In 2013, the total amount of data in the world was 4.4 zettabytes. In 2020 it is estimated to be 10 times more. With speed advances and miniaturization of computers, it is now easier than even to collect all sorts of data in vast amounts. But quantity does not equate quality. Some of the most expensive software defects were caused by handing an incorrect data. The most recent example is the crash of the Schiaparelli Mars Lander.
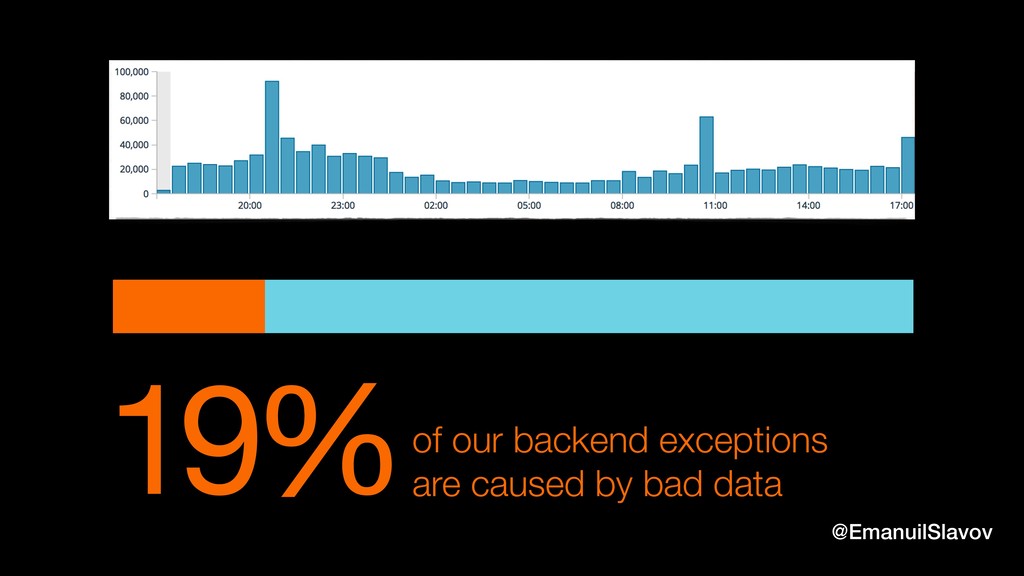
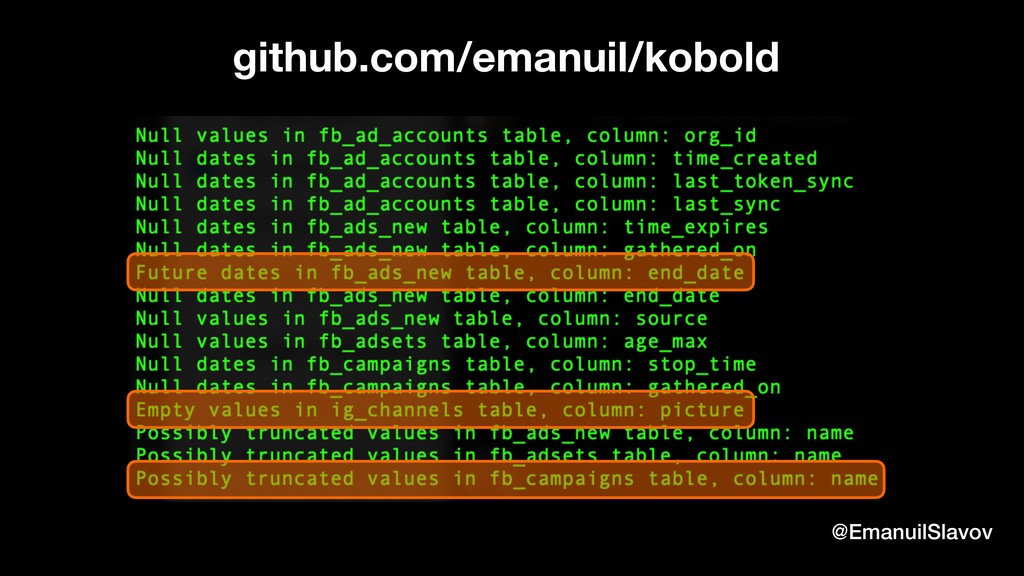
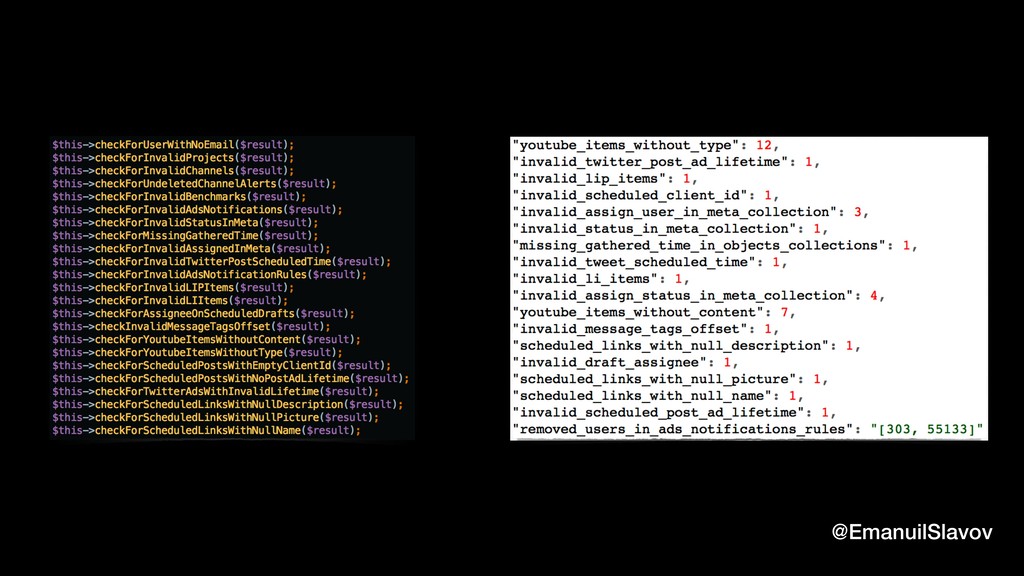
Back to Earth, at Falcon.io, we investigate every exception that is generated from our production environment. We were surprised to find out that 19% are caused by bad data. This includes missing data, data with the wrong type, truncated data, duplicated data, inconsistent format etc. As our core business is to collect and process and analyze data from the biggest social networks, this finding was a major wakeup call.
