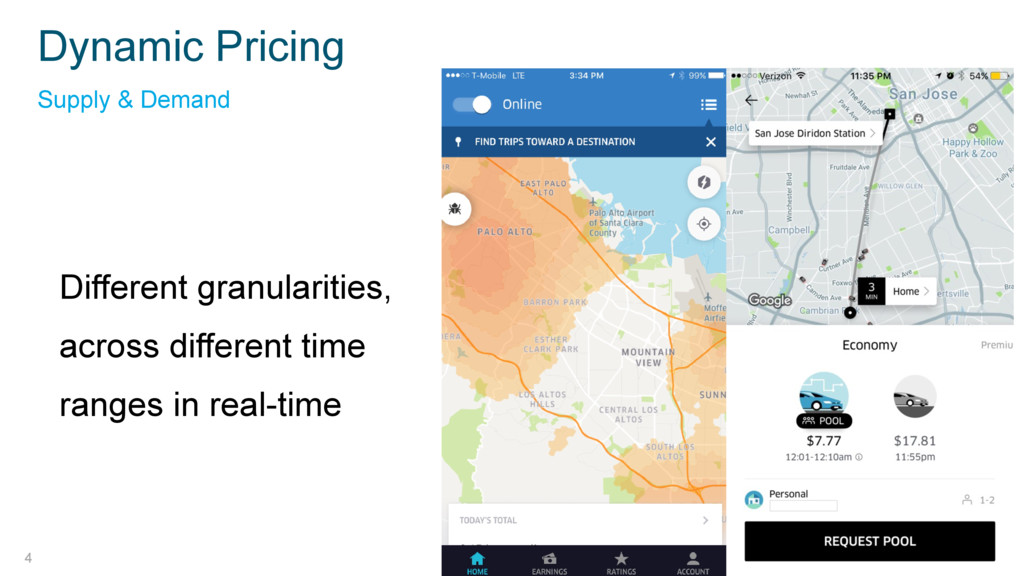
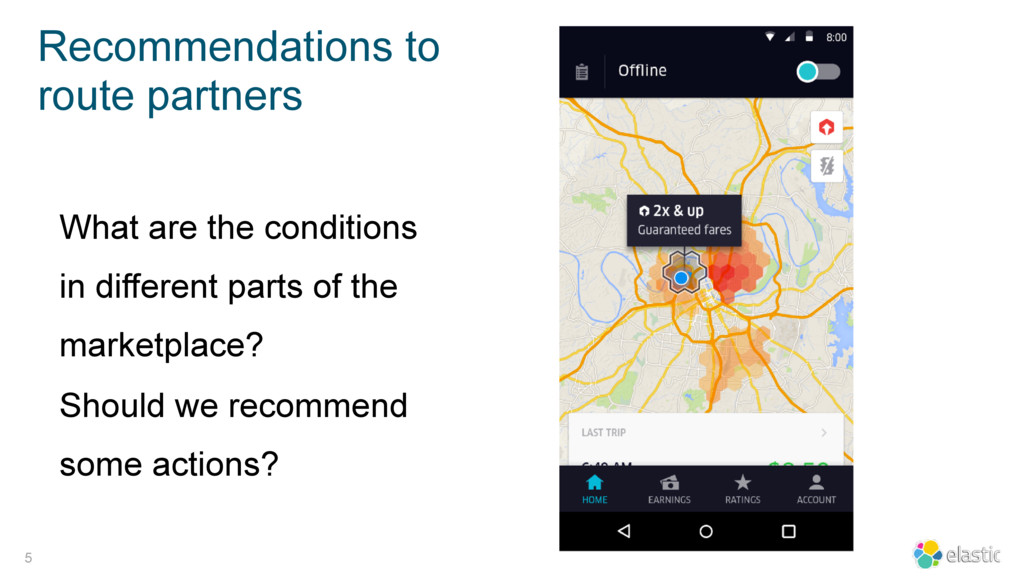
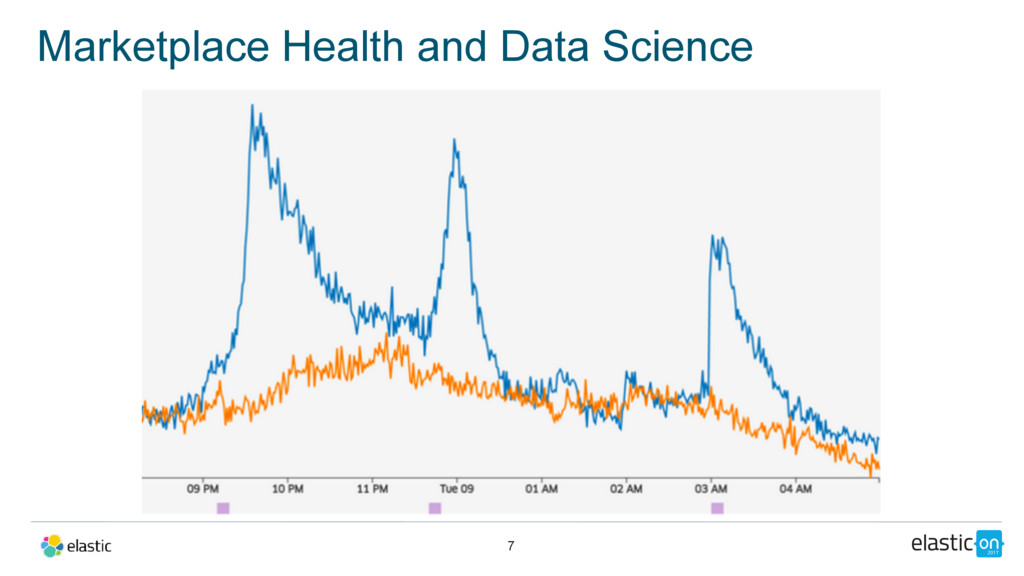
Elasticsearch plays a key role in Uber’s Marketplace Dynamics core data system, aggregating business metrics to control critical marketplace behaviors like dynamic (surge) pricing, supply positioning, and assess overall marketplace diagnostics – all in real time.
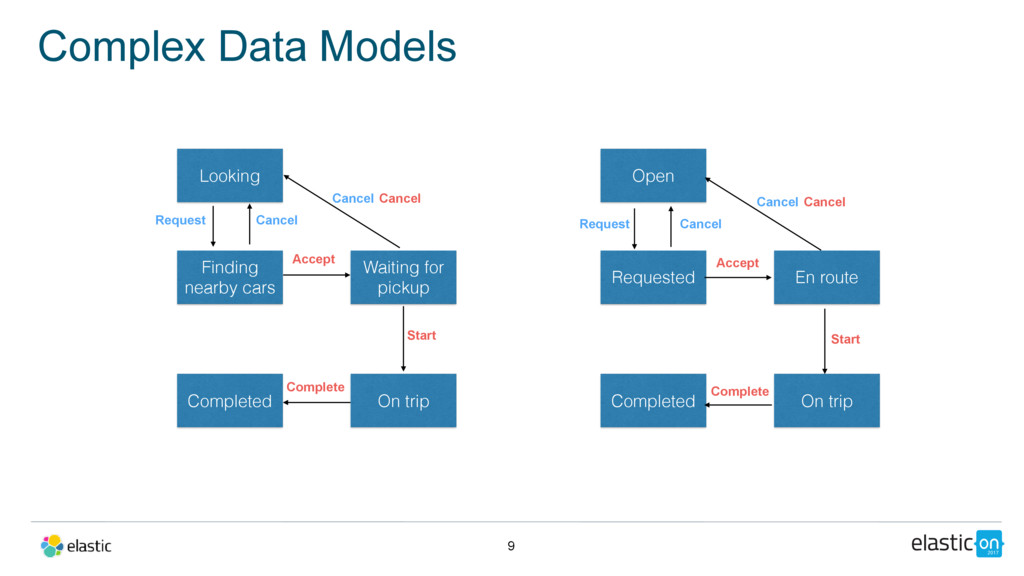
In this talk, Jae and Isaac will share how Uber uses Elasticsearch to support multiple use cases at the company, handling more than 1,000 QPS at peak. They will not only address why they ultimately chose Elasticsearch, but will also delve into key technical challenges they’re solving, such as how to model Uber’s marketplace data to express aggregated metrics efficiently, and how to run multiple layers of Elasticsearch clusters depending on criticality, among others.
