A recap of the main announcements from our recent global conference! We touched on Elasticsearch, Logstash, Kibana and Beats and so much more.
Presented by Mark Walkom, Joshua Rich, Russ Cam and Christian Strzadala.
For more detailed information on each of the topics, see the videos and slides from the original presenters at the conference here - https://www.elastic.co/elasticon/conf/2016/sf
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Indexing [An Enriched] Document specifying an ingest pipeline to execute](https://files.speakerdeck.com/presentations/dfffdab9818a4906a80dd33eaa25259d/slide_9.jpg){kind=link}
![Indexing [An Enriched ] Document document as it is being](https://files.speakerdeck.com/presentations/dfffdab9818a4906a80dd33eaa25259d/slide_10.jpg){kind=link}
{kind=link}
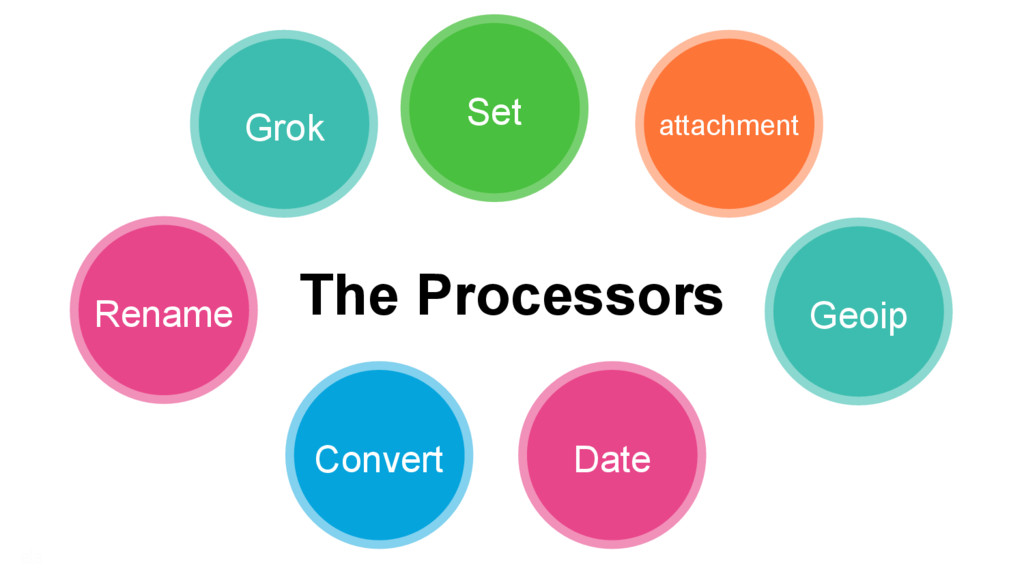{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
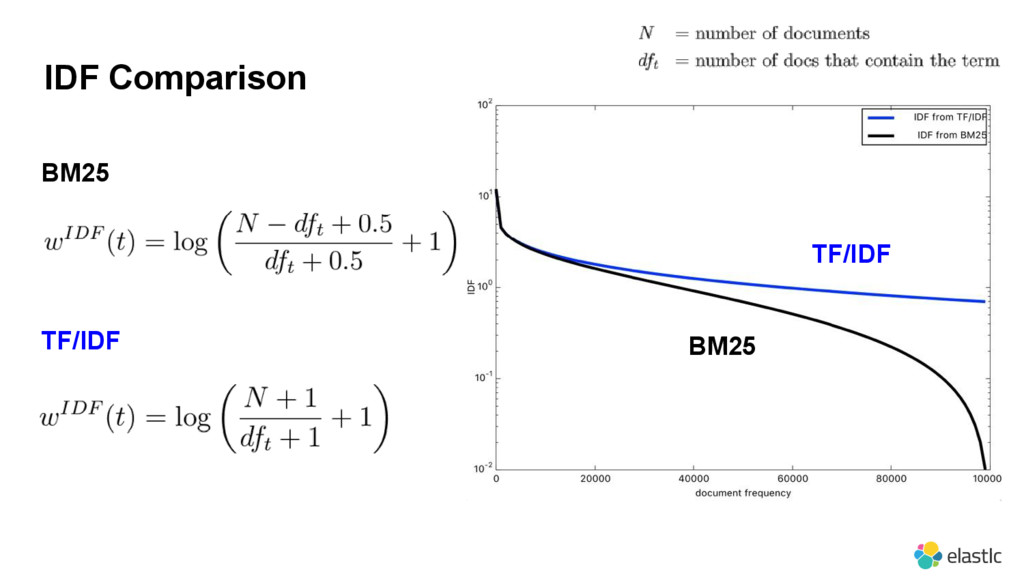{kind=link}
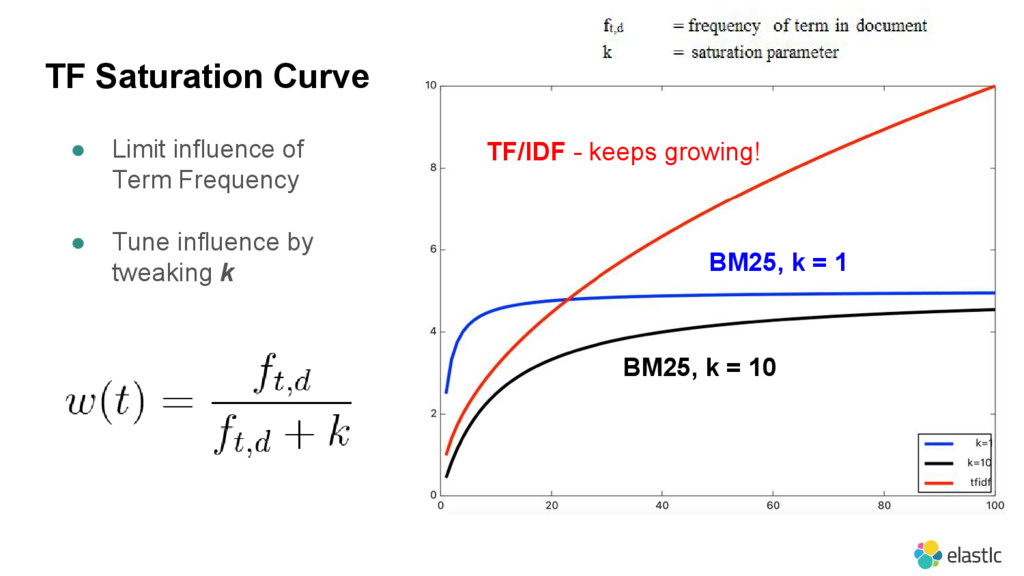{kind=link}
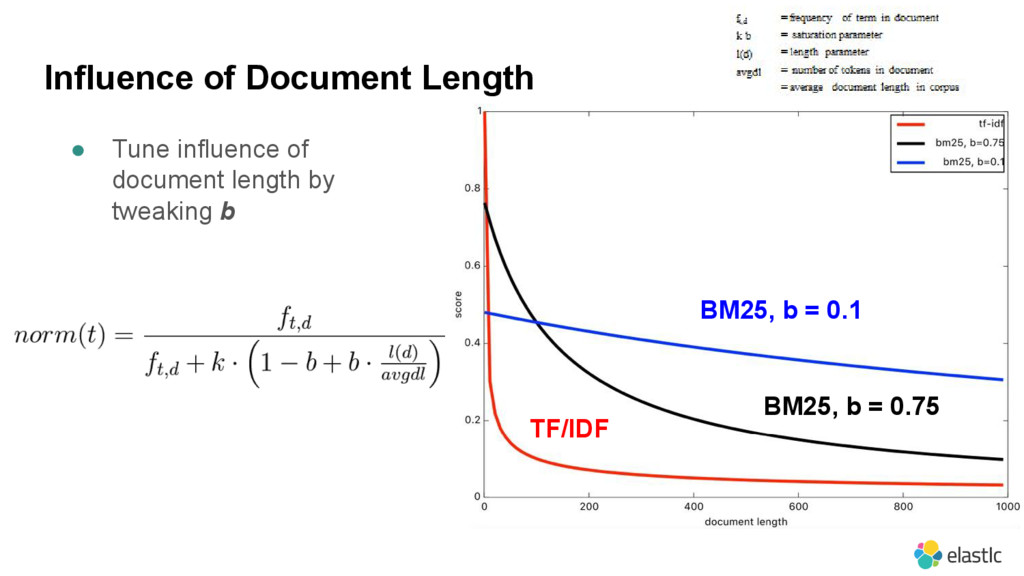{kind=link}
