• Wrote the first version of the Jupyter/IPython Notebook in the summer of 2011. • Continue as a core developer and leader of Jupyter/IPython. • Physics Professor @ Cal Poly: • 20%: Teach Data Science • 80%: Jupyter/IPython • Board member of NumFOCUS
processing data. 2. Humans are optimized for producing, consuming and processing narratives/stories. 3. For code and data to be useful to humans, we need tools for creating and sharing narratives that involve code and data.
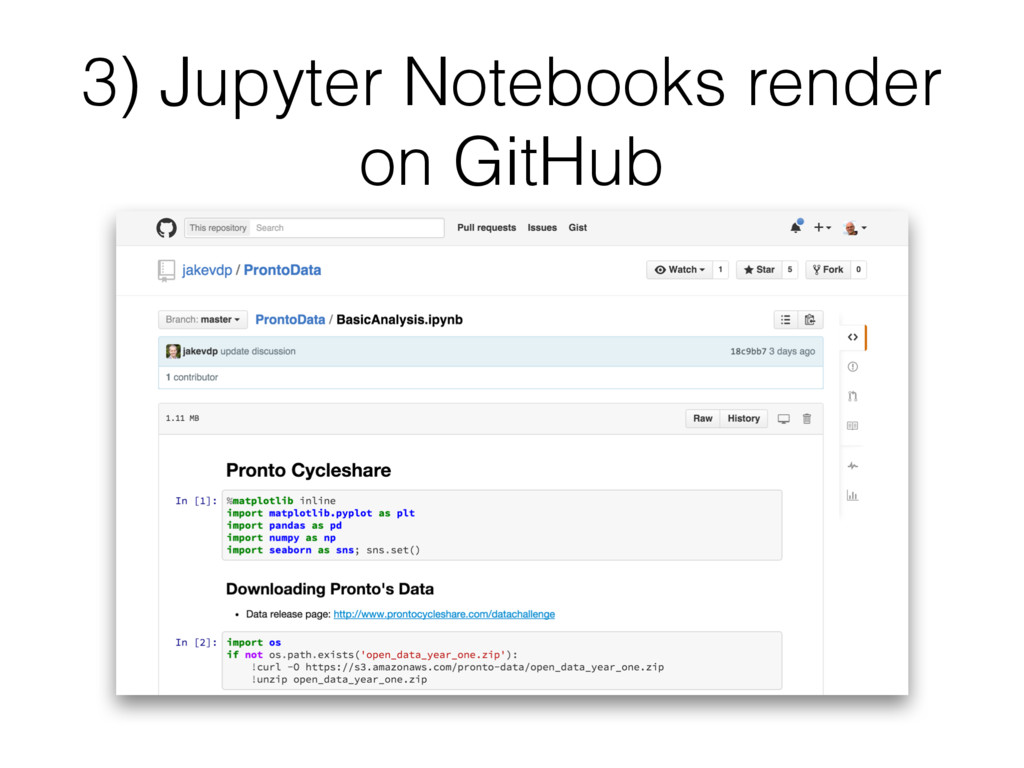
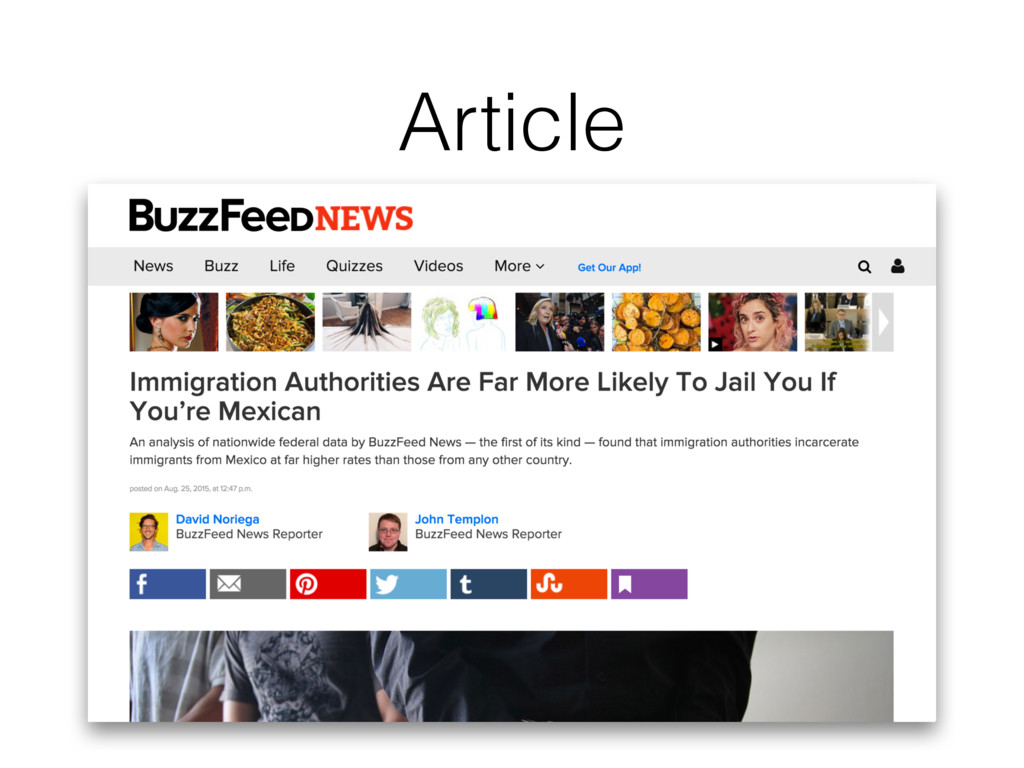
Templon are data journalists at BuzzFeedNews. • For each article they publish on BuzzFeeNews, they share their data and code on a GitHub repo. • Code is shared as Jupyter Notebooks. • https://github.com/BuzzFeedNews/everything
or Kernels • Microsoft AzureML and HD Insight • Quantopian Research Platform • Google Cloud Datalab • IBM Knowledge Anyhow • yhat Rodeo • Dataiku Data Science Studio • Domino Data Lab • O’Reilly Media • DataRobot • Dato GraphLab Create