Jae Hyeon Bae l Technical Lead l Uber
Isaac Brodsky l Software Engineer l Uber
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![15 "BY": [“HEXAGON_ID”,"STATUS"], "AGGREGATIONS": [ { "FUNCTION": "SUM", "METRIC": "APP_OPENED"](https://files.speakerdeck.com/presentations/85ea0ad21644450682618942222da130/slide_14.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
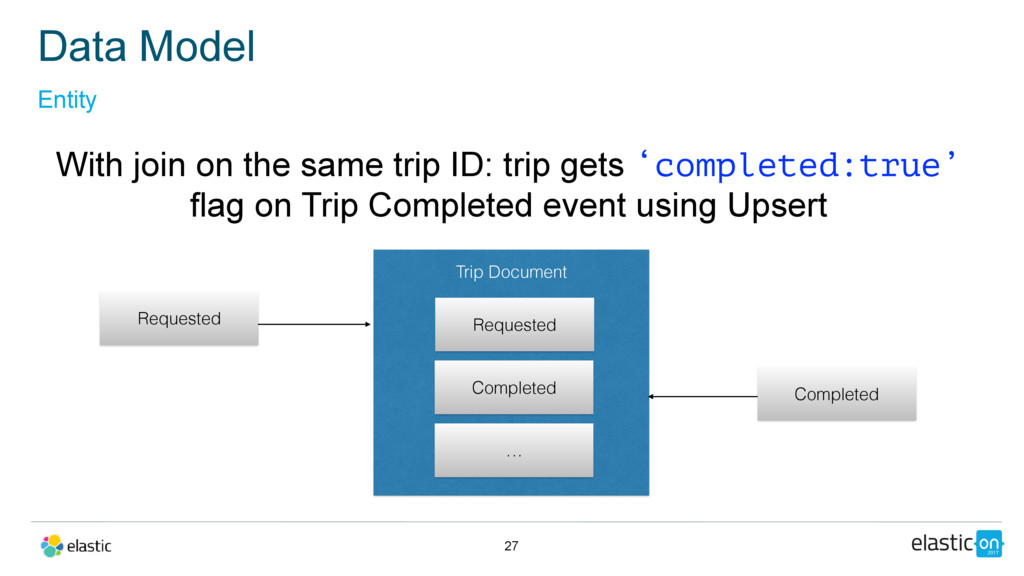{kind=link}