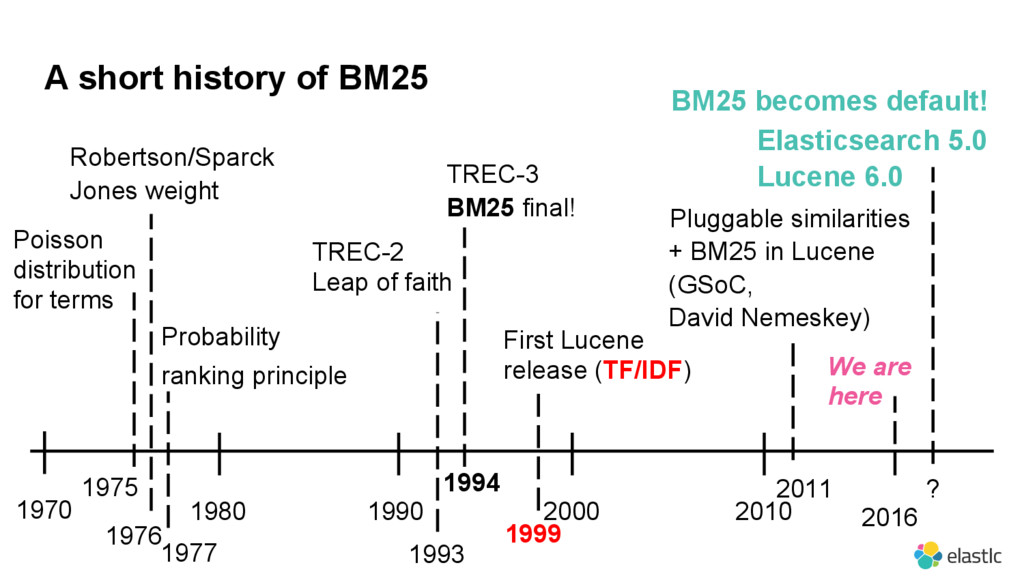{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
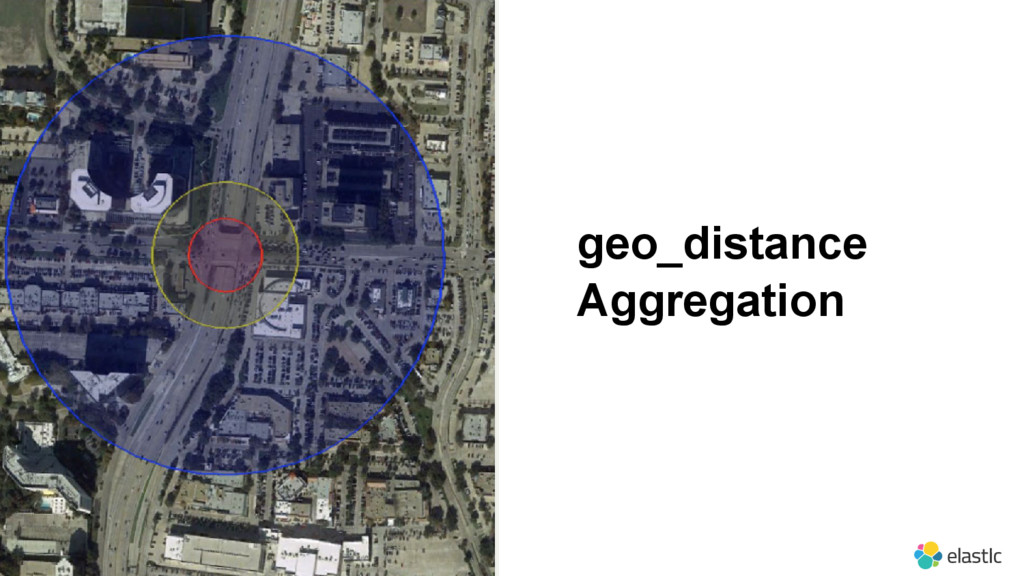{kind=link}
{kind=link}
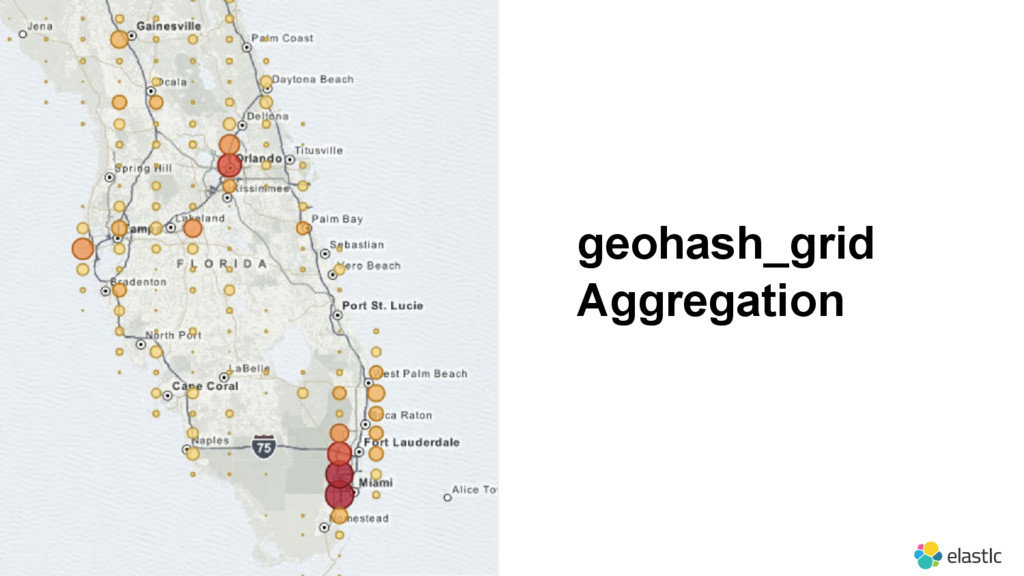{kind=link}
{kind=link}
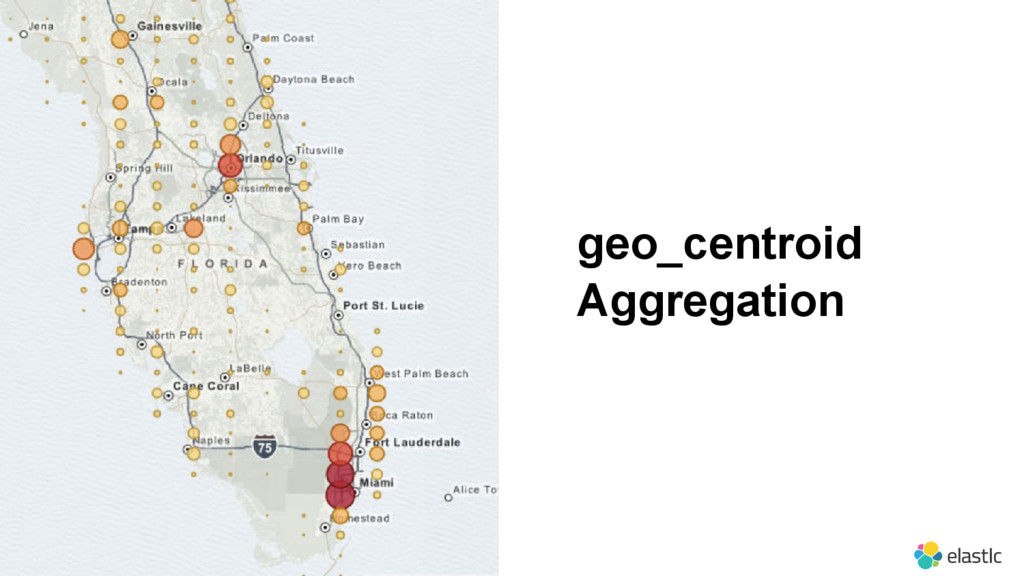{kind=link}
