Kubernetes-based GPU as a Service Platform at CyberAgent [INSIGHT 2021 Digital]
We will introduce an example of building and providing a platform that continues to evolve flexibly on NetApp® AFF A800 and NVIDIA DGX A100, adopting OSS such as Kubernetes with Trident.
in 2016, worked as a solutions architect for ad products and was in charge of private cloud and GKE-compatible container platform development. As AI infrastructure project manager, engaged in AI platform development. Lee Yeongjae Masaya Aoyama Daisuke Takahashi Software Engineer Hired by CyberAgent out of college in 2016. Built a private cloud and GKE-compatible container platform from scratch with OpenStack. Co-chair of Japan's biggest Cloud Native conference, official CNCF community organizer, etc. Infrastructure Engineer Hired by CyberAgent out of college in 2019. After working on private cloud operation and container infrastructure development, now leads the ML/3DCG/adtech domains as a Solutions Architect. Handled physical layer design and operation for this project.
business domain knowledge • Automated ad generation Improving impact • Identify unexpectedly effective ads • Improve ad impact analysis Reducing risk • Avoid risk of controversies from ad placement
complex info • The combination of ads and posted media is huge • Enormous info referencing population statistics (area, age, etc.) Fast execution • Trends change fast • Get real-time info
Jupyter Notebook : Execution environment for interactive GUI programs Google AI Platform : Manage ML workflows with Client Tools/GUI Train & evaluate model Deploy model Model with inferences Monitor inferences Manage model versions Implement code, prepare input data
of GPU resources for researchers ◦ Assigns an entire host to each researcher exclusively v2: GPU containers + Jupyter Notebook • Managed Notebook environment for researchers • Or primitive GPU containers, just as v1 v3: GPU containers + Jupyter Notebook + AI Platform • Expanded availability to developers in addition to researchers • Hosting AI platform (GCP-compatible) on top of GPUaaS
of researchers’ workstations ◦ Assigns 1 host (node) per user • Located at server room in our office ◦ GPU: 20x NVIDIA GeForce GTX 1080Ti 11 GB (220 GB) ◦ CPU: 324 cores ◦ Memory: 1.28 TB Environment for easier reproduction • Simplified recreation of experiment environment with container virtualization • Adopted Kubernetes, a proven option at CyberAgent ◦ Offers direct access to Kubernetes API
from v1 • Changed assignment policy to shared use (multi-tenancy) NEW: Shared storage for datasets • Could mount same data from containers • Software-defined storage on Kubernetes ◦ NFS service by Rook (Ceph) ◦ Usable Capacity: 48 TB with SATA SSDs NEW: Managed training environment • Launch Jupyter Notebook w/o Kubernetes knowledge • Could bring custom container images, optionally
is NOT a datacenter ◦ Reached the limit of power and cooling ◦ Regular blackouts for legal inspection • Poor connection quality ◦ Site-to-site VPN only ◦ Non-redundant network Machine maintenance • Lack of remote management feature ◦ BMC not equipped (field ops required) ◦ Restricted access to office for COVID-19 Performance • Insufficient GPU memory ◦ GeForce series not designed for ML • Outdated hardware ◦ Newer CPUs and GPUs come out ◦ Increasing rate of hardware failures
platform for their services To achieve the required quality, we had to address issues in v2 Location / Site • Escape from office building • Use existing datacenter in Tokyo for our private cloud Specs • Brand-new servers for GPUaaS (IPMI required) • Enterprise-grade GPUs with massive memory ◦ Tesla V100, T4, etc.
