SaaS offering for media providers to enable streaming of their content • Each media provider will have video and meta data stored in the system • Analytical data on videos streamed will also be stored and offered to media providers • Our service provides a public API for media providers to use the meta and analytical data to build their solutions 4
5 • Increased traffic / load to our public API’s • Increased storage of media meta data • Increased storage of analytical data • Increased reliance of system stability
data we expect for production into test cluster Performance test application and evaluate metrics to find upper limit of single shard What’s the best cluster configuration? Well, it depends
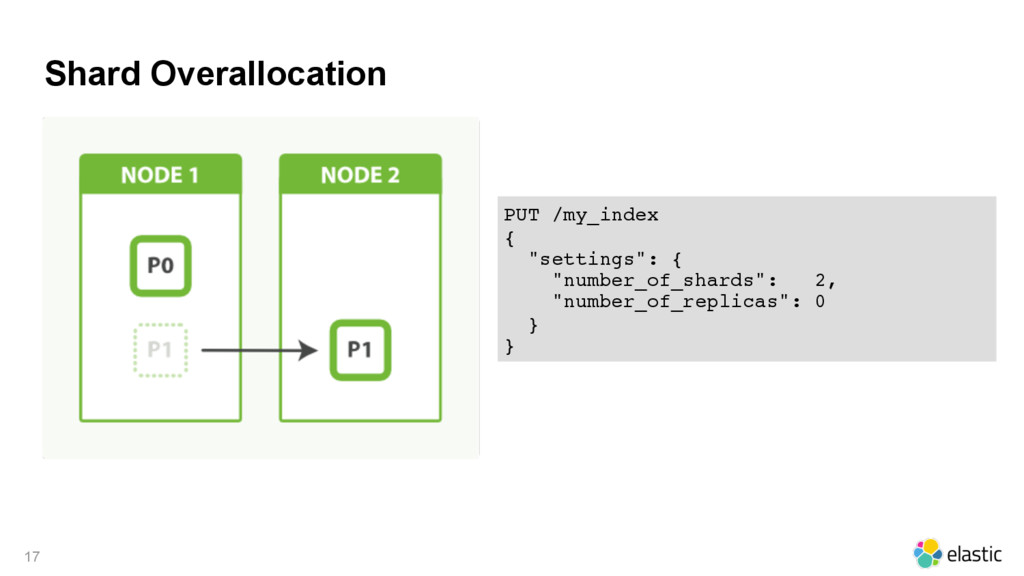
index under the covers, which uses file handles, memory, and CPU cycles. • Every search request needs to hit a copy of every shard in the index. • Term statistics, used to calculate relevance, are per shard. Having a small amount of data in many shards leads to poor relevance. 19 A little overallocation is good. A kagillion shards is bad.
media provider ID to index name • Data is easily separated between media providers • Indexes can have specific shards and replicas to deal with the amount of data for the media provider • Works really well while the amount of media providers is small 28
single index • Utilising filters and aliases, we can separate media providers data based on their ID • Define routing to increase search performance • Able to easily move heavy users off the shared index to their own dedicated index 33
separate index specifically for the large media provider • Migrating data from the existing shared index can be done using a scroll query and the bulk API • We can then set an index alias to point to the new index 38
out of space and resources quickly • Time based indexes are created for a specific time period, IE. Monthly • You can change the index configuration much quicker as new indexes are created more often • Use of aliases make querying and ingesting data easy • Your able to remove old data (old indexes) easily to save resources • Elastic Curator https://github.com/elastic/curator 41
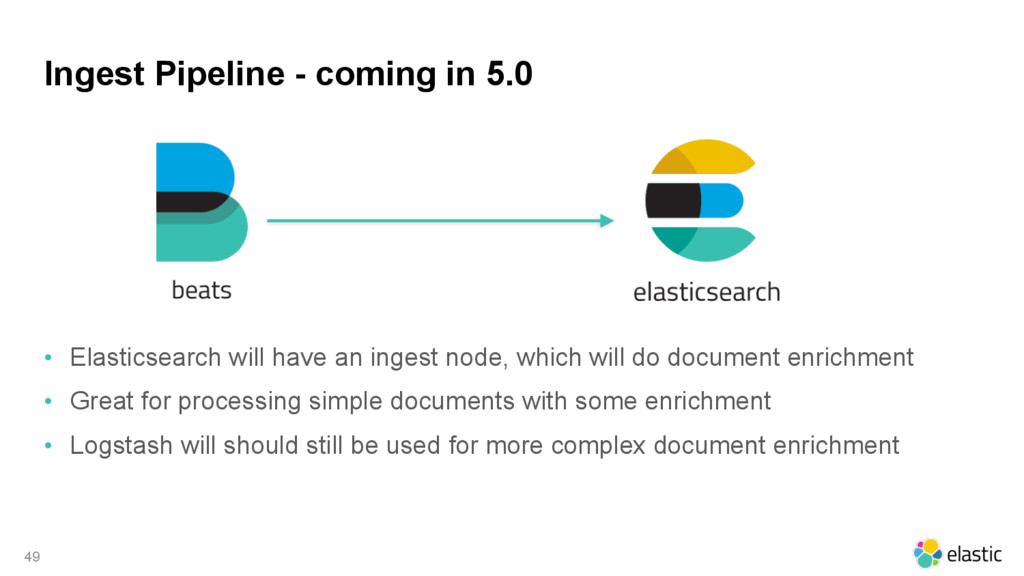
an ingest node, which will do document enrichment • Great for processing simple documents with some enrichment • Logstash will should still be used for more complex document enrichment 49
is associated with a timestamp • Allows us to query easily over a certain time period without overhead of querying all data • Example: How many plays of a particular media over the last day • We can easily remove old data that we no longer offer to our media providers • We only want to offer the last 3 years of analytical data 51
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}