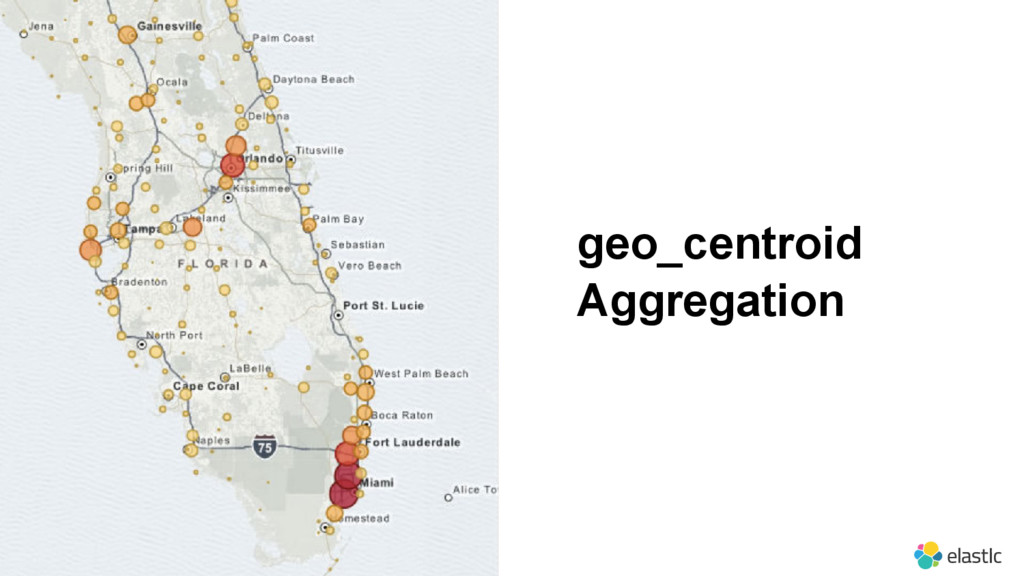{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
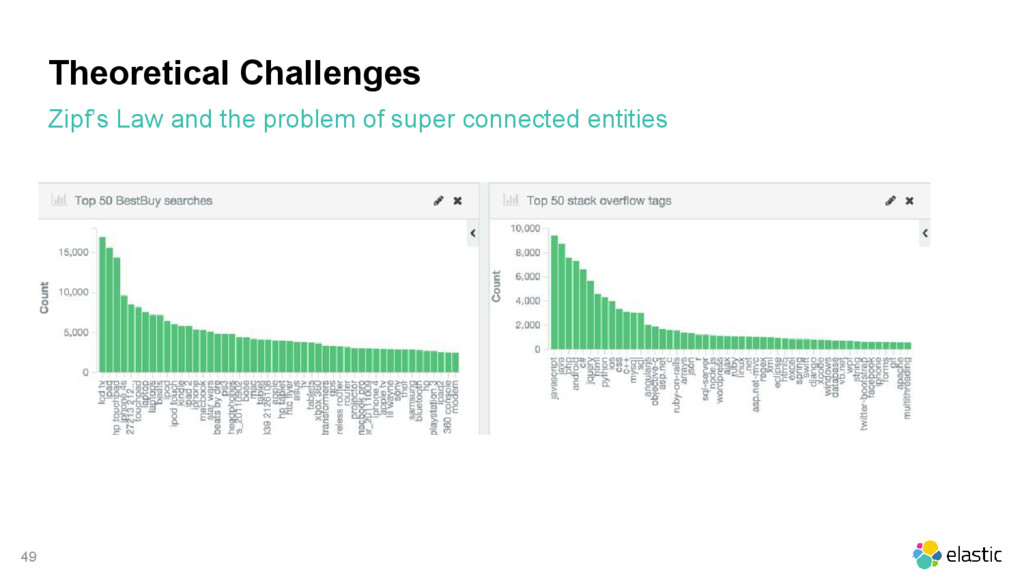{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
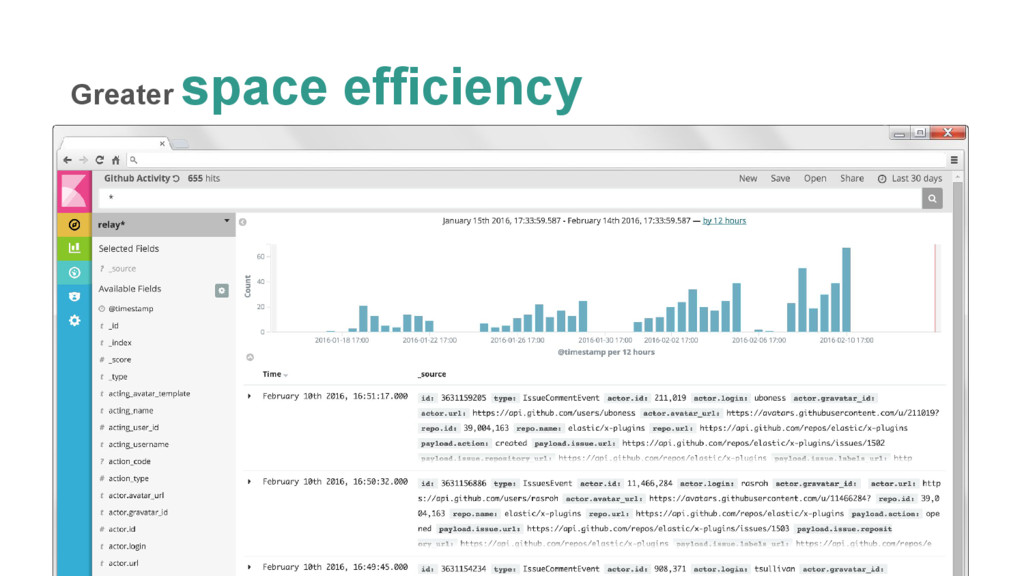{kind=link}
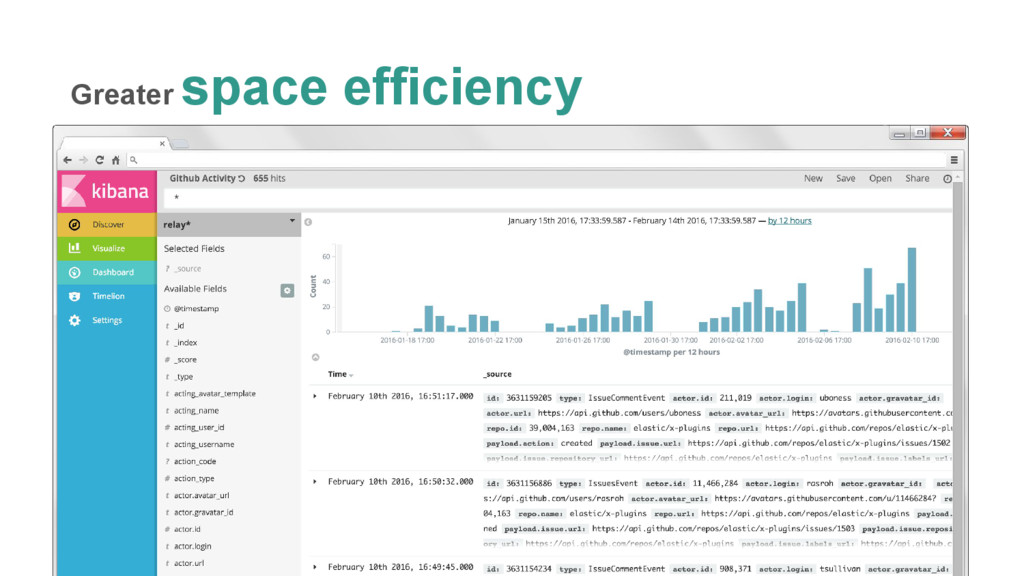{kind=link}
