Computational Science and Engineering. Applied Scientist Maritime Intelligence. Spend a lot of my time worrying about how to process remote sensing data efficiently.
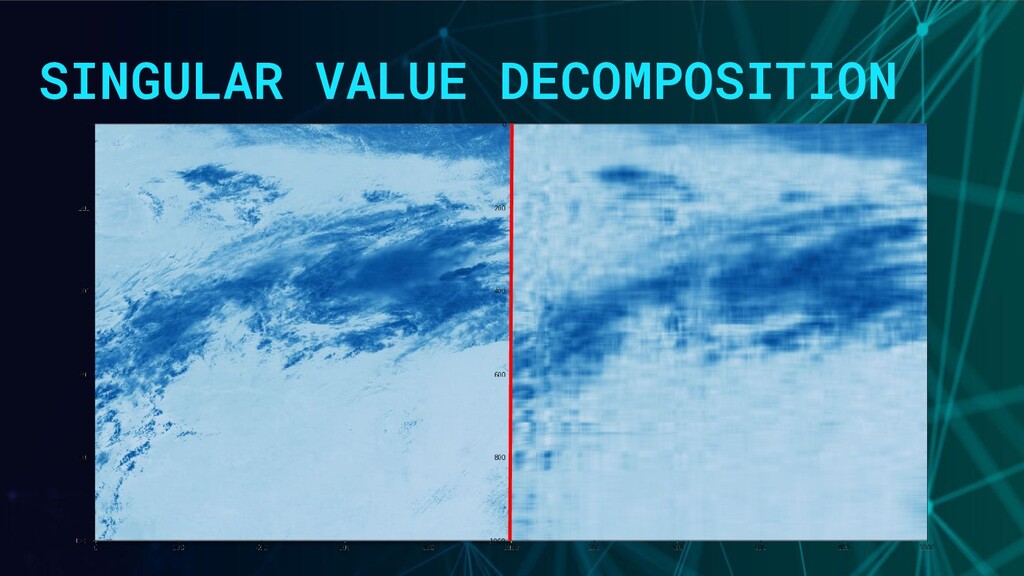
Processing. - Decomposes a matrix into low-rank matrices. - Reduces the model size. - Takes advantage of sparsity, given the amount of small singular values.
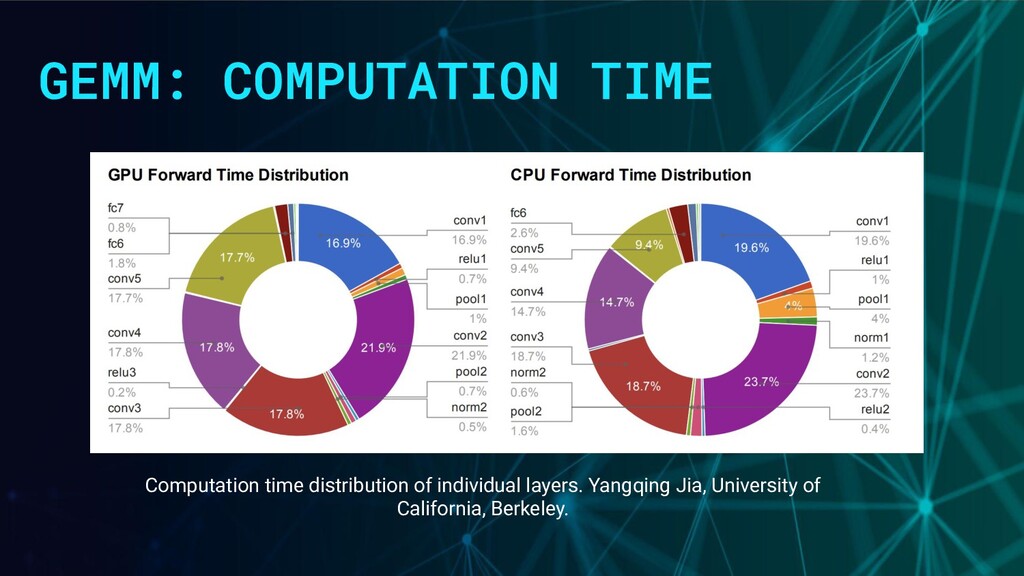
fastest computers available. - Fundamental building block for fully connected, recurrent, and convolutional layers. - The most common LA optimization trick in DNNs you never hear of.