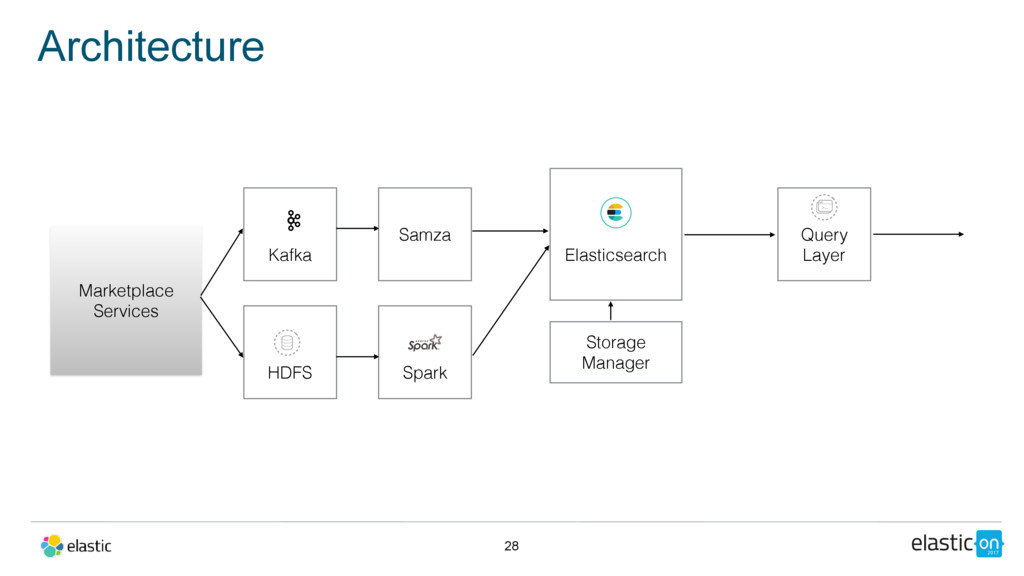{kind=link}
{kind=link}
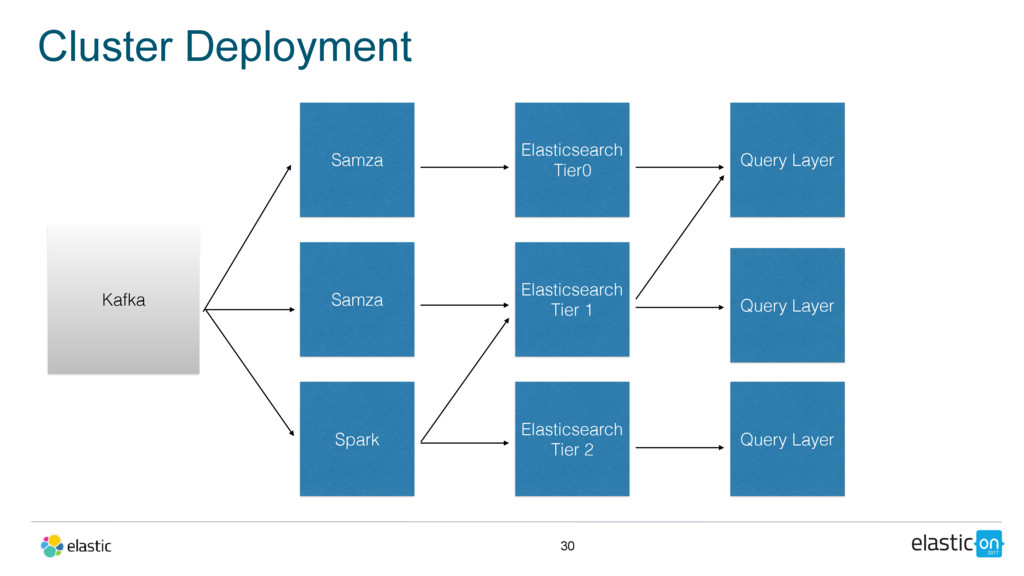{kind=link}
{kind=link}
![32 "DEMAND": { "CLUSTERS": { "TIER0": { "CLUSTERS": ["ES_CLUSTER_TIER0"], },](https://files.speakerdeck.com/presentations/85ea0ad21644450682618942222da130/slide_31.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
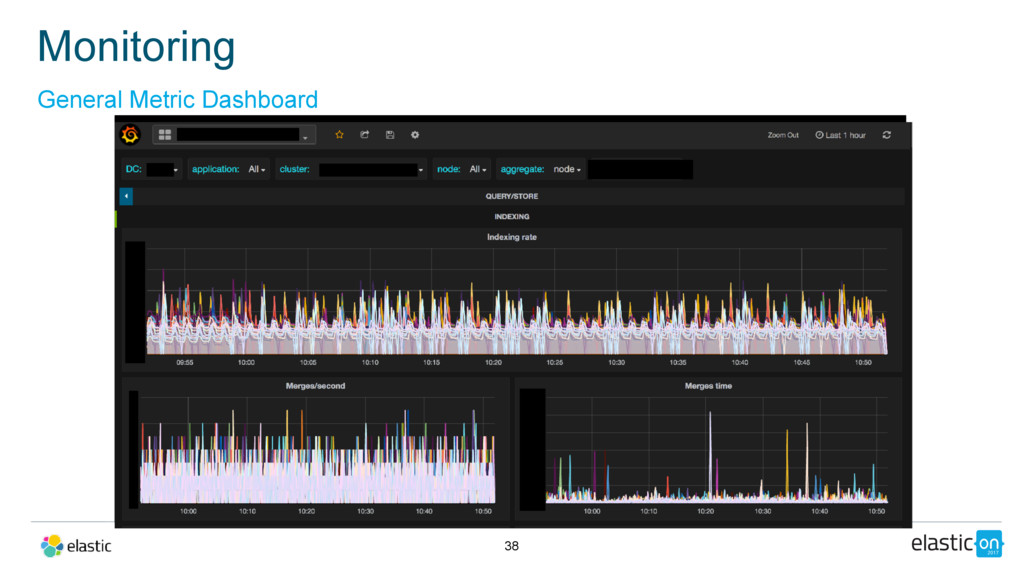{kind=link}
