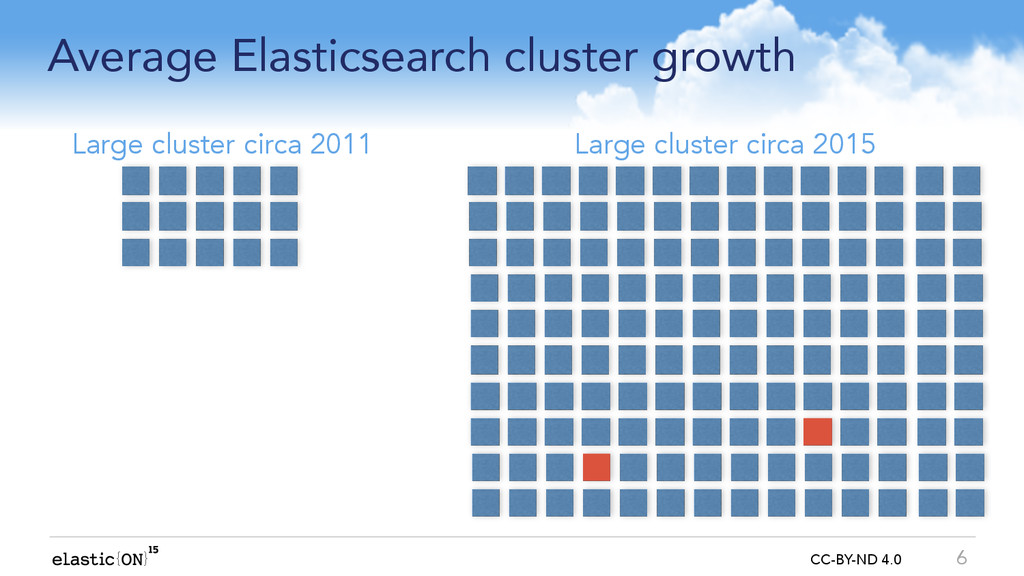
As Elasticsearch clusters grow larger, their resilience to hardware and network failure becomes increasingly important. At Elasticsearch, we invest a LOT in making both Elasticsearch and Apache Lucene both detect and cope with increasingly complex failures.
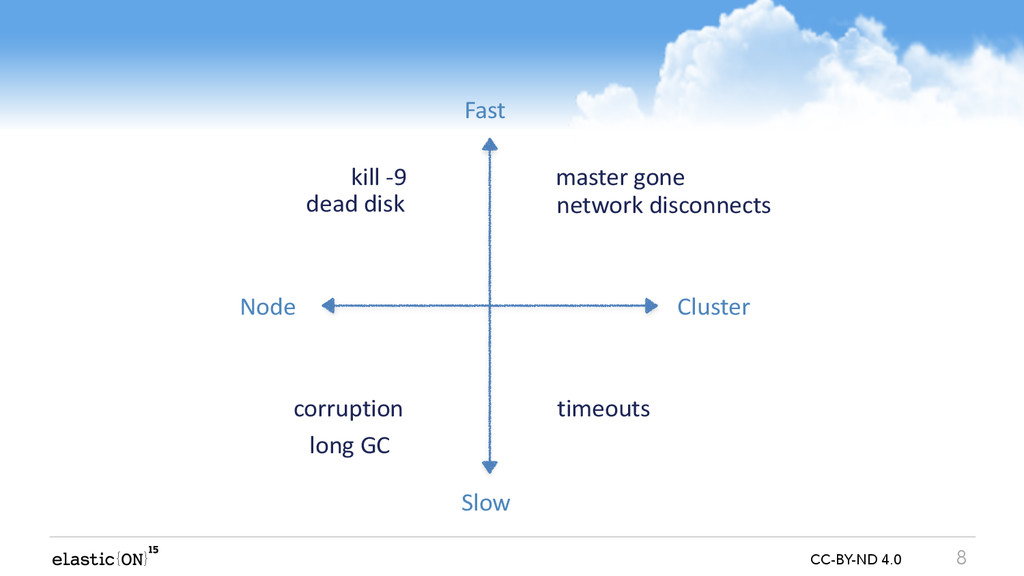
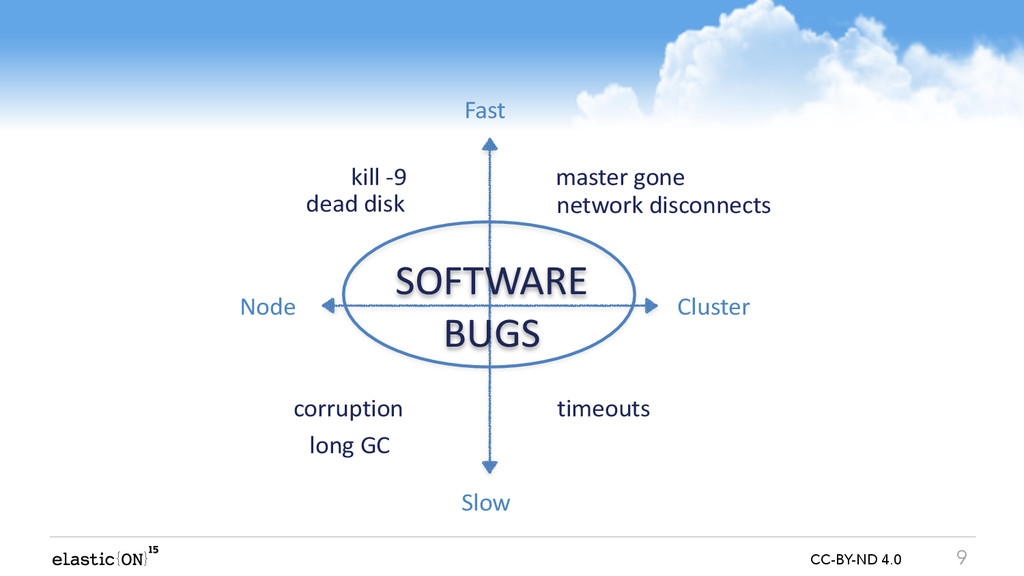
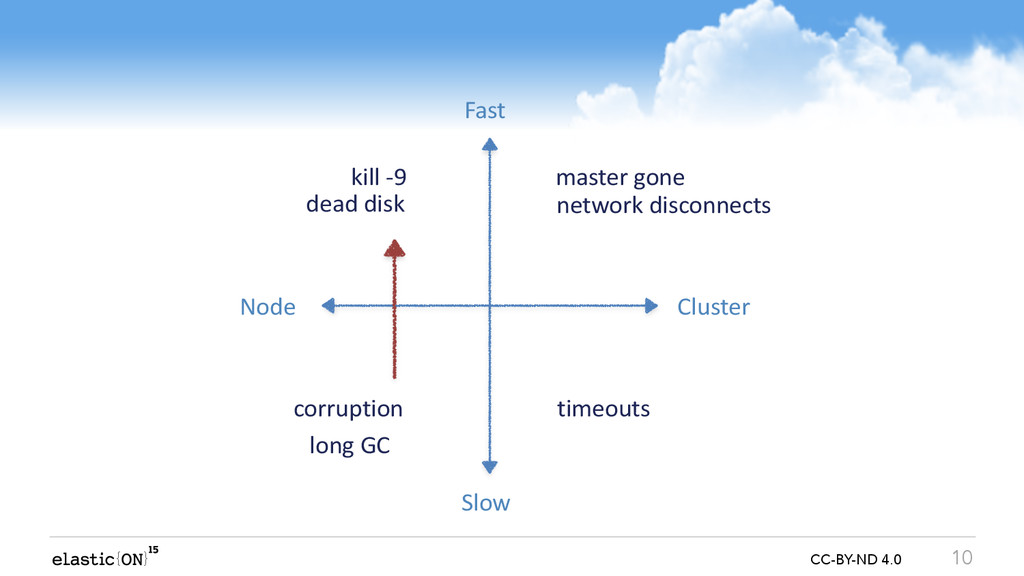