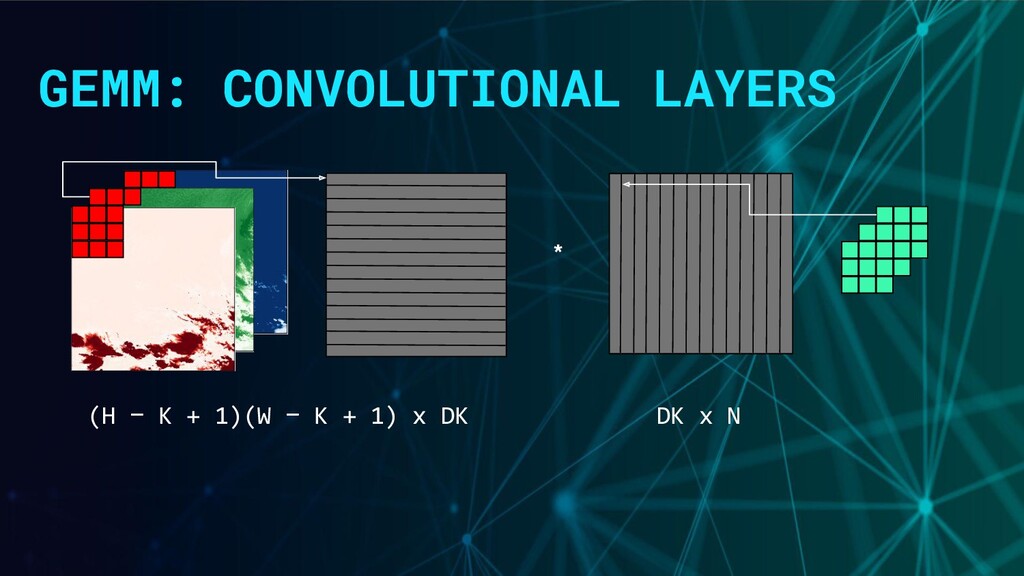
array that we can treat like a matrix. Same for kernel weights. In TensorFlow, Intel MKL, cuBLAS: using data format, data representation of nD tensors stored in linear (1D) memory address space. NCHW: default in Theano NHWC: default in TensorFlow
patches rows, and # of filters cols. // It's laid out like this, in row major order in memory: // < filter value count > // ^ +---------------------+ // patch | | // count | | // v +---------------------+ // Each patch row contains a filter_width x filter_height patch of the // input, with the depth channel as the most contiguous in memory, followed // by the width, then the height. This is the standard memory order in the // image world if it helps to visualize it. // Now we've assembled a set of image patches into a matrix, apply a // GEMM matrix multiply of the patches as rows, times the filter // weights in columns, to get partial results in the output matrix.
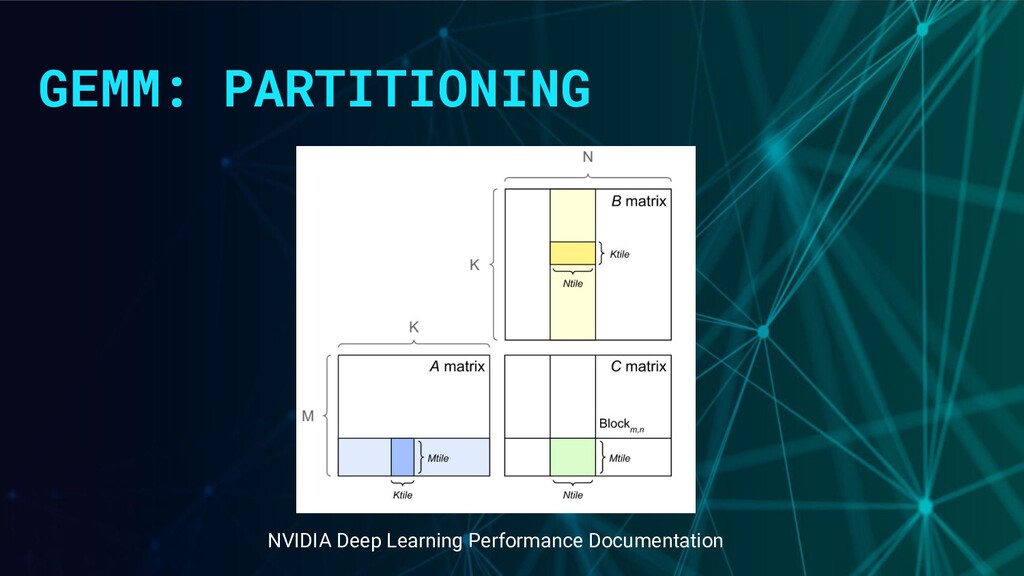
matrix decompositions Halko, et al., 2009 Anatomy of High-Performance Matrix Multiplication. Kazushige Goto and Robert A. van de Geijn, 2008. Using Intel® Math Kernel Library for Matrix Multiplication. NVIDIA® Deep Learning Performance Documentation.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}