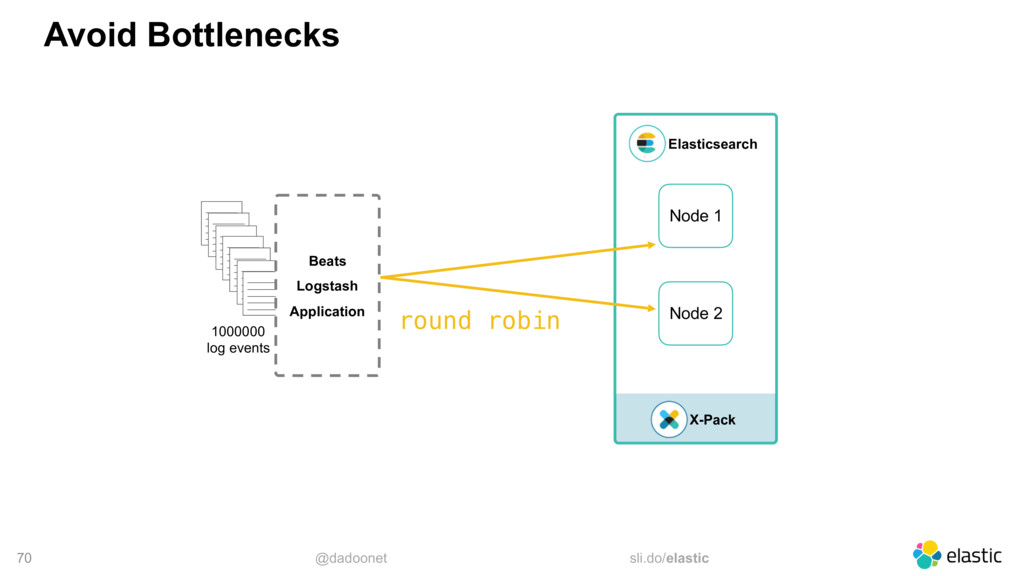
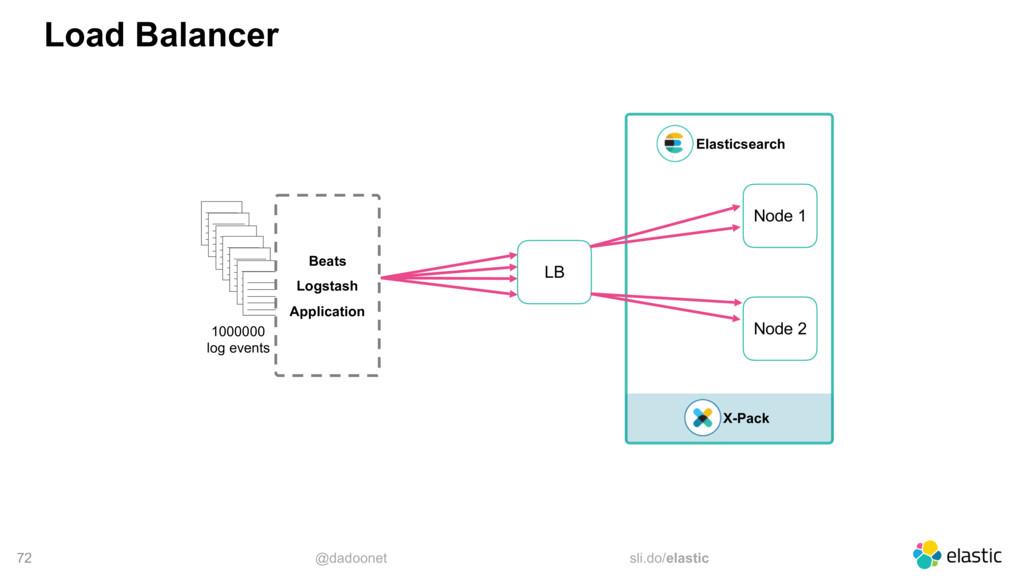
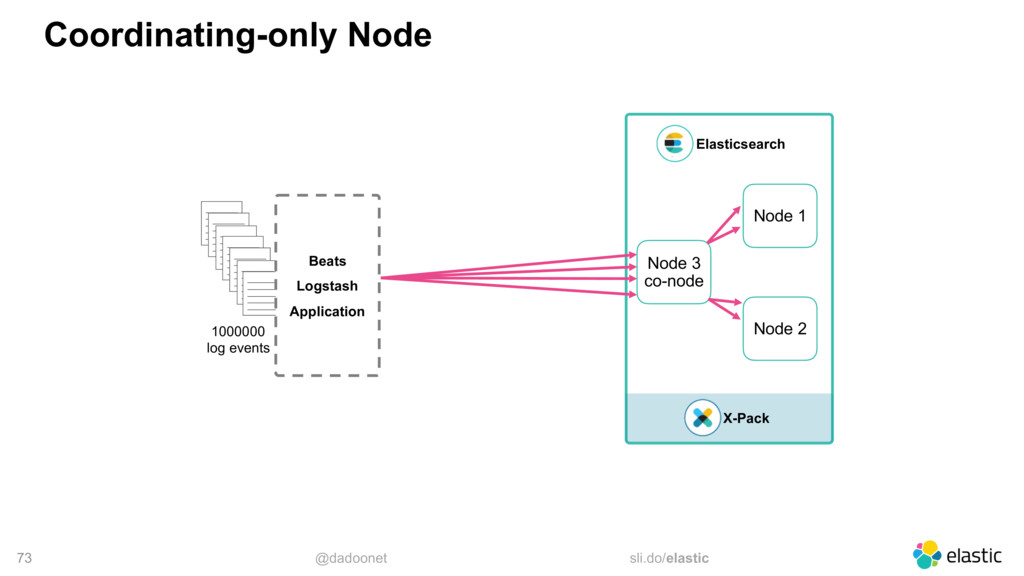
* Distribuer la charge
