Slides from my talk at Berlin Buzzwords, 27 May 2014. http://berlinbuzzwords.de/session/samza-linkedin-taking-stream-processing-next-level
Video: https://www.youtube.com/watch?v=d63kSjxVsGA&list=PLeKd45zvjcDHJxge6VtYUAbYnvd_VNQCx
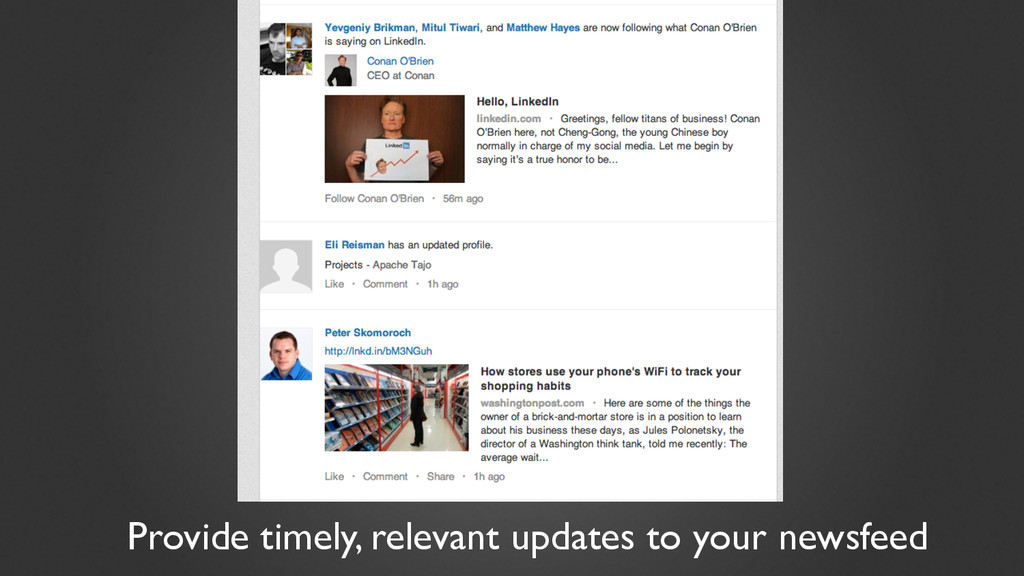
Stream processing is an essential part of real-time data systems, such as news feeds, live search indexes, real-time analytics, metrics and monitoring. But writing stream processes is still hard, especially when you're dealing with so much data that you have to distribute it across multiple