Jupyter Workbench • All frontend code being refactored into a set of loosely coupled npm packages with well defined models and views that you can use in building your own apps. • All based on a plug-in system to make it easy for third party developers to extend. • Flexible layout to freely mix notebooks, text editors, terminals, output areas, interactive visualizations, and dashboards in a single browser tab. • Real-time collaboration. • Funded by the Moore, Sloan, and Helmsley Foundations in collaboration with Continuum Analytics and Bloomberg. • Will start to show up in Q1/Q2 2016.
Project Manager. • Cal Poly • UI/UX Designer. • Software Engineers. • This is an incredible opportunity to work on open-source software as your day job. • Contact me here at ODSC or ellisonbg at gmail
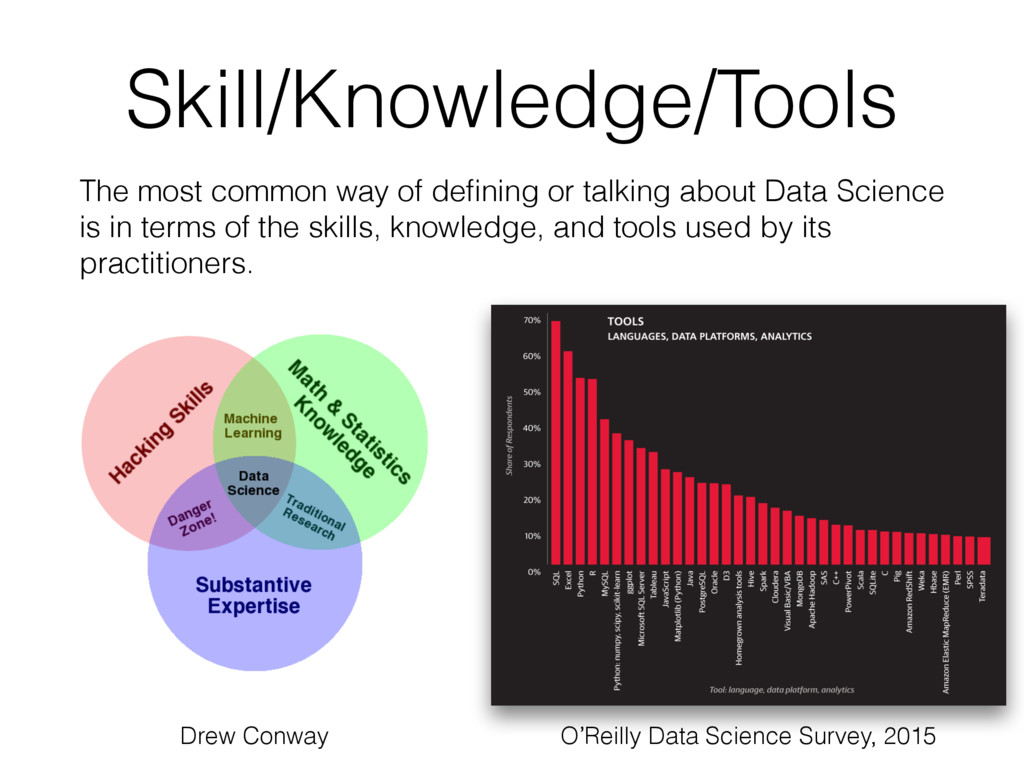
learning. • But let’s try to define something else using this approach and see how it goes. • What is cooking? • What skills/knowledge/tools are required? • Chopping, measuring, mixing, stirring, boiling, frying, operating a stove, purchasing ingredients, tasting, etc. • Knives, spoons, forks, cups, plates, pots, pans, measuring cups, oven, microwave, stove, etc. • These things are all true about cooking, but miss the fundamental point. • What is the fundamental point of cooking?