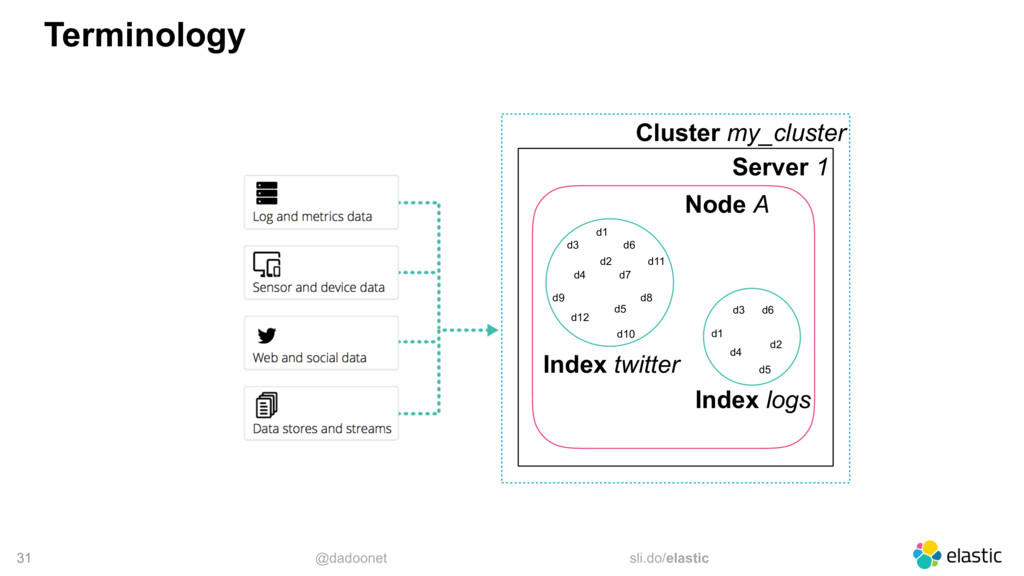
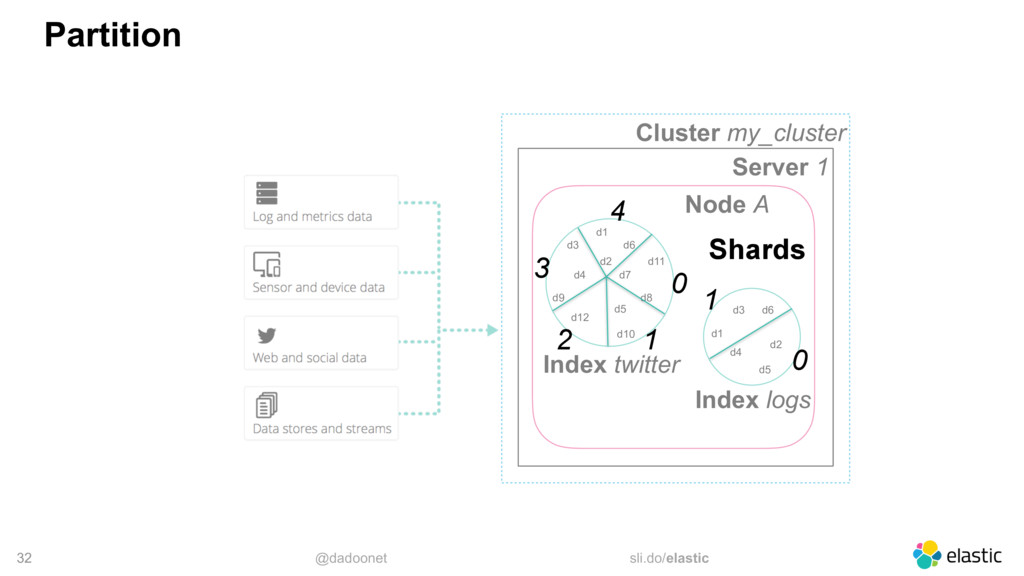
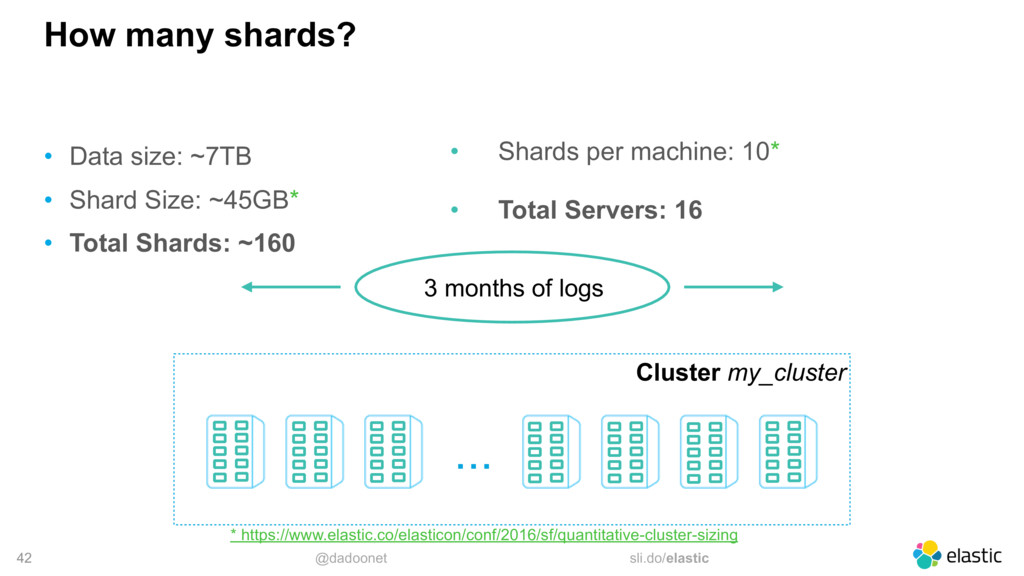