machines. How can you keep the system running smoothly, even when machines fail and bugs occur?
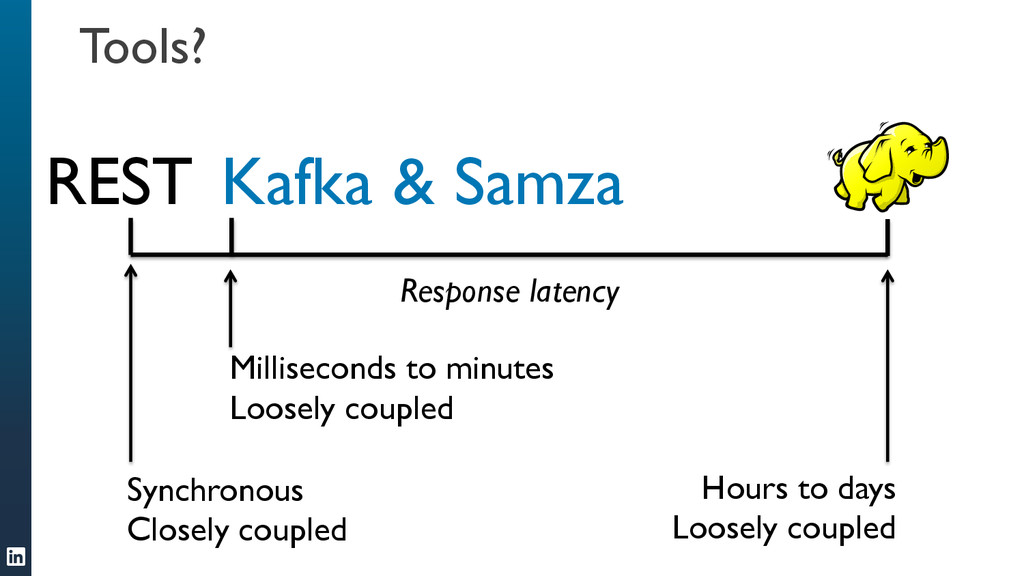
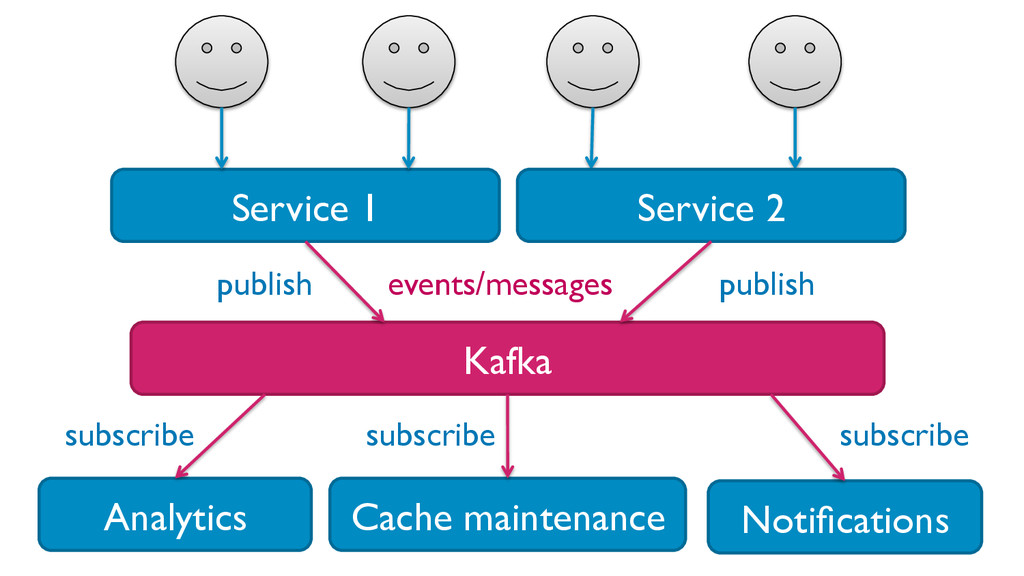
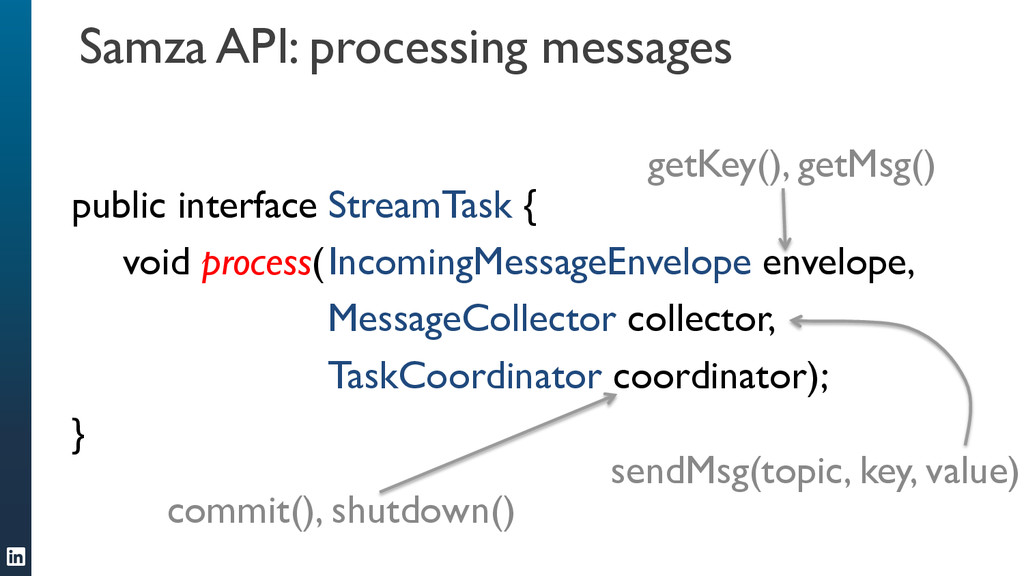
Apache Samza is a new framework for writing scalable stream processing jobs. Like Hadoop and MapReduce for batch processing, it takes care of the hard parts of running your message-processing code on a distributed infrastructure, so that you can concentrate on writing your application using simple APIs. It is in production use at LinkedIn.