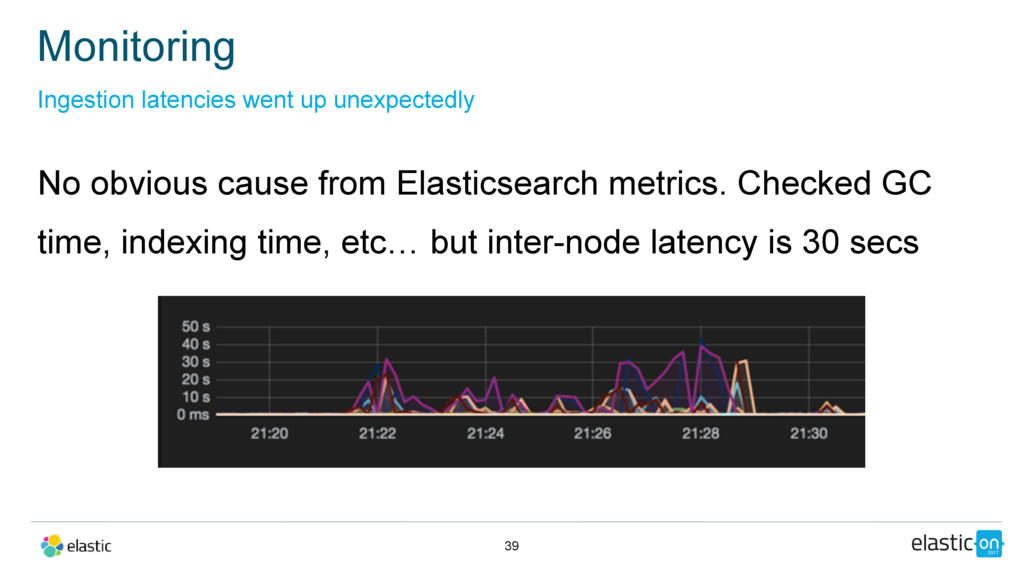{kind=link}
{kind=link}
{kind=link}
{kind=link}
![43 "BY": ["HEXAGON_ID", "STATUS"], "TIME": { "START": "2017-02-01", "END": "2016-02-02",](https://files.speakerdeck.com/presentations/85ea0ad21644450682618942222da130/slide_42.jpg){kind=link}
{kind=link}
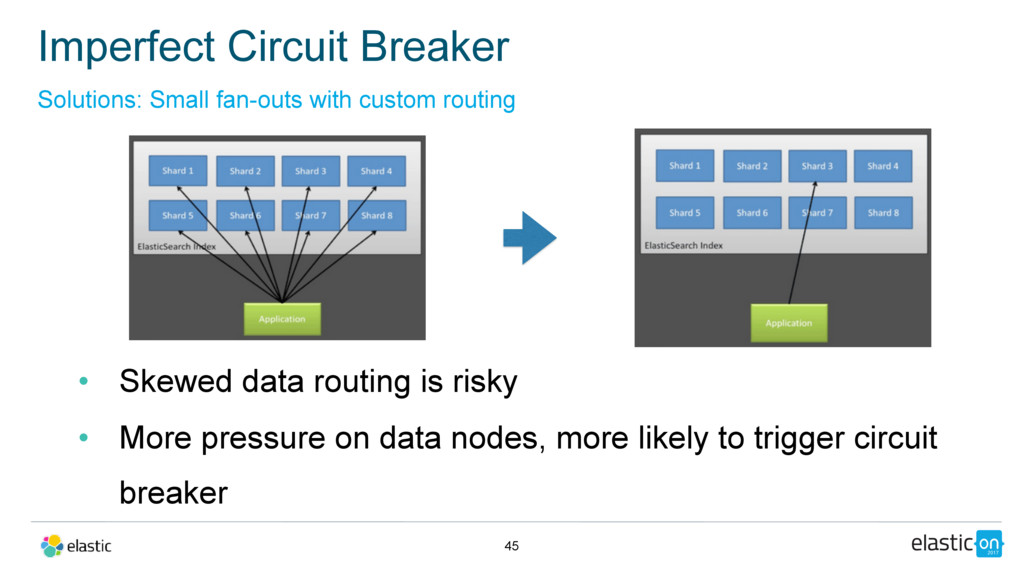{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}