(V100) New hardware features • Multi-Instance GPU, Sparsity, etc. Faster GPU-to-GPU interconnection • 3rd Gen NVLink2nd Gen NVSwitch • Up to 16 GPUs • Full mesh topology at 600 Gbps each
can run seven jobs in parallel on an A100 GPU (NVIDIA Blog) Multi-tenancy • For DGX A100, its 8 GPUs can be sliced into 56 GPU instances • Administrators can assign right-sized GPUs for each job Guaranteed QoS • All GPU instances include isolated memory (capacity/bandwidth) and cores
◦ GPU: 8x NVIDIA A100 40 GB (320 GB) ◦ CPU: 128 cores ◦ Memory: 1 TB ◦ Testing combination of new HW features and Kubernetes (Thanks to the people at NVIDIA for helping out!) ▪ Details on software later • Installed in DGX-Ready datacenter ◦ Verified location for power, cooling, installation
Low capacity efficiency per rack space → Should introduce large capacity drives and/or chassis with many disk slots • Insufficient throughput for transferring datasets (compared with A100 GPU's performance) → Should improve disk and network performance Focus on using storage, not operating • Rook (Ceph) was a suitable option to reuse existing resources ◦ Not motivated to operate SDS since the purpose is providing storage space → Should consider appliances, not just SDS Additional features • Want block access for internal metadata DBs of GPUaaS
AFF A800 ◦ NVMe SSD 62 TB (All-lash) ▪ Capable to scale-out/scale-up by adding: • Disks (into empty bays) • Disk shelves • Controllers ◦ Multi-protocol access ▪ File (NFS, SMB), Block (iSCSI ,etc.), Object (S3) ◦ Details on Kubernetes integration later • Selected with NVIDIA DGX POD in mind ◦ Scalable reference architecture for DGX system and storage ◦ NetApp announced as ONTAP AI * Photo of the evaluation system. Some configurations differ.
◦ Can easily create an image of the execution environment (cf. VM, metal) ◦ Low overhead, loads in short time (cf. VM) ◦ Can implement multi-tenancy environments for multiple users (cf. Metal) • Disadvantages of containers ◦ Low isolation compared to VM (cf. VM) ◦ Short environment life cycle (cf. VM, Metal)
◦ Can easily create an image of the execution environment (cf. VM, metal) ◦ Low overhead, loads in short time (cf. VM) ◦ Can implement multi-tenancy environments for multiple users (cf. Metal) • Disadvantages of containers ◦ Low isolation compared to VM (cf. VM) ◦ Short environment life cycle (cf. VM, Metal)
◦ Can easily create an image of the execution environment (cf. VM, metal) ◦ Low overhead, loads in short time (cf. VM) ◦ Can implement multi-tenancy environments for multiple users (cf. Metal) • Disadvantages of containers ◦ Low isolation compared to VM (cf. VM) ◦ Short environment life cycle (cf. VM, Metal)
◦ Can easily create an image of the execution environment (cf. VM, metal) ◦ Low overhead, loads in short time (cf. VM) ◦ Can implement multi-tenancy environments for multiple users (cf. Metal) • Disadvantages of containers ◦ Low isolation compared to VM (cf. VM) ◦ Short environment life cycle (cf. VM, Metal)
◦ Can easily create an image of the execution environment (cf. VM, metal) ◦ Low overhead, loads in short time (cf. VM) ◦ Can implement multi-tenancy environments for multiple users (cf. Metal) • Disadvantages of containers ◦ Low isolation compared to VM (cf. VM) ◦ Short environment life cycle (cf. VM, Metal)
on multiple containers. That means we need container orchestration tools. Kubernetes is one container orchestration tool. Computing resource pool Storage pool • Storage system ◦ Block ◦ Shared filesystem ◦ Others • Scheduling • Rolling updates • Health checks • Auto/Scaling • Malfunction self-healing • Authentication & authorization • Service discovery • Load balancing • Attach confidential info • Multi-tenancy • Integration with storage
plugable. Kubernetes can handle various devices. • GPU (NVIDIA/AMD/Intel) • TPU (Tensor Processing Unit) • FPGA • etc. We use Prometheus + DCGM Exporter for monitoring. Users have a dashboard to check GPU usage, etc. Note: You can optimize NUMA and GPU Topology by using InfiniBand with Kubernetes. (Container runtime must be compatible) containers: - name: mljob image: my-mljob:v0.1 resources: limits: nvidia.com/gpu: 1 nvidia.com/mig-3g.20gb: 1
uses programs called controllers to control systems. Multiple controllers bring things into a declared state. ◦ Maintain specified number of replicas ◦ Recovery from containers shut down by broken nodes ◦ Auto reload when changing confidential info or config file ◦ Auto management of load balancer members ◦ etc. Actual ReplicaSet (replicas=3) Watch ReplicaSet Controller kind: ReplicaSet spec: replicas: 3 template: spec: containers: - image: nginx:1.16 Desired State Watch
technology and develop and release various OSS integrated with Kubernetes. By using an OSS expansion controller employing a reconciliation loop, you can let Kubernetes handle most routine operations. • Prometheus / Grafana: monitors GPU and wide-ranging middleware • cert-manager: manages auto generation of certificates using ACME; auto integrates with load balancers • external-dns: manages provided IP address and DNS records • oauth2-proxy + nginx ingress: integrates OAuth2 with requests to WebUI • Others: auto scaling, progressive delivery, data transmission between projects, etc.
