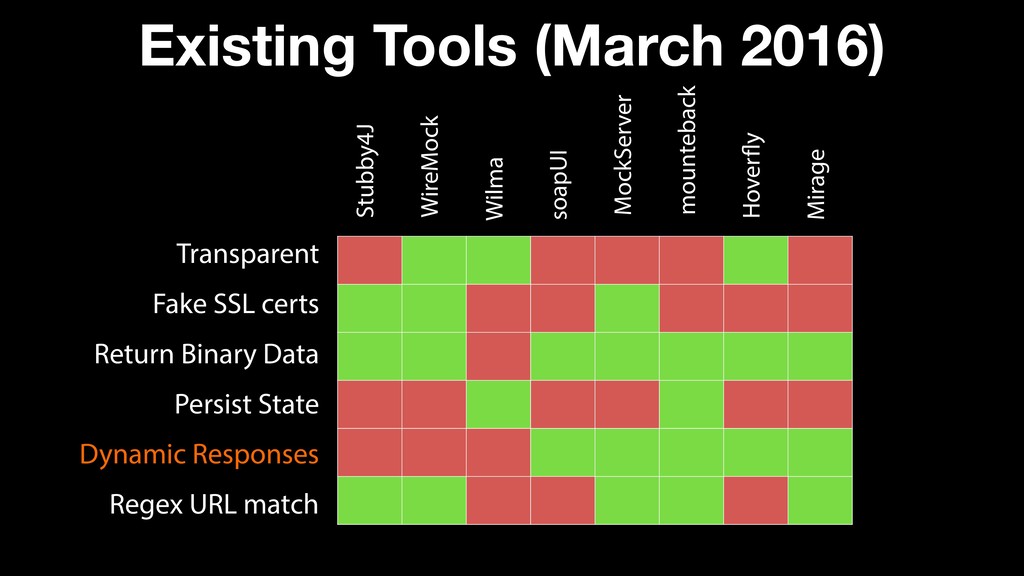
Automated tests are a great tool for regression testing, however they are as good as the data they use. There are different approaches to test data management and they all juggle between quality/quantity and its availability. One may use the current data present, other may use an obfuscated subset of production data, another will preload the full db with synthetic data. There is even a costly commercial tools that will do magic ‘data virtualization’ for you.
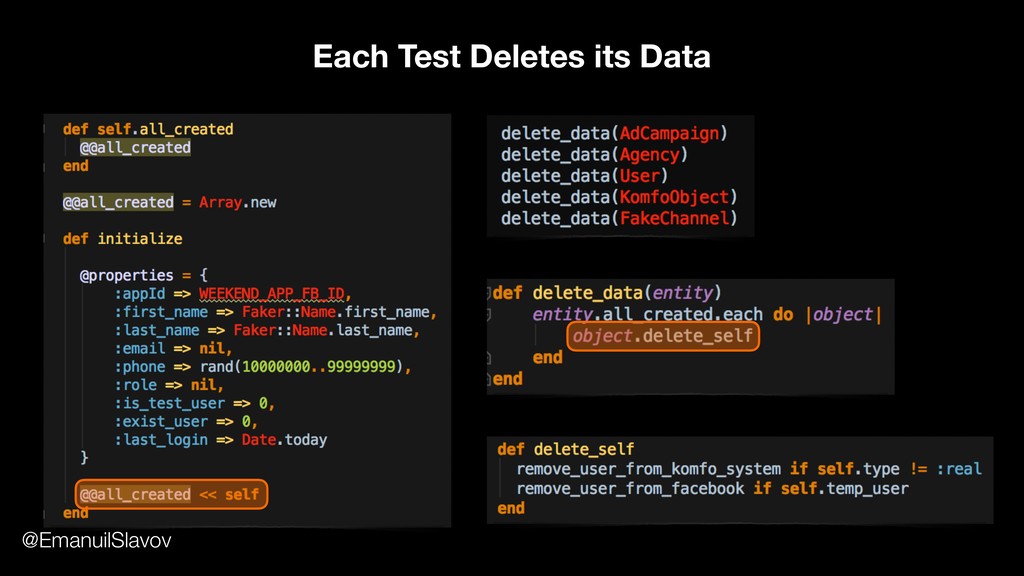
However, if you want a highly reliable automated tests the best approach is for each test to create all the data that it needs. Using this strategy your tests will be reliable, independent, could be run in parallel, could be run on any environment, on empty or on dirty database, could detect problems that they are not specifically programmed to do. The tests will also be very stable — we achieved 0.13% flakiness, as well as fast — we lowered the execution time from 3 hours to less than 3 minutes.