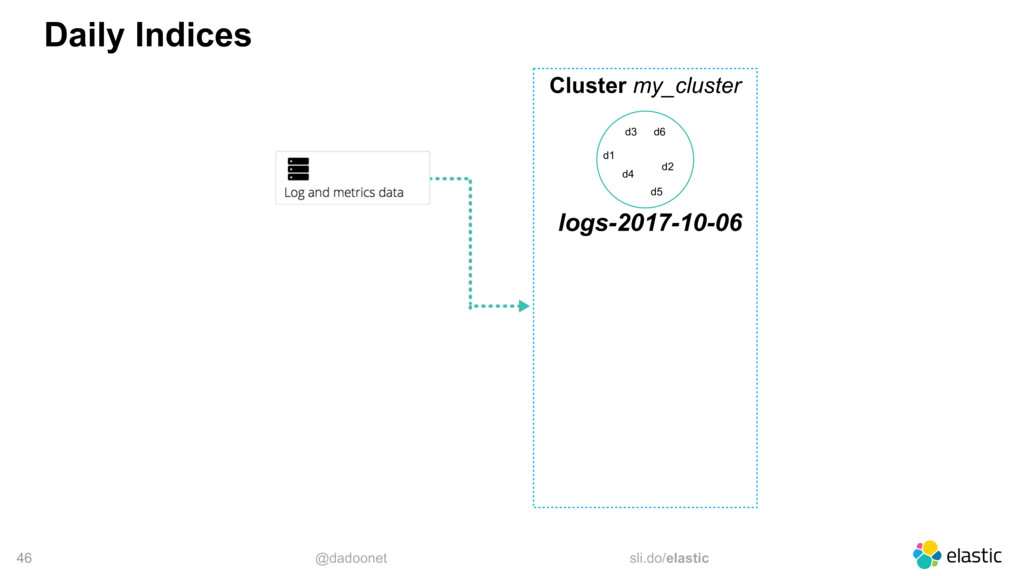
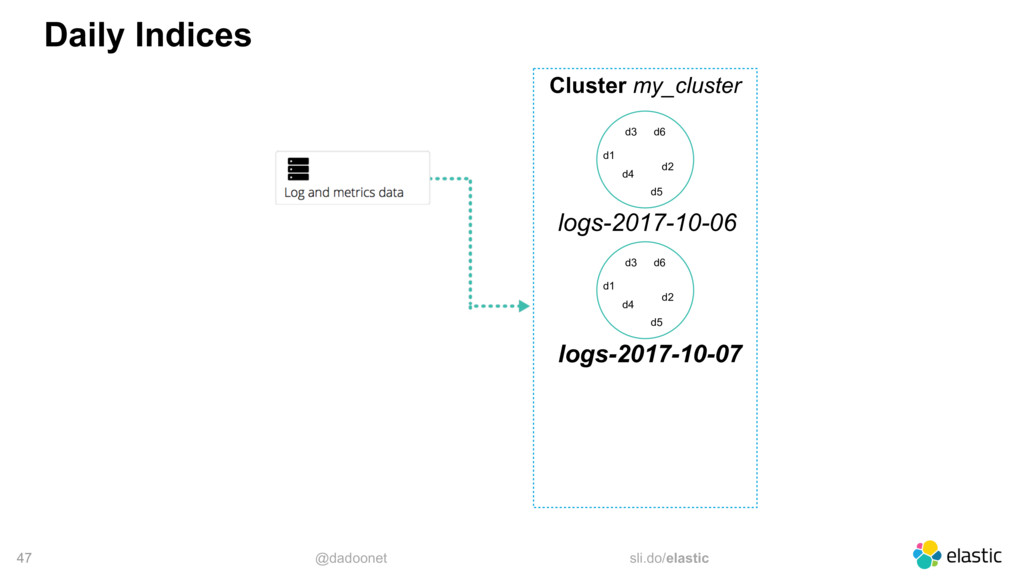
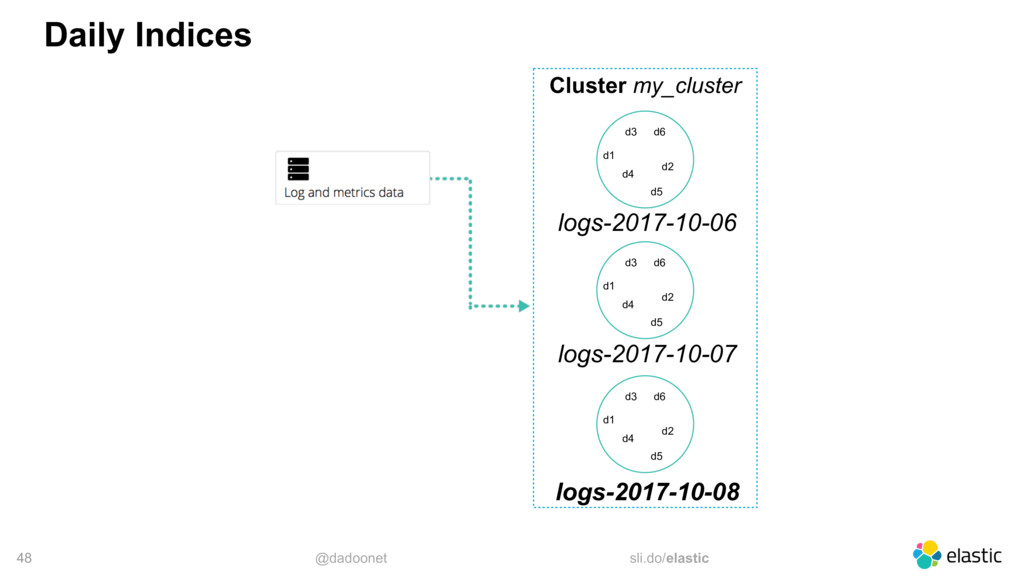
* Taille des index et des shards
