la Direction interministérielle du numérique (DINUM), le Laboratoire pour l’intelligence artificielle (Lab IA) accompagne les administrations dans le déploiement de leurs projets IA et renforce leurs capacités en data science.
open source qui répondent à des besoins récurrents des administrations 🎯 Exemples: Outil de pseudonymisation de textes PIAF (Pour des intelligences artificielles francophones) Lab IA d’Etalab
d’exploiter en masse des documents administratifs sous des formats non directement exploitable (PDF scannés, images, etc.). Irritant : L’information contenue dans ces documents, pour être exploitées, doit passer par une étape d'extraction et de structuration de l’information, qui est vite très chronophage si elle doit être réalisée à la main.
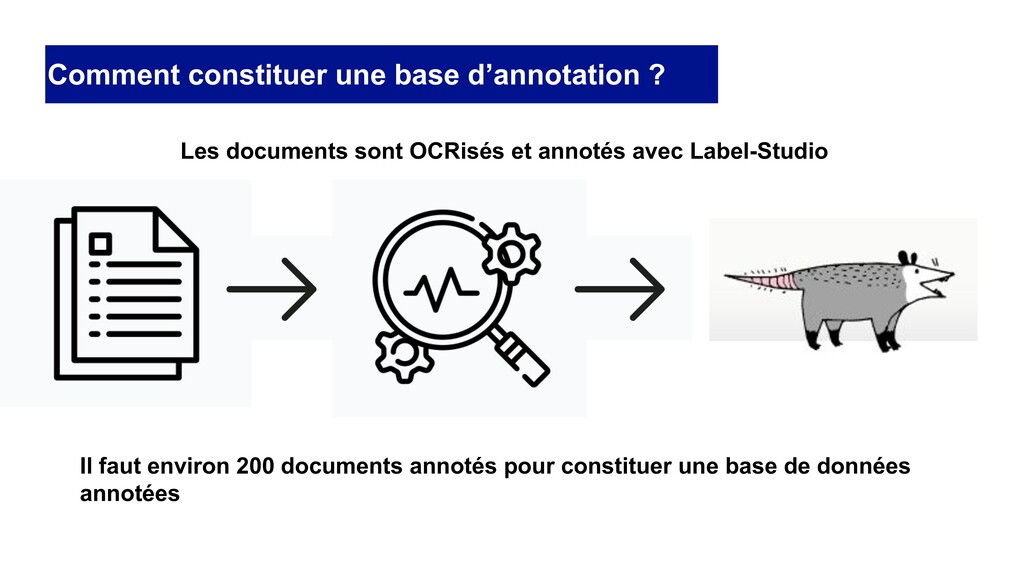
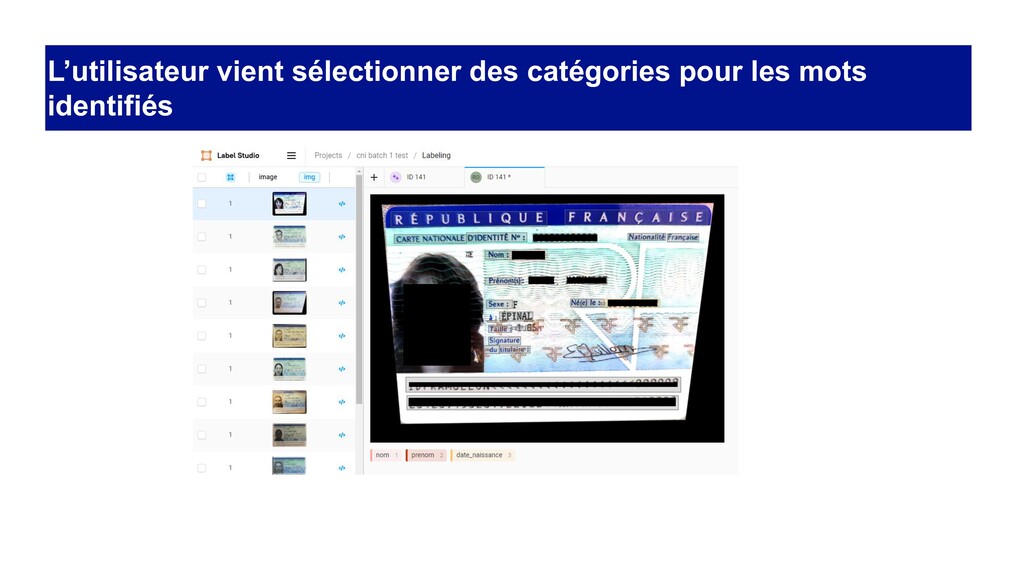
des documents et qui permet de: • OCRiser les documents au format image (PDF scannées, photos, images, etc) • Extraire des informations ciblées • Annoter des documents pour entraîner un modèle “customisé” lorsque les informations à extraire ne sont pas standards
de naissance des cartes d’identité pour vérifier automatiquement la validité des pièces d’un dossier • Extraction des noms, prénoms, employeur, salaire des fiches de paye • Numérisation et extraction d’informations des documents juridiques (délibérations, décisions de justices, etc)
d’OCR éprouvées, nombreuses solutions disponibles en open source • L’extraction d’information est une tâche plus complexe, les performances d’algorithmes de machine learning dépendront de la complexité des informations à extraire • Les gains à automatiser le processus d'extraction d’information, par rapport à une extraction manuelle, sont potentiellement très importants • Garder en tête qu’une précision de 100% n’est pas atteignable dans la majorité des cas. L’automatisation est pertinente lorsque les gains de temps compensent largement la perte en précision qui peut résulter de l’automatisation par rapport à la tâche manuelle
