CPU/GPU time is spent on convolutional and fully-connected layers. Matrix Partitioning: Like multiplying two matrices with scalar elements, but with the individual elements replaced by submatrices.
patches rows, and # of filters cols. // It's laid out like this, in row major order in memory: // < filter value count > // ^ +---------------------+ // patch | | // count | | // v +---------------------+ // Each patch row contains a filter_width x filter_height patch of the // input, with the depth channel as the most contiguous in memory, followed // by the width, then the height. This is the standard memory order in the // image world if it helps to visualize it. // Now we've assembled a set of image patches into a matrix, apply a // GEMM matrix multiply of the patches as rows, times the filter // weights in columns, to get partial results in the output matrix.
array that we can treat like a matrix. Same for kernel weights. In TensorFlow, Intel MKL, cuBLAS: GER, using data format, data representation of nD tensors stored in linear (1D) memory address space. NCHW: default in Theano NHWC: default in TensorFlow
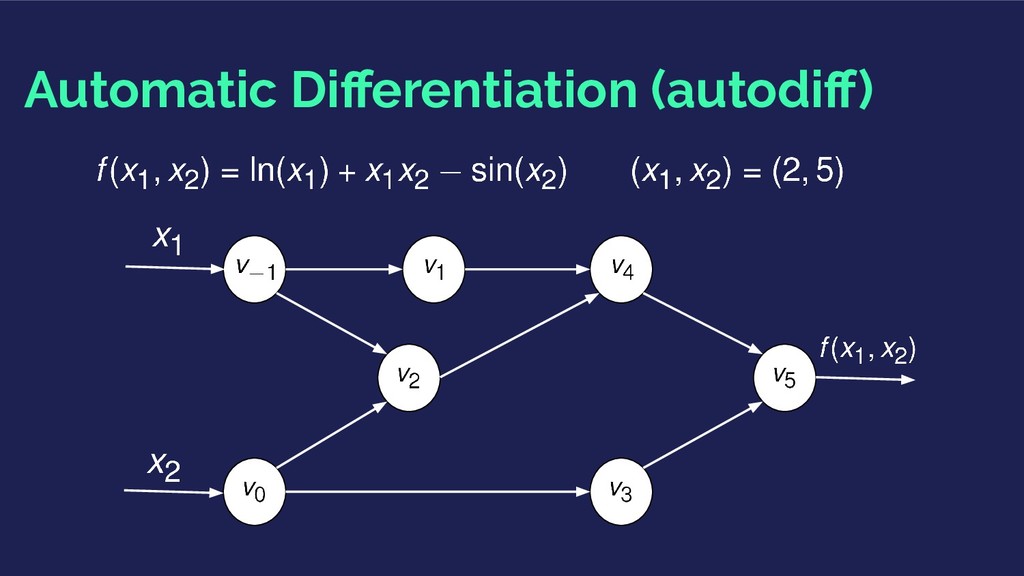
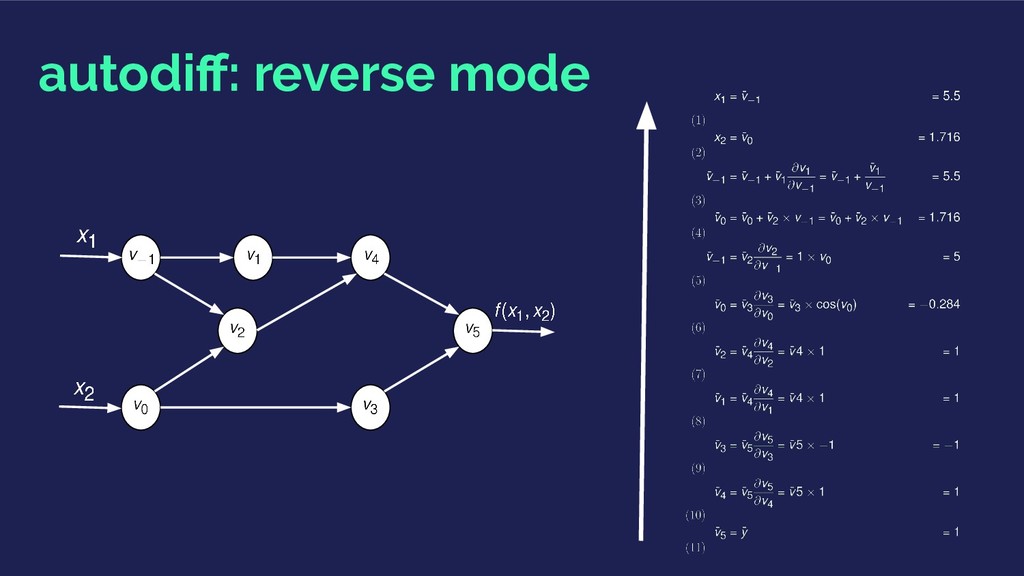
of gradients and hessians of an objective function. 1. Calculate analytical derivatives and code them: time consuming, requires closed-form solutions. 2. Numerical differentiation using finite differences: slow with partial derivatives. 3. Symbolic differentiation: expression swell 4. Automatic Differentiation
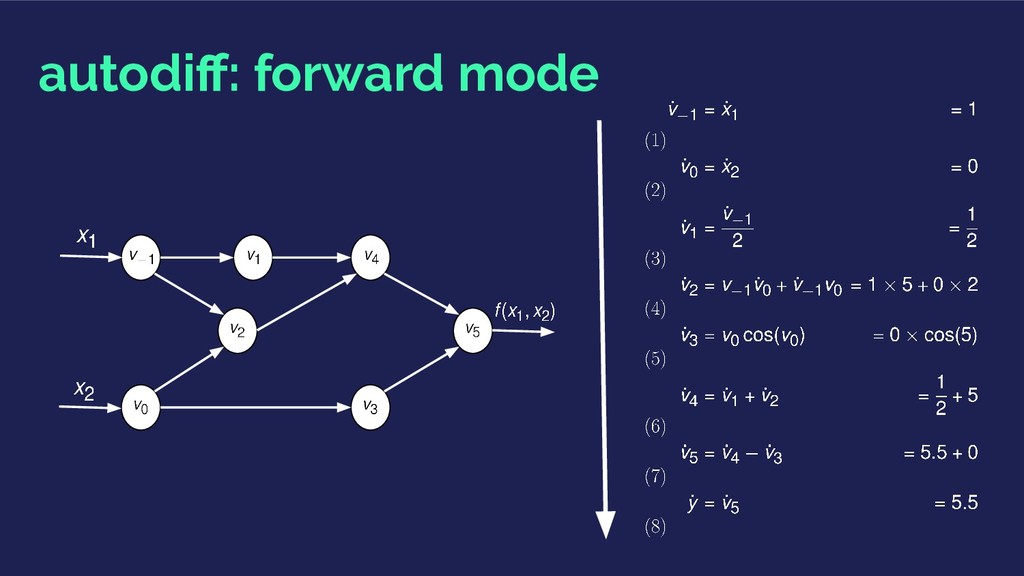
propagating the chain rule of differential calculus. Generate numerical derivative evaluations rather than derivative expressions: Computational Graphs.
using the chain rule to compute partial derivatives of the objective with respect to each weight. Special case of reverse mode autodiff: they have a ❤ history. Theano, Torch and TensorFlow are bringing general purpose autodiff to the mainstream.