of cooking are a set of questions that capture its essence and must be answered by anyone attempting to cook: • What meals/dishes are nutritional, pleasant and affordable to eat? • How long do those meals take to prepare? • What do I feel like eating? • What raw ingredients are required to prepare those meals? • What is the cost and availability of those raw ingredients? • What processes are required to prepare the meals from the raw ingredients? • What tools/skills are required to prepare the meals?
data? • What is the raw format of the data? • How much data and how often? • What variables/fields are present in the data and what are their types? • What relevant variables/fields are not present in the data? • What relationships are present in the data and how are they expressed? • Is the data observational or collected in a controlled manner? • What practical questions can we, or would we like to answer with the data? • How is the data stored after collection and how does that relate to the practical questions we are interested in answering? • What in memory data structures are appropriate for answering those practical questions efficiently? • What can we predict with the data? • What can we understand with the data? • What hypotheses can be supported or rejected with the data? • What statistical or machine learning methods are needed to answer these questions? • What user interfaces are required for humans to work with the data efficiently and productively? • How can the data be visualized effectively? • How can code, data and visualizations be embedded into narratives used to communicate results? • What software is needed to support the activities around these questions? • What computational infrastructure is needed? • How can organizations leverage data to meet their goals? • What organizational structures are needed to best take advantage of data? • What are the economic benefits of pursuing these questions? • What are the social benefits of pursuing these questions? • Where do these questions and the activities in pursuit of them intersect important ethical issues. • And many more…
the traditional scientific method. That is the Science in Data Science. • Can be pursued at any level (primary, secondary, undergraduate, graduate, professional, fun). • Open the door for a “data literacy” that extends far beyond the current hyper-technical realization of Data Science: • We can’t be the only ones who understand the fundamental questions related to data. • See, for example, the current national “discussion” surrounding global warming and vaccinations. • Chris Mooney, “The Science of Why We Don’t Believe Science,” Mother Jones (http:// www.motherjones.com/politics/2011/03/denial-science-chris-mooney). • Allow for a healthy understanding of the relationship between Data Science and the skills/knowledge of its practitioners: • The questions are fundamental, skills/knowledge are secondary — “implementation details” • Different individuals will have different skills/knowledge. Everyone will not know everything. • Are silent about education level, gender, race, academic degree, years of experience, etc.