This talk will introduce Samza, and show how to use it to solve a range of different problems. Samza has some unique features that make it especially interesting for large deployments, and in this talk we will dig into how they work under the hood. In particular:
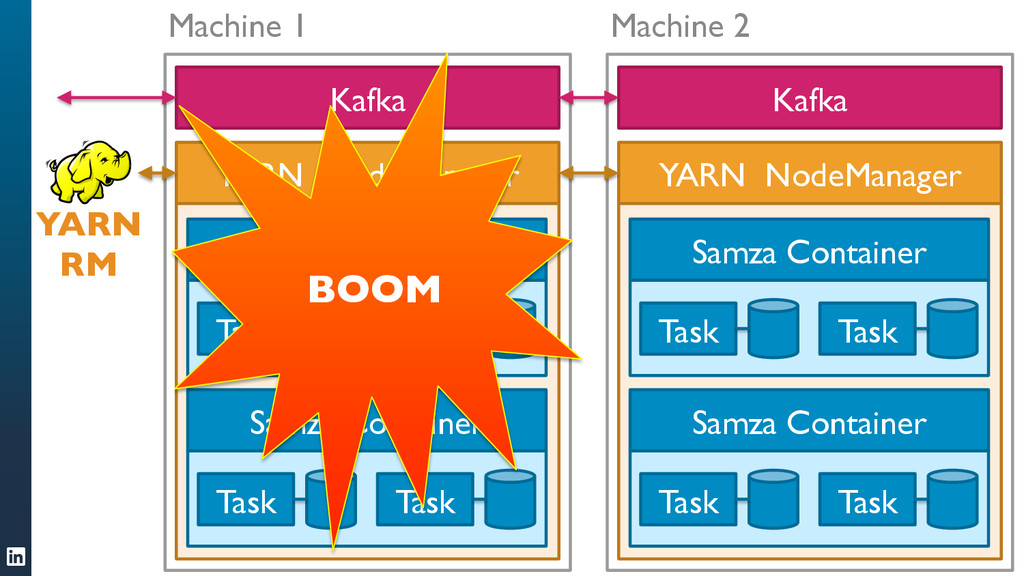
• Samza is built to support many different jobs written by different teams. Isolation between jobs ensures that a single badly behaved job doesn't affect other jobs. It is robust by design.
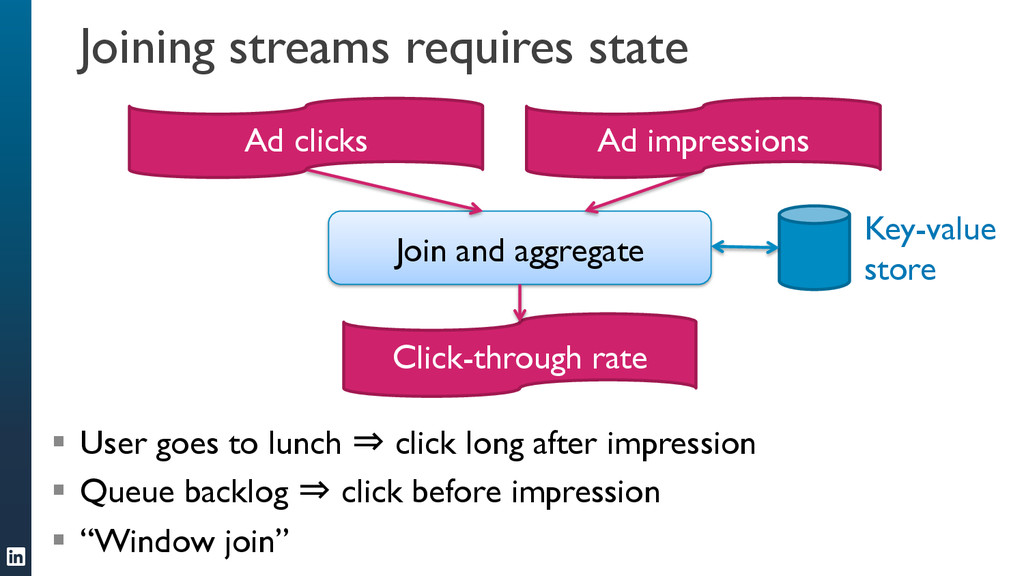