documents pour des agents publics • Accélérer le traitement des dossiers des usagers d’un service numérique : exemple de DossierFacile: l’automatisation permettra aux personnes qui déposent des dossiers d’obtenir une validation en temps réél lorsque les informations extraites des dossiers sont cohérentes • Proposer de nouveaux services grâce à l’exploitation de documents jusque là inexploités: Exemple pour les hôpitaux et des moteurs de de recherche pour les dossiers patients: un volume très important de pièces de dossiers scannés qui ne sont pas exploitées et qui contiennent pourtant des informations médicales sur le patient
propriétaires est élevé et souvent décourageant • Capitalisation du code et des modèles sur les différents cas d’usages • Meilleure sécurisation des données • A l’heure actuelle, difficulté pour les administrations d’identifier l’acteur privé le plus pertinent devant la multiplicité des offres
: MVP de la solution avec • Une application pour les cartes d’identités (CNI) et les feuilles de paye avec les fonctionnalités suivantes: ◦ Charger les documents sous différents formats ◦ Classifier le type de document ◦ Extraire les informations pertinentes (nom, prénom) • Une solution d’annotation pour annoter de nouveaux documents
: MVP de la solution avec • Une application permettant de lancer l’entraînement du modèle facilement avec une option pour ré-entraîner le modèle avec les corrections manuelles ou les nouvelles annotations • Amélioration des modèles • Extraction de nouveaux contenus.
Prénom Is_nom ? Is_numb er ? Label Nom: 0 En haut 0. 0. O Prénom: En bas 0 0. 0. O Berthier A droite En haut à droite 1. 0. Nom Corinne En bas à droite A droite 0.3 0. Prenom Comment fonctionne le modèle ?
pour monitorer les performances du modèle et le réentrainer avec de nouvelles données issues des prédictions corrigées Une App web Une API Comment utiliser le modèle ?
Kien): Partage de cas d’usages • Atelier 2 (Kim): Retours d’expériences sur des solutions existantes et tests des applications développées à date par le Lab IA • Atelier 3 (Robin): Retours d’expériences sur les librairies et les modèles pour l’OCR, l’extraction d’informations et l’apprentissage en ligne
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Nous avons besoin de vous ! [email protected]](https://files.speakerdeck.com/presentations/391901968975473dbbae7f1a78a2c160/slide_25.jpg){kind=link}