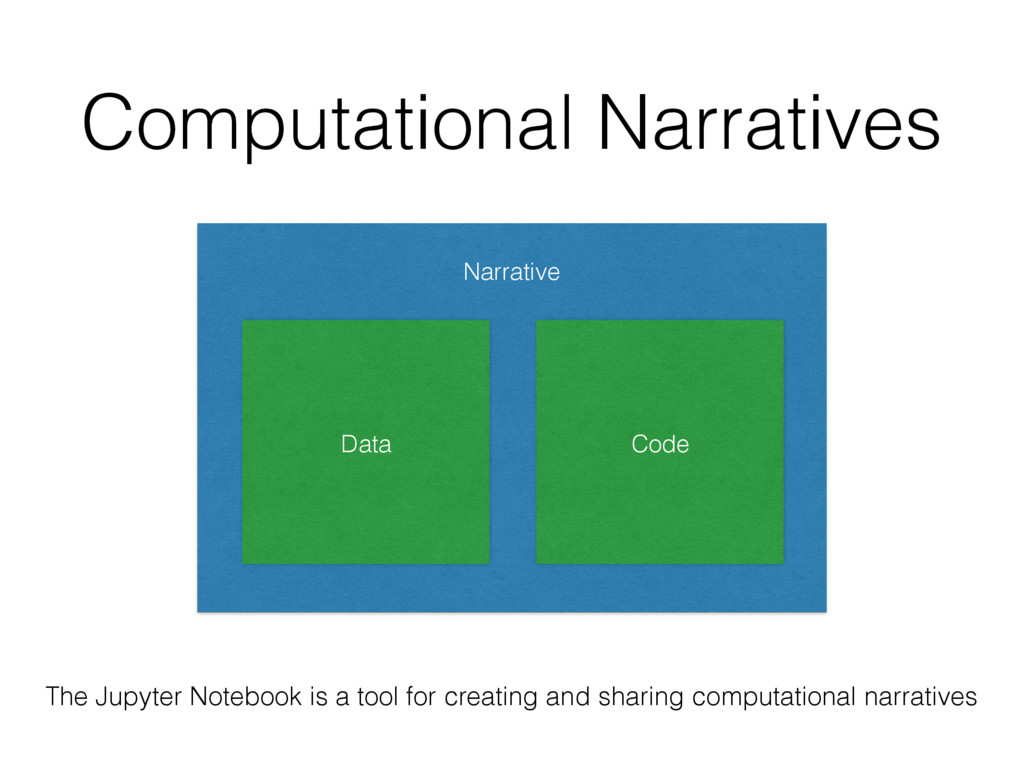
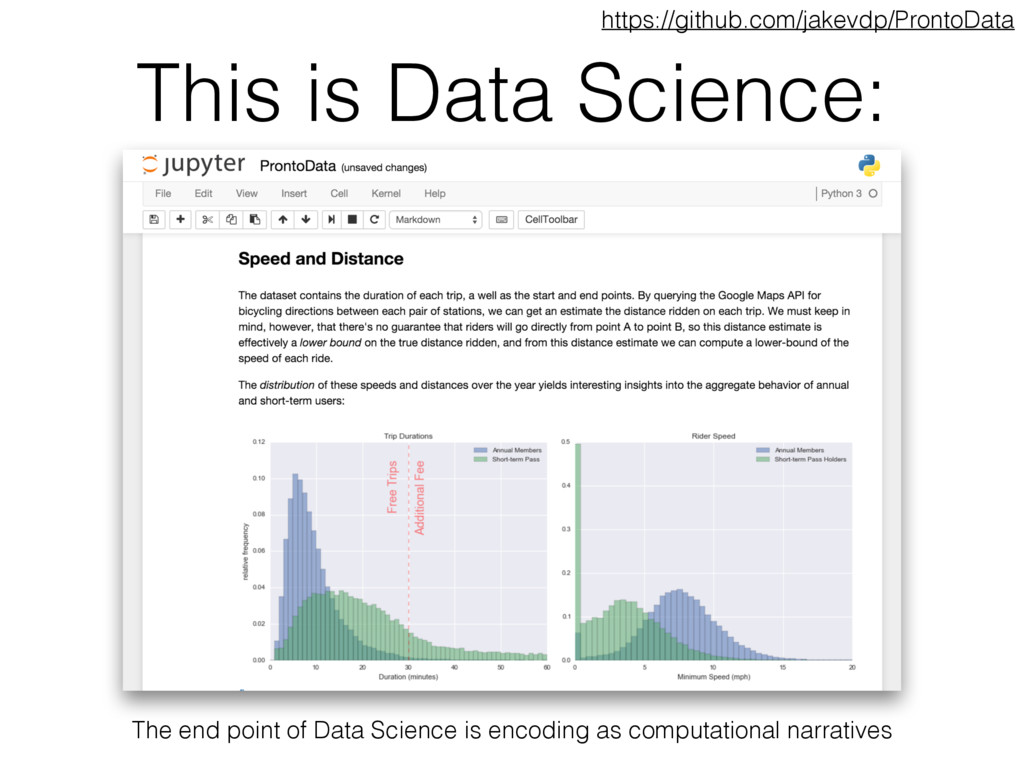
is a tool that allows us to explore the fundamental questions of Data Science • …with a particular dataset • …with code and data • …in a manner that produces a computational narrative • …that can be shared, reproduced, modified, and extended. • At the end of it all, those computational narratives encapsulate the goal or end point of Data Science. • The character of the narrative (prediction, inference, data generation, insight, etc.) will vary from case to case.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}