In this talk we will go through recent highlights and some of the future directions we plan to follow. We will touch all aspects of Elasticsearch, ranging from the lowest level of a single file, through network connection of a single node, and all the way up distributed failures on the cluster level. Even though the talk is about possible failures and various coping strategies, you will also learn about the inner workings of Elasticsearch - an interesting peek under the hood.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
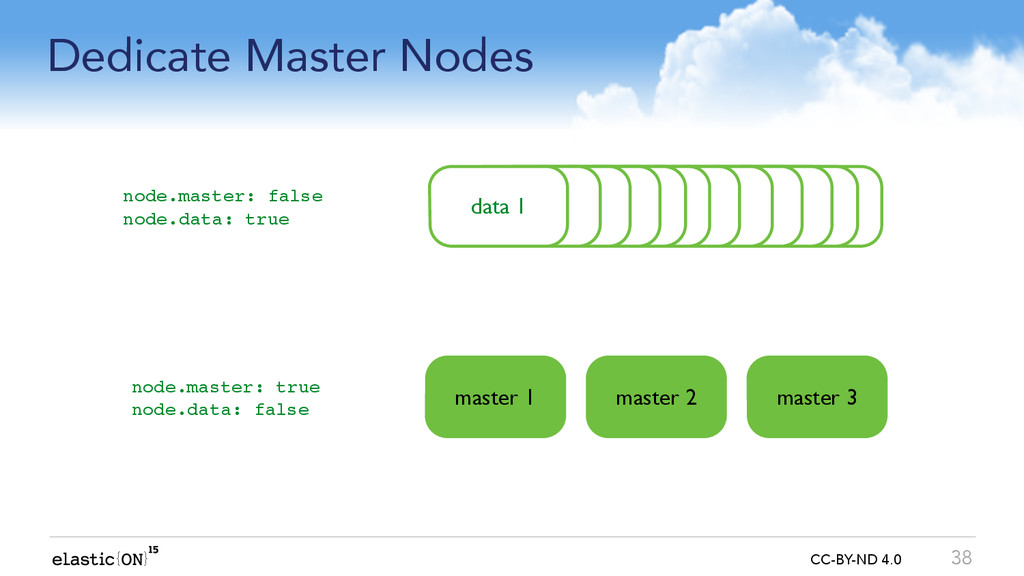{kind=link}
{kind=link}
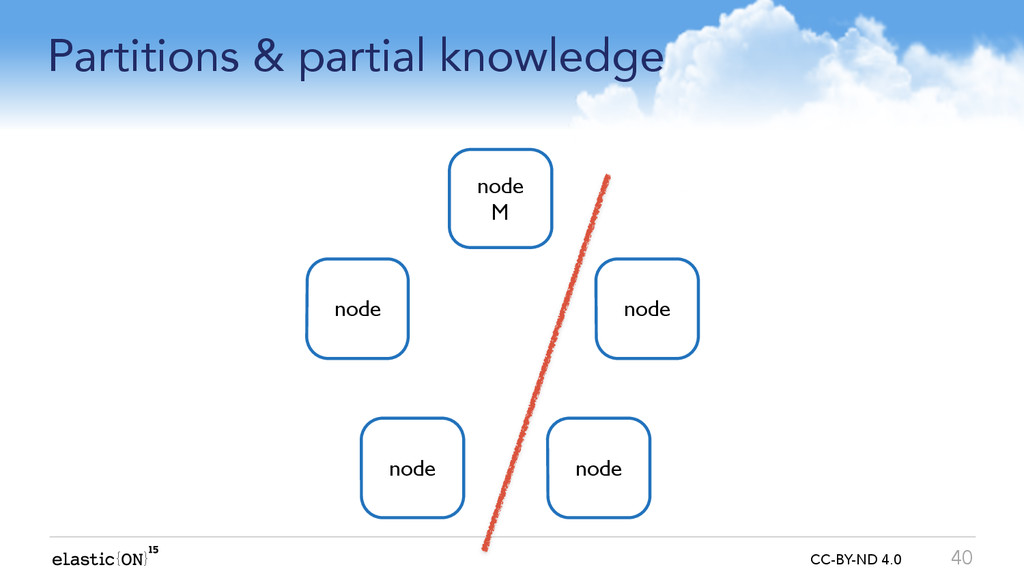{kind=link}
{kind=link}
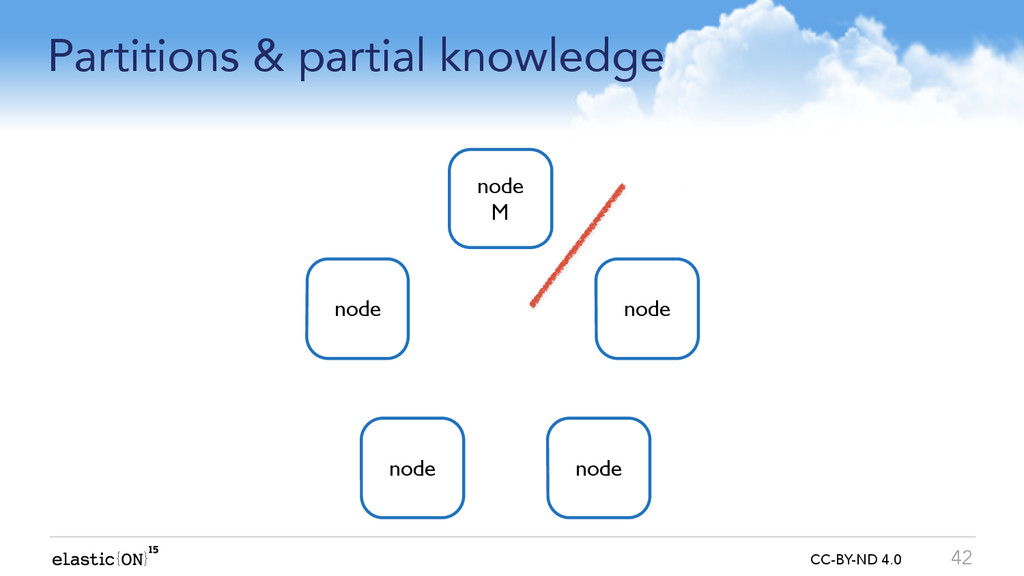{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![{ } Thank you! [email protected], [email protected] @bleskes, @imotov](https://files.speakerdeck.com/presentations/dc36a90f975a4512bfffb15eea711192/slide_49.jpg){kind=link}
{kind=link}