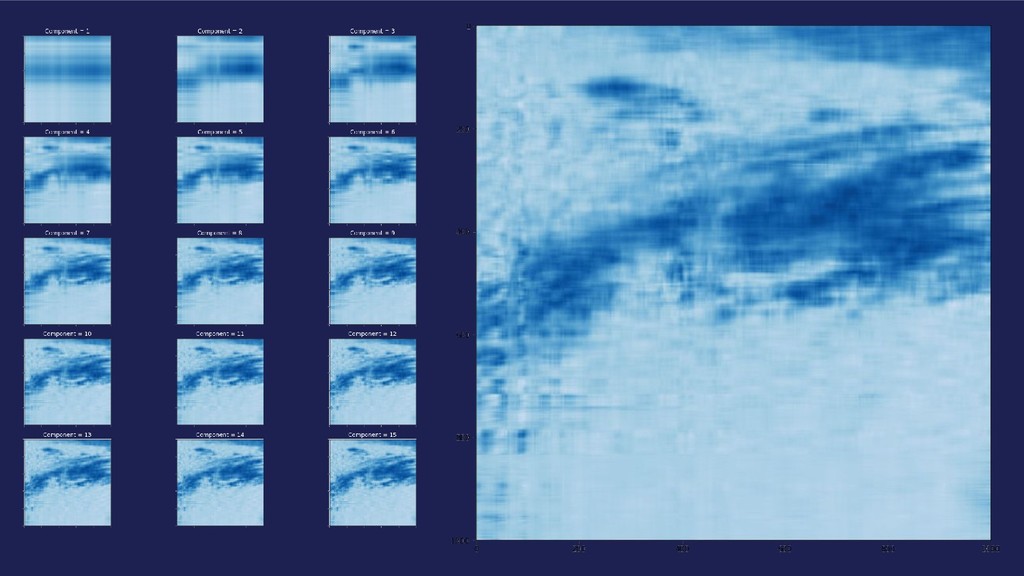
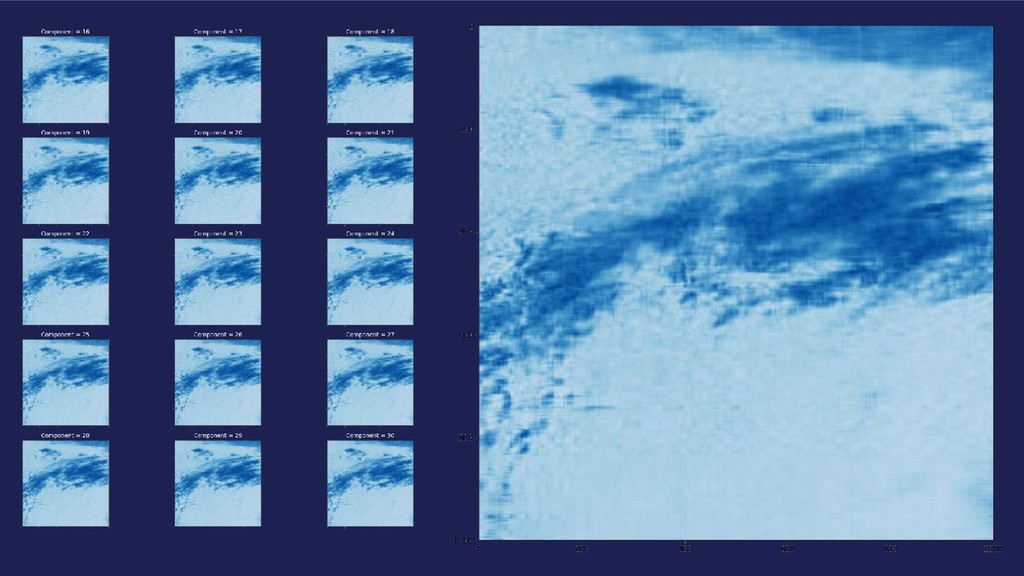
matrix decompositions Halko, et al., 2009 https:/ /arxiv.org/abs/0909.4061 Linear Algebra and Learning from Data. Gilbert Strang, 2019. https:/ /www.tensorflow.org/api_docs/python/tf/Gradi entTape
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}