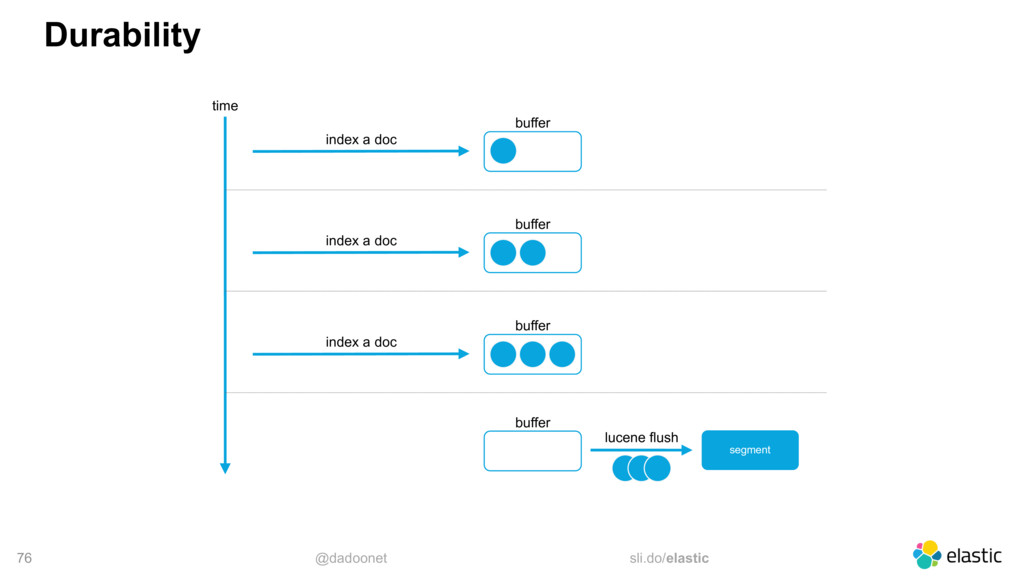
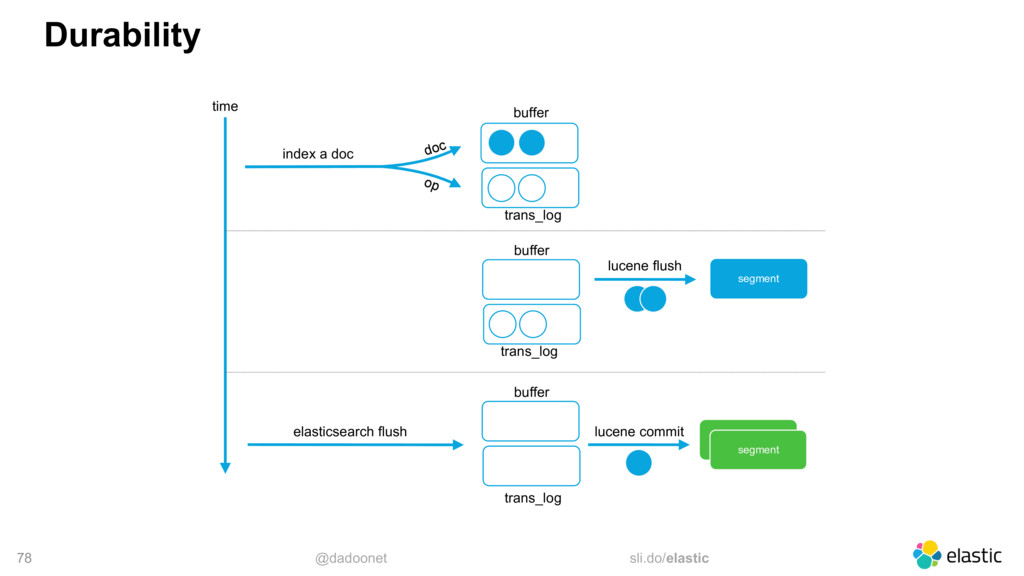
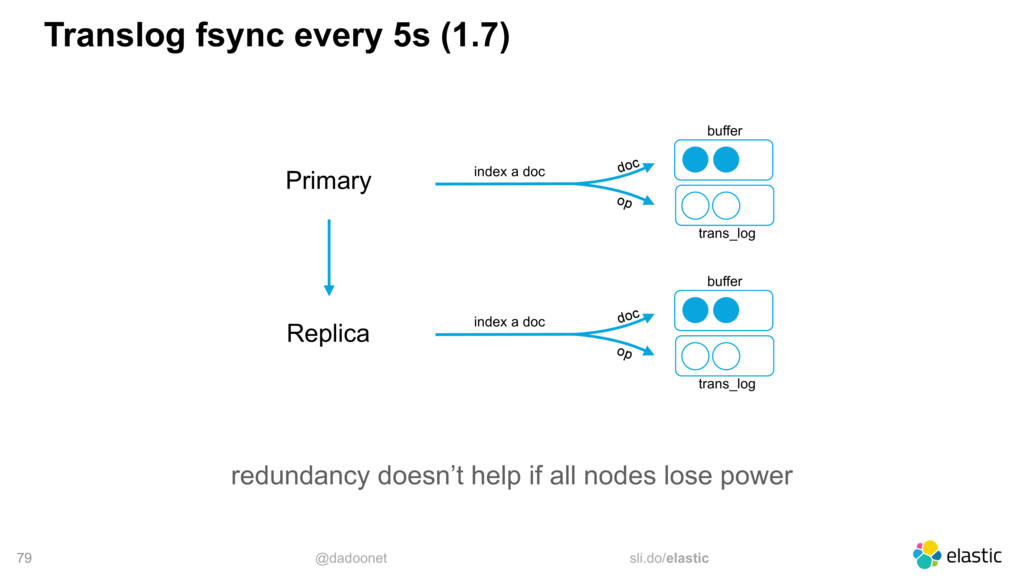
* Optimiser les E/S disque
Vous ressortirez de la session avec : des bonnes pratiques pour bâtir son système de monitoring avec la suite Elastic, le tuning avancé pour optimiser les performances d'ingestion et de recherche.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}