extendable and enables expansion of features tailored to our company's specific domains. It also offers a framework for mounting controllers (even using general OSS). Examples: • Auto data load + cash from S3/GCS (Custom Controller) • Auto inject of authentication info for cloud (Mutating Webhook) • Metadata storage using application instead of database (Secret/ConfigMap) • Billing system based on info retrieved from Kubernetes Our implementation also keeps pace with standardization: container runtime (OCI/CRI), networks (CNI), storage (CSI), etc.
Huge ecosystem Highly extendable platform • Restoration capability • Easy management • Observability • Frequent updates with robust automation • etc. 1 2 3 ⇒ As we track the evolution of OSS, we are guiding business to success by continuing to improve upon platforms.
Interface (CSI) to integrate storage with Kubernetes. • CSI is an interface that connects container orchestrators with storage. It can handle multiple orchestrators and multiple storage products. CSI only defines open specifications. Features used differ according to the CSI driver. ◦ https://github.com/container-storage-interface/spec ◦ https://kubernetes-csi.github.io/docs/drivers.html Storage Container Orchestrator Container Storage Interface • Volume production/deletion • Volume attachment/detachment • Volume expansion • Volume cloning • Snapshot & restore • Topology designation • RAW volume production
into multiple sub-features. Storage features are adequate but unusable without a compatible CSI driver. The lack of infrastructure features could prevent upper services from providing value. CSI driver considerations when selecting storage: 1. Tracking speed of Kubernetes upstream features (release frequency, upstream participation) 2. CSI driver quality (including bug fix speed) Since before CSI, NetApp has made Trident. It has very good release frequency, features, and quality. Container Orchestrator Container Storage Interface Storage Trident
Driver implementation is not a black box. • Our team wants to avoid always having to wait when a problem occurs Excellent development organization • Three-month release cycle (since Dec 2016) • Proactive contributions to the community mean we can expect fast upstream response Compatibility with both ReadWriteOnce and ReadWriteMany (AFF at CyberAgent) • NAS: for ML workloads • SAN: for system applications building GPUaaS (databases, Prometheus, etc.)
dedicated web console or kubectl. Kubernetes API Server GPUaaS API Server $ kubectl ... • launch notebooks • Manage volumes • Show billing info • Manage projects • etc. Web Console kubectl A B
concept as tenants. We use ClusterRole and RoleBinding to manage permissions. "Add member to project from WebUI Console" = "Add RoleBinding" This allows seamless management. (It's like using a user database.) Other processes also possible on the WebUI Console, depending on role. UserA namespace UserB namespace TeamX namespace A B TeamY namespace admin clusterrole member clusterrole rolebinding
console For users unfamiliar with Kubernetes: data scientists, researchers, etc. 2. SSH-like environment using Kubernetes CLI $ kubectl exec -it PODNAME-0 -- bash PODNAME-0 #
