Slides from a talk given at the Hydra distributed computing conference on 6 July 2020.
https://martin.kleppmann.com/2020/07/06/crdt-hard-parts-hydra.html
https://hydraconf.com/2020/msk/talks/3mkcfa5h151ekfvfqau4qk/
Abstract:
Conflict-free Replicated Data Types (CRDTs) are an increasingly popular family of algorithms for optimistic replication. They allow data to be concurrently updated on several replicas, even while those replicas are offline, and provide a robust way of merging those updates back into a consistent state. CRDTs are used in geo-replicated databases, multi-user collaboration software, distributed processing frameworks, and various other systems.
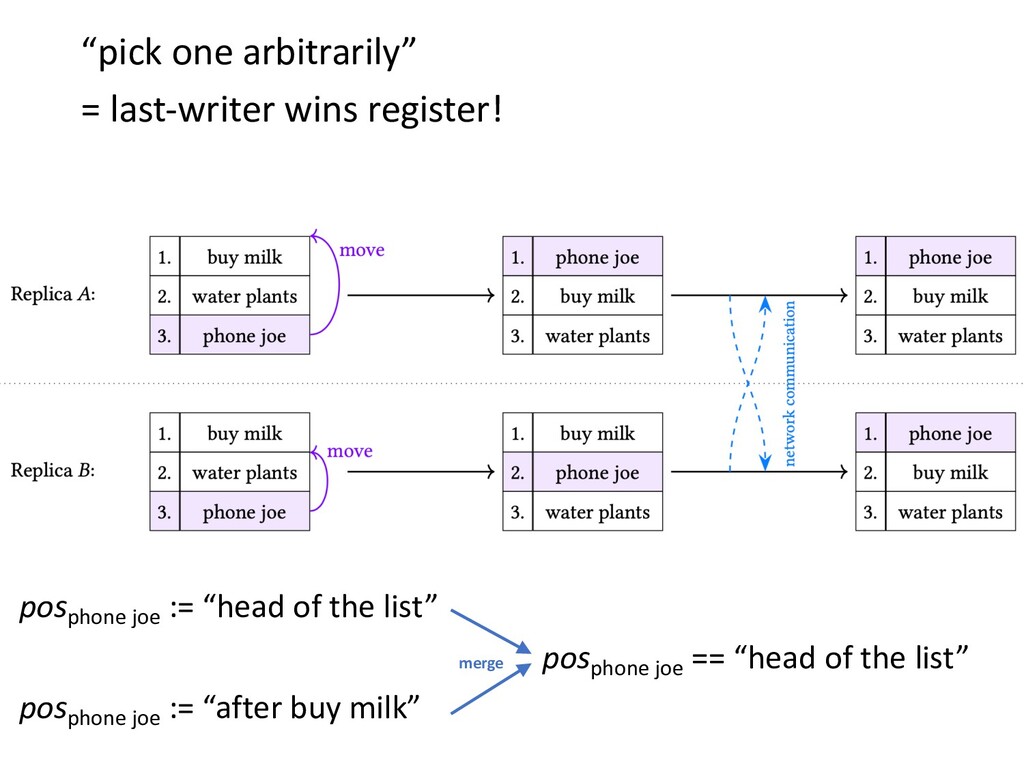
However, while the basic principles of CRDTs are now quite well known, many challenging problems are lurking below the surface. It turns out that CRDTs are easy to implement badly. Many published algorithms have anomalies that cause them to behave strangely in some situations. Simple implementations often have terrible performance, and making the performance good is challenging.
In this talk Martin goes beyond the introductory material on CRDTs, and discusses some of the hard-won lessons from years of research on making CRDTs work in practice.
Bio:
Dr Martin Kleppmann is a researcher in distributed systems at the University of Cambridge, and author of the acclaimed "Designing Data-Intensive Applications" (O'Reilly Media, 2017). He mainly works on collaboration software, CRDTs, and formal verification of distributed algorithms. Previously he was a software engineer and entrepreneur at Internet companies including LinkedIn and Rapportive, where he worked on large-scale data infrastructure.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Thanks! • Martin’s email: [email protected] • Martin on Twitter: https://twitter.com/martinkl](https://files.speakerdeck.com/presentations/71c432e2f3004c6e991bed35810cecfe/slide_76.jpg){kind=link}