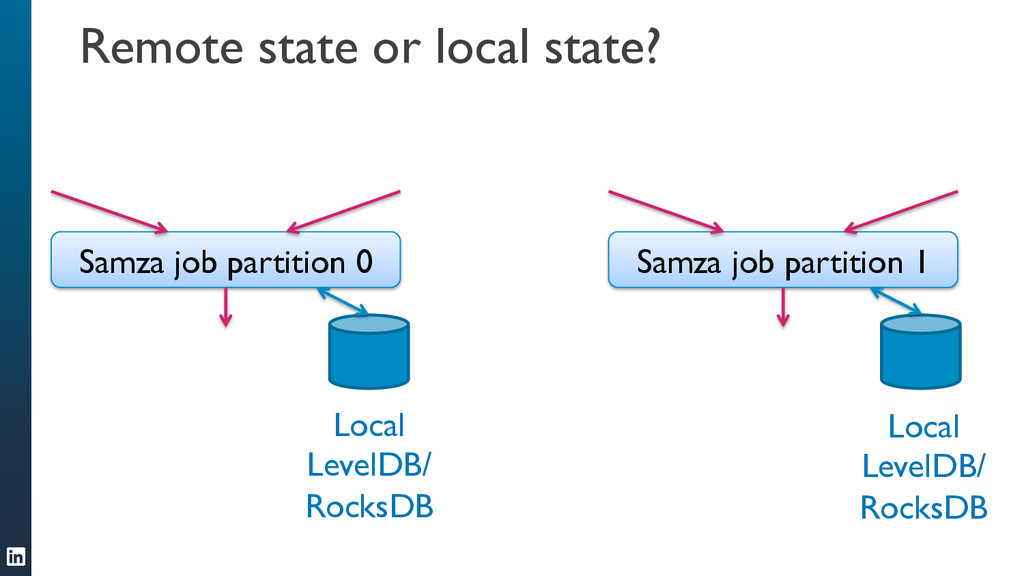
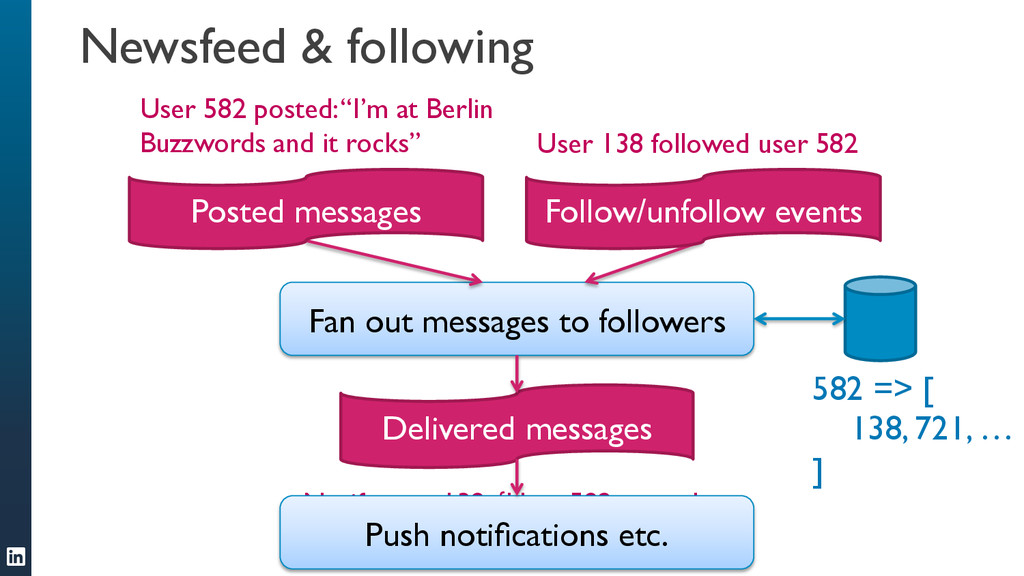
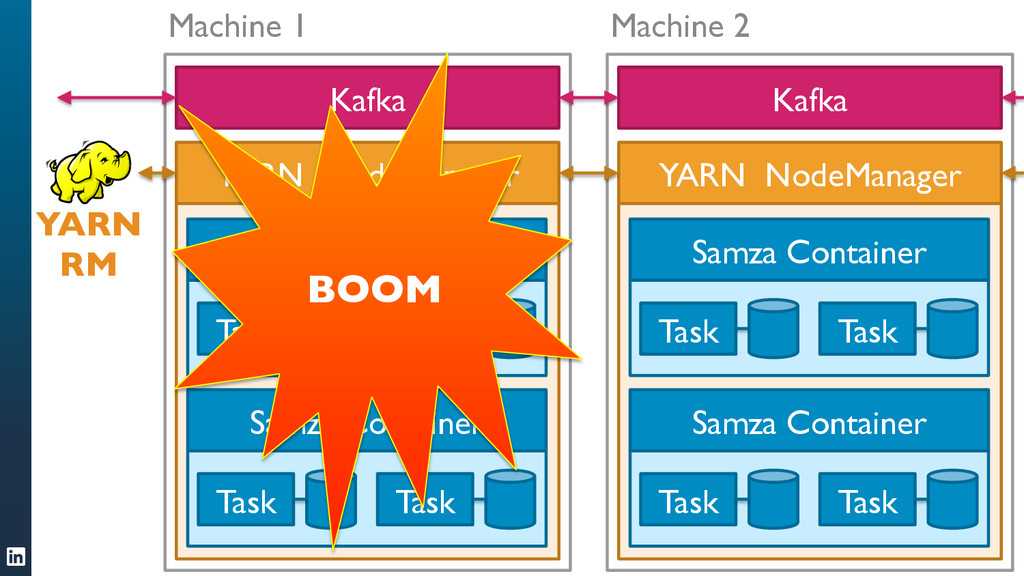
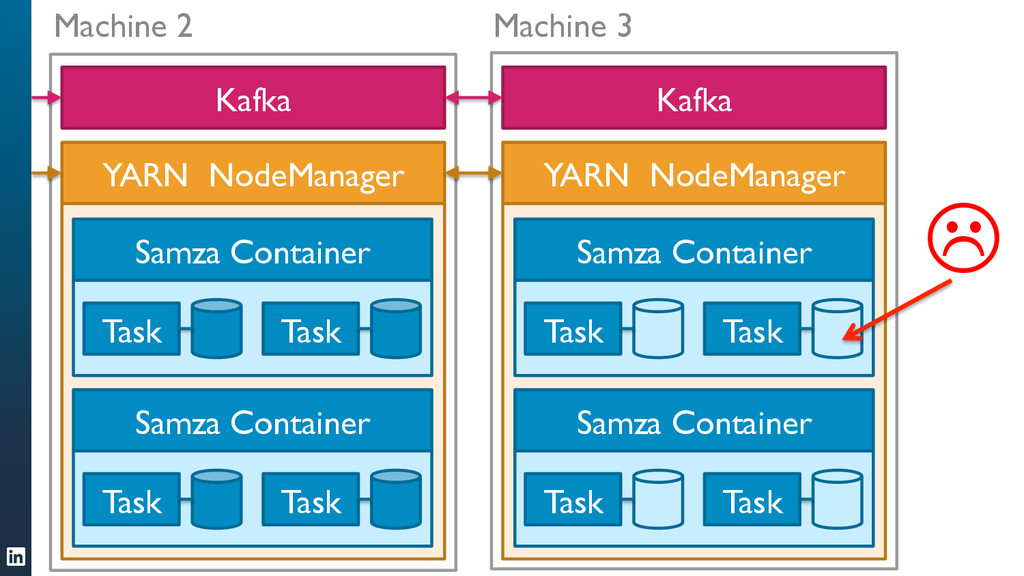
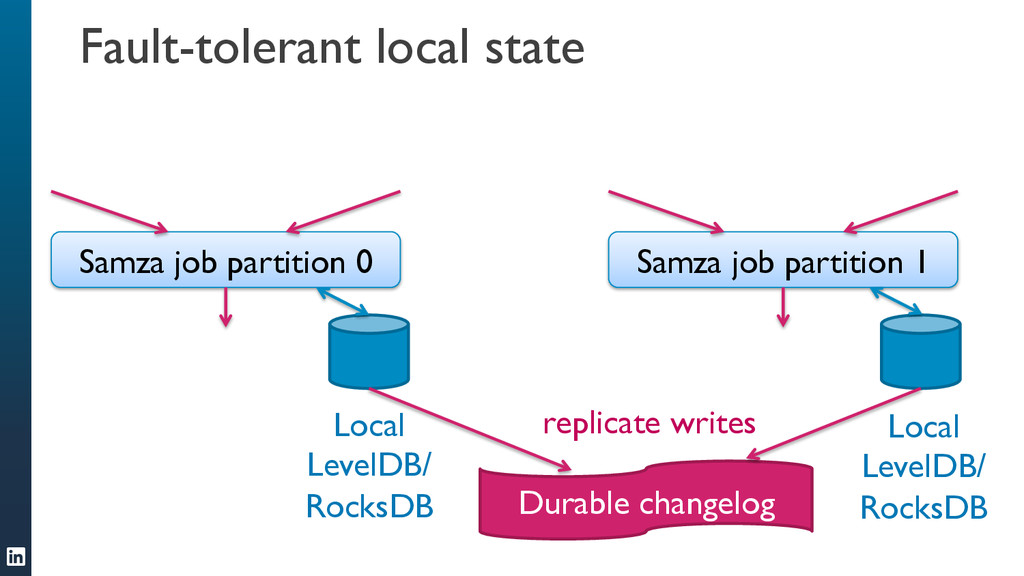
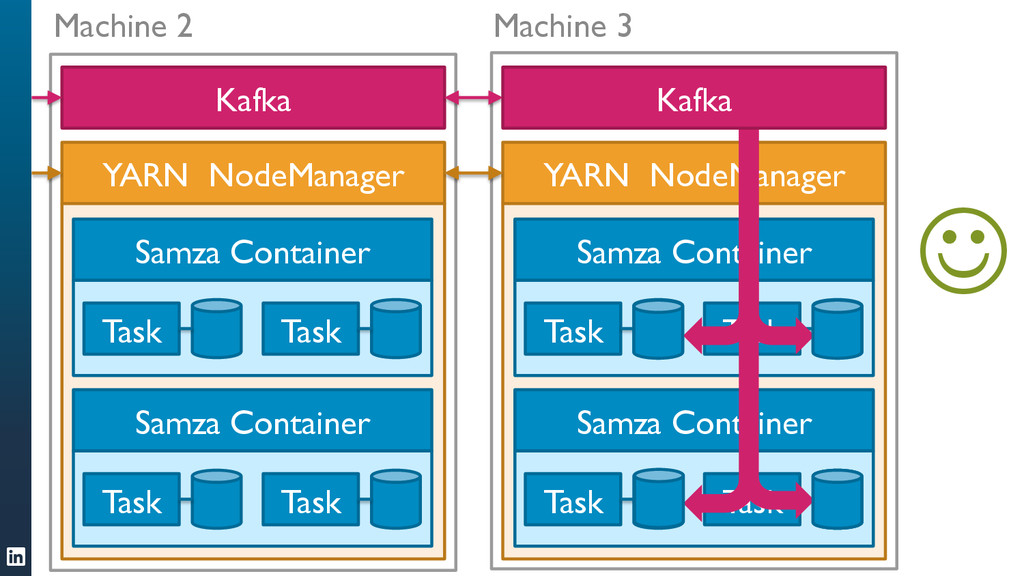
• Samza can handle jobs that require large amounts of state, for example joining multiple streams, augmenting a stream with data from a database, or aggregating data over long time windows. This makes it a very powerful tool for applications.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}