Those great advantages come at a cost however — you need to completely overhaul your testing framework. This presentation will help you do just that. From deciding which interfaces to use for data insertion to how to abstract this low level functionality at the correct level in your framework.
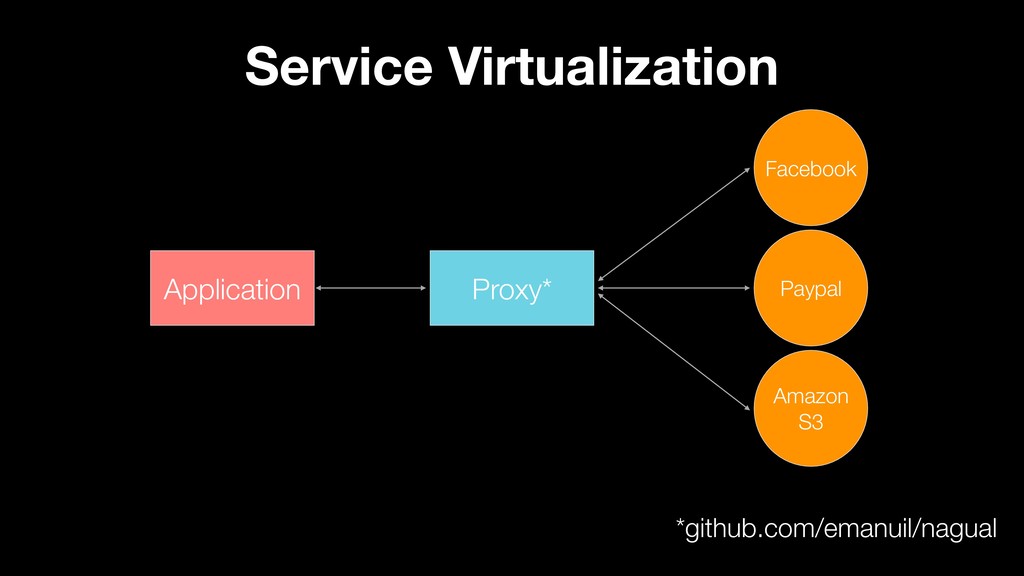
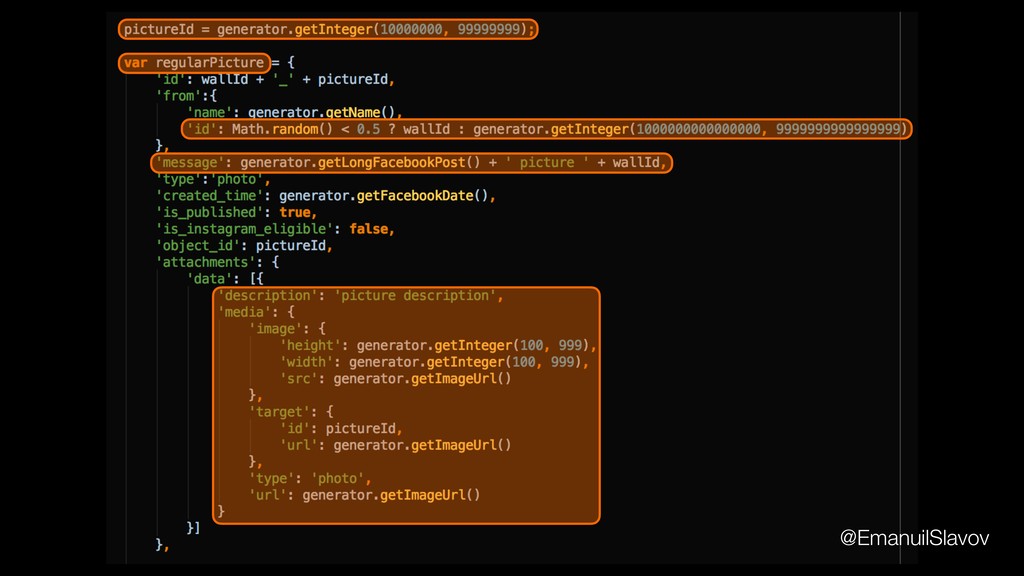
Test generation at the test case level is only one part of the solution. This presentation will also touch on topics such as random test data generation, strategies for cleaning test data and how to deal with test data if you’re using service virtualization when testing against 3rd party service outside of your control.
![DATA MANAGEMENT HIGHLY RELIABLE TESTS @EmanuilSlavov [email protected]](https://files.speakerdeck.com/presentations/5276735bbcc44cc3832769b9a739c2de/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![[email protected] @EmanuilSlavov EmanuilSlavov.com](https://files.speakerdeck.com/presentations/5276735bbcc44cc3832769b9a739c2de/slide_27.jpg){kind=link}