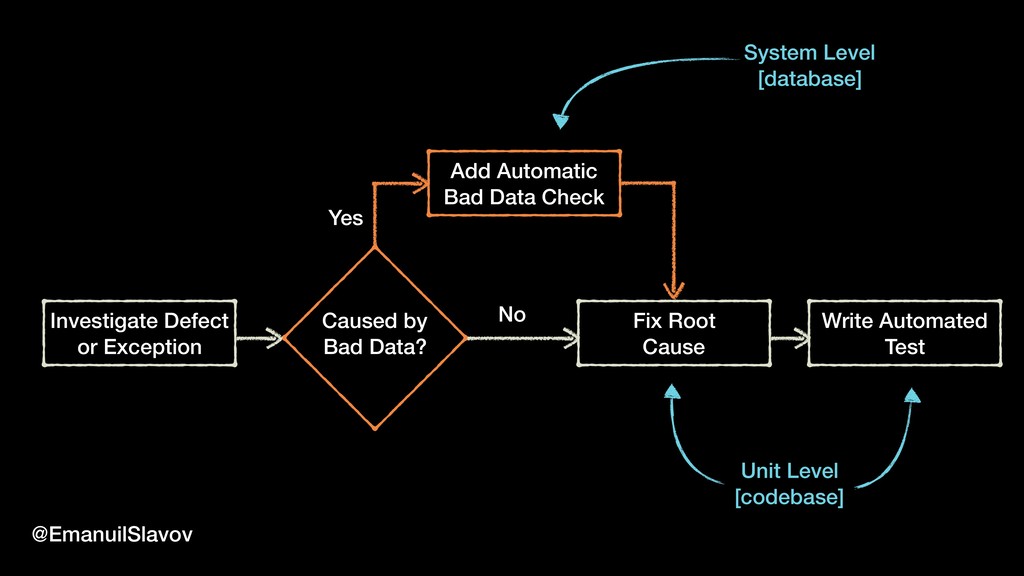
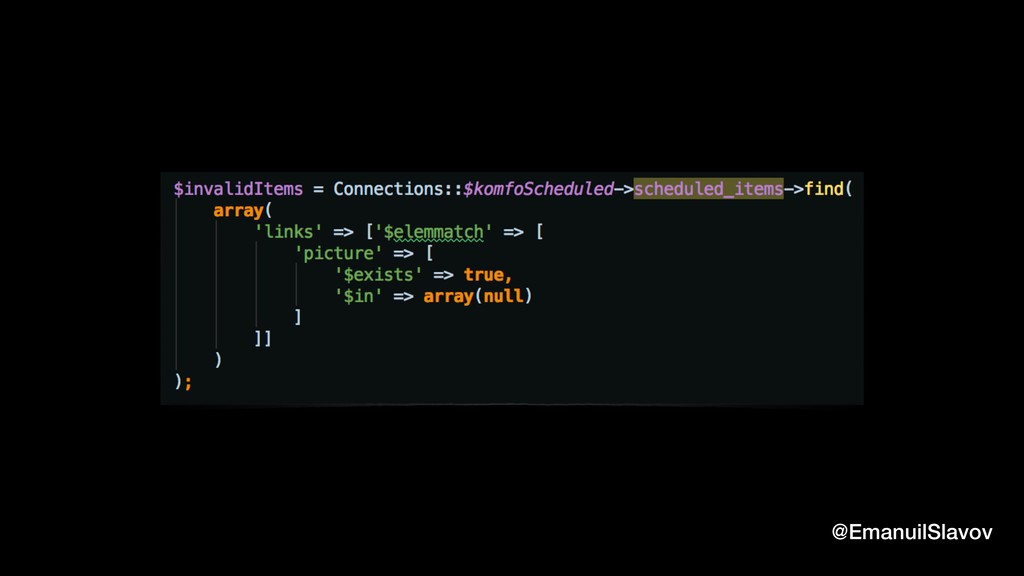
“Jidoka” is a term that comes from lean manufacturing. It means to give the machines “the ability to detect when an abnormal condition has occurred”. We wanted to go one step further and create a simple, yet robust system ability to not only recognize bad data but also to fix it automatically so that it can heal itself. As it turns out, in some cases, it’s faster/easier to fix bad data than to locate the code that produced it. This talk is a practical one, containing ideas and tips that you can quickly implement when dealing with data quality.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}