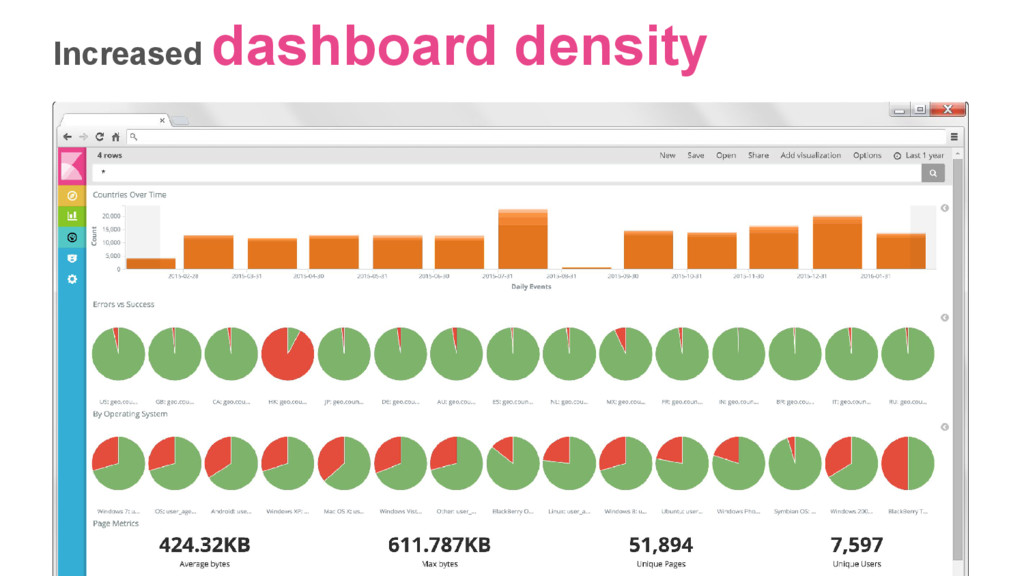{kind=link}
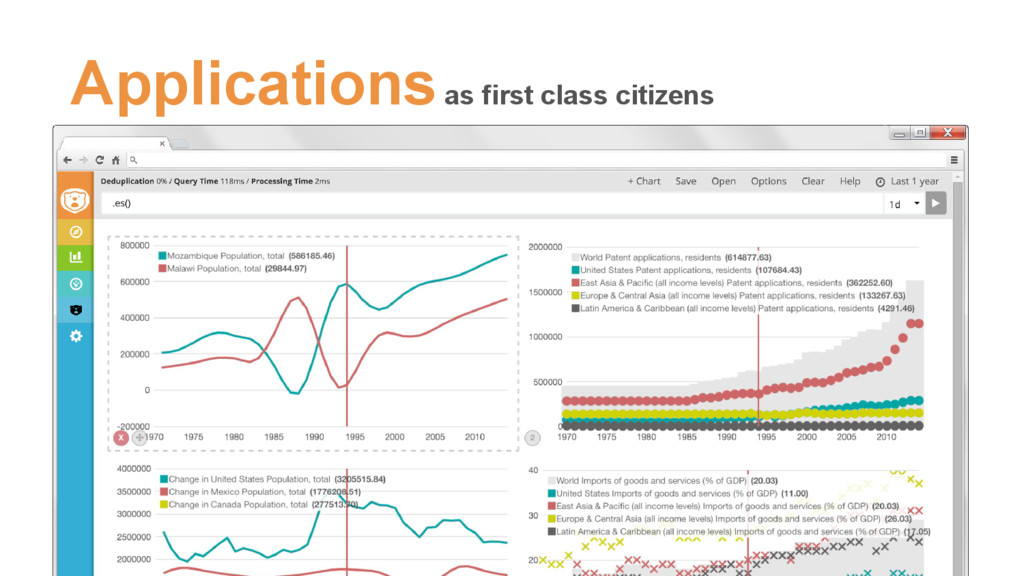{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
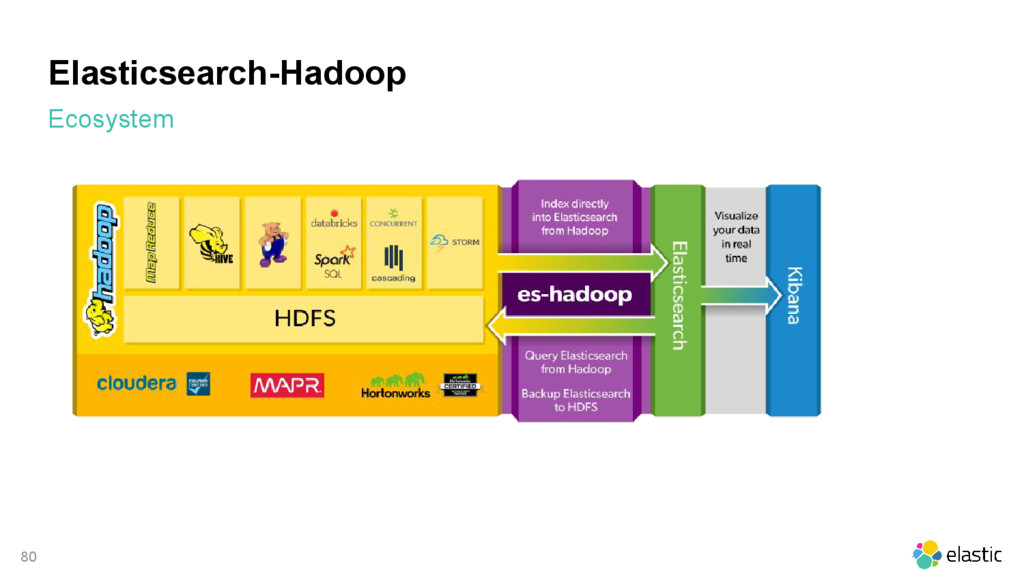{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}