developing machine learning infrastructure based on Kubernetes Can't implement as desired if lower layer features are inadequate ⇒ Storage features and CSI driver functionality are important DGX A100 AFF A800 AI Platform GPUaaS (Kubernetes) AI Platform Consider multi-DC rollout using Kubernetes portability
Can't train easily like on an AI platform Don't use since migration from cloud is hard (Multiple responses) What do you not like about the currently available GPUaaS? Why We Need an Original AI Platform
Google AI platform ML workflows ◦ Object storage as hub • Same operability as Google AI platform ◦ kubectl plugin features • Can reuse Google AI platform configuration files Training • Capable of hyperparameter tuning ◦ Use Kubeflow, a Katib component Inferences • Can make inference endpoints ◦ Use Kubeflow, a KFServing component • Model version management ◦ Use our original model metadata management infrastructure • External access to inference endpoints ◦ Authorization with Istio and External Authorization
Container Experiment • Individual execution of hyperparameter tuning • Write all settings (algorithms, etc.) Suggestion • Hyperparameter generation Trial • Training executed with the hyperparameters Metrics Container • Save model training prediction accuracy as metrics Metrics Collector • Write metrics to database and complete tuning Metrics Collector Katib DB Metrics Container
◦ Containers loaded by models ◦ Provide inference endpoint (FQDN) • Both preprocessing and post-processing OK • PodSpec descriptions allow custom containers
to models • Originally an infrastructure for follow-up tests and reproduction • Development/operation in other departments Special features • Savable model version histories • Can tie metadata to models ◦ Code, datasets, etc. • Controllable model access rights ◦ 3 patterns: Read, Write, RW • Can designate model location ◦ Compatible with GCS/S3
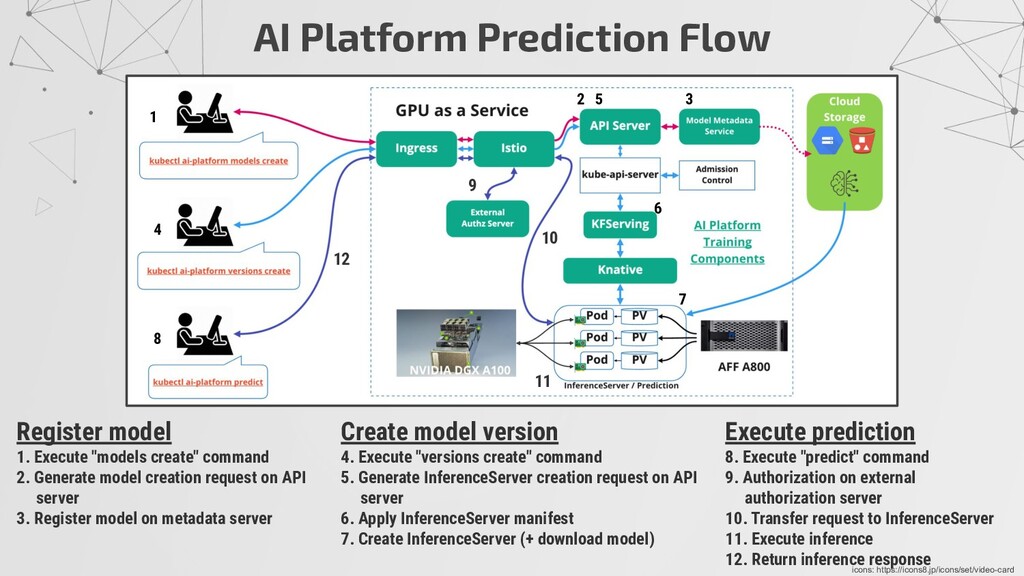
command 2. Generate model creation request on API server 3. Register model on metadata server Execute prediction 8. Execute "predict" command 9. Authorization on external authorization server 10. Transfer request to InferenceServer 11. Execute inference 12. Return inference response Create model version 4. Execute "versions create" command 5. Generate InferenceServer creation request on API server 6. Apply InferenceServer manifest 7. Create InferenceServer (+ download model) 1 2 3 4 5 9 7 8 10 12 11 6 icons: https://icons8.jp/icons/set/video-card
complex data On-premises advantages Features • Flexible software stack assembly • Easy connections with existing services Costs • High cloud expenses • Inexpensive over the long term
A100 GPUaaS (Kubernetes) AI Platform AI Platform By making aggressive use of OSS and improving upon platforms, we can make application development more agile and have a big impact on business. AFF A800 Google AI platform compatibility Ultra-high-performance GPUs/storage
• Pipeline features ◦ ML workflow automation • Black box optimization features Physical hardware • Augmented DGX A100/A100 GPU and AFF A800 • Improve cost-effectiveness by integrating with other GPUs (T4, etc.)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}